引言
本人是只有python語言基礎的小白,進入大學前從未接觸過編程知識,學習的專業也與編程無關,機緣巧合之下,有幸接觸到編程,對其產生濃厚的興趣,并開始學習,
此文旨在記錄生活,總結心得,若有不足之處,歡迎批評指正,
文章目錄
- 引言
- 一、明確目標
- 二、分析程序
- 三、代碼實作
- 四、代碼整合
- 五、更多
一、明確目標
用多協程爬取安客居前十頁的二手房源的名稱,價格,幾房幾廳,大小,建造年份,聯系人,地址,
二、分析程序
1. 首先打開安客居的網站
安客居的url:https://beijing.anjuke.com/sale/
進入網站后按F12進入開發者模式,在network中的Doc中的第0個檔案可以看到我們想要的資訊都在網頁的html中,所以我們可以直接點擊開發者框左上角的一個小箭頭,來查找我們需要的資訊的標簽,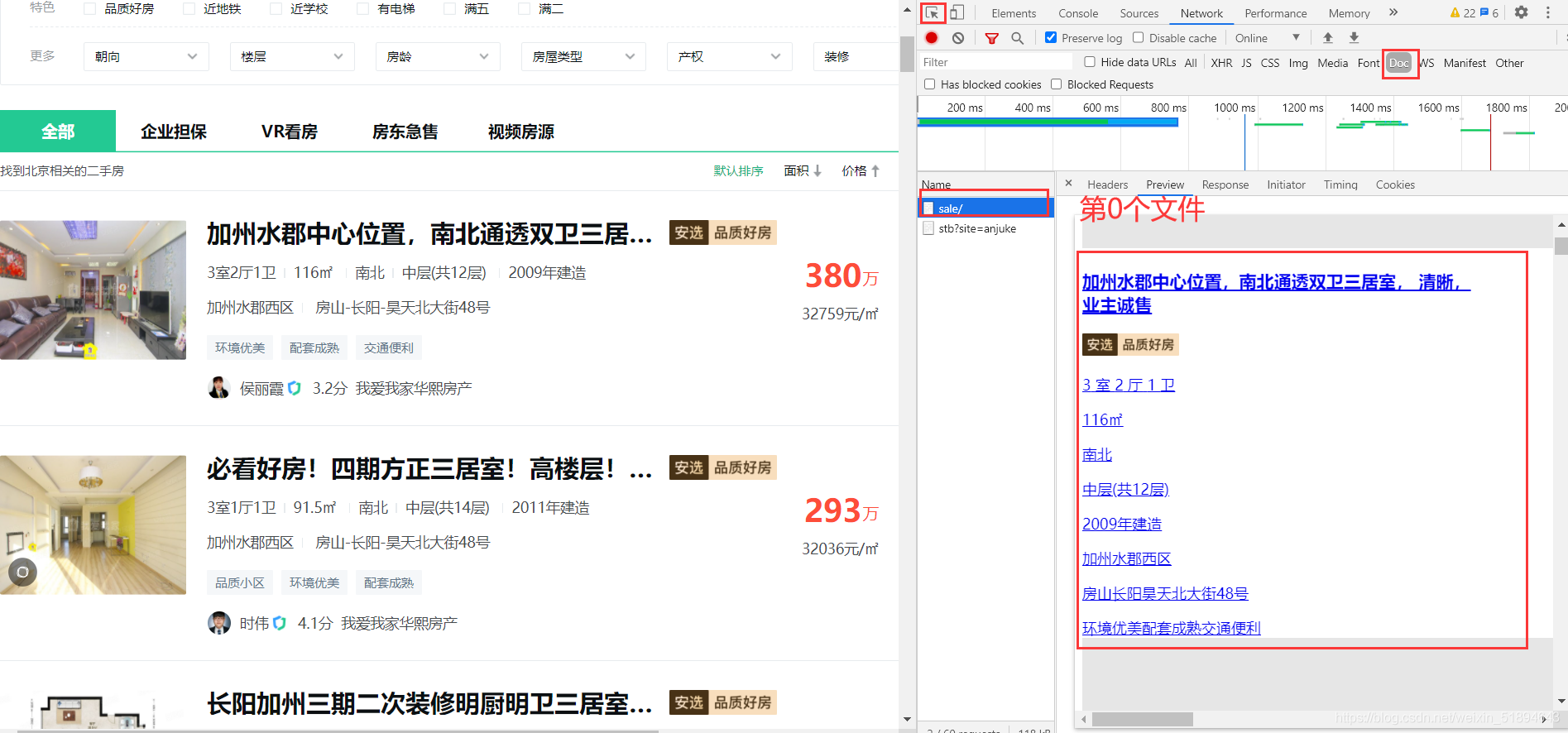
我們需要的每一個資訊的標簽都可以通過以下方式獲取
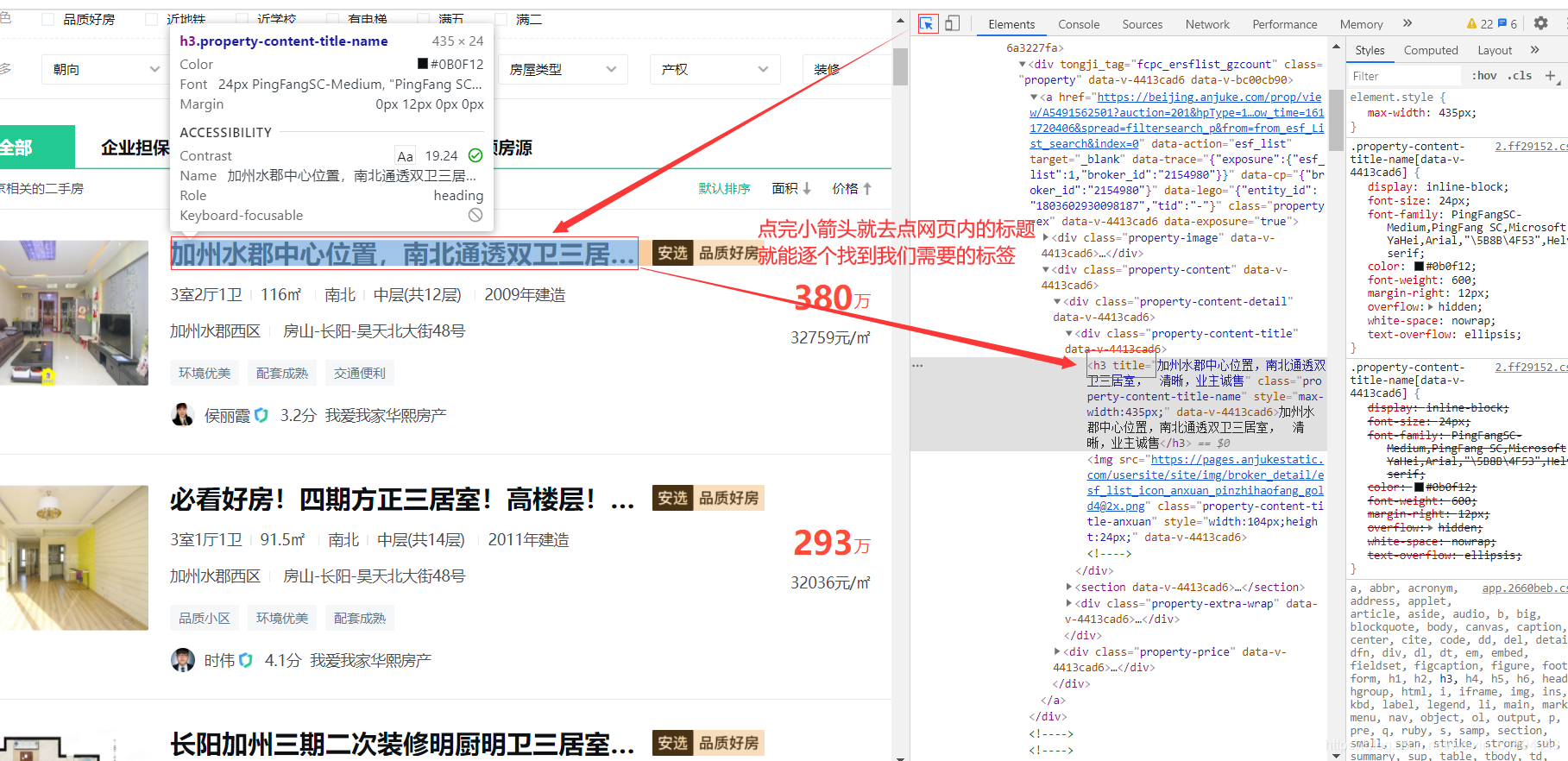
2. 下面接著分析網址
url:https://beijing.anjuke.com/sale/
不難看出,beijing是代表二手房源所在城市,但是我們還需要獲取前十頁的網頁資料,接下來就點開下一頁網址看看有無規律可循
第二頁:https://beijing.anjuke.com/sale/p2/
第三頁:https://beijing.anjuke.com/sale/p3/
第四頁:https://beijing.anjuke.com/sale/p4/
通過觀察前四頁,發先在原本的網址上多了一個p2,p3,p4,可想而知p就是pag的意思,數字則代表相應頁碼
若想獲取前十頁資料則需要在加入一個回圈便能做到,接下來便是代碼實作
三、代碼實作
首先第一步將我們上面需要用到的模塊匯入
from gevent import monkey
monkey.patch_all()
#讓程式變成異步模式,
import random,csv,gevent,time,requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
from gevent.queue import Queue
根據前面分析網址規律,用for回圈構造出前十頁的網址,并將這些網址放進佇列
work = Queue()
# 創建佇列物件,并賦值給work,
for pag in range(10):
# 利用回圈將前十頁的網址獲取到
url_list = 'https://fuzhoushi.anjuke.com/sale/p'+str(pag)
work.put_nowait(url_list)
# 把構造好的網址用put_nowait方法添加進串列里
定義一個爬取網頁的函式,用開發者選項里的小箭頭依次找到二手房源的名稱,價格,幾房幾廳,大小,建造年份,聯系人,地址的標簽,代碼實作如下:
def House_Spider():
# 定義House_Spider函式
house_items = []
# 創建一個空串列,到時候用來裝各個資訊
pagnum = 0
# 頁碼
while not work.empty():
# 當串列不是空的時候,執行下面的程式
pagnum += 1
print('正在爬取第{}頁資料'.format(pagnum))
# 顯示正在爬取的頁碼
url = work.get_nowait()
headers= {'User-Agent':str(UserAgent().random)}
# 隨機獲取請求頭
res = requests.get(url,headers=headers)
# 獲取網頁源代碼
bs =BeautifulSoup(res.text,'html.parser')
# 決議網頁原始碼資料
items = bs.find_all('div',tongji_tag="fcpc_ersflist_gzcount")
# 提取每一個房源的全部資訊
for item in items:
# 遍歷回圈items得到每個房源資訊
title = item.find('h3')['title']
# 房源標題
price = item.find('p',class_="property-price-total").text
# 二手房價格
room_num = item.find('p',class_="property-content-info-text property-content-info-attribute").text
# 房子型號,即幾室幾廳
area = item.find('div',class_="property-content-info").text.strip()[40:50]
# 房子面積
house_age = item.find('div',class_="property-content-info").text.strip()[-7:-1]
#房子建造年份
if house_age[-2:-1] != '年':
house_age = '無'
else:
pass
call_name = item.find('span',class_="property-extra-text").text
# 聯系人
house_addr = item.find('div',class_="property-content-info property-content-info-comm").text
# 房源地址
item1 = [title,room_num,area,price,house_age,call_name,house_addr]
# 將各個資訊放入item1串列中
house_items.append(item1)
# 將每個串列添加到house_items串列中,用于下步存盤
return house_items
#回傳house_items的值
所有資料已經拿到了,接下來就是要將我們拿到的資料存到本地,用csv模塊便能實作,打開的檔案最后一定要記得關閉,
def House_File(house_items):
# 定義一個存盤資料的檔案,并傳入我們要存盤的資料
house_file = open('house_price.csv','w',newline='',encoding='gbk')
# 打開一個名為house_price.csv的檔案(沒有則會創建),w為寫入模式,newline=''區分換行符,encoding='gbk'表示編碼格式
line = ['名稱','房型','面積','價格','建造年份','聯系人','地址']
w = csv.writer(house_file)
# 用csv.writer()函式創建一個w物件
w.writerow(line)
# 在第一行寫入line串列的資訊
for house_item in house_items:
# 用遍歷house_items得到每個房源的資訊
w.writerow(house_item)
# 逐行寫入
house_file.close()
# 關閉檔案
資料和存盤的代碼都搞定,接下來就是啟動整個專案啦!
task_list = []
# 創建一個任務串列
for x in range(5):
# 創建5只爬蟲來為我們服務
task = gevent.spawn(House_Spider,work)
# 創建一個任務task
task_list.append(task)
# 將任務全部匯入任務串列
gevent.joinall(task_list)
# 啟動任務串列內的任務
start = time.time()
# 記錄專案開始時間
print('任務開始'.center(20,'-'))
# 程式開始
house_items = House_Spider()
# 提取資料,決議資料,篩選拿到想要的資料
House_File(house_items)
# 將資料存盤到本地
end = time.time()
# 記錄結束時間
print('任務完成'.center(20,'-'))
# 程式結束
print('共耗時:{:.2f}秒'.format(end-start).center(20,'-'))
# 列印共消耗的時間
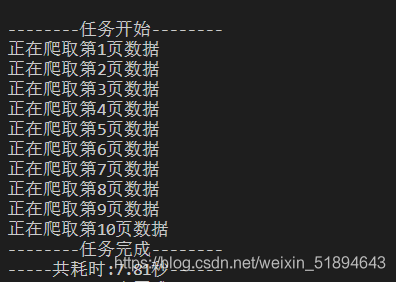
最后運行的結果為:
四、代碼整合
#獲取前十頁的二手房源的 名稱 價格 幾房幾廳 大小 建造年份 聯系人 地址 標簽
# url : https://fuzhoushi.anjuke.com/sale/
from gevent import monkey
monkey.patch_all()
import random,csv,gevent,time
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
from gevent.queue import Queue
work = Queue()
# 創建佇列物件,并賦值給work,
for pag in range(10):
# 利用回圈將前十頁的網址獲取到
url_list = 'https://fuzhoushi.anjuke.com/sale/p'+str(pag)
work.put_nowait(url_list)
# 把構造好的網址用put_nowait方法添加進串列里
def House_Spider():
# 定義House_Spider函式
house_items = []
# 創建一個空串列,到時候用來裝各個資訊
pagnum = 0
# 頁碼
while not work.empty():
# 當串列不是空的時候,執行下面的程式
pagnum += 1
print('正在爬取第{}頁資料'.format(pagnum))
# 顯示正在爬取的頁碼
url = work.get_nowait()
headers= {'User-Agent':str(UserAgent().random)}
# 隨機獲取請求頭
res = requests.get(url,headers=headers)
# 獲取網頁源代碼
bs =BeautifulSoup(res.text,'html.parser')
# 決議網頁原始碼資料
items = bs.find_all('div',tongji_tag="fcpc_ersflist_gzcount")
# 提取每一個房源的全部資訊
for item in items:
# 遍歷回圈items得到每個房源資訊
title = item.find('h3')['title']
# 房源標題
price = item.find('p',class_="property-price-total").text
# 二手房價格
room_num = item.find('p',class_="property-content-info-text property-content-info-attribute").text
# 房子型號,即幾室幾廳
area = item.find('div',class_="property-content-info").text.strip()[40:50]
# 房子面積
house_age = item.find('div',class_="property-content-info").text.strip()[-7:-1]
#房子建造年份
if house_age[-2:-1] != '年':
house_age = '無'
else:
pass
call_name = item.find('span',class_="property-extra-text").text
# 聯系人
house_addr = item.find('div',class_="property-content-info property-content-info-comm").text
# 房源地址
item1 = [title,room_num,area,price,house_age,call_name,house_addr]
# 將各個資訊放入item1串列中
house_items.append(item1)
# 將每個串列添加到house_items串列中,用于下步存盤
return house_items
def House_File(house_items):
# 定義一個存盤資料的檔案,并傳入我們要存盤的資料
house_file = open('house_price.csv','w',newline='',encoding='gbk')
# 打開一個名為house_price.csv的檔案(沒有則會創建),w為寫入模式,newline=''區分換行符,encoding='gbk'表示編碼格式
line = ['名稱','房型','面積','價格','建造年份','聯系人','地址']
w = csv.writer(house_file)
# 用csv.writer()函式創建一個w物件
w.writerow(line)
# 在第一行寫入line串列的資訊
for house_item in house_items:
# 用遍歷house_items得到每個房源的資訊
w.writerow(house_item)
# 逐行寫入
house_file.close()
# 關閉檔案
task_list = []
# 創建一個任務串列
for x in range(5):
# 創建5只爬蟲來為我們服務
task = gevent.spawn(House_Spider,work)
# 創建一個任務task
task_list.append(task)
# 將任務全部匯入任務串列
gevent.joinall(task_list)
# 啟動任務串列內的任務
start = time.time()
# 記錄專案開始時間
print('任務開始'.center(20,'-'))
# 程式開始
house_items = House_Spider()
# 提取資料,決議資料,篩選拿到想要的資料
House_File(house_items)
# 將資料存盤到本地
end = time.time()
# 記錄結束時間
print('任務完成'.center(20,'-'))
# 程式結束
print('共耗時:{:.2f}秒'.format(end-start).center(20,'-'))
# 列印共消耗的時間
五、更多
還有很多地方可以改進,比如可以用一個input來替代網頁中的beijing,可以搜索自己想搜索的城市等等,
雖然東西不多,但剛開始學習,以后也會慢慢的多寫一點,希望能和大家一起進步~
我也只是個菜鳥,文中錯誤的地方,歡迎拍磚~
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/253489.html
標籤:python