面試主要分為兩塊: -塊是考查工程師對基礎知識(包括了技術廣度、深度、對技術的熱情度等)的掌握程度,因為基礎知識決定了一個技術人員發展的上限;另一塊是考察工程師的工程能,力,比如:做過哪些專案?遇到最難的問題怎樣解決的?說說最有成就感的一項任務?工程能力考察工程師當下能為公司帶來的利益,
其它考核方面:抗壓性、合作能..暫且不說,Java只是一-門語言,即使是Java工程師也不能局限于Java,要從面向物件語言本身,甚至從整個計算機體系,從工程實際出發看Java, 很多知識在一般公司的開發中是用不到的,常有人戲稱:“面試造火箭, 作業擰螺絲”,但這只是通常情況下公司對程式員的標準一迅速產出,完成任務,
個人觀點:工程師為了自己職業的發展不能局限于公司對自己的要求,不能停留在應用層面,要能夠很好地掌味訓礎知識,要多看原始碼,自己多實踐,學成記得產出,比如多為開源社區貢獻代碼,幫助初學者指路等, 有沒有發現一個有意思的事情:“面試造火箭, 作業擰螺絲”的背后其實是考察者內心深處普遍都認可基礎知識的重要性(這-點僅為個人觀點, 不展開講哈), 下面為拼多多、餓了么、螞蟻金服、哈噦出行、攜程、餓了么、2345、 百度等公司給我留下較深印象的一些java面試題 1. private修飾的方法可以通過反射訪問,那么private的意 義是什么
2. Java類初始化順序
3.對方法區和永久區的理解以及它們之間的關系
4.一個java檔案有3個類,編譯后有幾個class檔案
5.區域變數使用前需要顯式地賦值,否則編譯通過不了 ,為什么這么設計
6. ReadWriteLock讀寫之間互斥嗎
7. Semaphore拿到執行權的執行緒之間是否互斥
8.寫一個你認為最好的單例模式
9. B樹和B +樹是解決什么樣的問題的,怎樣演化過來,之間區別
10.寫一個生產者消費者模式
11.寫一個死鎖
12. cpu 100%怎樣定位
13. Stringa = "ab"; Stringb= "a" + "b";a == b是否相等,為什么
14. inta= 1;是原子性操作嗎
15.可以用for回圈直接洗掉ArrayList的特定元素嗎?可能會出現什么問題?怎樣解決
16.新的任務提交到執行緒池,執行緒池是怎樣處理
17. AQS和CAS原理
18. synchronized底層實作原理
19. volatile作用,指令重排相關
20. AOP和IOC原理
21. Spring怎樣解決回圈依賴的問題
22. dispatchServlet怎樣分發任務的
23. mysq|給離散度低的欄位建立索引會出現什么問題,具體說下原因 其它經常問的HashMap底層實作原理,常規的多執行緒問題考的太多了,沒什么新意就不寫了 平時不能光抱著應用Java的目的去學習,要深入了解每個知識點背后底層實作原理,為什么這么設計,比如問爛的HashMap既然有hash進行排位還需要equals0作用是什么?就這個問題照樣能問倒一些人,所以一定要摳細節,真的把每個知識點搞懂 以下為解答大綱,部分作了擴展 1.這題是一道思想題目,天天會碰到private,有沒有想過這個問題?談談對java設計的認識程度,主要抓住兩點:
1.java的private修飾符并不是為 了絕對安全性設計的,更多是對用戶常規使用java的一種約束; 2.從外部對物件進行常規呼叫時,能夠看到清晰的類結構,2.先說結論:基類靜態代碼塊, 基類靜態成員欄位(并列優先級,按照代碼中出現的先后順序執行,且職有第一次加載時執行) 一> 派生類靜態代碼塊,派生類靜態成員欄位(并列優先級,按照代碼中出現的先后順序執行,且職有第一次加載時執行)一>基類普通代碼塊, 基類普通成員欄位(并列優點級,按代碼中出現先后順序執行)一->基類建構式一-> 派生 類普通代碼塊,派生類普通成員欄位(并列優點級,按代碼中出現先后順序執行)一> 派生類建構式 代碼驗證:

 控制臺結果輸出:
控制臺結果輸出:
 3.方法區是jvm規范里要求的,永久區是Hotspot虛擬機對方法區的具體實作,前者是規范,儲實作方式,jdk1.8作 了改變,本題看看對方在思想層面對jvm的理解程度,很基礎的一個題目,
4.檔案中有幾個類編譯后就有幾個class檔案,
5.成員變數是可以不經初始化的,在類加載程序的準備階段即可給它賦予默認值,但區域變數使用前需要顯式賦予初始值,javac不是推斷不出不可以這樣做,而是沒有這樣做,對于成員變數而言,其賦值和取值訪問的先后順序具有不確定性,對于成員變數可以在一個方法呼叫前賦值,也可以在方法呼叫后進行,這是運行時發生的,編譯器確定不了,交給jvm去做比較合適,而對于區域變數而言,其賦值和取值訪問順序是確定的,這樣設計是-種約束, 盡最大程度減少使用者犯錯的可能
(假使區域變數可以使用默認值,可能總會無意間忘記賦值,進而導致不可預期的情況出現)
6. ReadWriteRock讀寫鎖,使用場景可分為讀/讀、讀/寫、寫/寫,除了讀和讀之間是共享的,其它都是互斥的,接著會討論下怎樣實作互斥鎖和同步鎖的,想了解對方對AQS, CAS的掌握程度,技術學習的深度,
7. Semaphore拿到執行權的執行緒之間是否互斥,Semaphore、 CountDownL atch、CyclicBarrier、Exchanger 為java并發編程的4個輔助類,面試中常問的CountDownLatchCyclicBarrier之間的區別,面試者肯定是經常碰到的,所以問起來意 義不大,Semaphore問的相對少一些,有些知識點如果沒有使用過還是會忽略,Semaphore可有 多把鎖,可允許多個執行緒同時擁有執行權,這些有執行權的執行緒如并發訪問同-物件,會產生執行緒安全問題,
8.寫一個你認為最好的單例模式,這題面試者都可能遇到過, 也算是作業中最常遇到的設計模式之一,想考察面試者對經常碰到的題目的理解深度,單例一共有幾種實作方式:餓漢、懶漢、靜態內部類、列舉、雙檢鎖,要是寫了簡單的懶漢式可能就會問:要是多執行緒情況下怎樣保證執行緒安全呢,面試者可能說雙檢鎖,那么聊聊為什么要兩次校驗,接著會問光是雙檢鎖還會有什么問題,這時候基礎好的面試者就會說了:物件在定義的時候加上volatile關鍵字,接下來會繼續引申討論下原子性和可見性、java記憶體模型、類的加載程序,
其實沒有最好,列舉方式、靜態內部類、雙檢鎖都是可以的,就想聽下對不同的單例寫法認識程度,寫個雙檢鎖的方式吧:
3.方法區是jvm規范里要求的,永久區是Hotspot虛擬機對方法區的具體實作,前者是規范,儲實作方式,jdk1.8作 了改變,本題看看對方在思想層面對jvm的理解程度,很基礎的一個題目,
4.檔案中有幾個類編譯后就有幾個class檔案,
5.成員變數是可以不經初始化的,在類加載程序的準備階段即可給它賦予默認值,但區域變數使用前需要顯式賦予初始值,javac不是推斷不出不可以這樣做,而是沒有這樣做,對于成員變數而言,其賦值和取值訪問的先后順序具有不確定性,對于成員變數可以在一個方法呼叫前賦值,也可以在方法呼叫后進行,這是運行時發生的,編譯器確定不了,交給jvm去做比較合適,而對于區域變數而言,其賦值和取值訪問順序是確定的,這樣設計是-種約束, 盡最大程度減少使用者犯錯的可能
(假使區域變數可以使用默認值,可能總會無意間忘記賦值,進而導致不可預期的情況出現)
6. ReadWriteRock讀寫鎖,使用場景可分為讀/讀、讀/寫、寫/寫,除了讀和讀之間是共享的,其它都是互斥的,接著會討論下怎樣實作互斥鎖和同步鎖的,想了解對方對AQS, CAS的掌握程度,技術學習的深度,
7. Semaphore拿到執行權的執行緒之間是否互斥,Semaphore、 CountDownL atch、CyclicBarrier、Exchanger 為java并發編程的4個輔助類,面試中常問的CountDownLatchCyclicBarrier之間的區別,面試者肯定是經常碰到的,所以問起來意 義不大,Semaphore問的相對少一些,有些知識點如果沒有使用過還是會忽略,Semaphore可有 多把鎖,可允許多個執行緒同時擁有執行權,這些有執行權的執行緒如并發訪問同-物件,會產生執行緒安全問題,
8.寫一個你認為最好的單例模式,這題面試者都可能遇到過, 也算是作業中最常遇到的設計模式之一,想考察面試者對經常碰到的題目的理解深度,單例一共有幾種實作方式:餓漢、懶漢、靜態內部類、列舉、雙檢鎖,要是寫了簡單的懶漢式可能就會問:要是多執行緒情況下怎樣保證執行緒安全呢,面試者可能說雙檢鎖,那么聊聊為什么要兩次校驗,接著會問光是雙檢鎖還會有什么問題,這時候基礎好的面試者就會說了:物件在定義的時候加上volatile關鍵字,接下來會繼續引申討論下原子性和可見性、java記憶體模型、類的加載程序,
其實沒有最好,列舉方式、靜態內部類、雙檢鎖都是可以的,就想聽下對不同的單例寫法認識程度,寫個雙檢鎖的方式吧:
 9. B樹和B+樹,這題既問mysq|索弓的實作原理,也間資料結構基礎,首先從二叉樹說起,因為會產生退化現象,提出了平衡二叉樹,再提出怎樣讓每一層放的節點多-些來減少遍歷高度,引申出m叉樹,m叉搜索樹同樣會有退化現象,引出m叉平衡樹,也就是B樹,這時候每個節點既放了key也放了value,怎樣使每個節點放盡可能多的key值,以減少遍歷高度呢(訪問磁盤次數),可以將每個節點只放key值,將value值放在葉子結點,在葉子結點的value值增加指向相鄰節點指標,這就是優化后的B +樹,然后談談資料庫
索弓|失效的情況,為什么給離散度低的欄位(如性別)建立索引是不可取的,查詢資料反而更慢,如果將離散度高的欄位和性別建立聯合索引會怎樣,有什么需要注意的?
10.生產者消費者模式,synchronized鎖住一 個LinkedList, -一個生產者,只要佇列不滿,生產后往里放,一個消費者只要佇列不空,向外取,兩者通過wait(和notify0進行協調, 寫好了會問怎樣提高效率,最后會聊一聊訊息佇列設計精要思想及其使用,
11.寫一個死鎖,覺得這個問題真的很不錯, 經常說的死鎖四個條件,背都能背上,那寫一個看看,思想為:定義兩個ArrayList,將他們都加上鎖A,B,執行緒1,2, 1拿住了鎖A,請求鎖B, 2拿住了鎖B請求鎖A,在等待對方釋放鎖的程序中誰也不讓出已獲得的鎖,
9. B樹和B+樹,這題既問mysq|索弓的實作原理,也間資料結構基礎,首先從二叉樹說起,因為會產生退化現象,提出了平衡二叉樹,再提出怎樣讓每一層放的節點多-些來減少遍歷高度,引申出m叉樹,m叉搜索樹同樣會有退化現象,引出m叉平衡樹,也就是B樹,這時候每個節點既放了key也放了value,怎樣使每個節點放盡可能多的key值,以減少遍歷高度呢(訪問磁盤次數),可以將每個節點只放key值,將value值放在葉子結點,在葉子結點的value值增加指向相鄰節點指標,這就是優化后的B +樹,然后談談資料庫
索弓|失效的情況,為什么給離散度低的欄位(如性別)建立索引是不可取的,查詢資料反而更慢,如果將離散度高的欄位和性別建立聯合索引會怎樣,有什么需要注意的?
10.生產者消費者模式,synchronized鎖住一 個LinkedList, -一個生產者,只要佇列不滿,生產后往里放,一個消費者只要佇列不空,向外取,兩者通過wait(和notify0進行協調, 寫好了會問怎樣提高效率,最后會聊一聊訊息佇列設計精要思想及其使用,
11.寫一個死鎖,覺得這個問題真的很不錯, 經常說的死鎖四個條件,背都能背上,那寫一個看看,思想為:定義兩個ArrayList,將他們都加上鎖A,B,執行緒1,2, 1拿住了鎖A,請求鎖B, 2拿住了鎖B請求鎖A,在等待對方釋放鎖的程序中誰也不讓出已獲得的鎖,

 12. cpu 100%怎樣定位,這題是一個應用性題目, 網上搜一下即可, 比較常見,說實話,把這題放進來有點后悔,
13. Stringa= "ab"; Stringb= "a"+ "b";a, b是相等的(各位要寫代碼驗證-下,我看到有人寫了錯誤答案),常規的問法是new-一個物件賦給變數,問:這行運算式創建了幾個物件,但這樣的題目太常見,
14. inta= 1;是原子性操作,
15. for回圈直接洗掉ArrayList中的特定元素是錯的,不同的for回圈會發生不同的錯誤,泛型for會拋出ConcurrentModificationException,普通的for想要洗掉集合中重復且連續的元素,只能洗掉第一個,
錯誤原因:打開JDK的ArrayList原始碼, 看下ArrayList中的remove方法(注意ArrayList中的remove有兩個同名方法,只是入參不同,這里看的是入參為Object的remove方法)是怎么實作的,一般情況下程式的執行路徑會走到else路徑下最終呼叫faseRemove方法,會執行System.arraycopy方法,導致洗掉元素時涉及到陣列元素的移動,針對普通for回圈的錯誤寫法,在遍歷第一個字串b時因為符合洗掉條件,所以將該元素從陣列中洗掉,并且將后-個元素移動(也就是第二個字串b)至當前位置,導致下一次回圈遍歷時后一個字串b并沒有遍歷到,所以無法洗掉,針對這種情況可以倒序洗掉的方式來避免
解決方案:用Iterator,
12. cpu 100%怎樣定位,這題是一個應用性題目, 網上搜一下即可, 比較常見,說實話,把這題放進來有點后悔,
13. Stringa= "ab"; Stringb= "a"+ "b";a, b是相等的(各位要寫代碼驗證-下,我看到有人寫了錯誤答案),常規的問法是new-一個物件賦給變數,問:這行運算式創建了幾個物件,但這樣的題目太常見,
14. inta= 1;是原子性操作,
15. for回圈直接洗掉ArrayList中的特定元素是錯的,不同的for回圈會發生不同的錯誤,泛型for會拋出ConcurrentModificationException,普通的for想要洗掉集合中重復且連續的元素,只能洗掉第一個,
錯誤原因:打開JDK的ArrayList原始碼, 看下ArrayList中的remove方法(注意ArrayList中的remove有兩個同名方法,只是入參不同,這里看的是入參為Object的remove方法)是怎么實作的,一般情況下程式的執行路徑會走到else路徑下最終呼叫faseRemove方法,會執行System.arraycopy方法,導致洗掉元素時涉及到陣列元素的移動,針對普通for回圈的錯誤寫法,在遍歷第一個字串b時因為符合洗掉條件,所以將該元素從陣列中洗掉,并且將后-個元素移動(也就是第二個字串b)至當前位置,導致下一次回圈遍歷時后一個字串b并沒有遍歷到,所以無法洗掉,針對這種情況可以倒序洗掉的方式來避免
解決方案:用Iterator,
 將本問題擴展一下,下面的代碼可能會出現什么問題?
將本問題擴展一下,下面的代碼可能會出現什么問題?
 16.第一-步: 執行緒池判斷核心執行緒池里的執行緒是否都在執行任務,如果不是,則創建一一個新的作業執行緒來執行任務,如果核心執行緒池里的執行緒都在執行任務,則執行第二步,
第二步:執行緒池判斷作業佇列是否已經滿,如果作業佇列沒有滿,則將新提交的任務存盤在這個作業佇列里進行等待,如果作業佇列滿了,則執行第三步,
第三步:執行緒池判斷執行緒池的執行緒是否都處于作業狀態,如果沒有,則創建一個新的作業執行緒來執行任務,如果已經滿了,則交給飽和策略來處理這個任務,
17.抽象佇列同步器AQS (AbstractQueuedSychronizer) ,如果說java.util.concurrent的基礎是CAS的話,那么AQS就是整個Java并發包的核心了,ReentrantLock、 CountDownLatch、Semaphore等都用到了它,AQS實際上以雙向佇列的形式連接所有的Entry,比方說ReentrantLock,所有等待的執行緒都被放在-個Entry中并連成雙向佇列,前面一個執行緒使用ReentrantLock好了,則雙向佇列實際上的第一個Entry開始運行, AQS定 義了對雙向佇列所有的操作,而只開放了tryLock和tryRelease方法給開發者使用,開發者可以根據自己的實作重寫tryLock和tryRelease方法,以實作自己的并發功能,
比較并替換CAS(Compare and Swap),假設有三個運算元:記憶體值V、舊的預期值A、要修改的值B,當且僅當預期值A和記憶體值V相同時,才會將記憶體值修改為B并回傳true,否則什么都不做并回傳false,整個比較并替換的操作是一個原子操作, CAS- 定要volatile變 量配合,這樣才能保證每次拿到的變數是主記憶體中最新的相應值,否則舊的預期值A對某條執行緒來說,永遠是一個不會變的值A,只要某次CAS操作失敗,下面永遠都不可能成功,CAS雖然比較高效的解決了原子操作問題,但仍存在三大問題,
●回圈時間長開銷很大,, 只能保證-個共享變數的原子操作,
●ABA問題,
18. synchronized (this)原理:涉及兩條指令: monitorenter, monitorexit; 再說同步方法,從同步方法反編譯的結果來看,方法的同步并沒有通過指令monitorenter和monitorexit來實作,相對于普通方法,其常量池中多了'ACC_ SYNCHRONIZED標示符,
JVM就是根據該標示符來實作方法的同步的:當方法被呼叫時,呼叫指令將會檢查方法的ACC_ SYNCHRONIZED訪問標志是否被設定,如果設定了,執行執行緒將先獲取monitor,獲取成功之后才能執行方法體,方法執行完后再釋放monitor,在方法執行期間,其他任何執行緒都無法再獲得同一個monitor物件,
這個問題會接著追問: java物件頭資訊,偏向鎖,輕量鎖,重量級鎖及其他們相互間轉化,
19.理解volatile關鍵字的作用的前提是要理解Java記憶體模型,voltile關鍵字的作用主 要有兩點:多執行緒主要圍繞可見性和原子性兩個特性而展開,使用volatile關鍵字修飾的變數,保證了其在多執行緒之間的可見性,即每次讀取到volatile變數,一定是最新的資料
●代碼底層執行不像我們看到的高級語言一Java程式這么簡單, 它的執行是Java代碼- >位元組碼->根據位元組碼執行對應的C/C + +代碼- >C/C+ +代碼被編譯成匯編語言- > 和硬體電路互動,現實中,為了獲取更好的性能JVM可能會對指令進行重排序,多執行緒下可能會出現- -些意想不到的問題,使用volatile則會對禁止語意重排序,當然這也一定程度上降低了代碼執行效率
從實踐角度而言,volatile的一 個重要作用就是和CAS結合,保證了原子性,詳細的可以參見java.util.concurrent.atomic包下的類,比如AtomiclInteger,
20. AOP和I0C是Spring精華部分,AOP可以看 做是對OOP的補充,對代碼進行橫向的擴展,通過代理模式實作,代理模式有靜態代理,動態代理,Spring利用的是動態代理,在程式運行程序中將增強代碼織入原代碼中,I0C是控制反轉,將物件的控制權交給Spring框架,用戶需要使用物件無需創建,直接使用即可,AOP和IOC最可貴的是它們的思想,
21.什么是回圈依賴,怎樣檢測出回圈依賴,Spring回圈依賴有幾種方式,使用基于setter屬 性的回圈依賴為什么不會出現問題,接下來會問: Bean的生命周期,
22.上一張圖,從這張圖去理解
16.第一-步: 執行緒池判斷核心執行緒池里的執行緒是否都在執行任務,如果不是,則創建一一個新的作業執行緒來執行任務,如果核心執行緒池里的執行緒都在執行任務,則執行第二步,
第二步:執行緒池判斷作業佇列是否已經滿,如果作業佇列沒有滿,則將新提交的任務存盤在這個作業佇列里進行等待,如果作業佇列滿了,則執行第三步,
第三步:執行緒池判斷執行緒池的執行緒是否都處于作業狀態,如果沒有,則創建一個新的作業執行緒來執行任務,如果已經滿了,則交給飽和策略來處理這個任務,
17.抽象佇列同步器AQS (AbstractQueuedSychronizer) ,如果說java.util.concurrent的基礎是CAS的話,那么AQS就是整個Java并發包的核心了,ReentrantLock、 CountDownLatch、Semaphore等都用到了它,AQS實際上以雙向佇列的形式連接所有的Entry,比方說ReentrantLock,所有等待的執行緒都被放在-個Entry中并連成雙向佇列,前面一個執行緒使用ReentrantLock好了,則雙向佇列實際上的第一個Entry開始運行, AQS定 義了對雙向佇列所有的操作,而只開放了tryLock和tryRelease方法給開發者使用,開發者可以根據自己的實作重寫tryLock和tryRelease方法,以實作自己的并發功能,
比較并替換CAS(Compare and Swap),假設有三個運算元:記憶體值V、舊的預期值A、要修改的值B,當且僅當預期值A和記憶體值V相同時,才會將記憶體值修改為B并回傳true,否則什么都不做并回傳false,整個比較并替換的操作是一個原子操作, CAS- 定要volatile變 量配合,這樣才能保證每次拿到的變數是主記憶體中最新的相應值,否則舊的預期值A對某條執行緒來說,永遠是一個不會變的值A,只要某次CAS操作失敗,下面永遠都不可能成功,CAS雖然比較高效的解決了原子操作問題,但仍存在三大問題,
●回圈時間長開銷很大,, 只能保證-個共享變數的原子操作,
●ABA問題,
18. synchronized (this)原理:涉及兩條指令: monitorenter, monitorexit; 再說同步方法,從同步方法反編譯的結果來看,方法的同步并沒有通過指令monitorenter和monitorexit來實作,相對于普通方法,其常量池中多了'ACC_ SYNCHRONIZED標示符,
JVM就是根據該標示符來實作方法的同步的:當方法被呼叫時,呼叫指令將會檢查方法的ACC_ SYNCHRONIZED訪問標志是否被設定,如果設定了,執行執行緒將先獲取monitor,獲取成功之后才能執行方法體,方法執行完后再釋放monitor,在方法執行期間,其他任何執行緒都無法再獲得同一個monitor物件,
這個問題會接著追問: java物件頭資訊,偏向鎖,輕量鎖,重量級鎖及其他們相互間轉化,
19.理解volatile關鍵字的作用的前提是要理解Java記憶體模型,voltile關鍵字的作用主 要有兩點:多執行緒主要圍繞可見性和原子性兩個特性而展開,使用volatile關鍵字修飾的變數,保證了其在多執行緒之間的可見性,即每次讀取到volatile變數,一定是最新的資料
●代碼底層執行不像我們看到的高級語言一Java程式這么簡單, 它的執行是Java代碼- >位元組碼->根據位元組碼執行對應的C/C + +代碼- >C/C+ +代碼被編譯成匯編語言- > 和硬體電路互動,現實中,為了獲取更好的性能JVM可能會對指令進行重排序,多執行緒下可能會出現- -些意想不到的問題,使用volatile則會對禁止語意重排序,當然這也一定程度上降低了代碼執行效率
從實踐角度而言,volatile的一 個重要作用就是和CAS結合,保證了原子性,詳細的可以參見java.util.concurrent.atomic包下的類,比如AtomiclInteger,
20. AOP和I0C是Spring精華部分,AOP可以看 做是對OOP的補充,對代碼進行橫向的擴展,通過代理模式實作,代理模式有靜態代理,動態代理,Spring利用的是動態代理,在程式運行程序中將增強代碼織入原代碼中,I0C是控制反轉,將物件的控制權交給Spring框架,用戶需要使用物件無需創建,直接使用即可,AOP和IOC最可貴的是它們的思想,
21.什么是回圈依賴,怎樣檢測出回圈依賴,Spring回圈依賴有幾種方式,使用基于setter屬 性的回圈依賴為什么不會出現問題,接下來會問: Bean的生命周期,
22.上一張圖,從這張圖去理解
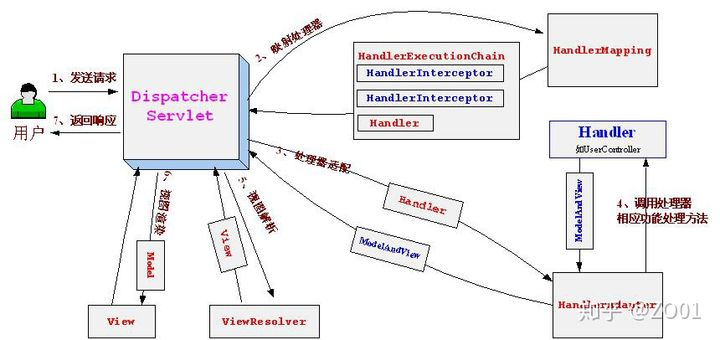 具體流程:
1) .用戶發請求--> DispatcherServlet, 前端控制器收到請求后自己不進行處理, 而是委托給其他的決議器進行處理,作為統- -訪問點, 進行全域的流程控制,
2) .DispatcherServlet--> HandlerMapping, HandlerMapping將會把請求映射為HandlerExecutionChain物件(包含一個Handler處理器,多個HandlerInterceptor攔截器),
3) .DispatcherServlet--> HandlerAdapter,HandlerAdapter將會把處理器包裝為配接器,從而支持多種型別的處理器,
4) .HandlerAdapter-->處理器功能處理方法的呼叫,HandlerAdapter將會根據適配的結果呼叫真正的處理器的功能處理方法,完成功能處理,并回傳- -個ModelAndView物件(包含模型資料,邏輯視圖名)
5) .ModelAndView的邏輯視圖名--> ViewResolver, ViewResoler將把邏 輯視圖名決議為具體的View,
6) .View-->渲染, View會根據傳進來的Model模型資料進行渲染,此處的Model實際是一個Map資料結構
7) .回傳控制權給DispatcherServlet, 由DispatcherServlet回傳回應給用戶,
23.先上結論:重復性較強的欄位,不適合添加索引,mysq|給離散度低的欄位,比如性別設定索引,再以性別作為條件進行查詢反而會更慢,
一個表可能會涉及兩個資料結構(檔案),一個是表本身,存放表中的資料,另- -個是索引,索引是什么?它就是把一個或幾個欄位(組合索引)按規律排列起來,再附上該欄位所在行資料的物理地址(位于表中),比如我們有個欄位是年齡,如果要選取某個年齡段的所有行,那么一般情況下可能需要進行一次全表掃描,但如果以這個年齡段建個索引,那么索引中會按年齡值根據特定資料結構建一個排列,這樣在索引中就能迅速定位,不需要進行全表掃描,為什么性別不適合建索弓|呢?
因為訪問索弓l需要付出額外的IO開銷,從索弓|中拿到的只是地址,要想真正訪問到資料還是要對表進行一次IO,假如你要從表的100萬行資料中取幾個資料,那么利用索引迅速定位,訪問索弓|的這10開銷就非常值了,但如果是從100萬行資料中取50萬行資料,就比如性別欄位,那你相對需要訪問50萬次索引,再訪問50萬次表,加起來的開銷并不會比直接對表進行一次完整打 描小,當然如果把性別欄位設為表的聚集索引,那么就肯定能加快大約一半該欄位的查詢速度了,聚集索引指的是表本身資料按哪個欄位的值來進行排序,因此,聚集索引只能有一個,而且使用聚集索引不會付出額外O開銷,當然你得能舍得把聚集索弓|這么寶貴資源用到性別欄位上,
可以根據業務場景需要,將性別和其它欄位建立聯合索引,比如時間戳,但是建立索弓|記得把時間戳欄位放在性別前面,
具體流程:
1) .用戶發請求--> DispatcherServlet, 前端控制器收到請求后自己不進行處理, 而是委托給其他的決議器進行處理,作為統- -訪問點, 進行全域的流程控制,
2) .DispatcherServlet--> HandlerMapping, HandlerMapping將會把請求映射為HandlerExecutionChain物件(包含一個Handler處理器,多個HandlerInterceptor攔截器),
3) .DispatcherServlet--> HandlerAdapter,HandlerAdapter將會把處理器包裝為配接器,從而支持多種型別的處理器,
4) .HandlerAdapter-->處理器功能處理方法的呼叫,HandlerAdapter將會根據適配的結果呼叫真正的處理器的功能處理方法,完成功能處理,并回傳- -個ModelAndView物件(包含模型資料,邏輯視圖名)
5) .ModelAndView的邏輯視圖名--> ViewResolver, ViewResoler將把邏 輯視圖名決議為具體的View,
6) .View-->渲染, View會根據傳進來的Model模型資料進行渲染,此處的Model實際是一個Map資料結構
7) .回傳控制權給DispatcherServlet, 由DispatcherServlet回傳回應給用戶,
23.先上結論:重復性較強的欄位,不適合添加索引,mysq|給離散度低的欄位,比如性別設定索引,再以性別作為條件進行查詢反而會更慢,
一個表可能會涉及兩個資料結構(檔案),一個是表本身,存放表中的資料,另- -個是索引,索引是什么?它就是把一個或幾個欄位(組合索引)按規律排列起來,再附上該欄位所在行資料的物理地址(位于表中),比如我們有個欄位是年齡,如果要選取某個年齡段的所有行,那么一般情況下可能需要進行一次全表掃描,但如果以這個年齡段建個索引,那么索引中會按年齡值根據特定資料結構建一個排列,這樣在索引中就能迅速定位,不需要進行全表掃描,為什么性別不適合建索弓|呢?
因為訪問索弓l需要付出額外的IO開銷,從索弓|中拿到的只是地址,要想真正訪問到資料還是要對表進行一次IO,假如你要從表的100萬行資料中取幾個資料,那么利用索引迅速定位,訪問索弓|的這10開銷就非常值了,但如果是從100萬行資料中取50萬行資料,就比如性別欄位,那你相對需要訪問50萬次索引,再訪問50萬次表,加起來的開銷并不會比直接對表進行一次完整打 描小,當然如果把性別欄位設為表的聚集索引,那么就肯定能加快大約一半該欄位的查詢速度了,聚集索引指的是表本身資料按哪個欄位的值來進行排序,因此,聚集索引只能有一個,而且使用聚集索引不會付出額外O開銷,當然你得能舍得把聚集索弓|這么寶貴資源用到性別欄位上,
可以根據業務場景需要,將性別和其它欄位建立聯合索引,比如時間戳,但是建立索弓|記得把時間戳欄位放在性別前面,
有完整的Java初級,高級對應的學習路線和資料!專注于java開發,分享java基礎、原理性知識、JavaWeb實戰、spring全家桶、設計模式、分布式及面試資料、開源專案,助力開發者成長!
歡迎關注微信公眾號:碼邦主

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/253800.html
標籤:Java