GET + 字典傳參:
代碼:


import urllib.request import urllib.parse import string def get_params(): url = "http://www.baidu.com/s?wd=" params = { "wd": "中文", "key": "zhang", "value": "san", } str_params = urllib.parse.urlencode(params) print(str_params) final_url = url + str_params #講帶有中文的url轉義成計算機可以識別的URL end_url = urllib.parse.quote(final_url, safe=string.printable) response = urllib.request.urlopen(end_url) data = response.read().decode("utf-8") print(data) get_params()GET + params + 字典
回傳結果:

GET傳參:
(1)漢字報錯:
解釋器ascii沒有漢字,url漢字轉碼
urllib.parse.quote(params, safe=string.printable)

(2)字典傳參:
urllib.parse.urlencode()
注:
POST請求:
urllib.request.urlopen(url, data=https://www.cnblogs.com/3cH0-Nu1L/archive/2021/01/29/"服務器接收的資料")
hander:
User-Agent:
(1)模擬真實的瀏覽器發送請求:百度批量搜索,檢察元素
(2)request.add_header()動態添加head資料
(3)回應頭:response.header
(4)創建request:urllib.request.Request(url)
Test(回應頭):
代碼:
import urllib.request
def load_baidu():
url = "http://www.baidu.com/"
response = urllib.request.urlopen(url)
print(response)
#回應頭
print(response.headers)
load_baidu()
回應頭
回傳:
E:\python\python.exe H:/code/Python爬蟲/Day02/02-request_header.py
<http.client.HTTPResponse object at 0x000001F64CC88CA0>
Bdpagetype: 1
Bdqid: 0x9829fa7c000a56cf
Cache-Control: private
Content-Type: text/html;charset=utf-8
Date: Tue, 26 Jan 2021 06:35:11 GMT
Expires: Tue, 26 Jan 2021 06:34:11 GMT
P3p: CP=" OTI DSP COR IVA OUR IND COM "
P3p: CP=" OTI DSP COR IVA OUR IND COM "
Server: BWS/1.1
Set-Cookie: BAIDUID=A276C955F91E3B32F4D56ADC1EE37C59:FG=1; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Set-Cookie: BIDUPSID=A276C955F91E3B32F4D56ADC1EE37C59; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Set-Cookie: PSTM=1611642911; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com
Set-Cookie: BAIDUID=A276C955F91E3B3283913B84A5B12CFA:FG=1; max-age=31536000; expires=Wed, 26-Jan-22 06:35:11 GMT; domain=.baidu.com; path=/; version=1; comment=bd
Set-Cookie: BDSVRTM=0; path=/
Set-Cookie: BD_HOME=1; path=/
Set-Cookie: H_PS_PSSID=33425_33507_33437_33257_33273_31253_33395_33398_33321_33265; path=/; domain=.baidu.com
Traceid: 1611642911060665933810964570178293749455
Vary: Accept-Encoding
Vary: Accept-Encoding
X-Ua-Compatible: IE=Edge,chrome=1
Connection: close
Transfer-Encoding: chunked
Process finished with exit code 0
View Code
Test(獲取請求頭資訊):
import urllib.request def load_baidu(): url = "http://www.baidu.com/" #創建請求物件 request = urllib.request.Request(url) #請求網路資料 response = urllib.request.urlopen(request) #print(response) data = response.read().decode("utf-8") #回應頭 #print(response.headers) #獲取請求頭的資訊 request_header = request.headers print(request_header) with open("02header.html", "w")as f: f.write(data) load_baidu()獲取請求頭的資訊

Test(添加請求頭資訊):
代碼1:
法一:自行獲取
回傳1:
E:\python\python.exe H:/code/Python爬蟲/Day02/03-request_header_two.py
{'User-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36', '3ch0 - nu1l': 's1mpL3'}
Process finished with exit code 0
View Code
代碼2:
import urllib.request
def load_baidu():
url = "http://www.baidu.com/"
header = {
#瀏覽器版本
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36",
"3cH0 - Nu1L": "s1mpL3",
}
#創建請求物件
request = urllib.request.Request(url, headers=header)
#請求網路資料(不在此處增加請求頭資訊,因為此方法系統沒有提供引數)
response = urllib.request.urlopen(request)
data = response.read().decode("utf-8")
#獲取請求頭的資訊(所有頭的資訊)
#request_headers = request.headers
#print(request_headers)
#第二種方式列印headers資訊
request_headers = request.get_header("User-agent")
print(request_headers)
with open("02header.html", "w")as f:
f.write(data)
load_baidu()
法二:內置函式獲取
回傳2:
E:\python\python.exe H:/code/Python爬蟲/Day02/03-request_header_two.py
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36
Process finished with exit code 0
View Code
注1:
對比兩次回傳值:
使用內置函式時,不回傳字典中的"3cH0 - Nu1L": "s1mpL3",
自行獲取時則都回傳
注2:
 中首字母要大寫(其余均小寫),若改為小寫,則回傳值為None
中首字母要大寫(其余均小寫),若改為小寫,則回傳值為None
代碼:
import urllib.request
def load_baidu():
url = "http://www.baidu.com/"
header = {
#瀏覽器版本
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36",
"3cH0 - Nu1L": "s1mpL3",
}
#創建請求物件
request = urllib.request.Request(url, headers=header)
#請求網路資料(不在此處增加請求頭資訊,因為此方法系統沒有提供引數)
response = urllib.request.urlopen(request)
data = response.read().decode("utf-8")
#獲取請求頭的資訊(所有頭的資訊)
#request_headers = request.headers
#print(request_headers)
#第二種方式列印headers資訊
request_headers = request.get_header("user-agent")
print(request_headers)
with open("02header.html", "w")as f:
f.write(data)
load_baidu()
View Code
回傳:
E:\python\python.exe H:/code/Python爬蟲/Day02/03-request_header_two.py
None
Process finished with exit code 0
View Code
Test(動態添加Header資訊):
代碼:
import urllib.request
def load_baidu():
url = "http://www.baidu.com/"
header = {
# 瀏覽器版本
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36",
"3cH0 - Nu1L": "s1mpL3",
}
#創建請求物件
request = urllib.request.Request(url)
#動態添加hander資訊
request.add_header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36")
#請求網路資料
response = urllib.request.urlopen(request)
#print(response)
data = response.read().decode("utf-8")
#回應頭
#print(response.headers)
#獲取請求頭的資訊
request_header = request.headers
print(request_header)
with open("02header.html", "w")as f:
f.write(data)
load_baidu()
View Code
回傳:
E:\python\python.exe H:/code/Python爬蟲/Day02/03-request_header_two.py
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36
Process finished with exit code 0
View Code
Test(獲取完整的url):
代碼:
import urllib.request
def load_baidu():
url = "http://www.baidu.com/"
header = {
# 瀏覽器版本
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36",
"3cH0 - Nu1L": "s1mpL3",
}
#創建請求物件
request = urllib.request.Request(url)
#動態添加hander資訊
request.add_header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.104 Safari/537.36")
#請求網路資料
response = urllib.request.urlopen(request)
#print(response)
data = response.read().decode("utf-8")
#獲取完整的url
final_url = request.get_full_url()
print(final_url)
load_baidu()
View Code
回傳:

Test(隨機user-agent):
需要多份user-agent(網上搜索user-agent大全即可)
代碼:
import urllib.request
import random
def load_baidu():
url = "http://www.baidu.com"
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:6.0) Gecko/20100101 Firefox/6.0",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50",
"Opera/9.80 (Windows NT 6.1; U; zh-cn) Presto/2.9.168 Version/11.50",
]
#每次請求的瀏覽器都是不一樣的
random_user_agent = random.choice(user_agent_list)
request = urllib.request.Request(url)
#增加對應的回應頭(user-agent)
request.add_header("User-Agent", random_user_agent)
#請求資料
response = urllib.request.urlopen(request)
#獲取請求頭的資訊
print(request.get_header("User-agent"))
load_baidu()
View Code
回傳:
具有隨機性




IP代理:
(1)免費IP:時效性差,錯誤率高
(2)付費IP:也存在失效的
IP分類:
透明IP:
對方知道我們的真實IP
匿名IP:
對方不知道我們的真實IP,知道我們使用了代理
高匿IP:
既不知道真實IP,也不知道使用了代理
handler:
系統的urlopen()不支持代理的添加
創建對應的處理器(handler)
- 代理處理器:ProxyHandler
- 用ProxyHandler創建openner:build_openner()
- openner.open(url)就可以請求資料
Test(HTTPHandler):
代碼:
import urllib.request
def handler_openner():
#系統的urlopen沒有添加代理的功能,需要我們自定義該功能
#安全 套接層 ssl第三方的CA數字證書
#http:80
#https:443
#urlopen為什么可以請求資料:
#①handler處理器,
#②自己的openner請求資料
url = "https://www.cnblogs.com/3cH0-Nu1L/"
#創建自己的處理器
handler = urllib.request.HTTPHandler
#創建自己的oppener
openner = urllib.request.build_opener(handler)
#用自己創建的openner呼叫open方法請求資料
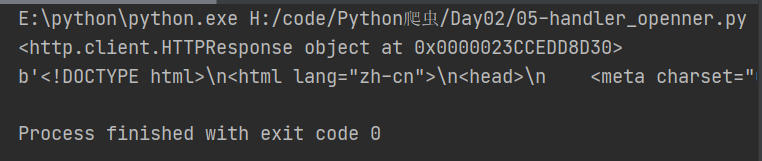
response = openner.open(url)
data = response.read()
print(response)
print(data)
handler_openner()
handler_openner
回傳:
注:
HTTPHandler()不可以增加代理
Test(使用代理IP_免費IP):
代碼:
import urllib.request
def create_proxy_handler():
url = "https://www.cnblogs.com/3cH0-Nu1L/"
#添加代理
proxy = {
#免費的寫法
"http": "104.131.109.66:8080"
}
#代理處理器
proxy_handler = urllib.request.ProxyHandler(proxy)
#創建自己的openner
openner = urllib.request.build_opener(proxy_handler)
#拿著代理IP發送請求
data = openner.open(url).read()
print(data)
create_proxy_handler()
Proxy_handler
回傳:

Test(隨機創建):
代碼:
import urllib.request
def proxy_user():
proxy_list = [
{"http": "104.131.109.66:8080"},
{"http": "88.198.24.108:8080"},
{"http": "96.113.165.182:3128"},
{"http": "117.185.17.151:80"},
{"http": "112.30.164.18:80"},
]
for proxy in proxy_list:
print(proxy)
#利用遍歷出來的IP創建處理器
proxy_handler = urllib.request.ProxyHandler(proxy)
#創建openner
openner = urllib.request.build_opener(proxy_handler)
try:
openner.open("http://www.baidu.com", timeout=1)
print("s1mpL3")
except Exception as e:
print(e)
proxy_user()
View Code
回傳:
E:\python\python.exe H:/code/Python爬蟲/Day02/07-random-user-proxy.py
{'http': '104.131.109.66:8080'}
s1mpL3
{'http': '88.198.24.108:8080'}
<urlopen error timed out>
{'http': '96.113.165.182:3128'}
s1mpL3
{'http': '117.185.17.151:80'}
s1mpL3
{'http': '112.30.164.18:80'}
<urlopen error timed out>
Process finished with exit code 0
View Code
Test(使用代理IP_付費IP):
代碼:
import urllib.request
import requests
#付費代理發送
#1.用戶名密碼(帶著)
#通過驗證的處理起來發送
def money_proxy_user():
#1.代理IP
money_proxy = {
"http": "username:[email protected]:8080"
}
#2.代理的處理器
proxy_handler = urllib.request.ProxyHandler(money_proxy)
#3.通過處理器創建openner
openner = urllib.request.build_opener(proxy_handler)
#4.open發送請求
openner.open("http://www.baidu.com/")
money_proxy_user()
方式一
import urllib.request
import requests
#付費代理發送
#1.用戶名密碼(帶著)
#通過驗證的處理起來發送
def money_proxy_user():
# 第二種方式發送付費的IP地址
user_name = "abcname"
passwd = "123456"
proxy_money = "123.158.62.120:8080"
# 2.創建密碼管理器,添加用戶名和密碼
password_manager = urllib.request.HTTPPasswordMgrWithDefaultRealm()
#uri定位 uri > url
#url:資源定位符
password_manager.add_password(None, proxy_money, user_name, passwd)
# 3.創建可以驗證代理IP的處理器
handler_auth_proxy = urllib.request.ProxyBasicAuthHandler(password_manager)
# 4.根據處理器創建openner
openner_auth = urllib.request.build_opener(handler_auth_proxy)
# 5.發送請求
response = openner_auth.open("http:www.baidu.com")
print(response.read())
money_proxy_user()
方式二
Auth認證:
爬取自己網站的資料進行分析,類似使用付費代理IP的程序,
Test:
代碼:
import urllib.request
def auth_neiwang():
# 1.用戶名密碼
user = "admin"
password ="admin123"
nei_url = "http://192.168.179.66"
# 2.創建密碼管理器
pwd_manager = urllib.request.HTTPPasswordMgrWithDefaultRealm()
pwd_manager.add_password(None, nei_url, user, password)
# 3.創建認證處理器(requests)
auth_handler = urllib.request.HTTPBasicAuthHandler(pwd_manager)
openner = urllib.request.build_opener(auth_handler)
response = openner.open(nei_url)
print(response)
auth_neiwang()
View Code
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/254321.html
標籤:其他