前言
本文的文字及圖片來源于網路,僅供學習、交流使用,不具有任何商業用途,如有問題請及時聯系我們以作處理,
Python爬蟲、資料分析、網站開發等案例教程視頻免費在線觀看
https://space.bilibili.com/523606542

前文內容
Python爬蟲新手入門教學(一):爬取豆瓣電影排行資訊
Python爬蟲新手入門教學(二):爬取小說
Python爬蟲新手入門教學(三):爬取鏈家二手房資料
Python爬蟲新手入門教學(四):爬取前程無憂招聘資訊
Python爬蟲新手入門教學(五):爬取B站視頻彈幕
Python爬蟲新手入門教學(六):制作詞云圖
Python爬蟲新手入門教學(七):爬取騰訊視頻彈幕
Python爬蟲新手入門教學(八):爬取論壇文章保存成PDF
Python爬蟲新手入門教學(九):多執行緒爬蟲案例講解
基本開發環境
- Python 3.6
- Pycharm
相關模塊的使用
- re
- requests
安裝Python并添加到環境變數,pip安裝需要的相關模塊即可,
一、明確需求
彼岸的壁紙,在我覺得是真的好看,雖然可以免費下載,但是對于有條件的小伙伴,還是可以支持一下付費的,畢竟不貴,只需要30元就可以全站無限制下載了,

二、網頁資料分析
一步一步點擊圖片進去可以發現詳情頁的url地址是有由 圖片ID 以及 圖片解析度 組成,

再次點擊,之后可以看到圖片的真實地址,如果你只是想要找一張壁紙圖片的話,這樣保存圖片之后就高清的壁紙了,

如果是要爬取圖片的話,在詳情頁的中是有圖片鏈接的,

所以只需要在串列頁中,獲取圖片的 ID 就可以了,因為我們爬取的本身就是 1920*1080的解析度,所以這個解析度的是固定的,只要獲取 圖片ID然后拼接url就可以了,
這里需要注意一個問題:
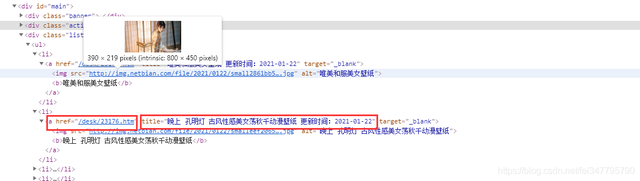
每頁的資料當中,是有兩個我們不需要的內容,
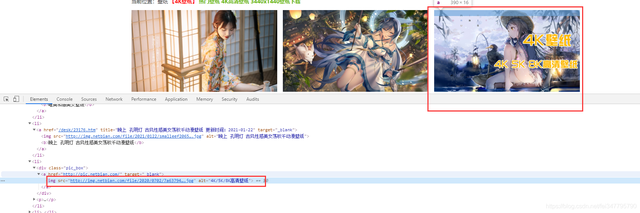
我們所需要的資料是附帶 標題的,不需要的則是沒有標題,所以可以根據這個進行一個判斷,
三、代碼實作
獲取網頁資料
def get_response(html_url): """獲取網頁資料""" headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36' } response = requests.get(url=html_url, headers=headers) return response
獲取每張壁紙的ID
def main(html_url): """獲取圖片ID""" response = get_response(html_url) selector = parsel.Selector(response.text) image_info = selector.css('.list ul li') for link in image_info: image_title = link.css('a::attr(title)').get() # 進行簡單的判斷,如果有標題就獲取ID if image_title: id_info = link.css('a::attr(href)').get() # /desk/23177.htm image_id = id_info.replace('.htm', '').split('/')[-1]
獲取每張壁紙的url地址
def get_image_url(image_id): """獲取圖片的真實url地址""" page_url = f'http://www.netbian.com/desk/{image_id}-1920x1080.htm' response = get_response(page_url) selector = parsel.Selector(response.text) image_url = selector.css('#endimg a::attr(href)').get() return image_url
保存壁紙
def save(image_url, title): filename = 'images\\' + title + '.jpg' image_content = get_response(image_url).content with open(filename, mode='wb') as f: f.write(image_content) print('正在保存:', title)
當我寫完代碼,運行的時候發現了一個問題
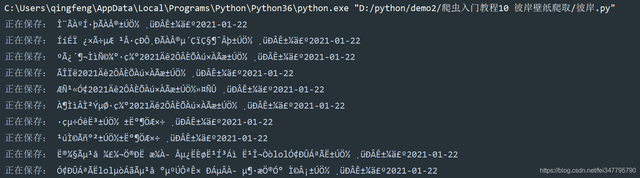

圖片是能保存下來,但是它亂碼了,所以需要在獲取網頁資料的函式里面加一行代碼
# 萬能的轉碼方式 response.encoding = response.apparent_encoding
更新代碼之后,標題變成了中文了,但是又出現新的問題了
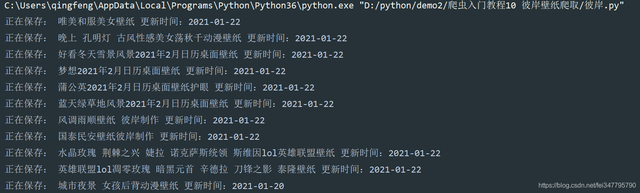
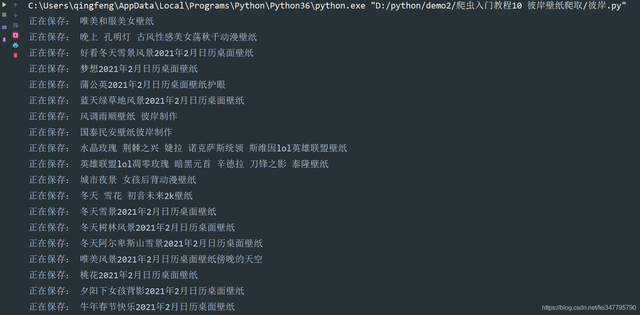
每個標題后面都是帶有 更新時間的,回傳網頁看一下源代碼,

a 標簽里面的 title 屬性里面是帶有更新時間,img標簽里面的alt屬性是沒有更新時間的,所以我們要重新提取一下標題資料,
更改后:
def main(html_url): """獲取圖片ID""" response = get_response(html_url) selector = parsel.Selector(response.text) image_info = selector.css('.list ul li') for link in image_info: image_title = link.css('a::attr(title)').get() if image_title: title = link.css('a img::attr(alt)').get() id_info = link.css('a::attr(href)').get() # /desk/23177.htm image_id = id_info.replace('.htm', '').split('/')[-1]
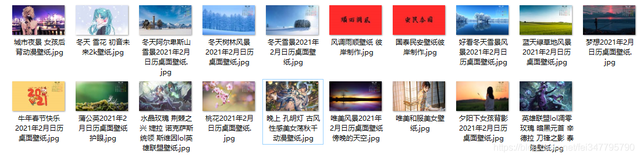

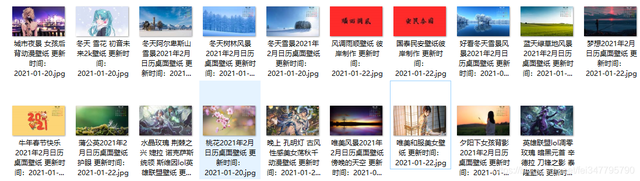
這些壁紙還挺大的,翻頁根據頁碼進行翻頁就好了,關于多執行緒爬取的話,可以參考上篇的文章內容,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/254331.html
標籤:其他
上一篇:處理 Exception 的幾種實踐,被很多團隊采納!
下一篇:redis主從復制