經常聽說線性回歸(Linear Regression) 到底什么才是線性,什么才是回歸?
有學者說,線性回歸模型是一切模型之母,所以,我們的機器學習之旅,也將從這個模型開始!
建立回歸模型的好處:隨便給一個x,就能通過模型算出y,這個y可能和實際值不一樣,這個y是對實際值的一個可靠的預測
要想理解線性回歸,就得理解下面幾個問題:
1、什么是回歸?
在幾何意義上,回歸就是找到一條具有代表性的直線或曲線(高維空間的超平面)來擬合輸入資料點和輸出資料點!
我查按了很多資料,也沒有確切的定義;按我自己的理解給了個定義:
回歸 是分析研究變數與變數之間的關系的一種行為,也可以說是回歸于事物本來的面目!
一個模型和資料因為回歸的存在,可能達到了一種理想化的擬合狀態,這么說來,回歸就是一種分析手段而已
2、什么是回歸分析?
在統計學中,回歸分析(regression analysis)指的是確定兩種或兩種以上變數間相互依賴的定量關系的一種統計分析方法,
回歸分析按照涉及的變數的多少,分為一元回歸和多元回歸分析;按照因變數的多少,可分為簡單回歸分析和多重回歸分析;按照自變數和因變數之間的關系型別,可分為線性回歸分析和非線性回歸分析,
3、回歸與分類的區別
監督學習中,
- 如果預測的變數是離散的,我們稱其為分類(如決策樹,支持向量機等),
- 如果預測的變數是連續的,我們稱其為回歸,
分類和回歸的區別在于輸出變數的型別:
定量輸出(有大概的結果)稱為回歸,或者說是連續變數預測;
定性輸出(有確定的結果)稱為分類,或者說是離散變數預測,
舉個例子:
預測明天的氣溫是多少度,這是一個回歸任務;
預測明天是陰、晴還是雨,就是一個分類任務,
4、什么是線性回歸
一句話總結:線性回歸就是在N維空間中找一個形式像直線方程一樣的函式來擬合資料而已,找直線的程序就是在做線性回歸!
線性回歸是利用統計中回歸分析,來確定兩種或兩種以上變數間相互依賴的定量關系的一種統計分析方法,其表達形式為y = w'x+e,e為誤差服從均值為0的正態分布
線性模型:在線性回歸中,資料使用線性預測函式來建模,并且未知的模型引數也是通過資料來估計,這些模型被叫做線性模型,
線性回歸是回歸問題中的一種,線性回歸假設目標值與特征之間線性相關,即滿足一個多元一次方程,通過構建損失函式,來求解損失函式最小時的引數w和b,通長我們可以表達成如下公式:
5、 目標/損失函式
求解最佳引數,需要一個標準來對結果進行衡量,為此我們需要定量化一個目標函式式,使得計算機可以在求解程序中不斷地優化, 針對任何模型求解問題,都是最終都是可以得到一組預測值y^ ,對比已有的真實值 y ,資料行數為 n ,可以將損失函式定義如下: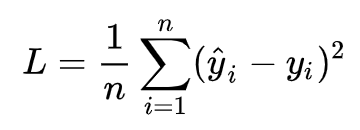 即預測值與真實值之間的平均的平方距離,統計中一般稱其為MAE(mean square error)均方誤差,把之前的函式式代入損失函式,并且將需要求解的引數w和b看做是函式L的自變數,可得
即預測值與真實值之間的平均的平方距離,統計中一般稱其為MAE(mean square error)均方誤差,把之前的函式式代入損失函式,并且將需要求解的引數w和b看做是函式L的自變數,可得
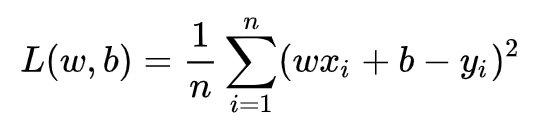 現在的任務是求解最小化L時w和b的值,
即核心目標優化式為
現在的任務是求解最小化L時w和b的值,
即核心目標優化式為
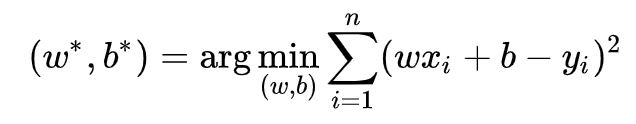 求解方式有兩種:
1)最小二乘法(least square method)
求解 w 和 b 是使損失函式最小化的程序,在統計中,稱為線性回歸模型的最小二乘“引數估計”(parameter estimation),我們可以將 L(w,b) 分別對 w 和 b 求導,得到
求解方式有兩種:
1)最小二乘法(least square method)
求解 w 和 b 是使損失函式最小化的程序,在統計中,稱為線性回歸模型的最小二乘“引數估計”(parameter estimation),我們可以將 L(w,b) 分別對 w 和 b 求導,得到
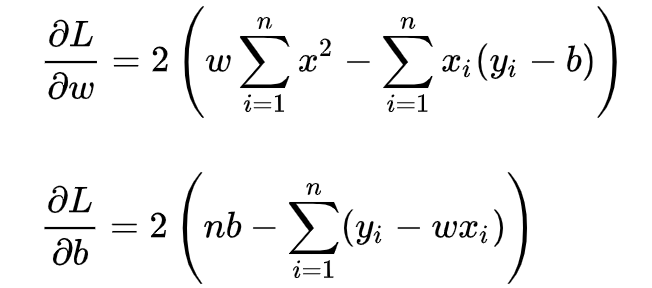 令上述兩式為0,可得到 w 和 b 最優解的閉式(closed-form)解:
令上述兩式為0,可得到 w 和 b 最優解的閉式(closed-form)解:
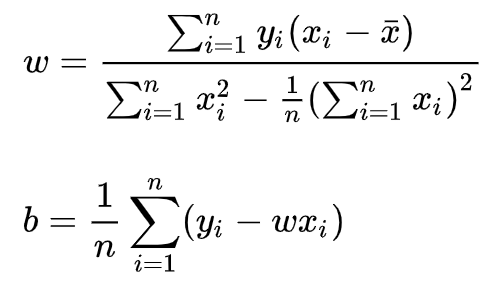 2)梯度下降(gradient descent)
梯度下降核心內容是對自變數進行不斷的更新(針對w和b求偏導),使得目標函式不斷逼近最小值的程序
2)梯度下降(gradient descent)
梯度下降核心內容是對自變數進行不斷的更新(針對w和b求偏導),使得目標函式不斷逼近最小值的程序
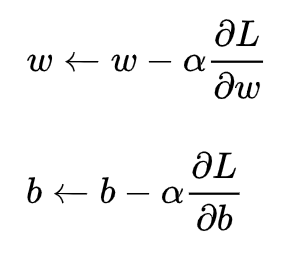
5、線性回歸的代碼實作?
5.1 簡單線性回歸
首先建立linear_regression.py檔案,用于實作線性回歸的類檔案,包含了線性回歸內部的核心函式:

# -*- coding: utf-8 -*- import numpy as np class LinerRegression(object): def __init__(self, learning_rate=0.01, max_iter=100, seed=None): np.random.seed(seed) self.lr = learning_rate self.max_iter = max_iter self.w = np.random.normal(1, 0.1) self.b = np.random.normal(1, 0.1) self.loss_arr = [] def fit(self, x, y): self.x = x self.y = y for i in range(self.max_iter): self._train_step() self.loss_arr.append(self.loss()) # print('loss: \t{:.3}'.format(self.loss())) # print('w: \t{:.3}'.format(self.w)) # print('b: \t{:.3}'.format(self.b)) def _f(self, x, w, b): return x * w + b def predict(self, x=None): if x is None: x = self.x y_pred = self._f(x, self.w, self.b) return y_pred def loss(self, y_true=None, y_pred=None): if y_true is None or y_pred is None: y_true = self.y y_pred = self.predict(self.x) return np.mean((y_true - y_pred)**2) def _calc_gradient(self): d_w = np.mean((self.x * self.w + self.b - self.y) * self.x) d_b = np.mean(self.x * self.w + self.b - self.y) return d_w, d_b def _train_step(self): d_w, d_b = self._calc_gradient() self.w = self.w - self.lr * d_w self.b = self.b - self.lr * d_b return self.w, self.bView Code
建立 train.py 檔案,用于生成模擬資料,并呼叫 liner_regression.py 中的類,完成線性回歸任務:
# -*- coding: utf-8 -*- import numpy as np import matplotlib.pyplot as plt from liner_regression import * def show_data(x, y, w=None, b=None): plt.scatter(x, y, marker='.') if w is not None and b is not None: plt.plot(x, w*x+b, c='red') plt.show() # data generation np.random.seed(272) data_size = 100 x = np.random.uniform(low=1.0, high=10.0, size=data_size) y = x * 20 + 10 + np.random.normal(loc=0.0, scale=10.0, size=data_size) # plt.scatter(x, y, marker='.') # plt.show() # train / test split shuffled_index = np.random.permutation(data_size) x = x[shuffled_index] y = y[shuffled_index] split_index = int(data_size * 0.7) x_train = x[:split_index] y_train = y[:split_index] x_test = x[split_index:] y_test = y[split_index:] # visualize data # plt.scatter(x_train, y_train, marker='.') # plt.show() # plt.scatter(x_test, y_test, marker='.') # plt.show() # train the liner regression model regr = LinerRegression(learning_rate=0.01, max_iter=10, seed=314) regr.fit(x_train, y_train) print('cost: \t{:.3}'.format(regr.loss())) print('w: \t{:.3}'.format(regr.w)) print('b: \t{:.3}'.format(regr.b)) show_data(x, y, regr.w, regr.b) # plot the evolution of cost plt.scatter(np.arange(len(regr.loss_arr)), regr.loss_arr, marker='o', c='green') plt.show()View Code
5.2 sklearn實作
sklearn.linear_model提供了很多線性模型,包括嶺回歸、貝葉斯回歸、Lasso等,本文主要嘗試使用嶺回歸Ridge,該函式一共有8個引數,詳見 https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.Ridge.html 嶺回歸是縮減法的一種,相當于對回歸系數的大小施加了限制,另一種很好的縮減法是lasso,lasso難以求解,但可以使用計算簡便的逐步線性回歸方法求的近似解,
# -*-coding:utf-8 -*- import numpy as np from bs4 import BeautifulSoup import random def scrapePage(retX, retY, inFile, yr, numPce, origPrc): """ 函式說明:從頁面讀取資料,生成retX和retY串列 Parameters: retX - 資料X retY - 資料Y inFile - HTML檔案 yr - 年份 numPce - 樂高部件數目 origPrc - 原價 Returns: 無 """ # 打開并讀取HTML檔案 with open(inFile, encoding='utf-8') as f: html = f.read() soup = BeautifulSoup(html) i = 1 # 根據HTML頁面結構進行決議 currentRow = soup.find_all('table', r = "%d" % i) while(len(currentRow) != 0): currentRow = soup.find_all('table', r = "%d" % i) title = currentRow[0].find_all('a')[1].text lwrTitle = title.lower() # 查找是否有全新標簽 if (lwrTitle.find('new') > -1) or (lwrTitle.find('nisb') > -1): newFlag = 1.0 else: newFlag = 0.0 # 查找是否已經標志出售,我們只收集已出售的資料 soldUnicde = currentRow[0].find_all('td')[3].find_all('span') if len(soldUnicde) == 0: print("商品 #%d 沒有出售" % i) else: # 決議頁面獲取當前價格 soldPrice = currentRow[0].find_all('td')[4] priceStr = soldPrice.text priceStr = priceStr.replace('$','') priceStr = priceStr.replace(',','') if len(soldPrice) > 1: priceStr = priceStr.replace('Free shipping', '') sellingPrice = float(priceStr) # 去掉不完整的套裝價格 if sellingPrice > origPrc * 0.5: print("%d\t%d\t%d\t%f\t%f" % (yr, numPce, newFlag, origPrc, sellingPrice)) retX.append([yr, numPce, newFlag, origPrc]) retY.append(sellingPrice) i += 1 currentRow = soup.find_all('table', r = "%d" % i) def ridgeRegres(xMat, yMat, lam = 0.2): """ 函式說明:嶺回歸 Parameters: xMat - x資料集 yMat - y資料集 lam - 縮減系數 Returns: ws - 回歸系數 """ xTx = xMat.T * xMat denom = xTx + np.eye(np.shape(xMat)[1]) * lam if np.linalg.det(denom) == 0.0: print("矩陣為奇異矩陣,不能求逆") return ws = denom.I * (xMat.T * yMat) return ws def setDataCollect(retX, retY): """ 函式說明:依次讀取六種樂高套裝的資料,并生成資料矩陣 Parameters: 無 Returns: 無 """ scrapePage(retX, retY, './lego/lego8288.html', 2006, 800, 49.99) #2006年的樂高8288,部件數目800,原價49.99 scrapePage(retX, retY, './lego/lego10030.html', 2002, 3096, 269.99) #2002年的樂高10030,部件數目3096,原價269.99 scrapePage(retX, retY, './lego/lego10179.html', 2007, 5195, 499.99) #2007年的樂高10179,部件數目5195,原價499.99 scrapePage(retX, retY, './lego/lego10181.html', 2007, 3428, 199.99) #2007年的樂高10181,部件數目3428,原價199.99 scrapePage(retX, retY, './lego/lego10189.html', 2008, 5922, 299.99) #2008年的樂高10189,部件數目5922,原價299.99 scrapePage(retX, retY, './lego/lego10196.html', 2009, 3263, 249.99) #2009年的樂高10196,部件數目3263,原價249.99 def regularize(xMat, yMat): """ 函式說明:資料標準化 Parameters: xMat - x資料集 yMat - y資料集 Returns: inxMat - 標準化后的x資料集 inyMat - 標準化后的y資料集 """ inxMat = xMat.copy() #資料拷貝 inyMat = yMat.copy() yMean = np.mean(yMat, 0) #行與行操作,求均值 inyMat = yMat - yMean #資料減去均值 inMeans = np.mean(inxMat, 0) #行與行操作,求均值 inVar = np.var(inxMat, 0) #行與行操作,求方差 # print(inxMat) print(inMeans) # print(inVar) inxMat = (inxMat - inMeans) / inVar #資料減去均值除以方差實作標準化 return inxMat, inyMat def rssError(yArr,yHatArr): """ 函式說明:計算平方誤差 Parameters: yArr - 預測值 yHatArr - 真實值 Returns: """ return ((yArr-yHatArr)**2).sum() def standRegres(xArr,yArr): """ 函式說明:計算回歸系數w Parameters: xArr - x資料集 yArr - y資料集 Returns: ws - 回歸系數 """ xMat = np.mat(xArr); yMat = np.mat(yArr).T xTx = xMat.T * xMat #根據文中推導的公示計算回歸系數 if np.linalg.det(xTx) == 0.0: print("矩陣為奇異矩陣,不能求逆") return ws = xTx.I * (xMat.T*yMat) return ws def crossValidation(xArr, yArr, numVal = 10): """ 函式說明:交叉驗證嶺回歸 Parameters: xArr - x資料集 yArr - y資料集 numVal - 交叉驗證次數 Returns: wMat - 回歸系數矩陣 """ m = len(yArr) #統計樣本個數 indexList = list(range(m)) #生成索引值串列 errorMat = np.zeros((numVal,30)) #create error mat 30columns numVal rows for i in range(numVal): #交叉驗證numVal次 trainX = []; trainY = [] #訓練集 testX = []; testY = [] #測驗集 random.shuffle(indexList) #打亂次序 for j in range(m): #劃分資料集:90%訓練集,10%測驗集 if j < m * 0.9: trainX.append(xArr[indexList[j]]) trainY.append(yArr[indexList[j]]) else: testX.append(xArr[indexList[j]]) testY.append(yArr[indexList[j]]) wMat = ridgeTest(trainX, trainY) #獲得30個不同lambda下的嶺回歸系數 for k in range(30): #遍歷所有的嶺回歸系數 matTestX = np.mat(testX); matTrainX = np.mat(trainX) #測驗集 meanTrain = np.mean(matTrainX,0) #測驗集均值 varTrain = np.var(matTrainX,0) #測驗集方差 matTestX = (matTestX - meanTrain) / varTrain #測驗集標準化 yEst = matTestX * np.mat(wMat[k,:]).T + np.mean(trainY) #根據ws預測y值 errorMat[i, k] = rssError(yEst.T.A, np.array(testY)) #統計誤差 meanErrors = np.mean(errorMat,0) #計算每次交叉驗證的平均誤差 minMean = float(min(meanErrors)) #找到最小誤差 bestWeights = wMat[np.nonzero(meanErrors == minMean)] #找到最佳回歸系數 xMat = np.mat(xArr); yMat = np.mat(yArr).T meanX = np.mean(xMat,0); varX = np.var(xMat,0) unReg = bestWeights / varX #資料經過標準化,因此需要還原 print('%f%+f*年份%+f*部件數量%+f*是否為全新%+f*原價' % ((-1 * np.sum(np.multiply(meanX,unReg)) + np.mean(yMat)), unReg[0,0], unReg[0,1], unReg[0,2], unReg[0,3])) def ridgeTest(xArr, yArr): """ 函式說明:嶺回歸測驗 Parameters: xMat - x資料集 yMat - y資料集 Returns: wMat - 回歸系數矩陣 """ xMat = np.mat(xArr); yMat = np.mat(yArr).T #資料標準化 yMean = np.mean(yMat, axis = 0) #行與行操作,求均值 yMat = yMat - yMean #資料減去均值 xMeans = np.mean(xMat, axis = 0) #行與行操作,求均值 xVar = np.var(xMat, axis = 0) #行與行操作,求方差 xMat = (xMat - xMeans) / xVar #資料減去均值除以方差實作標準化 numTestPts = 30 #30個不同的lambda測驗 wMat = np.zeros((numTestPts, np.shape(xMat)[1])) #初始回歸系數矩陣 for i in range(numTestPts): #改變lambda計算回歸系數 ws = ridgeRegres(xMat, yMat, np.exp(i - 10)) #lambda以e的指數變化,最初是一個非常小的數, wMat[i, :] = ws.T #計算回歸系數矩陣 return wMat def useStandRegres(): """ 函式說明:使用簡單的線性回歸 Parameters: 無 Returns: 無 """ lgX = [] lgY = [] setDataCollect(lgX, lgY) data_num, features_num = np.shape(lgX) lgX1 = np.mat(np.ones((data_num, features_num + 1))) lgX1[:, 1:5] = np.mat(lgX) ws = standRegres(lgX1, lgY) print('%f%+f*年份%+f*部件數量%+f*是否為全新%+f*原價' % (ws[0],ws[1],ws[2],ws[3],ws[4])) def usesklearn(): """ 函式說明:使用sklearn Parameters: 無 Returns: 無 """ from sklearn import linear_model reg = linear_model.Ridge(alpha = .5) lgX = [] lgY = [] setDataCollect(lgX, lgY) reg.fit(lgX, lgY) print('%f%+f*年份%+f*部件數量%+f*是否為全新%+f*原價' % (reg.intercept_, reg.coef_[0], reg.coef_[1], reg.coef_[2], reg.coef_[3])) if __name__ == '__main__': usesklearn()View Code
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/252455.html
標籤:Python
上一篇:odoo之技巧合集一