前言??
本文的文字及圖片來源于網路,僅供學習、交流使用,不具有任何商業用途,如有問題請及時聯系我們以作處理,
前文內容??
Python爬蟲入門教程01:豆瓣Top電影爬取
Python爬蟲入門教程02:小說爬取
Python爬蟲入門教程03:二手房資料爬取
Python爬蟲入門教程04:招聘資訊爬取
Python爬蟲入門教程05:B站視頻彈幕的爬取
Python爬蟲入門教程06:爬取資料后的詞云圖制作
PS:如有需要 Python學習資料 以及 解答 的小伙伴可以加點擊下方鏈接自行獲取
python免費學習資料以及群交流解答點擊即可加入
基本開發環境??
- Python 3.6
- Pycharm
相關模塊的使用??
- jieba
- wordcloud
安裝Python并添加到環境變數,pip安裝需要的相關模塊即可,
一、??明確需求
選擇 <歡樂喜劇人 第七季> 爬取網友發送的彈幕資訊

二、??分析網頁資料
復制網頁中的彈幕,再開發者工具里面進行搜索,

這里面就有對應的彈幕資料,這個url地址有一個小特點,鏈接包含著 danmu 所以大膽嘗試一下,過濾搜索一下 danmu 這個關鍵詞,看一下是否有像類似的內容
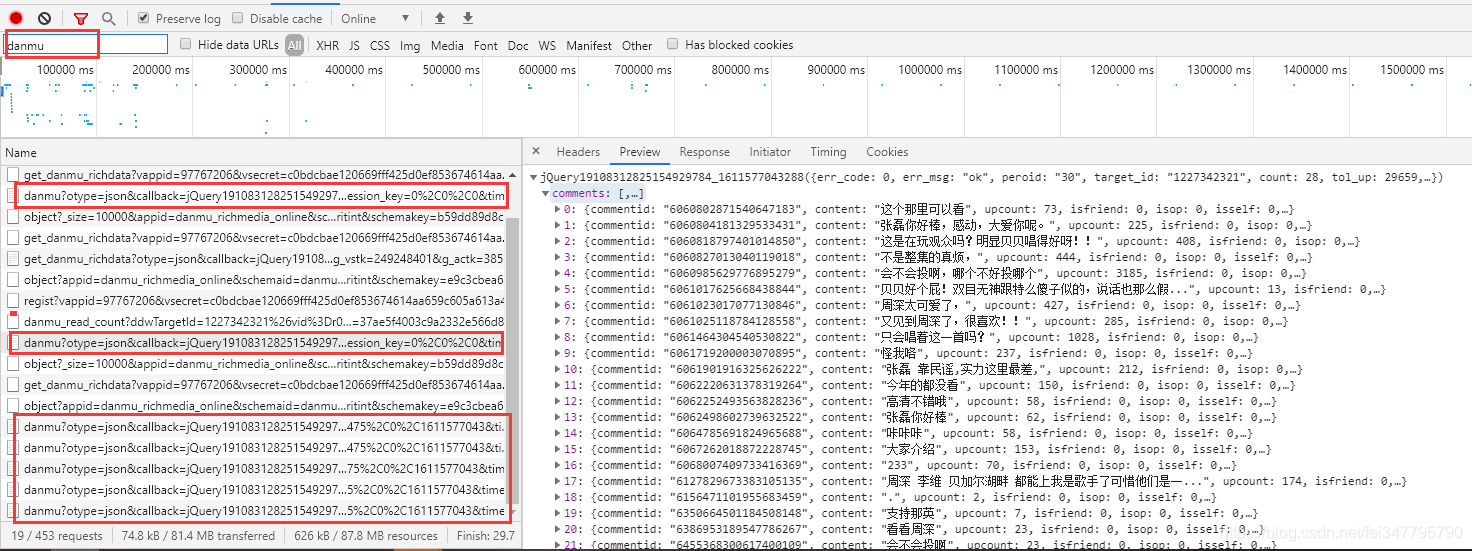
通過鏈接的引數對比,可以看到每個url地址引數的變化

回圈遍歷就可以實作爬取整個視頻的彈幕了,
三、??決議資料

在這里想問一下,你覺得請求這個url地址給你回傳的資料是什么樣的資料?給大家三秒考慮時間,
1 ....2....3...
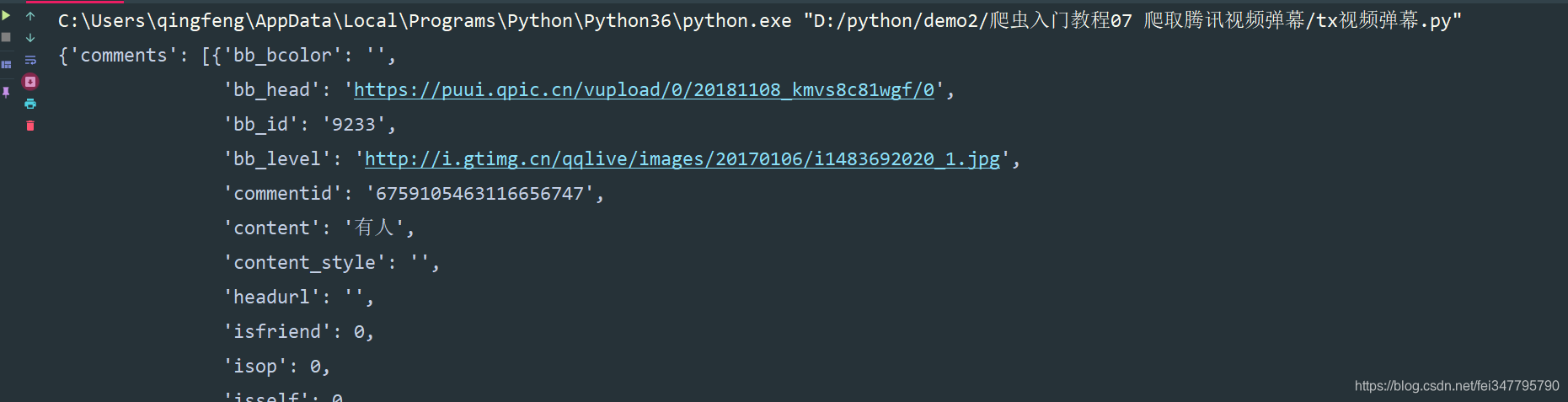
好的,現在公布答案了,它是一個 字串 你沒有聽錯,如果你直接獲取 respons.json() 那你會出現報錯

那如何才能讓它編程json資料呢,畢竟json資料更好提取資料,
??第一種方法

- 正則匹配提取中間的資料部分的資料
- 匯入json模塊,字串轉json資料
import requests
import re
import json
import pprint
url = 'https://mfm.video.qq.com/danmu?otype=json&callback=jQuery19108312825154929784_1611577043265&target_id=6416481842%26vid%3Dt0035rsjty9&session_key=30475%2C0%2C1611577043×tamp=105&_=1611577043296'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
result = re.findall('jQuery19108312825154929784_1611577043265\((.*?)\)', response.text)[0]
json_data = https://www.cnblogs.com/Qqun821460695/p/json.loads(result)
pprint.pprint(json_data)
??第二種方法
洗掉鏈接中的 callback=jQuery19108312825154929784_1611577043265 就可以直接使用 response.json()
import requests
import pprint
url = 'https://mfm.video.qq.com/danmu?otype=json&target_id=6416481842%26vid%3Dt0035rsjty9&session_key=30475%2C0%2C1611577043×tamp=105&_=1611577043296'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
# result = re.findall('jQuery19108312825154929784_1611577043265\((.*?)\)', response.text)[0]
json_data = https://www.cnblogs.com/Qqun821460695/p/response.json()
pprint.pprint(json_data)
這樣也可以,而且可以讓代碼更加簡單,
小知識點:
pprint 是格式化輸出模塊,讓類似json資料輸出的效果更加好看
??完整實作代碼
import requests
for page in range(15, 150, 15):
url = 'https://mfm.video.qq.com/danmu'
params = {
'otype': 'json',
'target_id': '6416481842&vid=t0035rsjty9',
'session_key': '30475,0,1611577043',
'timestamp': page,
'_': '1611577043296',
}
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=url, params=params, headers=headers)
json_data = https://www.cnblogs.com/Qqun821460695/p/response.json()
contents = json_data['comments']
for i in contents:
content = i['content']
with open('喜劇人彈幕.txt', mode='a', encoding='utf-8') as f:
f.write(content)
f.write('\n')
print(content)
代碼還是比較簡單的,沒有什么特別的難度,


轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/252468.html
標籤:Python
上一篇:Python爬蟲新手入門教學(三):爬取鏈家二手房資料
下一篇:智能語音喚醒詞,自學習意義與步驟