MySQL語法學習筆記
學習之道,非盡心竭力者不能進也!我是小七黛,歡迎查看我的筆記,有問題歡迎交流探討,
SQL是一種結構查詢語言,用于查詢關系資料庫的標準語言,包括若干關鍵字和一致的語法,便于資料庫元件(表、索引、欄位等)的建立和操縱,全文是學習《MySQL必知必會》做的筆記,如有必要可自行閱讀,
目錄
- MySQL語法學習筆記
- 1.MySQL建庫
- 1.1建庫陳述句
- 1.2洗掉庫
- 2.建表
- 2.1建表模板
- 2.2 主鍵(PRIMARY KEY)
- 2.3AUTO_INCREMENT
- 2.4 默認值
- 2.5 存盤引擎(ENGINE=InnoDB)
- 2.6 ALTER TABLE 陳述句
- 2.7 洗掉表
- 3.SQL處理資料的基本方法
- 3.1 資料檢索(select 陳述句)
- 3.2 資料排序
- 3.3 資料過濾
- 3.3.1 使用Where子句
- 3.3.2 空值檢查
- 3.3.3 And、Or、In、Not操作及其計算次序
- 3.3.4 通配符(模糊匹配)
- 4.SQL處理資料高級方法
- 4.1正則運算式
- 4.1.1基本字串匹配
- 4.1.2 特殊字符“ .” 的使用
- 4.1.3 使用 or 進行匹配(條件匹配)
- 4.1.4 []匹配
- 4.1.4.1 匹配幾個字符之一
- 4.1.4.2 匹配范圍
- 4.1.4.3 排他符[^]
- 4.1.5 特殊字符的匹配(. [] | -)
- 4.1.6 匹配字符類
- 4.1.7 匹配多個實體,重復元字符
- 4.1.8 定位符,元字符
- 4.2 計算欄位
- 4.2.1 什么是計算欄位
- 4.2.2 拼接欄位
- 4.2.3 執行算術計算
- 4.3 MySQL資料處理函式
- 4.3.1 文本處理函式
- 4.3.2 數值函式
- 4.3.3 日期函式
- 4.3.4 系統函式
- 4.4 資料匯聚
- 4.4.1 AVG() 函式
- 4.4.2 count() 函式
- 4.4.3 MAX() 函式
- 4.4.4 MIN() 函式
- 4.4.5 SUM() 函式
- 4.4.6 聚集不同值(distinct)
- 4.4.7 組合聚集函式
- 4.5 資料分組
- 4.5.1 創建分組
- 4.5.2 過濾分組
- 4.5.3 分組與排序
- 4.5.4 SELECT 子句順序
- 4.6 子查詢
- 4.6.1 利用子查詢進行過濾
- 4.6.2 作為計算欄位使用子查詢
- 4.7 聯結表
- 4.7.1 創建聯結表
- 4.7.2 自聯結
- 4.7.3 自然聯結
- 4.7.4 外部聯結
- 4.7.5 帶聚集函式的聯結
- 5.SQL高級資料查詢
- 5.1 組合查詢
- 5.1.1 創建組合查詢
- 5.1.2 UNION的使用規則
- 5.2 全文本搜索
- 5.2.1 全文本搜索基本應用
- 5.2.2 查詢擴展
- 5.2.3 布爾文本查詢
- 5.2.4 全文本搜索說明
- 5.3 插入資料
- 5.3.1 插入完整的行
- 5.3.2 插入行的一部分
- 5.3.3 插入多行
- 5.3.4 插入某些查詢的結果
- 5.4 更新和洗掉資料
- 5.4.1 更新資料
- 5.4.2 洗掉資料
- 5.5 視圖
- 5.6 存盤程序
- 5.6.1 創建存盤程序
- 5.6.2 呼叫存盤程序
- 5.6.3 洗掉存盤程序
- 5.6.4 使用引數
- 5.7 游標
- 5.7.1 創建游標
- 5.7.2 打開和關閉游標
- 5.7.3 使用游標資料
- 5.8 觸發器
- 5.8.1 創建觸發器
- 5.8.2 觸發器的洗掉
- 5.8.3 INSERT 觸發器
- 5.8.4 DELETE 觸發器
- 5.8.4 UPDATE觸發器
- 6.MySQL資料安全
- 6.1 事務管理
- 6.2 資料備份和性能管理
- 6.2.1 資料備份
1.MySQL建庫
1.1建庫陳述句
create database emp #建庫 名為 emp
default character set utf-8 #設定該庫的默認編碼格式為 utf-8
collate utf8_general_ci; #設定資料庫校對規則,不區分大小寫示例中 utf8_bin將字串中的每一個字符用二進制資料存盤,區分大小寫,utf8_genera_ci不區分大小寫,ci為case insensitive的縮寫,即大小寫不敏感,utf8_general_cs區分大小寫,cs為case sensitive的縮寫,即大小寫敏感,
1.2洗掉庫
drop database emp;2.建表
2.1建表模板
CREATE TABLE customers
(
cust_id int NOT NULL AUTO_INCREMENT,
cust_name char(50) NOT NULL ,
cust_address char(50) NULL ,
cust_city char(50) NULL ,
cust_state char(5) NULL ,
cust_zip char(10) NULL ,
cust_country char(50) NULL ,
cust_contact char(50) NULL ,
cust_email char(255) NULL ,
PRIMARY KEY (cust_id)
) ENGINE=InnoDB;2.2 主鍵(PRIMARY KEY)
主鍵值必須唯一:表中的每個行必須具有唯一的主鍵值,
如果主鍵使用單個列,則它的值必須唯一,
迄今為止我們看到的CREATE TABLE例子都是用單個列作為主鍵,
PRIMARY KEY (cust_id)如果使用多個列,則這些列的組合值必須唯一 ,
創建由多個列組成的主鍵,應該以逗號分隔的串列給出各列名,
PRIMARY KEY (order_num,order_item)主鍵中只能使用不允許NULL值的列,允許NULL值的列不能作為唯一標識,
2.3AUTO_INCREMENT
AUTO_INCREMENT定義列為自增的屬性,一般用于主鍵,每次執行一個INSERT操作時,數值會自動加1
使用的最簡單的編號是下一個編號,所謂下一個編號是大于當前最大編號的編號,例如,如果cust_id的最大編號為10005,則插入表中的下一個顧客,可以具有等于10006的 cust_id ,
2.4 默認值
如果在插入行時沒有給出值,MySQL允許指定此時使用的默認值,默認值 用CREATE TABLE陳述句的列定義中的DEFAULT關鍵字指定
2.5 存盤引擎(ENGINE=InnoDB)
與其他DBMS一樣,MySQL有一個具體管理和處理資料的內部引擎,
在你使用CREATE TABLE陳述句時,該引擎具體創建表,
而在你使用SELECT陳述句 或進行其他資料庫處理時,該引擎在內部處理你的請求,
多數時候,此引擎 都隱藏在DBMS內,不需要過多關注它,
以下是幾個需要知道的引擎:
-
InnoDB是一個可靠的事務處理引擎,它不支持全文本搜索;
-
MEMORY在功能等同于MyISAM,但由于資料存盤在記憶體(不是磁盤)中,速度很快(特別適合于臨時表);
-
MyISAM是一個性能極高的引擎,它支持全文本搜索但不支持事務處理 ,
2.6 ALTER TABLE 陳述句
ALTER TABLE 陳述句用于在已有的表中添加、洗掉或修改列,
-- 表中添加列
ALTER TABLE customers
ADD cust_phone char(10)
-- 洗掉表中的列(請注意,某些資料庫系統不允許這種在資料庫表中洗掉列的方式)
ALTER TABLE customers
DROP COLUMN cust_phone
-- 改變表中列的資料型別
-- 修改數量欄位的默認值為80
ALTER TABLE customers
MODIFY COLUMN quantity int(11) null default 80 after prod_id2.7 洗掉表
DROP TABLE customers3.SQL處理資料的基本方法
3.1 資料檢索(select 陳述句)
Select 陳述句語法
Select 檢索所有列
Select 檢索單個列
Select 檢索不同行
Select 的結果限定
# 描述表
DESC products;
# select 陳述句 檢索所有列
SELECT * FROM products;
# select 陳述句 檢索指定的多個列
SELECT prod_id,prod_name,prod_price FROM products;
# select 陳述句 檢索指定的一個列
SELECT vend_id FROM products;
# 去重,DISTINCT 關鍵詞用于回傳唯一不同的值
SELECT distinct vend_id FROM products;
# 第1行開始,取前3行
SELECT * FROM products limit 3;
# 第4行開始,取3行
SELECT * FROM products limit 3,3;3.2 資料排序
ORDER BY 關鍵字用于對結果集按照一個列或者多個列進行排序,
ORDER BY 關鍵字默認按照升序對記錄進行排序,如果需要按照降序對記錄進行排序,可以使用 DESC 關鍵字,
# 先查看一下這次用的products表
SELECT * from products;
# 單個欄位的排序 升序 降序
SELECT prod_id,prod_price from products
ORDER BY prod_price;
# 默認(ASC)是升序,desc 是降序,默認可以不寫
SELECT prod_id,prod_price from products
ORDER BY prod_price desc;
# 默認排序a-z ,反序就是z-a
SELECT prod_id,prod_price from products
ORDER BY prod_name desc;
# 多欄位排序
SELECT prod_name,prod_price from products
ORDER BY prod_price,prod_name;
# 找出最便宜的產品
SELECT prod_name,prod_price from products
ORDER BY prod_price LIMIT 1;
# 找出最貴的產品
SELECT * from products
ORDER BY prod_price DESC LIMIT 1; 3.3 資料過濾
資料庫表一般包含大量的資料,很少需要檢索表中所有行,
通常只會根據特定操作或報告的需要提取表資料的子集,
只檢索所需資料需要指定搜索條件(search criteria)
搜索條件也稱為過濾條件(filter condition),
在SELECT陳述句中,資料根據WHERE子句中指定的搜索條件進行過濾,
WHERE子句在表名 (FROM子句)之后給出,
3.3.1 使用Where子句
檢查單個值
不匹配檢查
# 篩選價格是2.5的產品
select * from products where prod_price = 2.5;
# 篩選價格是2.5的產品,并只顯示特定的欄位
select prod_name,prod_price from products
where prod_price = 2.5;
# WHERE 條件運算子:=、>、<、>=、<=、<>/!=、between * and *(包含首尾)
select prod_name,prod_price from products
where prod_price >= 2.5 and prod_price <10
order by prod_price;
select prod_name,prod_price from products
where prod_price BETWEEN 2.5 and 10
order by prod_price;練習:
找出價格低于10元的產品
找出價格不是供應商1003制造的產品
找出供應商1001,1003 制造的產品
select prod_name,prod_price from products
where prod_price < 10
order by prod_price;
select vend_id,prod_name,prod_price from products
where vend_id != 1003
order by prod_price;
select vend_id,prod_name,prod_price from products
where vend_id = 1001 or vend_id = 1003;
order by prod_price;3.3.2 空值檢查
select * from products
where prod_desc is null3.3.3 And、Or、In、Not操作及其計算次序
- AND & OR 運算子用于基于一個以上的條件對記錄進行過濾,
- 如果第一個條件和第二個條件都成立,則 AND 運算子顯示一條記錄,
- 如果第一個條件和第二個條件中只要有一個成立,則 OR 運算子顯示一條記錄,
- 先and陳述句后執行or陳述句
# where 組合子句之 and 操作(交集)
select * from products where vend_id=1003 and prod_price <=10
ORDER BY prod_price;
# where 組合子句之 or 操作(并集)
select * from products where vend_id=1003 or vend_id =1002;
# where 組合子句之 AND 和 OR 的結合使用(使用圓括號來組成復雜的運算式)
SELECT * FROM products
WHERE prod_price <=10
AND (vend_id=1003 or vend_id =1002);- IN 運算子允許在 WHERE 子句中規定多個值
- ‘=’ 規定一個值
# where 組合子句之 in 操作
select * from products where
vend_id in (1001,1005,1002);
# where 組合子句之 in 與 = 的轉換
select * from products where
vend_id = 1001 or vend_id = 1005 or vend_id = 1002;
# where 組合子句之 not 操作
select * from products where
vend_id not in (1002);- not操作
# where 組合子句之 not 操作
select * from products where
vend_id not in (1002);3.3.4 通配符(模糊匹配)
- 通配符可用于替代字串中的任何其他字符,
- % 替代 0 個或多個字符
- “_” 替代1個字符,
- LIKE 運算子用于在 WHERE 子句中搜索列中的指定模式
# 找到以 jet開頭的產品
select prod_id ,prod_name from products
where prod_name like 'jet%'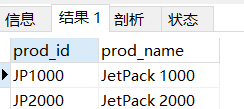
select prod_id ,prod_name from products
where prod_name like '%anvil%'
select prod_id ,prod_name from products
where prod_name like 's%e'
select prod_id ,prod_name from products
where prod_name like '_ ton anvil'
select prod_id ,prod_name from products
where prod_name like '__ ton anvil'注意:
- 不要過度使用通配符,如果其他運算子能達到相同的目的,應優先使用其他運算子,
- 非必要情況下,不要把通配符用在搜索模式的開始處,因為這樣搜索起來是最慢的,
- 仔細注意通配符的位置,如果放錯地方可能不會回傳想要的資料,
4.SQL處理資料高級方法
4.1正則運算式
正則運算式 用特殊的字符集合與一個文本串進行比較,過濾檢索出想要的資料
- 正則運算式是用來匹配文本的特殊的串(字符集合)
- 如果你想從一個文本檔案中提取電話號碼,可以使用正則運算式,
- 如果你需要查找名字中間有數字的所有檔案,可以使用一個 正則運算式,
- 如果你想在一個文本塊中找到所有重復的單詞,可以使用一 個正則運算式,
- 如果你想替換一個頁面中的所有URL為這些URL的實際 HTML鏈接,也可以使用一個正則運算式(對于最后這個例子,或者是兩個正則運算式),
4.1.1基本字串匹配
# 使用 like 關鍵字和通配符 %
select prod_name from products
where prod_name like '%1000';
# 使用正則運算式 REGEXP
select prod_name from products
where prod_name REGEXP '1000';
# 可以檢索出prod_name 中所有含有‘1000’的行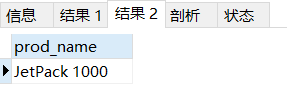
4.1.2 特殊字符“ .” 的使用
“ .” 在正則運算式中表示匹配任意一個字符
# 使用 like 關鍵字和通配符 _
select prod_name from products
where prod_name like 'JetPack _000';
# 使用正則運算式 REGEXP 和特殊字符“.”
select prod_name from products
where prod_name REGEXP '.000';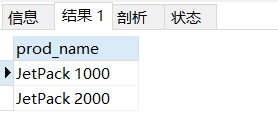
- 在這里會不會有人覺得奇怪,“.” 表示的是匹配任意一個字符,但結果顯示的 JetPack 1000、JetPack
2000,000的前面可不止一個字符,為什么能這樣匹配呢? - 好好理解這句話 “正則運算式是用來匹配文本的特殊的串”
你會發現利用正則運算式我們可以匹配出相應欄位中所有含有需要匹配的文本的行,例子中我們需要匹配的是‘.000’,.
可以代表任何一個字符,所以我們把 JetPack 1000、JetPack 2000
匹配出來了,1000,2000就是我們想要匹配的文本,不管他們前后還有沒有別的字符都會被查詢的到, - 對比 關鍵字 like 與通配符的聯合使用就無法達到這種效果了,
4.1.3 使用 or 進行匹配(條件匹配)
此 or 不是真的 or ,而是使用豎線 “|” 表示搜索 兩個匹配文本串的其中一個
# 檢索prod_name 中所有含有‘1000’或者‘2000’的行
select prod_name from products
where prod_name REGEXP '1000|2000';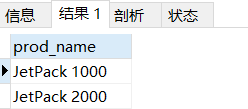
正則運算式中可使用多個 or 條件
select prod_name from products
where prod_name REGEXP '1000|2000|anvil';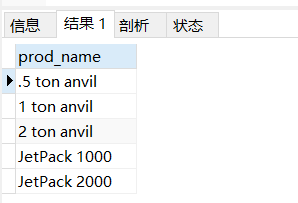
4.1.4 []匹配
”[]“代表需要匹配[]中所包含的任意一個字符
4.1.4.1 匹配幾個字符之一
select prod_name from products
where prod_name REGEXP '[12] ton';這里使用正則運算式 [12] ton , [12] 定義了一組字符1,2;可以匹配 1 ton 或者 2 ton.
其實,[] 是另一種形式的 or 陳述句
4.1.4.2 匹配范圍
[]匹配[]中所包含的任意一個字符
[0-9] 匹配0到9的任意數字字符
[1-3] 匹配1到3的任意數字字符
[6-9] 匹配6到9的任意數字字符
[a-z] 匹配a到z 的任意字母字符
select prod_name from products
where prod_name REGEXP '[1-5] ton';
# 匹配1到5任意一個數字,所以回傳了1 ton、2 ton、5 ton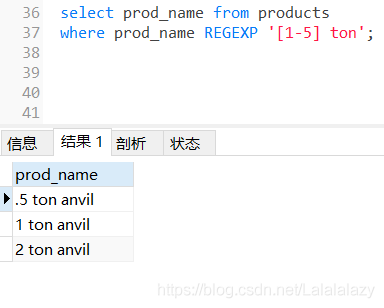
4.1.4.3 排他符[^]
- [^] 匹配未包含在[]中的任意字符,即,將匹配除指定字符外的任何東西,
- 在集合開始處放置一個 ^
- 例如,[^12],會匹配除1,2外的任何東西
select prod_name from products
where prod_name REGEXP '[^345] ton'
# 不會出現 3 ton、4 ton、5 ton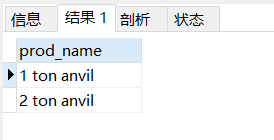
4.1.5 特殊字符的匹配(. [] | -)
匹配特殊字符(. [] | -)時,需要使用 轉義符(兩個反斜杠\\)
\\- 表示查找 -,\\.表示查找 .
select prod_name from products
where prod_name REGEXP '\\.';
#查找 .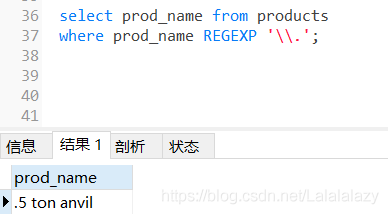
\\也用來參考元字符(具有特殊含義的字符)
| 元字符 | 說明 |
|---|---|
| \\f | 換頁 |
| \\n | 換行 |
| \\r | 回車 |
| \\t | 制表 |
| \\v | 縱向制表 |
4.1.6 匹配字符類
[:digit:] 任意數字 (同[0-9])
[:alnum:] 任意字母和數字 (同[a-zA-Z0-9])
[:alpha:] 任意字母 (同[a-zA-Z])
[:lower:] 任意小寫字母 (同[a-z])
[:upper:] 任意大寫字母 (同[A-Z])
select prod_name from products
where prod_name REGEXP '[[:digit:]]{4}'4.1.7 匹配多個實體,重復元字符
| 元字符 | 說明 |
|---|---|
| * | 0個或多個匹配 |
| + | 1個或多個匹配 (同{1,}) |
| ? | 0個或1個匹配(同{0,1}) |
| {n} | 指定數目的匹配 |
| {n,} | 不少于指定數目的匹配 |
| {n,m} | 匹配數目的范圍(m不超過255) |
#匹配連在一起的任意4位數字的行
select prod_name from products
here prod_name REGEXP '[[:digit:]]{4}';
select prod_name from products
where prod_name REGEXP '[0-9][0-9][0-9][0-9]';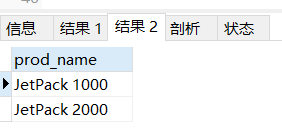
select prod_name from products
where prod_name REGEXP '\\([0-9] sticks?\\)';
# \\( 、\\) 使用轉義符,[0-9]匹配1到9任意數字
#s? 中 使用 ?表示 s 可以出現0次或1次,所以出現了結果stick、sticks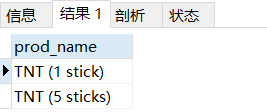
- ? 匹配它前面的任何字符的0次或1次出現,換句話說,?前面的字符有(1個)或者沒有(0個)都能被匹配
4.1.8 定位符,元字符
| 元字符 | 說明 |
|---|---|
| ^ | 文本的開始 |
| $ | 文本的結尾 |
| [[:<:]] | 詞的開始 |
| [[:>:]] | 詞的結尾 |
select prod_name from products
where prod_name REGEXP '^[\\.]'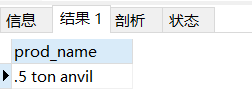
在這里,我們可以回顧一下排他符[^ ]
總結一下^ 的用途:
1.在集合中 [^],表示不匹配集合所包含的字符
2.匹配輸入字串的開始位置,
4.2 計算欄位
4.2.1 什么是計算欄位
- 有時候,我們需要的是直接從資料庫中檢索出轉換、計算或格式化過的資料;比如物品訂單表存盤的是物品的價格和數量,而有時候我們需要的是總價格,這時我們就可以通過計算欄位創建我們需要的資料了,
- 計算欄位不實際存在于資料庫表中,而是運行時在select陳述句內創建的欄位(列),可以使用別名,
4.2.2 拼接欄位
- 將值聯結到一起構成單個值
- concat() 函式,可以拼接字串,可以拼接兩個列,拼接的串之間用逗號分隔
SELECT * FROM vendors;
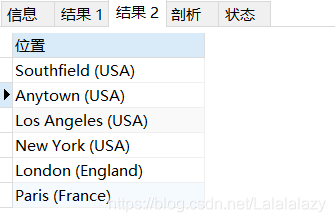
SELECT CONCAT(vend_city,' (',vend_country,')') from vendors;
- 使用別名:使用 as 關鍵字
- as 后接著你想要賦予欄位的名字
SELECT CONCAT(vend_city,' (',vend_country,')') as '位置'
from vendors;
4.2.3 執行算術計算
- 對檢索出來的資料進行算術計算
select prod_id,quantity * item_price as total
from orderitems
ORDER BY total;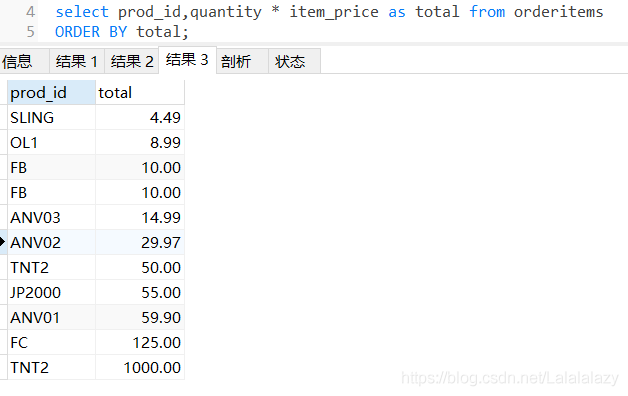
- MySQL算術運算子
| 運算子 | 說明 |
|---|---|
| + | 加 |
| - | 減 |
| * | 乘 |
| / | 除 |
4.3 MySQL資料處理函式
| 函式型別 | 說明 |
|---|---|
| 文本函式 | 處理文本串(如洗掉或填充值,轉換值得大小寫) |
| 數值函式 | 用于數值資料上的算術操作(如回傳絕對值,進行代數計算 ) |
| 日期和時間函式 | 處理日期和時間值并從這些值中提取特定的成分(如回傳兩個日期之差,檢查日期有效性等) |
| 系統函式 | 回傳DBSM正使用的特殊資訊(如回傳用戶登錄資訊,檢查版本細節) |
4.3.1 文本處理函式
| 函式 | 作用 |
|---|---|
| Rtrim(s) | 去除字串右邊的空格 |
| Ltrim(s) | 去除字串左邊的空格 |
| TRIM(s) | 去除字串開頭結尾的空格 |
| upper(s) | 定義字串全部大寫 |
| UCASE(s) | 將字串轉成大寫 |
| lower(s) | 定義字串全部小寫 |
| LCASE(s) | 將字串全部轉成小寫 |
| ASCII(s) | 回傳字串 s 的第一個字符的 ASCII 碼 |
| CHAR_LENGTH(s) | 回傳字串s的字符數 |
| CHARACTER_LENGTH(s) | 回傳字串s的字符數 |
| CONCAT(s1,s2…sn) | 合并字串 |
| MID(s,n,len) | 從字串 s 的 n 位置截取長度為 len 的子字串,同 SUBSTRING(s,n,len) |
| substring(s,n,len) | 從字串 s 的 n 位置截取長度為 len 的子字串 |
| SPACE(n) | 回傳n個空格 |
| RIGHT(s,n) | 回傳字串 s 的后 n 個字符 |
| LPAD(s1,len,s2) | 在字串 s1 的開始處填充字串 s2,使字串長度達到 len |
| RPAD(s1,len,s2) | 在字串 s1 的結尾處添加字串 s2,使字串的長度達到 len |
| INSERT(s1,x,len,s2) | 字串 s2 替換 s1 的 x 位置開始長度為 len 的字串 |
| FORMAT(x,n) | 函式可以將數字 x 進行格式化 “#,###.##”, 將 x 保留到小數點后 n 位,最后一位四舍五入, |
SELECT UPPER(RTRIM(vend_name))as vend_name FROM vendors;
SELECT vend_name,ASCII(vend_name) FROM vendors;4.3.2 數值函式
| 函式 | 說明 |
|---|---|
| ABS(x) | 回傳 x 的絕對值 |
| ACOS(x) | 求反余弦值(引數是弧度) |
| ASIN(x) | 求反正弦值(引數是弧度) |
| ATAN(x) | 求反正切值(引數是弧度) |
| AVG(expression) | 回傳一個運算式的平均值,expression 是一個欄位 |
| CEIL(x) | 回傳大于或等于 x 的最小整數 |
| CEILING(x) | 回傳大于或等于 x 的最小整數 |
| COS(x) | 求余弦值(引數是弧度) |
| COT(x) | 求余切值(引數是弧度) |
| COUNT(expression) | 回傳查詢的記錄總數,expression 引數是一個欄位或者 * 號 |
| DEGREES(x) | 將弧度轉換為角度 |
| n DIV m | 整除,n 為被除數,m 為除數 |
| EXP(x) | 回傳 e 的 x 次方 |
| FLOOR(x) | 回傳小于或等于 x 的最大整數 |
| GREATEST(expr1, expr2, expr3, …) | 回傳串列中的最大值 |
| LEAST(expr1, expr2, expr3, …) | 回傳串列中的最小值 |
| LN() | 回傳數字的自然對數,以 e 為底, |
| LOG(x) 或 LOG(base, x) | 回傳自然對數(以 e 為底的對數),如果帶有 base 引數,則 base 為指定帶底數, |
| LOG10(x) | 回傳以 10 為底的對數 |
| LOG2(x) | 回傳以 2 為底的對數 |
| MAX(expression) | 回傳欄位 expression 中的最大值 |
| MIN(expression) | 回傳欄位 expression 中的最小值 |
| MOD(x,y) | 回傳 x 除以 y 以后的余數 |
| PI() | 回傳圓周率(3.141593) |
| POW(x,y) | 回傳 x 的 y 次方 |
| POWER(x,y) | 回傳 x 的 y 次方 |
| RADIANS(x) | 將角度轉換為弧度 |
| RAND() | 回傳 0 到 1 的亂數 |
| ROUND(x) | 回傳離 x 最近的整數 |
| SIGN(x) | 回傳 x 的符號,x 是負數、0、正數分別回傳 -1、0 和 1 |
| SIN(x) | 求正弦值(引數是弧度) |
| SQRT(x) | 回傳x的平方根 |
| SUM(expression) | 回傳指定欄位的總和 |
| TAN(x) | 求正切值(引數是弧度) |
| TRUNCATE(x,y) | 回傳數值 x 保留到小數點后 y 位的值(與 ROUND 最大的區別是不會進行四舍五入) |
4.3.3 日期函式
| 函式 | 說明 |
|---|---|
| ADDDATE(d,n) | 計算起始日期 d 加上 n 天的日期 |
| ADDTIME(t,n) | n 是一個時間運算式,時間 t 加上時間運算式 n |
| CURDATE() | 回傳當前日期 |
| CURRENT_DATE() | 回傳當前日期 |
| CURRENT_TIME | 回傳當前時間 |
| CURRENT_TIMESTAMP() | 回傳當前日期和時間 |
| CURTIME() | 回傳當前時間 |
| DATE() | 從日期或日期時間運算式中提取日期值 |
| DATEDIFF(d1,d2) | 計算日期 d1->d2 之間相隔的天數 |
| DAY(d) | 回傳日期值 d 的日期部分 |
| DAYNAME(d) | 回傳日期 d 是星期幾,如 Monday,Tuesday |
| DAYOFMONTH(d) | 計算日期 d 是本月的第幾天 |
| DAYOFWEEK(d) | 日期 d 今天是星期幾,1 星期日,2 星期一,以此類推 |
| DAYOFYEAR(d) | 計算日期 d 是本年的第幾天 |
| NOW() | 回傳當前日期和時間 |
| WEEK(d) | 計算日期 d 是本年的第幾個星期,范圍是 0 到 53 |
| YEAR(d) | 回傳年份 |
4.3.4 系統函式
| 函式 | 說明 |
|---|---|
| VERSION() | 回傳資料庫的版本號 |
| USER() | 回傳當前用戶 |
| NULLIF(expr1, expr2) | 比較兩個字串,如果字串 expr1 與 expr2 相等 回傳 NULL,否則回傳 expr1 |
| ISNULL(expression) | 判斷運算式是否為 NULL |
| IFNULL(v1,v2) | 如果 v1 的值不為 NULL,則回傳 v1,否則回傳 v2, |
4.4 資料匯聚
- 確定表中行數(或者滿足某個條件或包含某個特定值的行數),
- 獲得表中行組的和,
- 找出表列(或所有行或某些特定的行)的最大值、最小值和平均值,
- SQL匯聚函式 AVG()、COUNT()、MAX()、MIN()、SUN()
- 匯聚函式:運行在行組上,計算和回傳單個值的函式
| 匯聚函式 | 說明 |
|---|---|
| AVG() | 回傳某列的平均值 |
| COUNT() | 回傳某列的行數 |
| MAX() | 回傳某列的最大值 |
| MIN() | 回傳某列的最小值 |
| SUN() | 回傳某列值之和 |
4.4.1 AVG() 函式
#計算產品表中所有產品的平均價格
SELECT AVG(prod_price) as avg_price from products;
#計算特定供應商所提供產品的平均價格
SELECT AVG(prod_price) as avg_price
from products
WHERE vend_id = 1003;注意:AVG()函式忽略列值為 null 的行
4.4.2 count() 函式
- COUNT() 確定表中行的數目或符合特定條件的行的數目
- 使用COUNT(*)對表中行的數目進行計數,不管表列中包含的是空值(NULL)還是非空值,
- 使用COUNT(column)對特定列中具有值的行進行計數,忽略NULL值,
SELECT * from customers;
#對所有行進行計數
SELECT COUNT(*) as num_cust from customers;
# cust_email 為null的行不被計數
SELECT COUNT(cust_email) as num_cust from customers;4.4.3 MAX() 函式
MAX() 回傳指定列中最大值,要求指定列名
SELECT MAX(prod_price) as max_price from products;4.4.4 MIN() 函式
MIN() 回傳指定列中最小值,要求指定列名
SELECT MIN(prod_price) as max_price from products;4.4.5 SUM() 函式
回傳指定列值得和
select sum(quantity) from orderitems where order_num = 200054.4.6 聚集不同值(distinct)
對所有行計算,檢索出包含不同的值
SELECT distinct vend_id FROM products;SELECT AVG(DISTINCT prod_price) as avg_price from products WHERE vend_id = 1003;4.4.7 組合聚集函式
select count(*) as num_items, MIN(prod_price) as min_price,
max(prod_price) as max_price, avg(prod_price) as avg_price from products;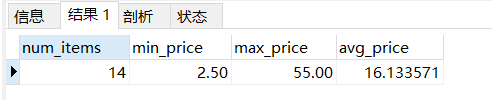
單個select 陳述句執行了4個聚集函式
4.5 資料分組
- group by 子句
- having 子句
4.5.1 創建分組
- 利用group by 子句創建分組輕松知道哪個供應商提供了多少個產品,
SELECT vend_id,COUNT(*) as num_prods from products
GROUP BY vend_id;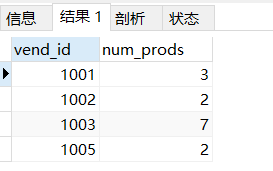
- 使用關鍵字 with rollup 得到匯總數
SELECT vend_id,COUNT(*) as num_prods from products
GROUP BY vend_id with rollup;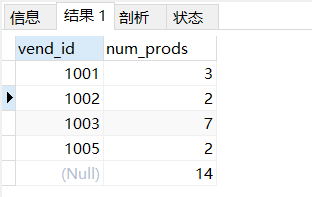
4.5.2 過濾分組
- 使用 having 子句,having 必須跟在 group by 子句之后,
- 對比where 子句,where 子句只是過濾指定的行,而 having 子句過濾的是分組,把不符合條件的組過濾掉,
- where 分組前過濾,having 分組后過濾,
- having 與 where 句法相同
SELECT vend_id,COUNT(*) as num_prods from products
GROUP BY vend_id
having num_prods >2;
#把供應產品數目小于2的供應商過濾掉SELECT vend_id,COUNT(*) as num_prods from products
WHERE prod_price >=10
GROUP BY vend_id
having num_prods >=2
ORDER BY num_prods;
#使用where 把產品單價小于10的行過濾掉,然后按照供應商id分組,再把供應產品數目小于2的供應商過濾掉,最后排序,4.5.3 分組與排序
| ORDER BY | GROUP BY |
|---|---|
| 排序產生的輸出 | 分組行,輸出可能不是分組的順序 |
| 任何列都可以使用(非選擇的列也可以使用) | 只能使用選擇列或運算式列,而且必須使用每個選擇列運算式 |
SELECT order_num,SUM(quantity*item_price) as order_total
from orderitems
GROUP BY order_num
HAVING order_total>=50;4.5.4 SELECT 子句順序
| 子句 | 說明 | 是否必須使用 |
|---|---|---|
| SELECT | 要回傳的列或運算式 | 是 |
| FROM | 從中檢索資料的表 | 僅在從表選擇資料時使用 |
| WHERE | 行級過濾 | 否 |
| GROUP BY | 分組說明 | 僅在按組計算聚集時使用 |
| HAVING | 組級過濾 | 否 |
| ORDER BY | 輸出排序順序 | 否 |
| LIMIT | 要檢索的行數 | 否 |
SELECT order_num,SUM(quantity*item_price) as order_total
from orderitems
GROUP BY order_num
HAVING order_total>=50
ORDER BY order_total
LIMIT 3;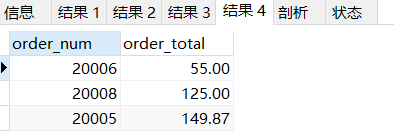
4.6 子查詢
- 子查詢:嵌套在其他查詢中的查詢
4.6.1 利用子查詢進行過濾
- 以訂單錄入系統表為例,假如需要列出訂購物品TNT2的所有客戶,應該怎樣檢索?
#(1)檢索包含物品TNT2的所有訂單的編號,
SELECT order_num,prod_id from orderitems
where prod_id = 'tnt2';
#(2) 檢索具有前一步驟列出的訂單編號的所有客戶的ID,
SELECT cust_id,order_num FROM orders
WHERE order_num in (20005,20007);
#(3) 檢索前一步驟回傳的所有客戶ID的客戶資訊,
SELECT * FROM customers
WHERE cust_id in (10001,10004);- 上述每個步驟都可以單獨作為一個查詢來執行,
- 可以把一條SELECT陳述句回傳的結果用于另一條SELECT陳述句的WHERE子句,
SELECT cust_id FROM orders
WHERE order_num in (SELECT order_num from orderitems
where prod_id = 'tnt2');SELECT * FROM customers
WHERE cust_id in (SELECT cust_id FROM orders
WHERE order_num in (SELECT order_num from orderitems
where prod_id = 'tnt2'));- 在select 陳述句中,子查詢總是從內向外處理,
- SQL對于能嵌套的子查詢的數目沒有限制,不過實際時有性能的限制,不能嵌套太多的子查詢,
- where 子句中使用子查詢時需要注意列必須匹配
4.6.2 作為計算欄位使用子查詢
- 假如現在需要顯示customers表中每個客戶的訂單總數,你會怎么做呢?
#(1) 查看客戶表有哪些客戶
SELECT cust_id,cust_name FROM customers c;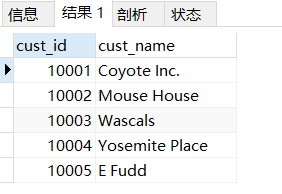
#(2)根據第一步結果相應的去查找哪個客戶下了多少訂單
SELECT COUNT(*) as '10001的訂單數' from orders
WHERE cust_id = 10001;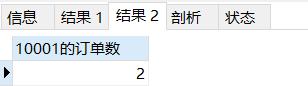
- 是不是感覺很費力!那就看看怎么使用子查詢作為計算欄位吧!
SELECT cust_id,cust_name,(SELECT COUNT(*) FROM orders s# s 是orders表的別名,代表的是orders表
WHERE c.cust_id = s.cust_id) as '訂單總數' FROM customers c;# o 是customers表的別名,代表的是customers表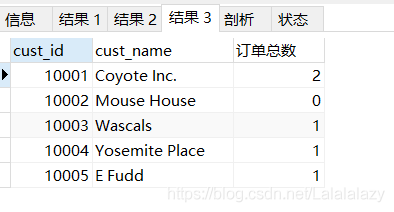
- 這個例子中,“訂單總數”就是我們利用圓括號中的子查詢創建的計算欄位,
(SELECT COUNT(*) FROM orders s WHERE c.cust_id = s.cust_id) as '訂單總數' - 跟子查詢過濾不太一樣的是,我們這里使用了限定列名 WHERE c.cust_id = s.cust_id 這個where陳述句告訴SQL
需要比較orders表中的cust_id 與customers表中的cust_id,當他們相同時把訂單的數目回傳來, - 在這個例子中,該子查詢其實執行了5次,檢索了5個客戶, 當c.cust_id=10001時,在s 中查找s.cust_id
,所以查找到了2個訂單編號,當c.cust_id=10002時,在s
中沒找到s.cust_id=10002,所以回傳了0,說明10001這個客戶沒有訂單,
4.7 聯結表
4.7.1 創建聯結表
SELECT * FROM vendors v,products p
WHERE v.vend_id = p.vend_id;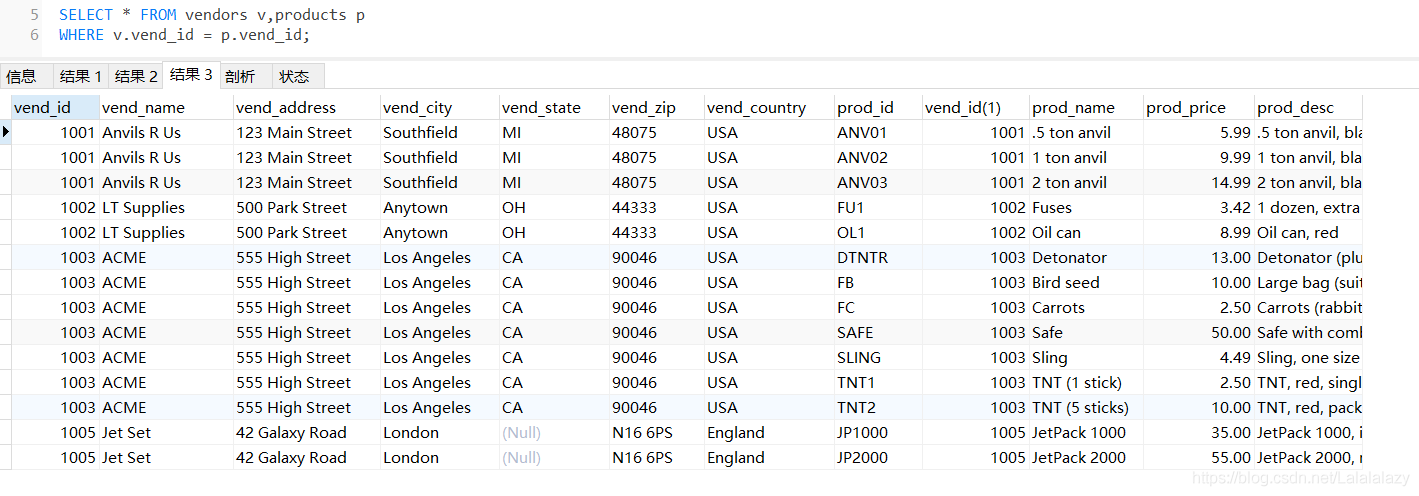
當然你也可以只創建你想要的欄位
SELECT v.vend_id,p.prod_name,p.prod_price FROM vendors v,products p
WHERE v.vend_id = p.vend_id;
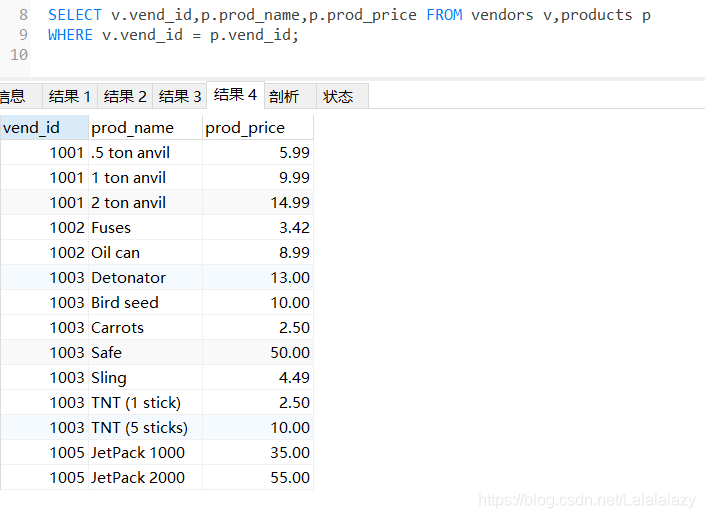
再看一下多表聯結
SELECT * FROM customers c,orders o,orderitems oi
WHERE c.cust_id=o.cust_id and o.order_num =oi.order_num
#通過外鍵主鍵關系聯結了3個表
SELECT c.cust_name,o.order_num,oi.prod_id FROM customers c,orders o,orderitems oi
WHERE c.cust_id=o.cust_id and o.order_num =oi.order_num
# 創建我想要的資料欄位
SELECT c.cust_name,o.order_num,oi.prod_id FROM customers c,orders o,orderitems oi
WHERE c.cust_id=o.cust_id and o.order_num =oi.order_num
and c.cust_name = 'Coyote Inc.';
#找到某個客戶所購買的產品id4.7.2 自聯結
- 引入例子:假如你發現某物品(其ID為DTNTR)存在問題,因此想知道生產該物品的供應商生產的其他物品是否也存在這些問題,
- 此查詢要求首先找到生產ID為DTNTR的物品的供應商,然后找出這個供應商生產的其他物品,
SELECT prod_id,prod_name,vend_id FROM products
WHERE vend_id in (SELECT vend_id FROM products WHERE prod_id='dtntr');
#使用子查詢,回傳生產了DTNTR物品的供應商id,
#該id用于外部查詢的where子句中,檢索出這個供應商生產的所有物品,- 接著,使用自聯結看看效果
SELECT p1.prod_id,p1.prod_name,p1.vend_id
FROM products p1,products p2
WHERE p1.vend_id = p2.vend_id
AND p2.prod_id = 'dtntr';
# where 通過vend_id 匹配表p1、p2,
#按照p2.prod_id='dtntr'過濾資料,把需要的vend_id號傳達給p1表,
#從而找出對應vend_id號的相關產品資訊,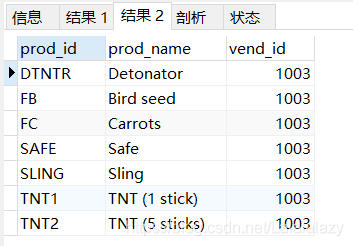
4.7.3 自然聯結
- 無論何時,我們對表進行聯結時,都至少有一個列不止一次出現在一個表中,
- 自然聯結關注的是一一對應,通過主鍵與外鍵的關聯,把相關聯的資訊顯示出來,而關聯不上的資料會被過濾掉,比如客戶表id為1009,如果在訂單表找不到cust_id=1009 ,則這條資料不會顯示出來,
- 事實上,我們建立的每個內部聯結都是自然聯結
select c.* ,o.order_num,o.order_date from customers c , orders o ,orderitems oi
where c.cust_id = o.cust_id and oi.order_num = o.order_num
and oi.prod_id ='FB'4.7.4 外部聯結
- 對比內部聯結,外部聯結有時候可以包含沒有關聯的行
以下例子,聯結包含了哪些在相關表中沒有關聯行的行,這種型別的聯結稱為外部聯結
- 對每個客戶下了多少訂單進行計數,包括那些至今尚未下訂單的客戶;
- 列出所有產品以及訂購數量,包括沒有人訂購的產品;
- 計算平均銷售規模,包括那些至今尚未下訂單的客戶,
#內部聯結,檢索所有客戶及其訂單
SELECT c.cust_id,o.order_num FROM customers c
INNER JOIN orders o
ON c.cust_id = o.cust_id;
# INNER JOIN 內部聯結,INNER表示是內部聯結,省略inner也可以
# 另一種寫法
SELECT c.cust_id,o.order_num FROM customers c,orders o
WHERE c.cust_id = o.cust_id;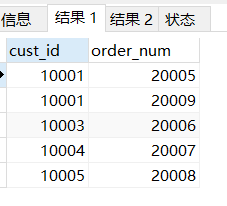
SELECT c.cust_id,o.order_num FROM customers c
LEFT JOIN orders o
ON c.cust_id = o.cust_id;
# LEFT JOIN 左邊聯結,實際上是LEFT OUTER JOIN,表示這是外部聯結,此處省略了OUTER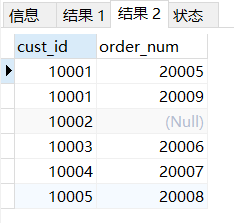
SELECT c.cust_id,o.order_num FROM customers c
RIGHT JOIN orders o
ON c.cust_id = o.cust_id;
# RIGHT JOIN 右邊聯結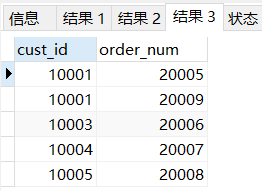
- 外部聯結必須使用 RIGHT JOIN、LEFT JOIN 關鍵字
- 左外部聯結與右外部聯結唯一的差別是所關聯的表的順序不一樣,
- 顧名思義,LEFT指在from子句之后的左邊表(customers表)中選擇所有的行,RIGHT是指在from子句之后的右邊表(orders)中選擇所有的行,
- 換種說法,from之后有兩個表,customers、orders,相對來說customers是左邊的表,而orders是右邊的表,
- 為什么右邊聯結與左邊聯結的結果不一樣,不必明說也可意會了吧!
4.7.5 帶聚集函式的聯結
- 引入例子:如果要檢索所有客戶及每個客戶所下的訂單數,你會怎么做?
#(1)內部聯結
SELECT c.cust_id,c.cust_name,COUNT(o.order_num) AS '訂單數' FROM customers c,orders o
WHERE c.cust_id = o.cust_id
GROUP BY o.cust_id;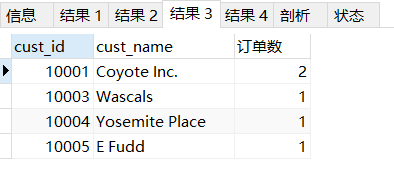
#(2)外部聯結
SELECT c.cust_id,c.cust_name,COUNT(o.order_num) AS '訂單數' FROM customers c LEFT JOIN orders o
ON c.cust_id = o.cust_id
GROUP BY c.cust_id;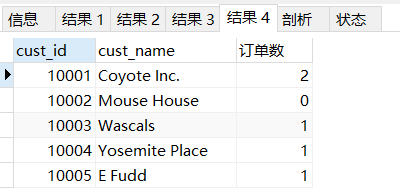
5.SQL高級資料查詢
5.1 組合查詢
- 利用關鍵字union 將多條select陳述句組合成一個結果集
- 在單個查詢中從不同的表回傳類似結構的資料;
- 對單個表執行多個查詢,按單個查詢回傳資料,
5.1.1 創建組合查詢
- 引入例子:假如需要價格小于等于5的所有物品的一個串列,而且還想包括供應商1001和1002生產的所有物品(不考慮價格),
- 可以利用WHERE子句完成,不過這次主要是使用UNION,
#使用where子句
SELECT prod_id,vend_id,prod_price FROM products
WHERE prod_price <=5 OR vend_id IN (1001,1002)
ORDER BY vend_id,prod_price;# 使用組合陳述句 union
SELECT prod_id,vend_id,prod_price FROM products
WHERE prod_price <=5
UNION
SELECT prod_id,vend_id,prod_price FROM products
WHERE vend_id IN (1001,1002)
ORDER BY vend_id,prod_price;- 創建組合查詢即在兩條select陳述句之間加入關鍵字 UNION
5.1.2 UNION的使用規則
- UNION必須由兩潭訓兩條以上的SELECT陳述句組成,陳述句之間用關鍵字UNION分隔(因此,如果組合4條SELECT陳述句,將要使用3個UNION關鍵字),
- UNION中的每個查詢必須包含相同的列、運算式或聚集函式(不過各個列不需要以相同的次序列出),
- 列資料型別必須兼容:型別不必完全相同,但必須是DBMS可以隱含地轉換的型別(例如,不同的數值型別或不同的日期型別),
- UNION的查詢結果會自動去除重復的行
- 如果需要回傳所有匹配的行,可以使用 UNION ALL
SELECT prod_id,vend_id,prod_price FROM products
WHERE prod_price <=5
UNION ALL
SELECT prod_id,vend_id,prod_price FROM products
WHERE vend_id IN (1001,1002)
ORDER BY vend_id,prod_price;- 對組合查詢的排序,order by 必須只能使用一次且只能放在最后一條select 陳述句之后,以上例子都可觀察到,
5.2 全文本搜索
- MySQL最常用的資料庫引擎為 myisam 和 inodb
- MyISAM 支持全文本搜索
- INODB 不支持全文本搜索
- 在使用全文本搜索時,MySQL不需要分別查看每個行,不需要分別分析和處理每個詞,MySQL創建指定列中各詞的一個索引,搜索可以針對這些詞進行,這樣,MySQL可以快速有效地決定哪些詞匹配(哪些行包含它們),哪些詞不匹配,它們匹配的頻率,等等,
- 為了進行全文本搜索,必須索引被搜索的列,而且要隨著資料的改變不斷地重新索引
- 在索引之后,select 可與match() 和 against() 一起使用以實際執行搜索,
- 一般會在創建表時啟用全文本搜索
CREATE TABLE `productnotes` (
`note_id` int(11) NOT NULL AUTO_INCREMENT,
`prod_id` char(10) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`note_date` datetime NOT NULL,
`note_text` text CHARACTER SET utf8 COLLATE utf8_general_ci NULL,
PRIMARY KEY (`note_id`) USING BTREE,
FULLTEXT INDEX `note_text`(`note_text`)
) ENGINE = MyISAM AUTO_INCREMENT = 115 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;# 以上的代碼中根據以下這條子句啟用了全文索引
FULLTEXT INDEX `note_text`(`note_text`)- 在定義之后,MySQL自動維護該索引,在增加、更新或洗掉行時,索引隨之自動更新,
5.2.1 全文本搜索基本應用
- 在索引之后,使用兩個函式 Match()、Against() 執行全文本搜索,
- Match() 指定被搜索的列
- Against() 指定要使用的搜索運算式
SELECT note_text FROM productnotes
WHERE MATCH(note_text) against('rabbit');- 注意:傳遞給 Match() 的值必須與FULLTEXT() 定義中的相同,如果指定多個列,則必須列出它們(而且次序必須正確),
# 使用正則運算式
SELECT note_text FROM productnotes
WHERE note_text REGEXP 'rabbit';
# 使用關鍵字 like
SELECT note_text FROM productnotes
WHERE note_text LIKE '%rabbit%';- 通過對比三個結果,你會發現全文本搜索的一個重要部分就是對結果排序(匹配rabbit時,全文本搜索中先回傳rabbit 作為第3個詞的行,因為包含詞rabbit作為第3個詞的行的等級比作為第20個詞的行高),具有較高等級的行先回傳(因為這些行很可能是你真正想要的行),而like陳述句及正則運算式不具有這種特別的排序功能,
- 如果還不太理解,那再繼續看以下例子,
SELECT note_text,MATCH(note_text) against('rabbit') AS rank_notetext FROM productnotes;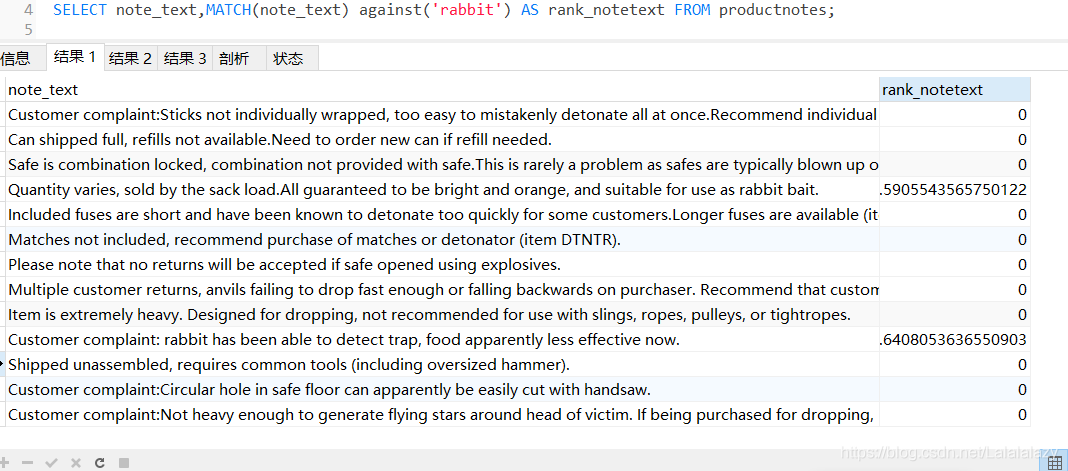
- 在這里,Match()和Against() 作為一個計算欄位被回傳,別名是rank_notetext,此列包含全文本搜索計算出來的等級值,也就是匹配率,這里每個行以及每個行與rabbit這個詞的等級值都顯示出來,不包含詞rabbit的行,等級值為0,文本中詞越靠前的行等級值就越高,
- 這里體現了全文本搜索提供了簡單的LIKE搜素不能提供的功能,而且由于資料是索引的,全文本搜索還相當快,
5.2.2 查詢擴展
- 查詢擴展用來設法放寬所回傳的全文本搜索結果的范圍,
- 使用查詢擴展時,MySQL對資料和索引進行兩遍臊面來完成搜索:
- 首先,進行一個基本的全文本搜索,找出與搜索條件匹配的所有行;
- 其次,MySQL檢查這些匹配行并選擇所有有用的詞(我們將會簡要地解釋MySQL如何斷定什么有用,什么無用),
- 再其次,MySQL再次進行全文本搜索,這次不僅使用原來的條件,而且還使用所有有用的詞,
- 利用查詢擴展,能找出可能相關的結果,即使它們并不精確包含所查找的詞,
# 這是簡單的全文本查詢,沒有查詢擴展,結果回傳了一行包含詞anvils的行
SELECT note_text FROM productnotes
WHERE MATCH(note_text) against('anvils');# 使用了查詢擴展
SELECT note_text FROM productnotes
WHERE MATCH(note_text) against('anvils' WITH QUERY expansion);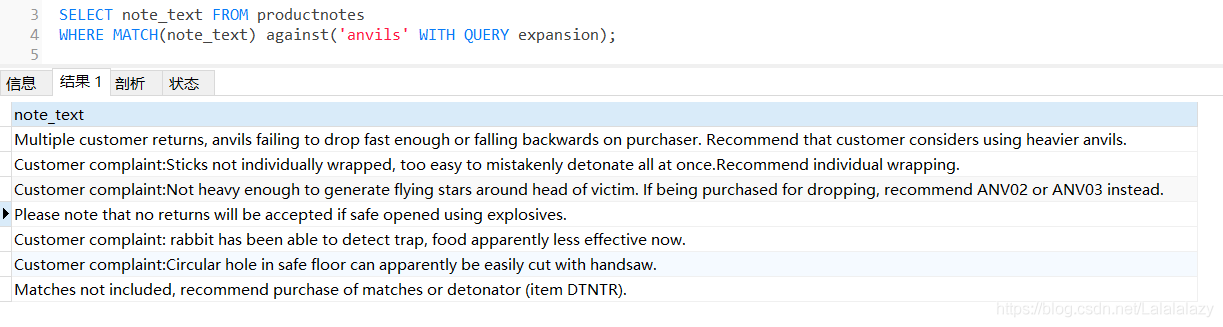
- 這次回傳了7行,第一行包含詞anvils,因此等級最高,第二行與anvils無關,但因為它包含第一行中的兩個詞(customer和recommend),所以也被檢索出來了,
- 查詢擴展的行越多越好
5.2.3 布爾文本查詢
- 要匹配的詞;
- 要排斥的詞(如果某行包含這個詞,則不回傳該行,即使它包含其他指定的詞也是如此);
- 排列提示(指定某些詞比其他詞更重要,更重要的詞等級更高);
- 運算式分組;
- 另外一些內容,
| 布爾運算子 | 說明 |
|---|---|
| + | 必須包含 |
| - | 必須不包含 |
| > | 增加優先等級 |
| < | 降低優先等級 |
| * | 詞尾通配符 |
| “” | 定義短句 |
- 為了匹配包含heavy但不包含任意以rope開始的詞的行,可使用以下查詢:
SELECT note_text FROM productnotes
WHERE MATCH(note_text) against('heavy -rope*' in boolean mode);5.2.4 全文本搜索說明
- 在索引全文本資料時,短詞被忽略且從索引中排除,短詞定義為那些具有3個或3個以下字符的詞(如果需要,這個數目可以更改),
- MySQL帶有一個內建的非用詞(stopword)串列,這些詞在索引全文本資料時總是被忽略,如果需要,可以覆寫這個串列(請參閱MySQL檔案以了解如何完成此作業),
- 許多詞出現的頻率很高,搜索它們沒有用處(回傳太多的結果),因此,MySQL規定了一條50%規則,如果一個詞出現在50%以上的行中,則將它作為一個非用詞忽略,50%規則不用于 IN BOOLEAN MODE,
- 如果表中的行數少于3行,則全文本搜索不回傳結果(因為每個詞或者不出現,或者至少出現在50%的行中),
- 忽略詞中的單引號,例如,don’t索引為dont,
- 不具有詞分隔符(包括日語和漢語)的語言不能恰當地回傳全文本搜索結果,
- 如前所述,僅在MyISAM資料庫引擎中支持全文本搜索,
5.3 插入資料
- INSERT INTO……VALUES(……)
5.3.1 插入完整的行
INSERT語法,要求指定表名和被插入新行中的值
insert into customers values ( null,'ABC','100 Main street','Los angeles','CA','90046','USA',null,null )- 上例插入一行資料到customers表中,存盤在表列中的每個資料在values子句中,對每個列必須提供一個值,沒有值時應使用NULL(前提是該表允許該列是空值),各個列必須以它們在表中出現的次序填充,
- 這種語法特點是簡單但不安全,應盡量避免使用,
- 撰寫insert陳述句更安全(但更繁瑣)的方法如下:
- 表名后括號里明確給出列名,values后相對應的給出值,
insert into customers(
cust_id,
cust_name,
cust_address,
cust_city,
cust_state,
cust_zip,
cust_country,
cust_contact,
cust_email)
values (null,'john','CDEF','99878','ug',null,null,null,null);5.3.2 插入行的一部分
insert into customers (cust_name,cust_zip) values ('CDEF','99878');5.3.3 插入多行
insert into customers (cust_name,cust_zip) values ('2CDEF','199878');
insert into customers (cust_name,cust_zip) values ('3CDEF','399878');
insert into customers (cust_name,cust_zip) values ('4CDEF','599878');
insert into customers (cust_name,cust_zip) values ('5CDEF','799878');5.3.4 插入某些查詢的結果
insert into customers2 select * from customers;5.4 更新和洗掉資料
- UPDATE陳述句
- DELETE陳述句
5.4.1 更新資料
- UPDATE……SET ……
# 復制表customers
CREATE TABLE customers2 as SELECT * FROM customers;update customers2 set cust_email = 'elmer@fudd.com'
where cust_id =10005;5.4.2 洗掉資料
- DELETE FROM ……
delete from customers2 where cust_id = 10006;5.5 視圖
- 視圖是虛擬的表,與包含資料的表不一樣,視圖只包含使用時動態檢索資料的查詢,
- 視圖不包含表中應有的任何列或資料,它包含的是一個SQL查詢
視圖常見的應用:
- 重用SQL陳述句 ,
- 簡化復雜的SQL操作:在撰寫查詢后,可以方便的重用它而不必知道它的基本查詢細節,
- 使用表的組成部分而不是整個表,
- 保護資料,可以給用戶授予表的特定部分的訪問權限而不是整個表的訪問權限,
- 更改資料格式和表示,視圖可以回傳與底層表的表示和格式不同的資料,
視圖的功能:
- 可執行select操作,過濾和排序資料
- 可將視圖聯結到其他視圖或表
- 能添加和更改資料(添加和更新資料有一定的限制)
但視圖僅僅是用來查看存盤在別處的資料的一種設施,視圖本身不包含資料,它們回傳的資料是從其他表中檢索出來的,在添加或更改這些表中的資料是,視圖將回傳改變過的資料,
視圖的性能問題:
- 因為視圖不包含資料,所以每次使用視圖時,都必須處理查詢執行時所需的任一個檢索,如果你用多個聯結和過濾創建了復雜的視圖或者嵌套了視圖,可能會發現性能下降得很厲害,因此,在部署使用了大量視圖的應用前,應該進行測驗,
視圖的規則和限制
- 視圖必須唯一命名
- 對于可以創建的視圖數目沒有限制
- 為了創建視圖,必須具有足夠的訪問權限,這些限制通常由資料庫管理人員授予,
- 視圖可以嵌套,即可以利用從其他視圖中檢索資料的查詢來構造一個視圖,
- ORDER BY可以用在視圖中,但如果從該視圖檢索資料的SELECT陳述句中也含有ORDER BY,那么該視圖中的ORDER BY將被覆寫,
- 視圖不能索引,也不能有關聯的觸發器或默認值,
- 視圖可以和表一起使用,例如,撰寫一條聯結表和視圖的SELECT陳述句,
創建視圖
- 視圖用CREATE VIEW陳述句來創建,
- 使用SHOW CREATE VIEW viewname;來查看創建視圖的陳述句,
- 用DROP洗掉視圖,其語法為DROP VIEW viewname;,
- 更新視圖時,可以先用DROP再用CREATE,也可以直接用CREATE OR REPLACE
VIEW,如果要更新的視圖不存在,則第2條更新陳述句會創建一個視圖;如果要更新的視圖存在,則第2條更新陳述句會替換原有視圖,
還記得在學習聯結表時,我們為了檢索購買了TNT2產品的客戶是怎么做的嗎?
SELECT cust_name,cust_contact,prod_id
FROM customers c,orders o,orderitems oi
WHERE c.cust_id = o.cust_id
AND o.order_num =oi.order_num
AND prod_id = 'TNT2';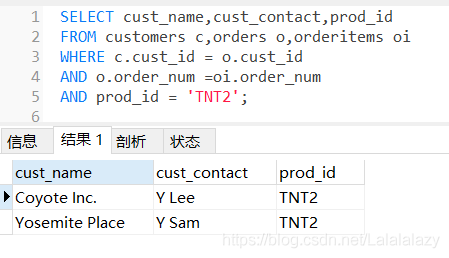
現在,我如果想檢查購買了別的產品的客戶呢?再創建一個這樣的陳述句嗎?也不是不行,只是我們可以通過創建視圖的方法,一次性撰寫基礎的SQL,然后可以根據需要多次使用,極大地簡化了復雜的SQL陳述句,
#講了這么多,先創建個視圖
CREATE VIEW productscustomers AS
SELECT cust_name,cust_contact,prod_id
FROM customers c,orders o,orderitems oi
WHERE c.cust_id = o.cust_id
AND o.order_num =oi.order_num;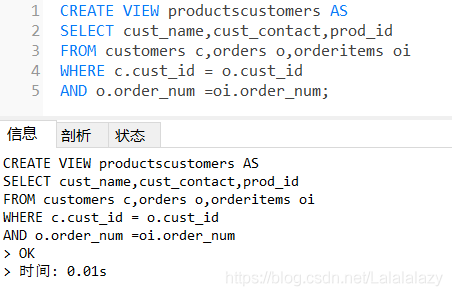
#查看視圖
SELECT * FROM productscustomers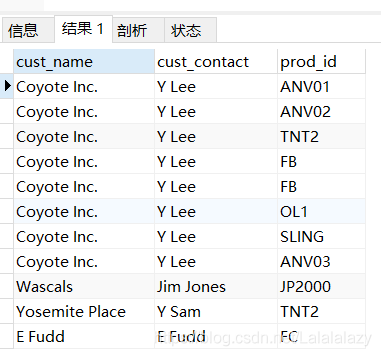
#查看購買了TNT2產品的客戶
SELECT cust_name,cust_contact,prod_id
FROM productscustomers
WHERE prod_id = 'tnt2';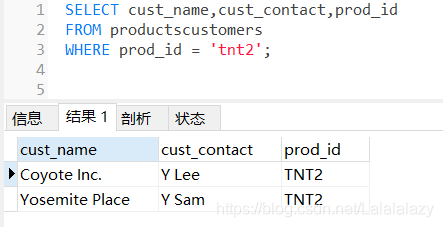
#還想再看看購買了產品FB的客戶
SELECT cust_name,cust_contact,prod_id
FROM productscustomers
WHERE prod_id = 'fb';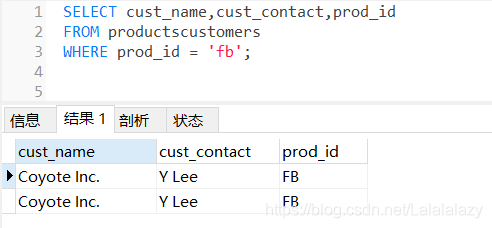
視圖內容格式化
- 視圖還可以重新格式化檢索出來的資料
#學習拼接欄位時,我們利用了select陳述句在單個組合計算列中回傳供應商名和位置,
SELECT CONCAT(RTRIM(vend_name),' (',RTRIM(vend_country),')') AS vend_title
FROM vendors
ORDER BY vend_name;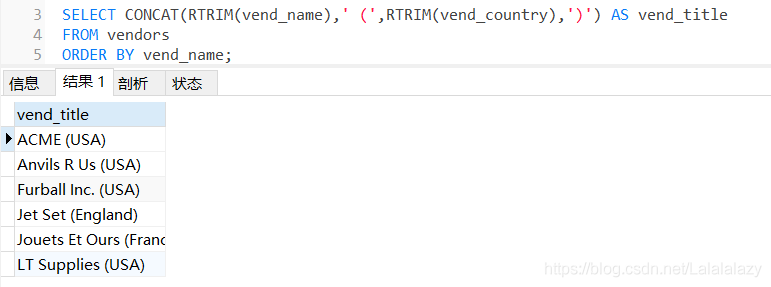
#假如我們需要經常需要這個格式的結果,可創建個視圖,不必每次都進行拼接
CREATE VIEW vendorlocation AS
SELECT CONCAT(RTRIM(vend_name),' (',RTRIM(vend_country),')') AS vend_title
FROM vendors
ORDER BY vend_name;
# 檢索相關資料
SELECT * FROM vendorlocation;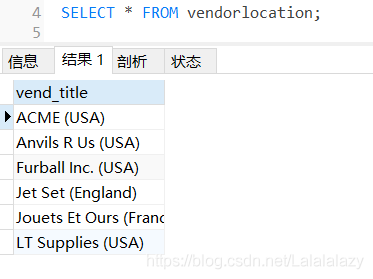
視圖過濾
#創建視圖,過濾掉資訊為空值的資料
CREATE view customernotnull as
select * from customers
where cust_contact is not NULL視圖與計算欄位
CREATE view orderprice as
select prod_id,quantity,item_price,
(quantity*item_price) as total from orderitems;視圖可更新(可使用insert、update、delete,但有條件)
- 不可包含group by和having的使用
- 不可包含子查詢
- 不可包含計算欄位
- 不可包含distinct
5.6 存盤程序
- 簡單來說,存盤程序就是為以后的使用而保存的一潭訓多條MySQL陳述句的集合,可將其視為批檔案,但它們的作用不僅限于批處理,
- 存盤程序的使用有3個好處:簡單、安全、高性能,
- 存盤程序的缺點:撰寫較基本的SQL陳述句復雜,需要更高的技能更豐富的經驗;許多資料庫管理員限制存盤程序的創建權限,允許用戶使用存盤程序,但不允許他們創建存盤程序,
5.6.1 創建存盤程序
CREATE PROCEDURE productpricing()
BEGIN
SELECT AVG(prod_price) AS avg_price
FROM products;
END;
- 此例中,存盤程序名為:productpricing
- 用CREATE PROCEDURE productpricing() 來定義
- BEGIN 和 END 陳述句用來限定存盤程序體,此程序體僅用了一個簡單的 select 陳述句,
- 如果存盤程序接受引數,可將其列舉進productpricing() 的括號中
delimiter //
create PROCEDURE productpricing2()
begin
select AVG(prod_price) from products;
end //
# delimiter;——>保護程式5.6.2 呼叫存盤程序
CALL productpricing();
#執行存盤程序并顯示回傳的結果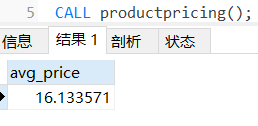
- 存盤程序實際上是一種函式,所以存盤程序名后需要有()括號,即使不傳遞引數也是需要的,
5.6.3 洗掉存盤程序
DROP PROCEDURE productpricing;
- 注意:洗掉存盤程序時,存盤程序名后沒有使用括號(),
5.6.4 使用引數
CREATE PROCEDURE productpricing(
OUT pl DECIMAL(8,2),
OUT ph DECIMAL(8,2),
OUT pa DECIMAL(8,2)
)
BEGIN
SELECT MIN(prod_price)
INTO pl
FROM products;
SELECT MAX(prod_price)
INTO ph
FROM products;
SELECT AVG(prod_price)
INTO pa
FROM products;
END;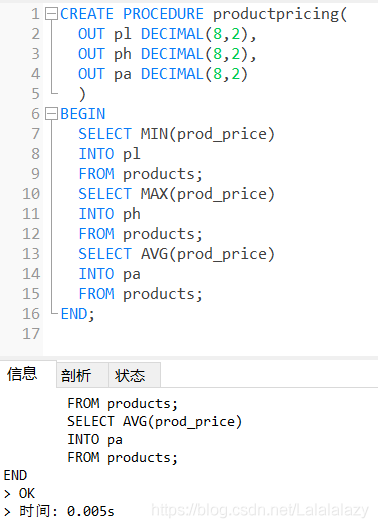
- 此存盤程序接受了3個引數,pl、ph、pa,每個引數必須具有指定的型別,這里使用了十進制值(DECIMAL)
- 關鍵字 OUT 表示相應的引數是從存盤程序中傳出的一個值(回傳給call 呼叫)
| 關鍵字 | 作用 |
|---|---|
| IN | 傳遞給存盤程序 |
| OUT | 從存盤過程序傳出 |
| INOUT | 對存盤程序傳入和傳出 |
| INTO | 保存存盤體的值 |
CALL productpricing(@pl,@ph,@pa);
# 呼叫存盤程序,必須指出3個變數名
# 所有的MySQL變數都必須以@開始
SELECT @pl,@pa;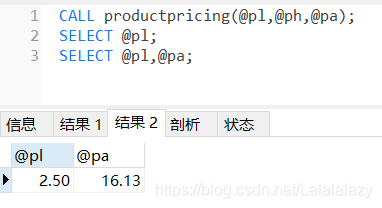
# 下面使用 in 和 out 創建存盤程序
CREATE PROCEDURE ordertotal(
IN o_number INT,
OUT o_total DECIMAL(8,2))
BEGIN
SELECT SUM(item_price*quantity)
INTO o_total
FROM orderitems
WHERE order_num =o_number;
END;# 呼叫
CALL ordertotal(20005,@o_total);
SELECT @o_total;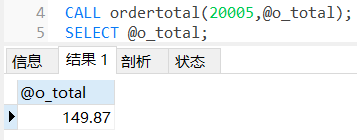
- 此例中,傳遞了兩個引數,o_number (定義為IN ,作為傳入引數傳給了存盤程序)、o_total (定義為OUT ,作為傳出引數用于回傳值)
5.7 游標
5.7.1 創建游標
# 用 DECLARE 陳述句創建游標
CREATE PROCEDURE processorders()
BEGIN
DECLARE ordernumbers CURSOR
FOR
SELECT order_num FROM orders;
END;
# 存盤程序處理完成后,游標就消失,因為游標局限于存盤程序5.7.2 打開和關閉游標
# 打開游標
OPEN ordernumbers;
# 在處理open陳述句執行查詢時,存盤檢索出的資料以供瀏覽和滾動
# 游標處理完成后,當使用CLOSE陳述句關閉游標
CLOSE ordernumbers;- CLOSE釋放游標使用的所有內部記憶體和資源,因此在每個游標不再需要時都應該關閉,
- 游標關閉后可用OPEN 陳述句打開,否則不能使用
- 隱含關閉:如果不明確關閉游標,陳述句到達END陳述句時會自動關閉游標
CREATE PROCEDURE processorders()
BEGIN
-- 宣告定義一個游標
DECLARE ordernumbers CURSOR
FOR
SELECT order_num FROM orders;
-- 打開游標
OPEN ordernumbers;
-- 關閉游標
CLOSE ordernumbers;
END;
# 此存盤程序宣告、打開和關閉了游標,但對檢索出來的數什么也沒有做5.7.3 使用游標資料
CREATE PROCEDURE processorders2()
BEGIN
-- DECLARE local variables 宣告區域變數
DECLARE o INT;
DECLARE ordernumbers CURSOR
FOR
SELECT order_num FROM orders;
OPEN ordernumbers;
-- Get order number 獲取當前行
FETCH ordernumbers INTO o;
CLOSE ordernumbers;
END;- 其中,fetch 用來檢索當前行的order_num 列(將自動從第1行開始),到一個名為 o 的區域變數中,對檢索出的資料不做任何處理,
# 回圈檢索資料,從第1行到最后一行
CREATE PROCEDURE processorders0()
BEGIN
-- DECLARE local variables 宣告定義區域變數done(用作回圈標記),開始值默認為0
DECLARE done boolean DEFAULT 0;
-- 宣告區域變數o
DECLARE o INT;
DECLARE ordernumbers CURSOR
FOR
SELECT order_num FROM orders;
-- DECLARE continue handler
-- 當出現‘02000’錯誤(游標取不到資料)時把區域變數done的值設定為1
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET done = 1;
OPEN ordernumbers;
REPEAT
-- Get order number 把游標獲得的資料取到變數o中
FETCH ordernumbers INTO o;
-- 查詢變數的值
select o;
-- end of loop 結束回圈的條件
UNTIL done
END REPEAT;
-- 關閉游標,釋放游標使用的所有內部記憶體和資源
CLOSE ordernumbers;
END;
call processorders0;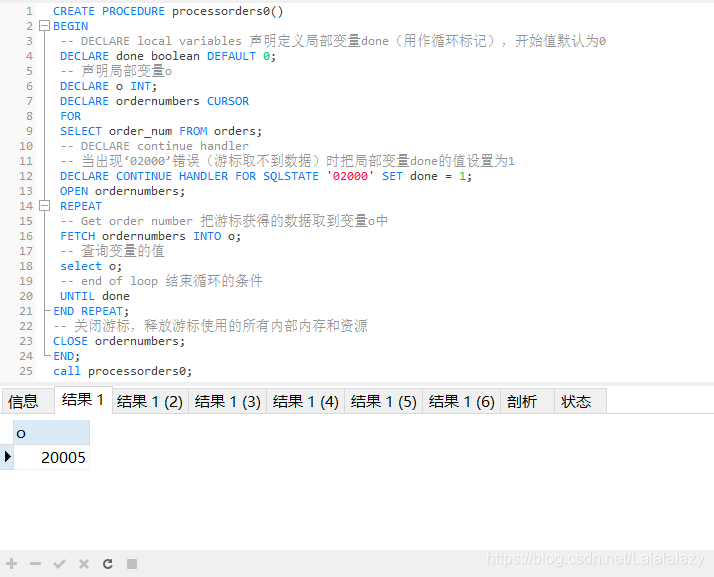
- 通過結果可以看到,游標就是一個結果集,把select陳述句的結果一行一行的回傳,
# 以下是把游標得到的結果集放在創建的表中
CREATE PROCEDURE processorders3()
BEGIN
-- DECLARE local variables
DECLARE done boolean DEFAULT 0;
DECLARE o INT;
DECLARE t DECIMAL(8,2);
DECLARE ordernumbers CURSOR
FOR
SELECT order_num FROM orders;
-- DECLARE continue handler
DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET done = 1;
-- CREATE a table to store the results
CREATE TABLE IF NOT EXISTS ordertotals(order_num INT,total DECIMAL(8,2));
OPEN ordernumbers;
REPEAT
-- Get order number
FETCH ordernumbers INTO o;
-- INSERT order and total into ordertotals
INSERT INTO ordertotals(order_num,total)
VALUES(o,t);
select * from ordertotals;
-- end of loop
UNTIL done END REPEAT;
CLOSE ordernumbers;
END;5.8 觸發器
- 觸發器是在我們執行delete update insert陳述句時自動執行另外一組sql陳述句的功能,
- 觸發器只能用于表,不能用于視圖中
5.8.1 創建觸發器
觸發器的創建需要包含以下4點資訊:
- 唯一的觸發器名;
- 觸發器關聯的表;
- 觸發器應該回應的活動(DELETE、INSERT或UPDATE);
- 觸發器何時執行(處理之前或之后)
# 創建觸發器
create trigger newproduct after insert on products
for each row select 'Product add' into @ee;-
以上例子創建了一個名為 newproduct 的觸發器,在表 products 每次完成插入陳述句時把’Product add’存進變數@ee中
-
接著,為了驗證效果,我們可試著插入一行資料
insert into products(prod_id,vend_id,prod_name,prod_price,prod_desc)
VALUES(666,1006,'隨便','999','好產品');
# 查看結果
SELECT @ee;5.8.2 觸發器的洗掉
- 觸發器不能更新或覆寫,為了修改一個觸發器,必須先洗掉它,然后再重新創建,
drop trigger newproduct;5.8.3 INSERT 觸發器
create trigger neworder after insert on orders
for each row select NEW.order_num into @ee;- 這里創建了一個名為neworder的觸發器,在插入一個新的訂單后(after insert on orders),MySQL會生成一個新的訂單號并保存在order_num 中,觸發器會獲得這個值并回傳它,
- 以下測驗觸發器:
insert into orders(order_date,cust_id)
values (now(),10001);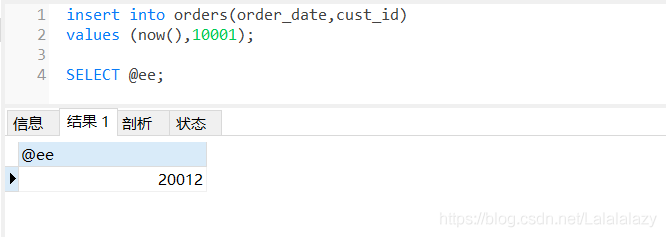
- 以上例子,在insert觸發器的代碼內,參考了‘new‘虛擬表,用來訪問被插入的行
- 在BEFORE INSERT觸發器中,NEW中的值也可以被更新(允許更改被插入的值);
- 對于AUTO_INCREMENT列,NEW在INSERT執行之前包含0,在INSERT執行之后包含新的自動生成值,
5.8.4 DELETE 觸發器
create trigger deleteorder before delete on orders
for each row
BEGIN
insert into archive_orders(order_num,order_date,cust_id)
values (old.order_num,old.order_date,old.cust_id);
end;- 在DELETE觸發器代碼內,可以參考一個名為OLD的虛擬表,訪問被洗掉的行
- OLD中的值全都是只讀的,不能更新,
5.8.4 UPDATE觸發器
- 在UPDATE觸發器代碼中,可以參考一個名為OLD的虛擬表訪問以前(UPDATE陳述句前)的值,參考一個名為NEW的虛擬表訪問新更新的值;
- 在BEFORE UPDATE觸發器中,NEW中的值可能也被更新(允許更改將要用于UPDATE陳述句中的值);
- OLD中的值全都是只讀的,不能更新,
CREATE TRIGGER updatevendor BEFORE UPDATE ON vendors
FOR EACH ROW SET new.vend_state = UPPER(new.vend_state);6.MySQL資料安全
6.1 事務管理
- 用來維護資料庫的完整性,它保證成批的SQL操作要么全部成功,要么全部失敗,
- 事務處理主要是用于管理INSERT、UPDATE、DELETE陳述句
- 并非所有引擎都適合事務管理:
- myisam不支持事務管理
- inodb 支持事務管理
事務處理術語
- 事務(transaction)一組SQL陳述句
- 回退(rollback)撤銷指定SQL陳述句的程序
- 提交(commit )將未存盤的SQL陳述句結果寫入資料庫表中
- 保留點(savepoint)事務處理中設定的臨時占位符,可對它發布回退
事務處理開始陳述句
START TRANSACTION;使用ROLLBACK
SELECT * FROM ordertotals;
START TRANSACTION;
DELETE FROM ordertotals;
SELECT * FROM ordertotals;
ROLLBACK;
SELECT * FROM ordertotals;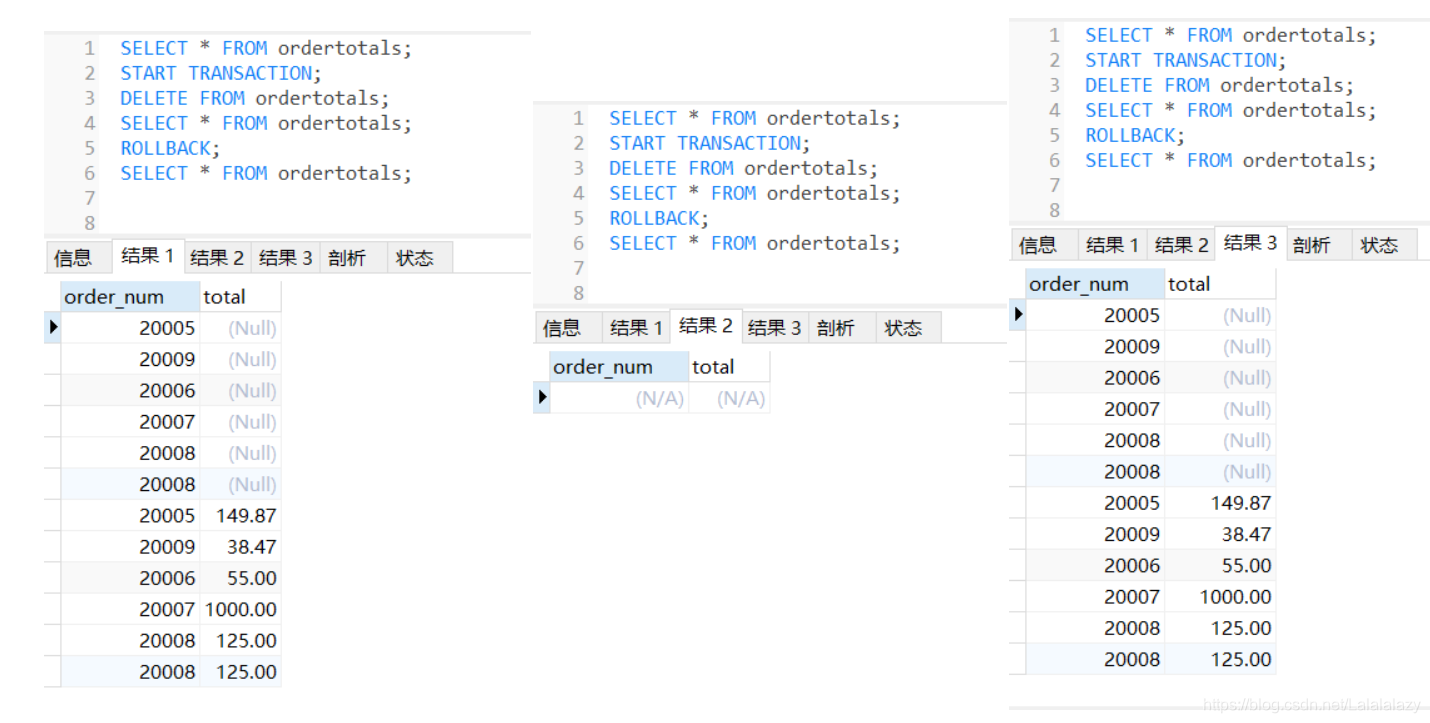
- 以上例子中,選擇了表ordertotals進行操作,第一個select陳述句說明了這表不為空(開始的狀態),開始事務管理,執行了delete陳述句,洗掉ordertotals表中的所有行,第二個select陳述句驗證了表ordertotals確實為空了,然而,當執行ROLLBACK陳述句時,回退事務處理(START TRANSACTION)之后的所有陳述句,即撤退了事務處理中的SQL陳述句,
使用COMMIT
START TRANSACTION;
DELETE FROM ordertotals WHERE total is NULL;
DELETE FROM ordertotals WHERE order_num = 20005;
COMMIT;
SELECT * FROM ordertotals;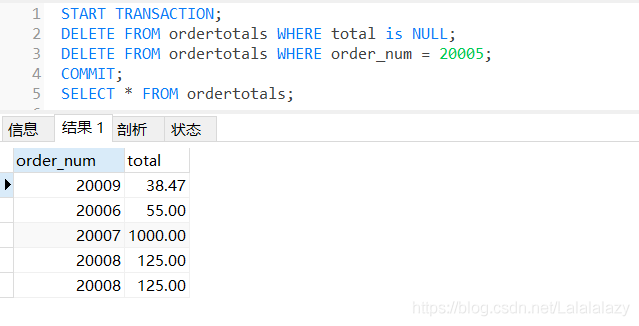
使用保留點(SAVEPOINT)
- 為了支持回退部分事務處理,必須能在事務處理塊中合適的位置放置占位符,這樣,如果需要回退,可以回退到某個占位符,
SELECT * FROM ordertotals;
START TRANSACTION;
DELETE FROM ordertotals WHERE order_num = 20007;
SAVEPOINT d1;
DELETE FROM ordertotals WHERE order_num = 20009;
SELECT * FROM ordertotals;
ROLLBACK TO d1;
SELECT * FROM ordertotals;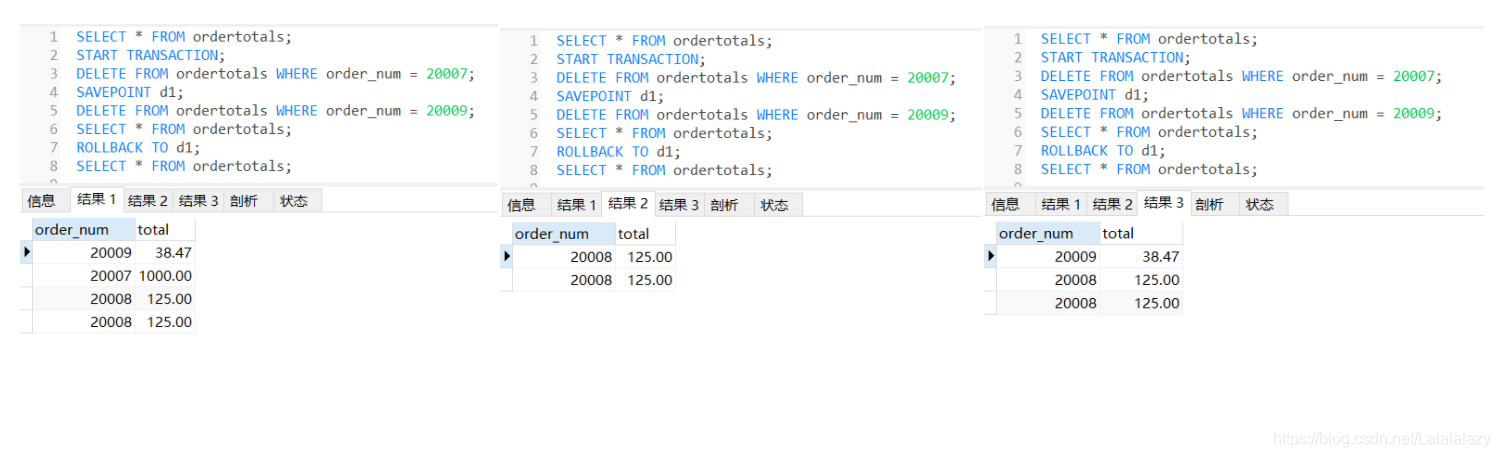
6.2 資料備份和性能管理
6.2.1 資料備份
- 使用命令列實用程式mysqldump轉儲所有資料庫內容到某個外部檔案,在進行常規備份前這個實用程式應該正常運行,以便能正確地備份轉儲檔案,
- 可用命令列實用程式mysqlhotcopy從一個資料庫復制所有資料(并非所有資料庫引擎都支持這個實用程式),
- 可以使用MySQL的BACKUP TABLE或SELECT INTO OUTFILE轉儲所有資料到某個外部檔案,這兩條陳述句都接受將要創建的系統檔案名,此系統檔案必須不存在,否則會出錯,資料可以用RESTORE TABLE來復原,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/251781.html
標籤:python
上一篇:python常用標準庫總結