爬取酷狗歌曲并進行下載用的是selenuim
1. 請求的url并發起請求
2. 定位元素,回圈遍歷
3. 視窗的轉移
4. 獲取歌曲的下載路徑
5. 保存到指定的檔案里面
6. 總結
開始來看看吧
首先大家還是先導一下包吧,也就那幾個好吧:
不會導包的看下我寫的這篇喲https://blog.csdn.net/XY52wiue/article/details/112975003
import requests
from selenium.webdriver import Chrome,ChromeOptions
import os
import time
一:請求的url并發起請求
我這里直接到音樂里面,這里不涉及登錄,可以不用想那么多,哈哈哈哈,
url = 'https://www.kugou.com/yy/rank/home/1-8888.html?from=homepage'
進行偽裝:
headers = {
"User_Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36"
}
發起請求,并且以utf-8的格式進行讀取資料:
如果有看不懂的,可以看下我前面幾篇文章:
response = requests.get(url=url,headers=headers)
#手動設定回應資料的編碼格式
response.encoding = 'utf-8'
page_text = response.text
#這個就是再后臺上面運行那個瀏覽器,不在表面上占用你的
option = ChromeOptions()
option.add_argument('--headless')
option.add_argument("--no-sandbox")
option.add_experimental_option('excludeSwitches',['enable-automation'])
#這里也要輸入
browser = Chrome(options=option)
browser.get(url)
二:定位元素,并進行回圈遍歷 到了這一步可是重點了
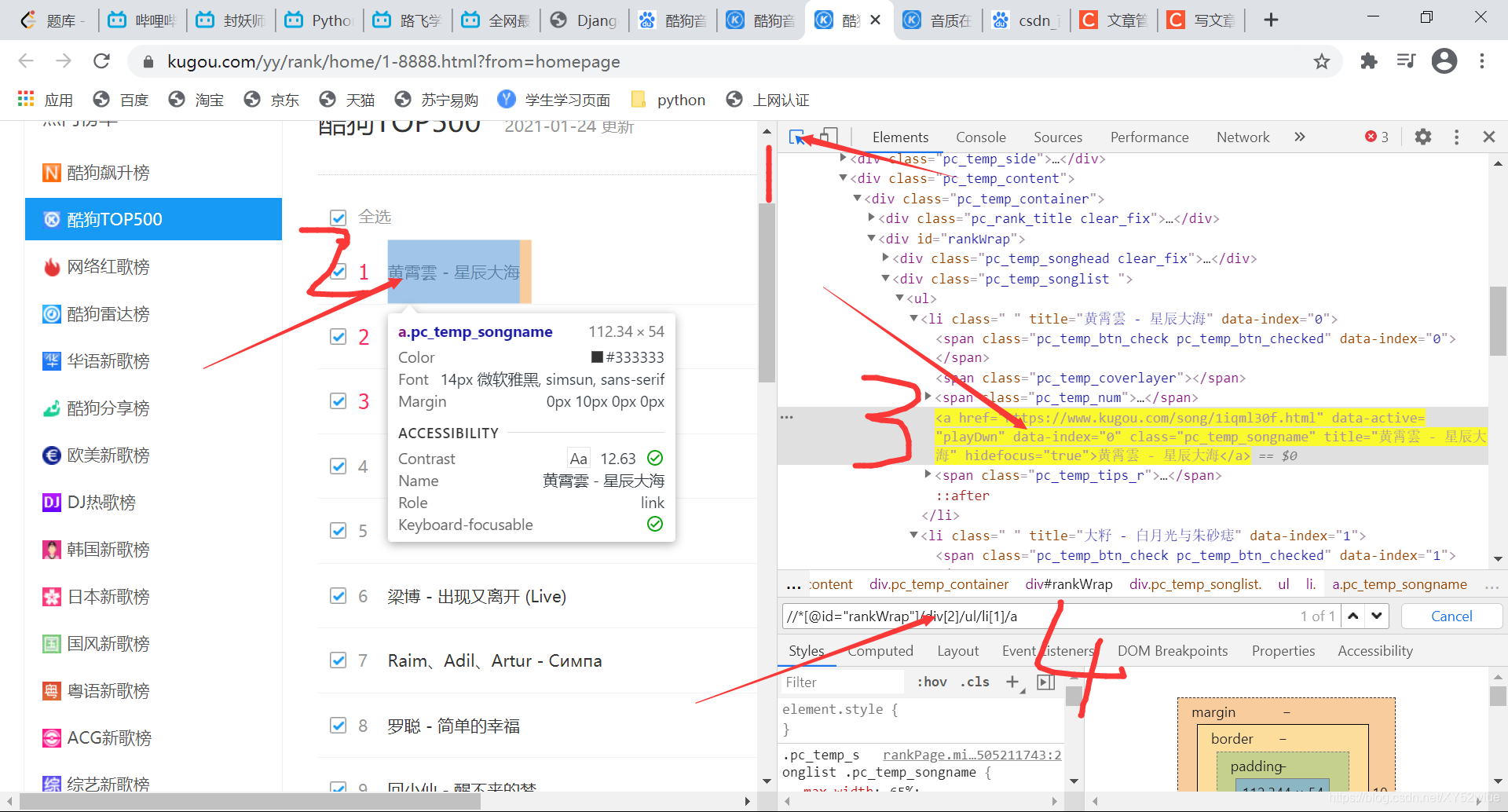
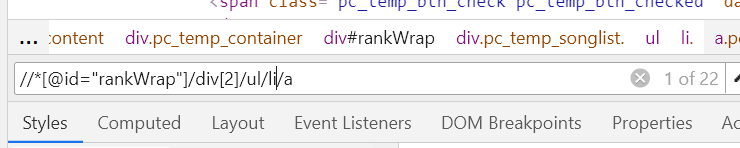
可以看到上圖,大家按著順序走就行,按住crtl+f 出現那個框框,把copy-xpath粘貼s上去,看到是1 of 1 ,這很正常,我們所定位的只有一個元素,要把一頁的資料搜索出來很簡單,把li[1]的[1]去掉就像了,【中括號也要一起去掉】
下面看下代碼:
n = 1 #為后面切換視窗回圈做準備
#把要取的類名統統取出來,找到他,注意是elements,所以不止是一個
li_list = browser.find_elements_by_xpath('//*[@id="rankWrap"]/div[2]/ul/li')
for li in li_list:
browser.switch_to.window(browser.window_handles[-1])
#歌曲名字
li_name = li.find_element_by_xpath('./a').get_attribute('title')
#歌曲的url
li_url = li.find_element_by_xpath('./a').get_attribute('href')
#進行測驗一下,是否走到這一步
print(li_name, li_url)
#點擊標題,跳轉
# 把要取的類名統統取出來,找到他,注意是elements,所以不止是一個
alist = browser.find_elements_by_class_name('pc_temp_songname')
# 因為我們要對這個名字點擊事件,回圈他,在進行點擊
for a in alist:
a.click()
browser.switch_to.window(browser.window_handles[-1])
time.sleep(1)
#歌曲的下載路徑
song = browser.find_element_by_xpath('//*[@id="myAudio"]').get_attribute('src')
#歌曲的名稱
song_name = browser.find_element_by_xpath('/html/body/div[1]/div[3]/div[1]/div[2]/div[1]/span').get_attribute('title')
# print(song)
對于上述注釋不理解的可以評論區問喲
三、視窗的轉移
browser.switch_to.window(browser.window_handles[-1])
#關閉這些視窗
browser.close()
#切換上一個視窗
browser.switch_to.window(browser.window_handles[0])
#進行下一個點擊事件
n += 1
四:獲取下載的路徑
對于新打開的視窗進行獲取下載連接MP3:
找到flash播放插件就可以進行下載:【注意一下,這里如果有視窗彈出來的話不用進行理會,我們不需要點擊什么,只是要一個元素而已,所以不管,】

五、保存到指定的檔案里面:
#創建歌曲的檔案
if not os.path.exists('./音樂'):
os.mkdir('./音樂')
#對新的發起一個請求
song_data = requests.get(url=song, headers=headers).content
song_path = '音樂/' + song_name
#新進去
with open(song_path, 'wb') as fp:
fp.write(song_data)
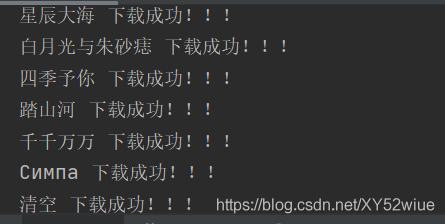
print(song_name, '下載成功!!!')
這里也與我前面幾篇文章一樣就行,
最后進行播放:
from pygame import mixer
import time
#進行初始化
mixer.init()
#獲取路徑
mixer.music.load('E:\python\program1\抓包\音樂\ 星辰大海')
#播放
mixer.music.play()
#播放的時間有多久
time.sleep(1000)
#關閉
mixer.music.stop()
六:總結
這次抓取的時候有個彈窗問題一直困擾我,就是點進歌曲里面要彈出視窗,第一次會出現,但后面再次進入就不會,網上找了很多,沒咋個判斷出來,希望會的小伙伴在評論區告知一下下,好了,隨便下載歌曲都可以了,
結果如下:
點個贊把,親
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/252685.html
標籤:python
上一篇:DW&LeetCode_day14(215、217、230)
下一篇:【Python】給PDF添加水印