本文github地址:鏈接
論文趨勢分析專欄:鏈接
論文趨勢分析(python+excel+tableau)
- 1資料讀取
- 1.1讀取原始資料
- 1.2抽取5%的資料作為樣本進行分析
- 1.3 爬取論文類別資訊
- 1.4處理多種類論文
- 1.5表連接
- 1.6提取論文的發表年份和月份
- 1.7提取論文的頁數,圖數
- 1.8提取論文的作者數量
- 1.9洗掉重復的論文
- 2論文趨勢分析-python
- 2.1論文大類總體分析
- 2.1.1各大類論文總數
- 2.1.2各類論文數量隨年份的變化
- 2.1.3論文總數量隨時間的變化
- 2.1.4不同大類論文頁數的不同
- 2.1.5不同大類合作作者數量的不同
- 2.2計算機領域論文趨勢分析
- 2.2.1各領域論文的總數量
- 2.2.2各領域論文數量隨時間的變換
- 2.2.3論文頁數
- 2.2.4計算機視覺領域的合作作者數量最多
- 3使用Excel分析
- 3.1創建資料透視表
- 3.2不同大類的論文數量隨時間的變化趨勢
- 4使用tableau進行分析
- 4.1計算機領域論文數量差異
- 4.2計算機領域論文數量變化(top5)
- 4.3計算機領域論文頁數差異
- 總結
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import json
from bs4 import BeautifulSoup #用于爬取arxiv的資料
import re #用于正則運算式,匹配字串的模式
import requests #用于網路連接,發送網路請求,使用域名獲取對應資訊
1資料讀取
1.1讀取原始資料
- 資料集來源:資料集鏈接;
- 資料集的格式如下:
id:arXiv ID,可用于訪問論文;submitter:論文提交者;authors:論文作者;title:論文標題;comments:論文頁數和圖表等其他資訊;journal-ref:論文發表的期刊的資訊;doi:數字物件識別符號,https://www.doi.org;report-no:報告編號;categories:論文在 arXiv 系統的所屬類別或標簽;license:文章的許可證;abstract:論文摘要;versions:論文版本;authors_parsed:作者的資訊,
# 讀取json資料
def readArxivFile(path, columns=['id', 'submitter', 'authors', 'title', 'comments', 'journal-ref', 'doi','report-no', 'categories', 'license', 'abstract', 'versions','update_date', 'authors_parsed'], count=None):
data = []
with open(path, 'r') as f:
for idx, line in enumerate(f):
if idx == count:
break
d = json.loads(line)
d = {col : d[col] for col in columns}
data.append(d)
data = pd.DataFrame(data)
return data
data = readArxivFile('D:\code\Github\data\AcademicTrendsAnalysis/arxiv-metadata-oai-snapshot.json', ['id', 'submitter', 'authors', 'title', 'comments', 'journal-ref', 'categories', 'abstract', 'versions','update_date', 'authors_parsed'])
1.2抽取5%的資料作為樣本進行分析
- 注釋掉此段代碼,就可以對全部資料進行分析,限于本人的機子性能有限,所以只取5%的資料進行分析
data = data.sample(frac =0.05,replace = False,random_state = 1 )
# 清理記憶體垃圾
import gc
gc.collect()
76
# 存盤轉換后的資料
data.to_csv('D:\code\Github\data\AcademicTrendsAnalysis\data.csv',index = False)
data.head(3)
| id | submitter | authors | title | comments | journal-ref | categories | abstract | versions | update_date | authors_parsed | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1506.04017 | Serena Ng | Jean-Jacques Forneron and Serena Ng | A Likelihood-Free Reverse Sampler of the Poste... | NaN | NaN | stat.ME | This paper considers properties of an optimi... | [{'version': 'v1', 'created': 'Fri, 12 Jun 201... | 2015-12-02 | [['Forneron', 'Jean-Jacques', ''], ['Ng', 'Ser... |
| 1 | gr-qc/9211024 | NaN | R. Mansouri and M.Mohazzab (BROWN) | Tunneling in Anisotropic Cosmological Models | 13 pages, phyzzx | Class.Quant.Grav.10:1353-1359,1993 | gr-qc | Tunneling rate is investigated in homogenous... | [{'version': 'v1', 'created': 'Thu, 19 Nov 199... | 2010-04-06 | [['Mansouri', 'R.', '', 'BROWN'], ['Mohazzab',... |
| 2 | 2011.02152 | Rotem Liss | Rotem Liss, Tal Mor | From Practice to Theory: The "Bright Illuminat... | 17 pages | NaN | quant-ph cs.CR | The "Bright Illumination" attack [Lydersen e... | [{'version': 'v1', 'created': 'Wed, 4 Nov 2020... | 2020-11-05 | [['Liss', 'Rotem', ''], ['Mor', 'Tal', '']] |
1.3 爬取論文類別資訊
- group_name 論文大類
- archive_name 論文子類(除了物理學領域,其他種類都沒有子類)
- archive_id 論文子類的縮寫
- category_name 論文細類的名稱
- categories 論文細類的縮寫
#爬取所有的類別
website_url = requests.get('https://arxiv.org/category_taxonomy').text #獲取網頁的文本資料
soup = BeautifulSoup(website_url,'lxml') #爬取資料,這里使用lxml的決議器,加速
root = soup.find('div',{'id':'category_taxonomy_list'}) #找出 BeautifulSoup 對應的標簽入口
tags = root.find_all(["h2","h3","h4","p"], recursive=True) #讀取 tags
#初始化 str 和 list 變數
level_1_name = ""
level_2_name = ""
level_2_code = ""
level_1_names = []
level_2_codes = []
level_2_names = []
level_3_codes = []
level_3_names = []
level_3_notes = []
#進行
for t in tags:
if t.name == "h2":
level_1_name = t.text
level_2_code = t.text
level_2_name = t.text
elif t.name == "h3":
raw = t.text
level_2_code = re.sub(r"(.*)\((.*)\)",r"\2",raw) #正則運算式:模式字串:(.*)\((.*)\);被替換字串"\2";被處理字串:raw
level_2_name = re.sub(r"(.*)\((.*)\)",r"\1",raw)
elif t.name == "h4":
raw = t.text
level_3_code = re.sub(r"(.*) \((.*)\)",r"\1",raw)
level_3_name = re.sub(r"(.*) \((.*)\)",r"\2",raw)
elif t.name == "p":
notes = t.text
level_1_names.append(level_1_name)
level_2_names.append(level_2_name)
level_2_codes.append(level_2_code)
level_3_names.append(level_3_name)
level_3_codes.append(level_3_code)
level_3_notes.append(notes)
#根據以上資訊生成dataframe格式的資料
df_taxonomy = pd.DataFrame({
'group_name' : level_1_names,
'archive_name' : level_2_names,
'archive_id' : level_2_codes,
'category_name' : level_3_names,
'categories' : level_3_codes,
'category_description': level_3_notes
})
df_taxonomy.head()
# 存盤論文類別資訊
df_taxonomy.to_csv('D:\code\Github\data\AcademicTrendsAnalysis\categories.csv',index = False)
data = pd.read_csv('D:\code\Github\data\AcademicTrendsAnalysis\data.csv')
df_taxonomy = pd.read_csv('D:\code\Github\data\AcademicTrendsAnalysis\categories.csv')
df_taxonomy.head(3)
| group_name | archive_name | archive_id | category_name | categories | category_description | |
|---|---|---|---|---|---|---|
| 0 | Computer Science | Computer Science | Computer Science | Artificial Intelligence | cs.AI | Covers all areas of AI except Vision, Robotics... |
| 1 | Computer Science | Computer Science | Computer Science | Hardware Architecture | cs.AR | Covers systems organization and hardware archi... |
| 2 | Computer Science | Computer Science | Computer Science | Computational Complexity | cs.CC | Covers models of computation, complexity class... |
1.4處理多種類論文
- 有的論文同時屬于多個種類,在統計時,只按照其最重要的類別(第一個類別)
data.categories.iloc[:5]
0 stat.ME
1 gr-qc
2 quant-ph cs.CR
3 cond-mat.mtrl-sci
4 math.FA math.AP math.CA math.DG
Name: categories, dtype: object
看到類別資料以空格分割
data['category'] = data.categories.str.split(' ',expand=True)[0]
print(data['category'].nunique())
172
1.5表連接
data = data.merge(df_taxonomy,how='left',left_on='category',right_on='categories')
data.shape
(89846, 18)
1.6提取論文的發表年份和月份
data['month'] = pd.to_datetime(data.update_date).dt.month
data['year'] = pd.to_datetime(data.update_date).dt.year
1.7提取論文的頁數,圖數
# 將評論轉換成pd.string型別
data.comments = data.comments.astype('string')
pat = '(\d+) pages'
data['pages'] = data.comments.str.extract(pat=pat)
pat = '(\d+) figures'
data['figure'] = data.comments.str.extract(pat)
# 將文本轉換為數字
data.pages = data.pages.fillna('0').astype(int)
# 避免0值參與計算的影響,將0值轉換為空值,聚合計算時會自動忽略
data.loc[data.pages == 0] = np.nan
# 將文本轉換為數字
data.figure = data.figure.fillna('0').astype(int)
# 避免0值參與計算的影響,將0值轉換為空值,聚合計算時會自動忽略
data.figure.loc[data.figure == 0] = np.nan
1.8提取論文的作者數量
- 將文本型的串列轉換為python串列
import ast
data.authors_parsed = data.authors_parsed.apply(ast.literal_eval)
- 統計作者數量
data['author_num'] = data.authors_parsed.apply(len)
1.9洗掉重復的論文
- 一篇論文可能多次提交,因此有多個版本,只保留第一個版本
data = data.drop_duplicates(['id','category'],keep = 'first')
data.to_csv('D:\code\Github\data\AcademicTrendsAnalysis\data_processed.csv',index=False)
2論文趨勢分析-python
2.1論文大類總體分析
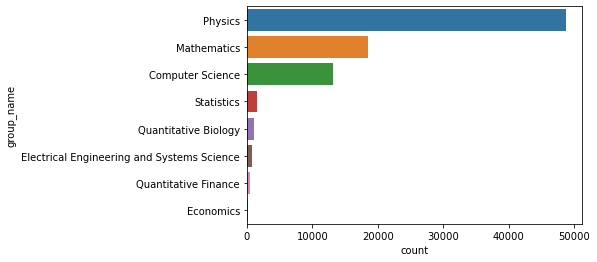
2.1.1各大類論文總數
- 物理,數學,計算機科學是數量最多的三大門類
- 統計學,計量生物學等門類的數量較少
group1 = data.groupby('group_name')['id'].agg('count').sort_values(ascending = False).to_frame()
group1 = group1.reset_index()
group1.columns = ['group_name','count']
sns.barplot(x = 'count',y = 'group_name',data = group1)
<matplotlib.axes._subplots.AxesSubplot at 0x1ca624ed730>
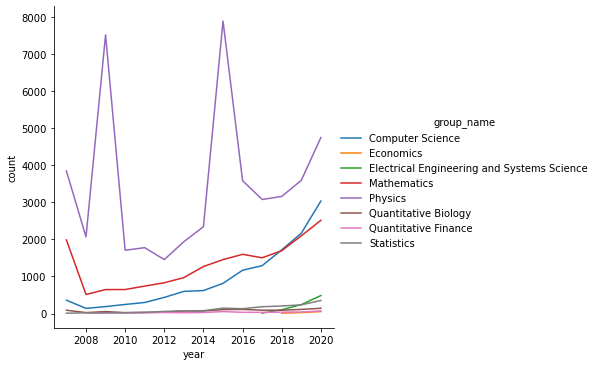
2.1.2各類論文數量隨年份的變化
- 可以看到計算機科學的論文數量隨著時間,增長越來越快,數學次之
- 物理學領域的論文數量變化較大,但總體也呈現上升趨勢
- 其他領域的論文數量則增幅很小
group2 = data.groupby(['group_name','year'])['id'].agg('count').to_frame()
group2 = group2.reset_index()
group2.columns = ['group_name','year','count']
sns.relplot(data=group2,x='year',y = 'count',hue='group_name',kind='line')
<seaborn.axisgrid.FacetGrid at 0x1ca63d96130>
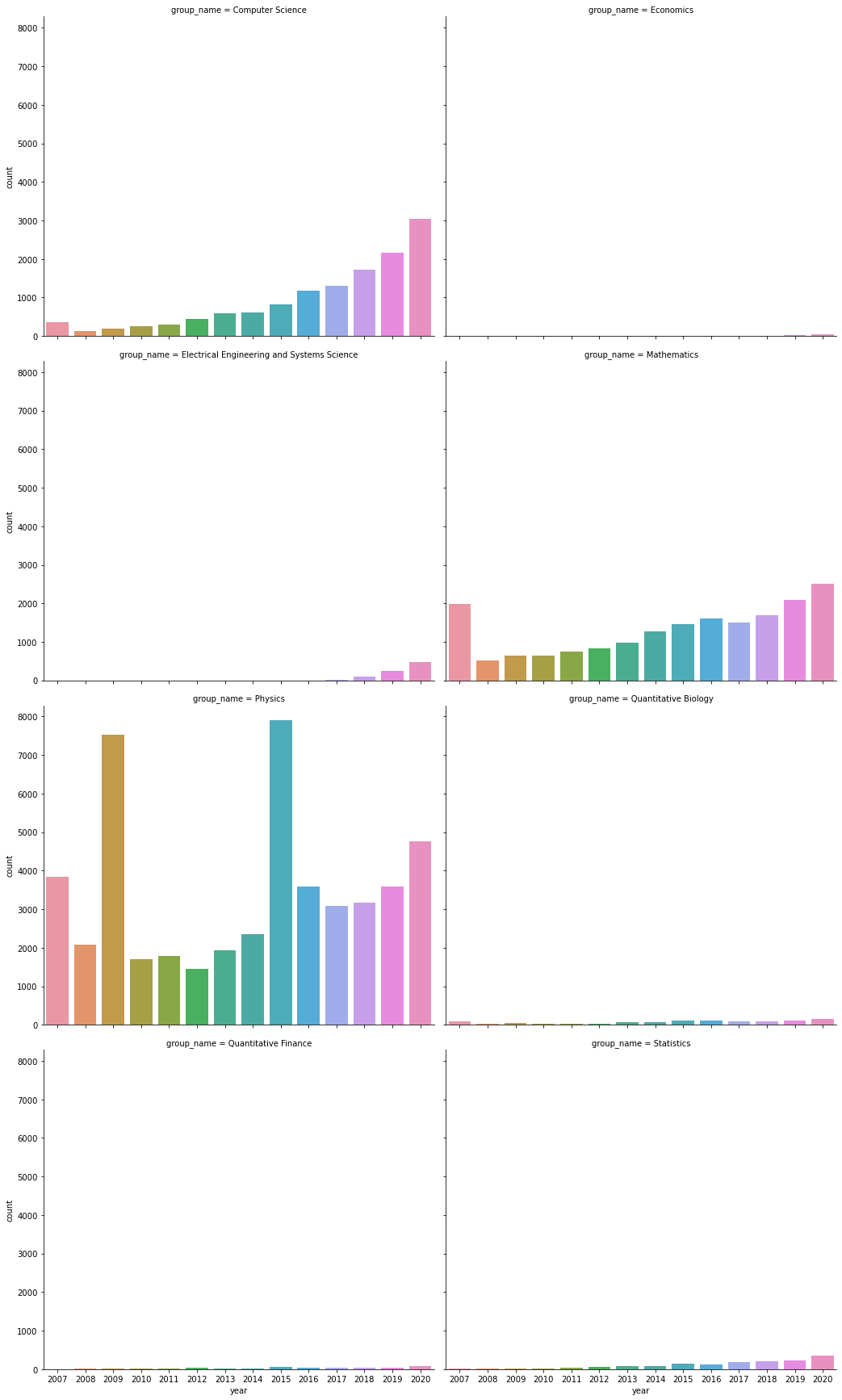
sns.catplot(data = group2,x = 'year',y ='count',col='group_name'
,col_wrap=2,height=6,aspect=1.2,kind='bar')
<seaborn.axisgrid.FacetGrid at 0x1ca62d0baf0>
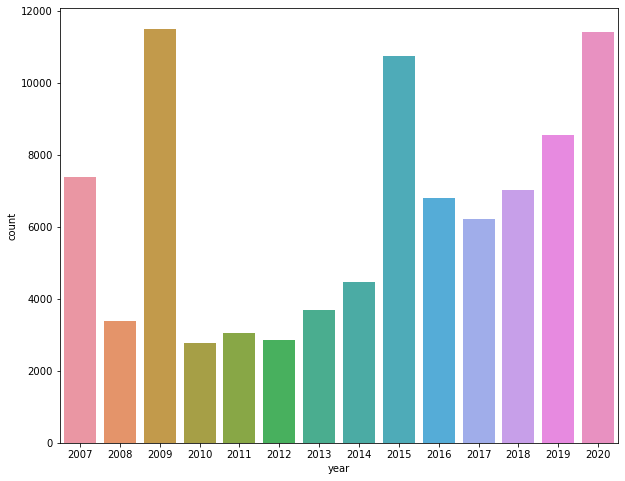
2.1.3論文總數量隨時間的變化
group3 = data.groupby('year')['id'].agg('count').sort_values(ascending = False).to_frame().reset_index()
group3.columns = ['year','count']
plt.figure(figsize = (10,8))
sns.barplot(data=group3,x='year',y='count')
<matplotlib.axes._subplots.AxesSubplot at 0x1ca65815940>
2.1.4不同大類論文頁數的不同
- 可以看到計算機科學的平均論文頁數并不算高
- 經濟學,數學,統計學的論文頁數較多
group4 = data.groupby('group_name')['pages'].agg('mean').sort_values(ascending = False).to_frame().reset_index()
group4.columns = ['group_name','pages']
sns.barplot(data=group4,x='pages',y='group_name')
<matplotlib.axes._subplots.AxesSubplot at 0x1ca6c4183a0>
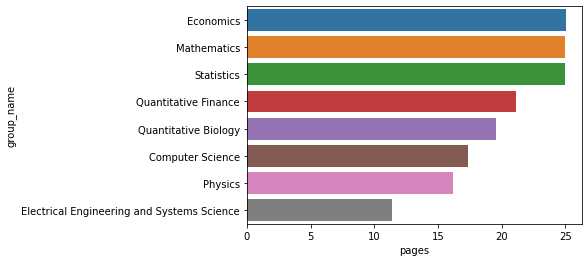
2.1.5不同大類合作作者數量的不同
- 物理學領域論文平均每篇的作者數量最多,為5人
- 數學領域論文平均每篇的作者數量最少,只有不到2人
group4 = data.groupby('group_name')['author_num'].agg('mean').sort_values(ascending = False).to_frame().reset_index()
group4.columns = ['group_name','author_num']
sns.barplot(data=group4,x='author_num',y='group_name')
<matplotlib.axes._subplots.AxesSubplot at 0x1ca6ba9faf0>
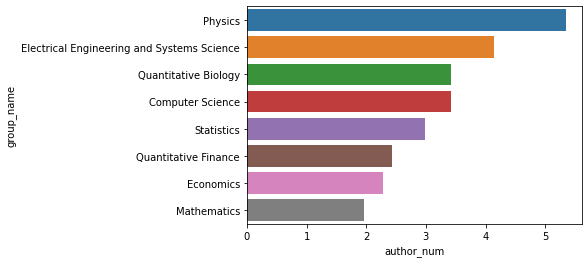
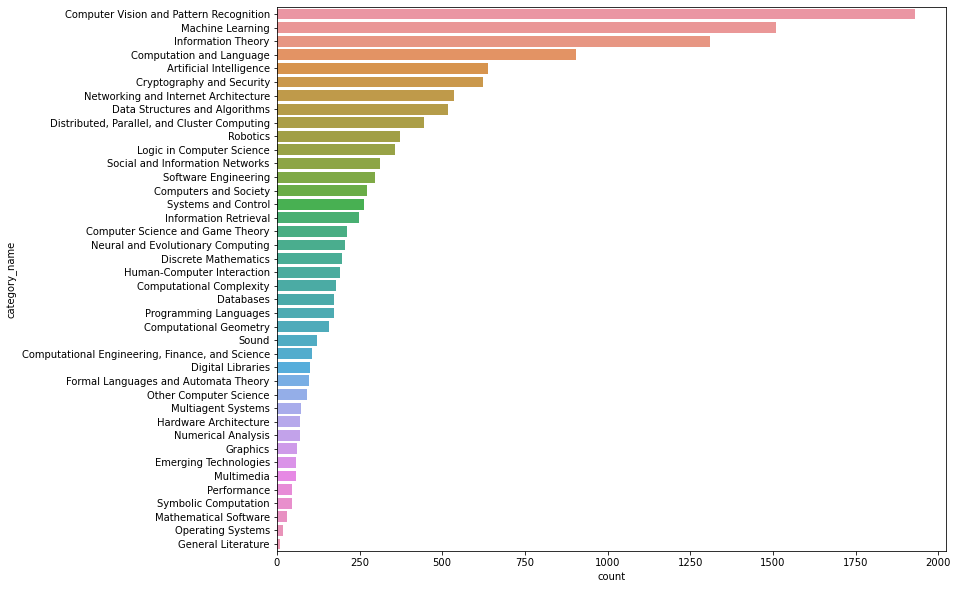
2.2計算機領域論文趨勢分析
2.2.1各領域論文的總數量
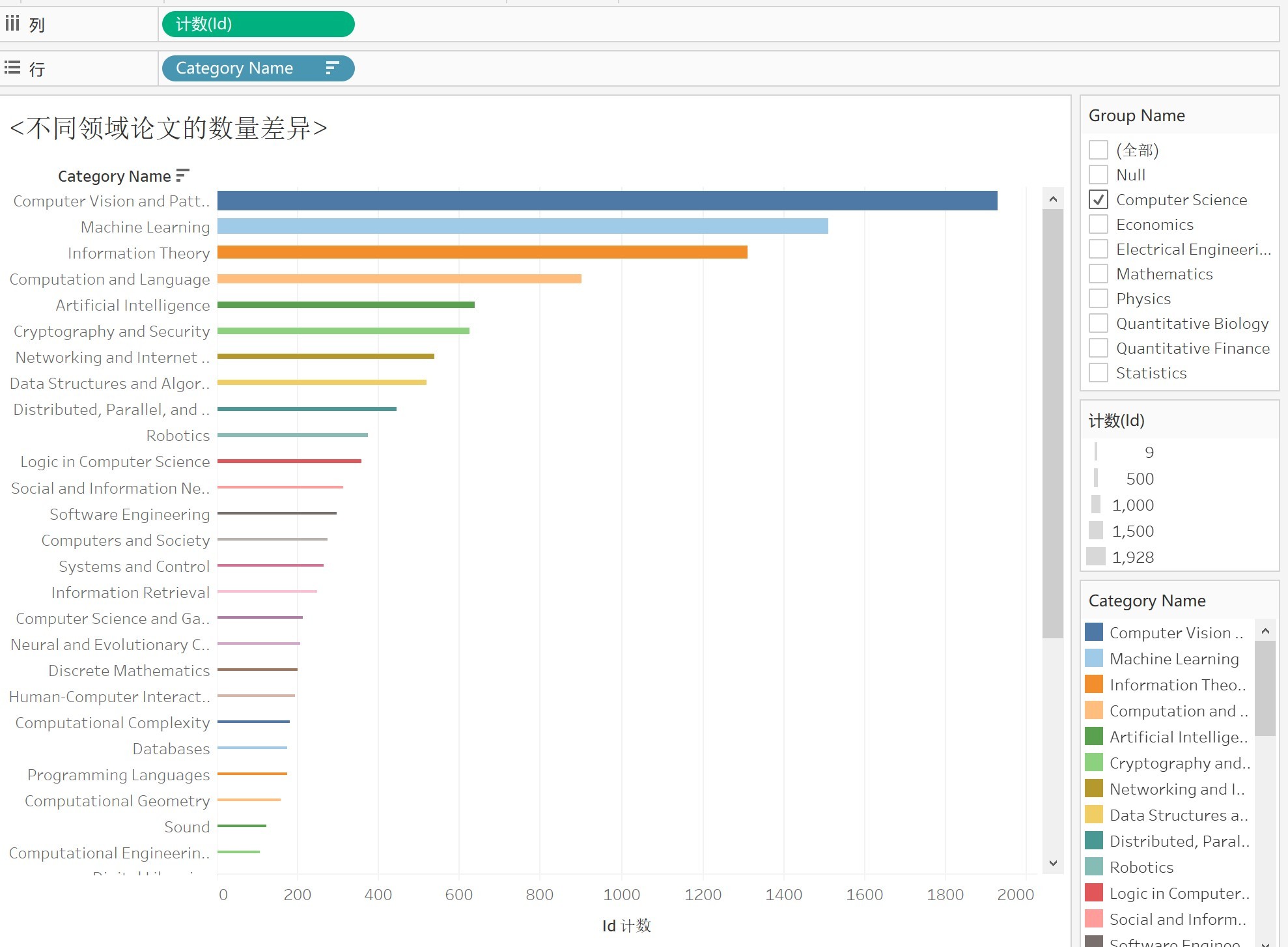
- 計算機視覺,機器學習果然是計算機科學論文最多的領域
group5 = data.loc[data.group_name == 'Computer Science'].groupby('category_name')['id'].agg('count').sort_values(ascending = False).to_frame().reset_index()
group5.columns = ['category_name','count']
plt.figure(figsize=(12,10))
sns.barplot(data=group5,x='count',y='category_name')
<matplotlib.axes._subplots.AxesSubplot at 0x1ca7165a1f0>
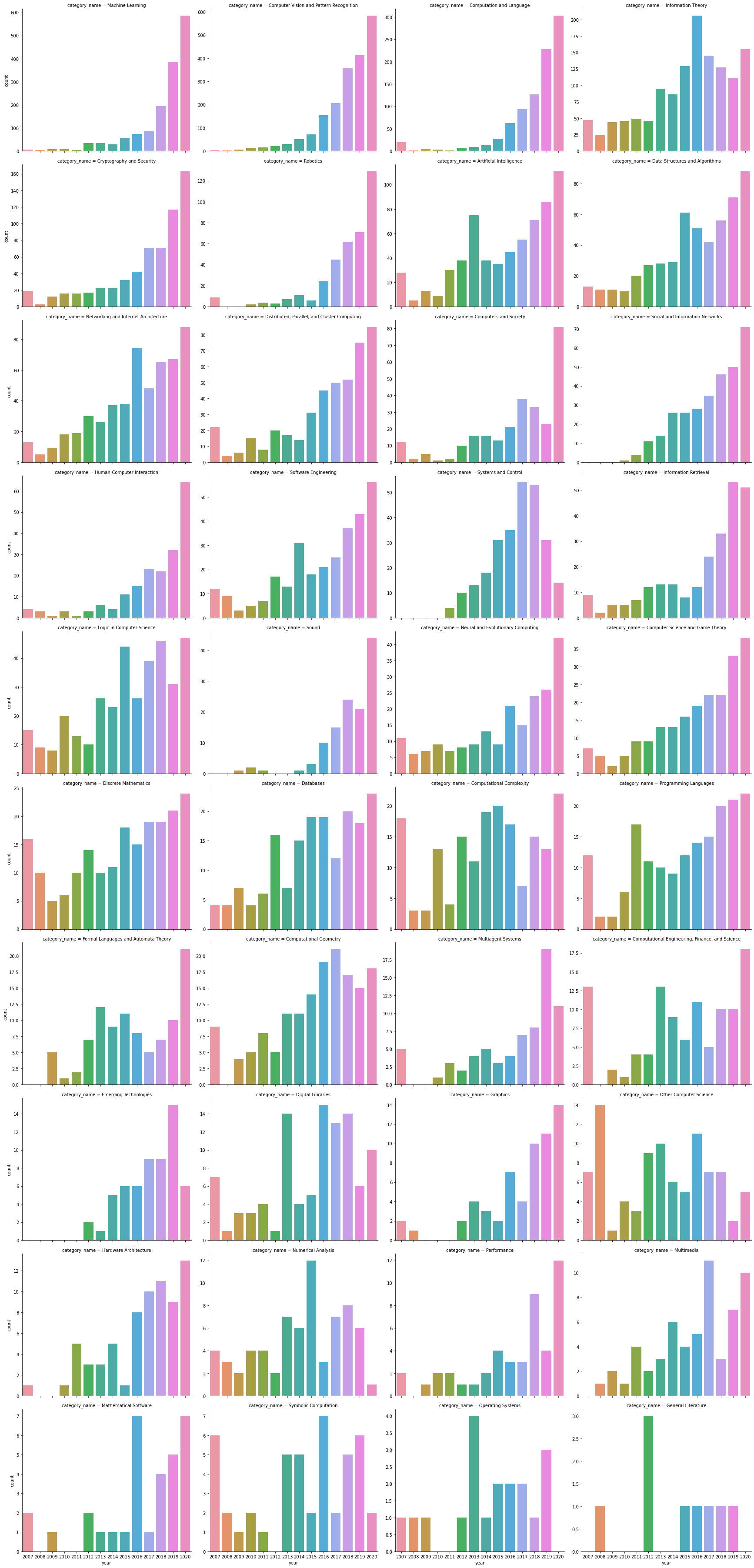
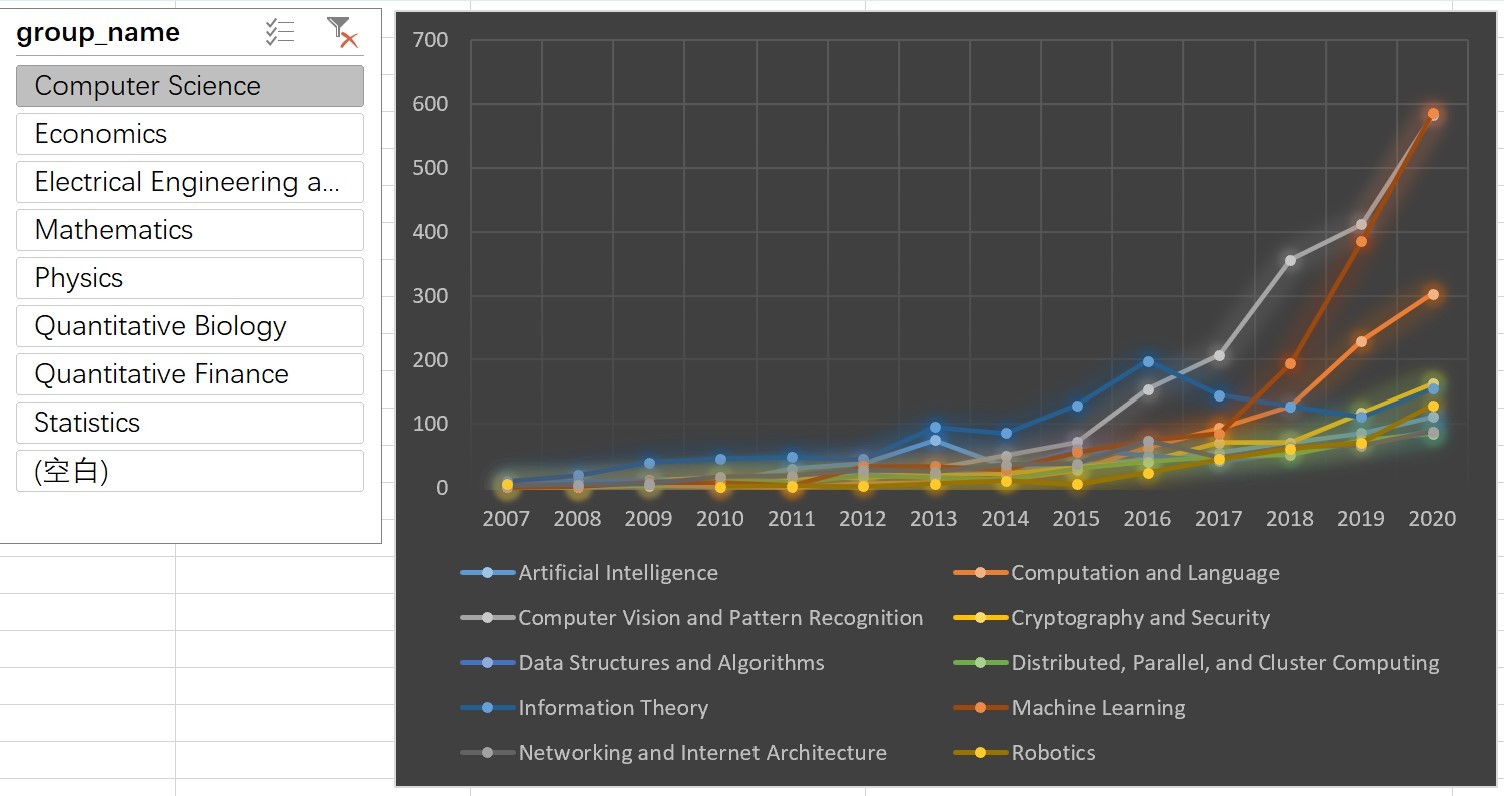
2.2.2各領域論文數量隨時間的變換
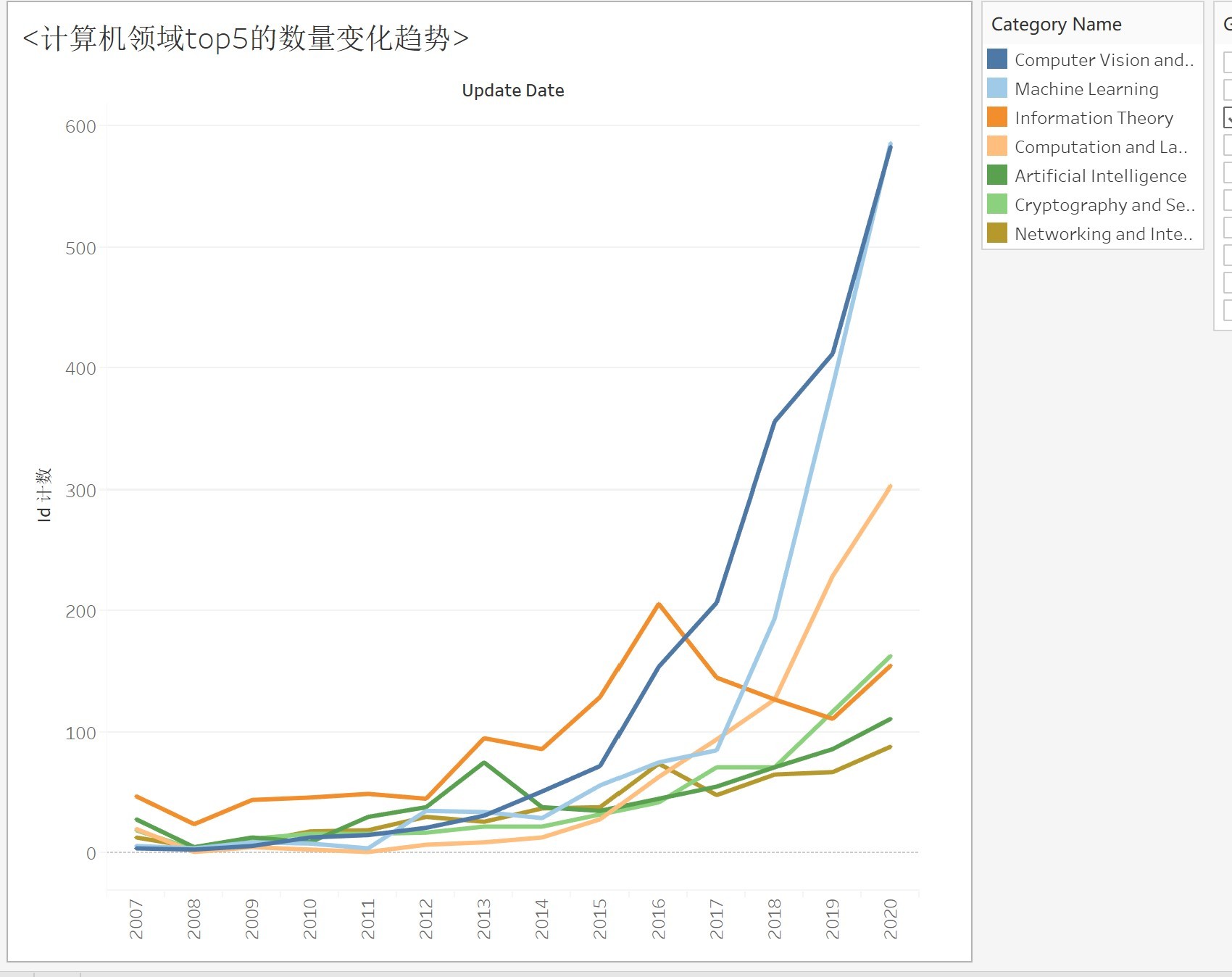
- 可以看到除了機器學習,機器視覺,自然語言處理增長較快之外,其他領域的論文數量增長都比較慢
- 資訊理論,密碼學與安全,機器人是除了ML,CV,NLP之外發表論文數量比較多的領域
- ML和CV還是計算機科學領域最火的方向
group6 = data.loc[data.group_name == 'Computer Science'].groupby(['category_name','year'])['id'].agg('count').sort_values(ascending = False).to_frame().reset_index()
group6.columns = ['category_name','year','count']
sns.relplot(data=group6,x='year',y = 'count',hue='category_name',kind='line',height = 10,style = 'category_name',palette='husl')
<seaborn.axisgrid.FacetGrid at 0x1ca6c6c5070>
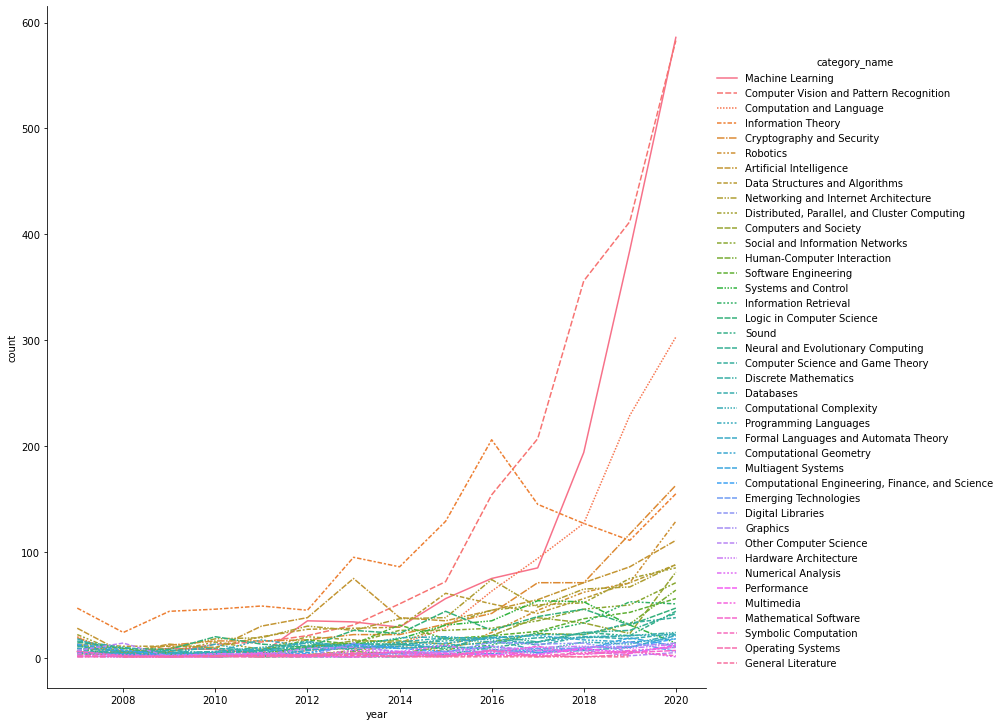
- Y軸相同刻度,查看相對數量
sns.catplot(data = group6,x = 'year',y ='count',col='category_name'
,col_wrap=4,height=5,aspect=1.2,kind='bar')
<seaborn.axisgrid.FacetGrid at 0x1ca6c2eb7f0>

- Y軸不同刻度,查看變化趨勢
sns.catplot(data = group6,x = 'year',y ='count',col='category_name'
,col_wrap=4,height=5,aspect=1.2,kind='bar',sharey=False)
<seaborn.axisgrid.FacetGrid at 0x1ca6c474130>
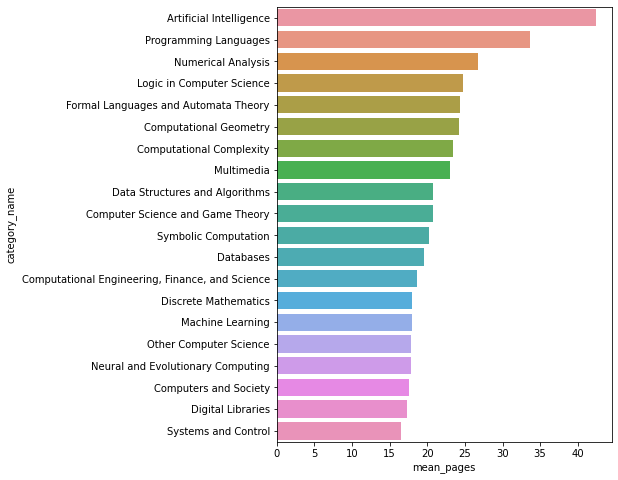
2.2.3論文頁數
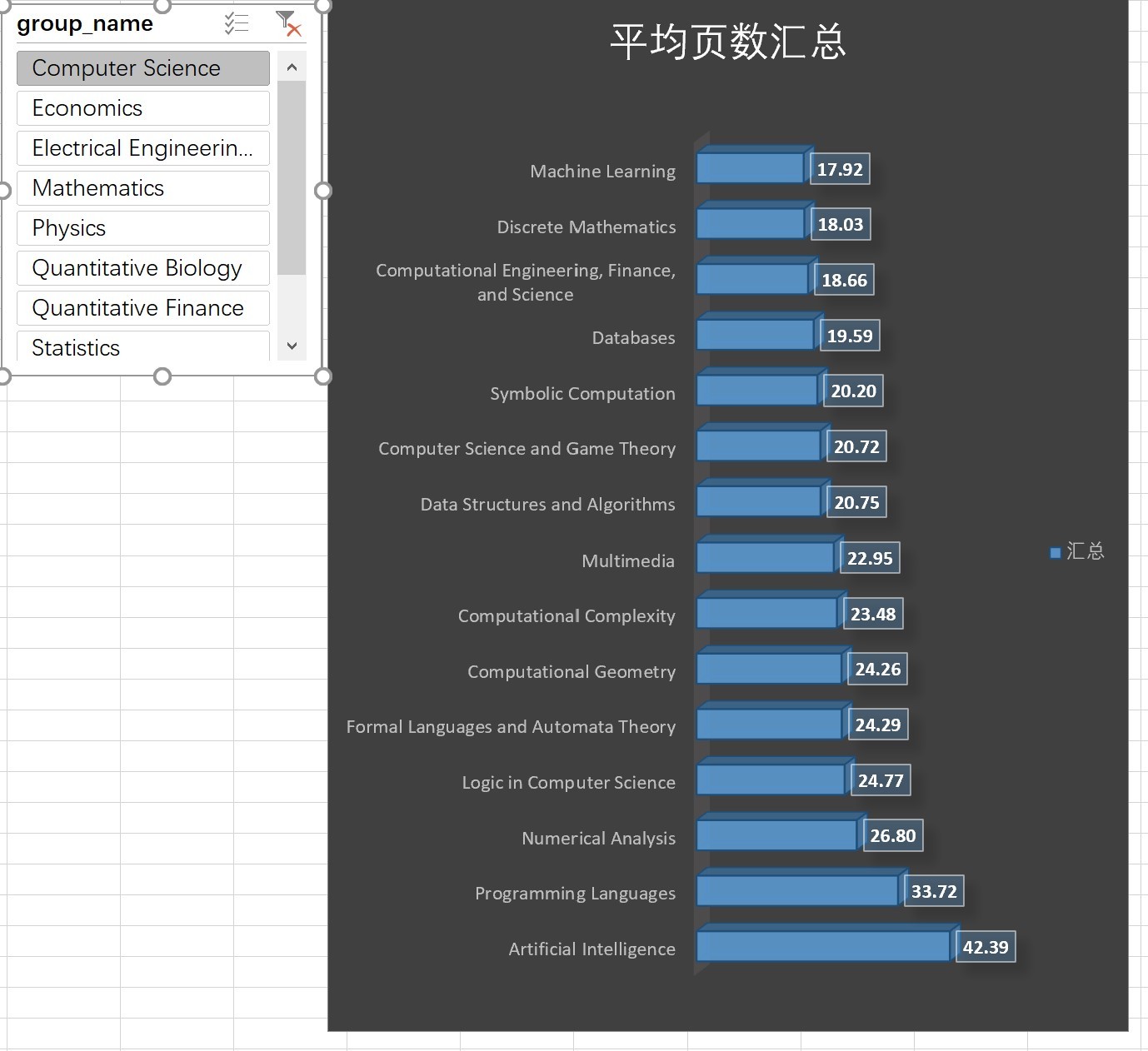
- 人工智能,編程語言,數值分析領域的論文頁數最長
- CV和NLP的平均頁數未進入前20
group7 = data.loc[data.group_name == 'Computer Science'].groupby('category_name')['pages'].agg('mean').sort_values(ascending = False).to_frame().reset_index().head(20)
group7.columns = ['category_name','mean_pages']
plt.figure(figsize=(6,8))
sns.barplot(data=group7,x='mean_pages',y='category_name')
<matplotlib.axes._subplots.AxesSubplot at 0x1ca76e637f0>
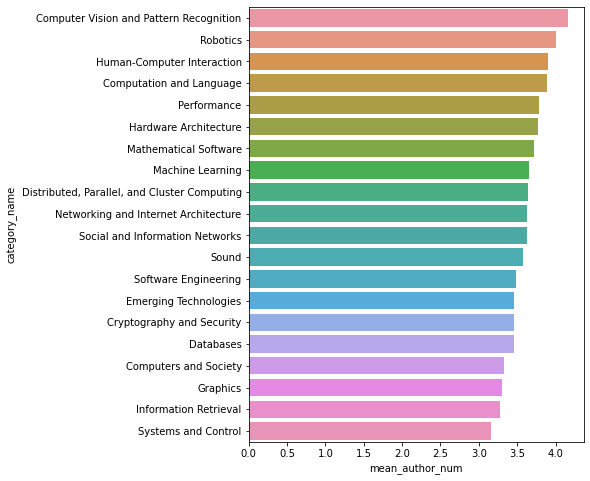
2.2.4計算機視覺領域的合作作者數量最多
group8 = data.loc[data.group_name == 'Computer Science'].groupby('category_name')['author_num'].agg('mean').sort_values(ascending = False).to_frame().reset_index().head(20)
group8.columns = ['category_name','mean_author_num']
plt.figure(figsize=(6,8))
sns.barplot(data=group8,x='mean_author_num',y='category_name')
<matplotlib.axes._subplots.AxesSubplot at 0x1ca772646d0>
3使用Excel分析
3.1創建資料透視表
- 將存盤的csv檔案另存為excel檔案,并隨便創建打開一個excel檔案
- 點擊資料選項卡-獲取外部資料-現有連接
- 點擊瀏覽,選擇上面保存的
data_processed.xlsx檔案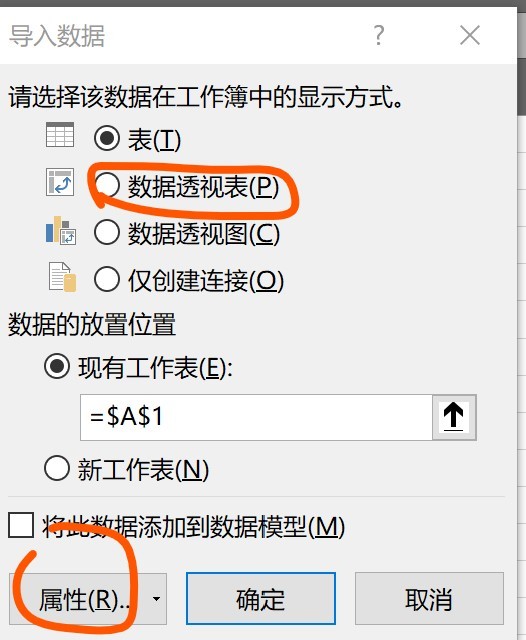
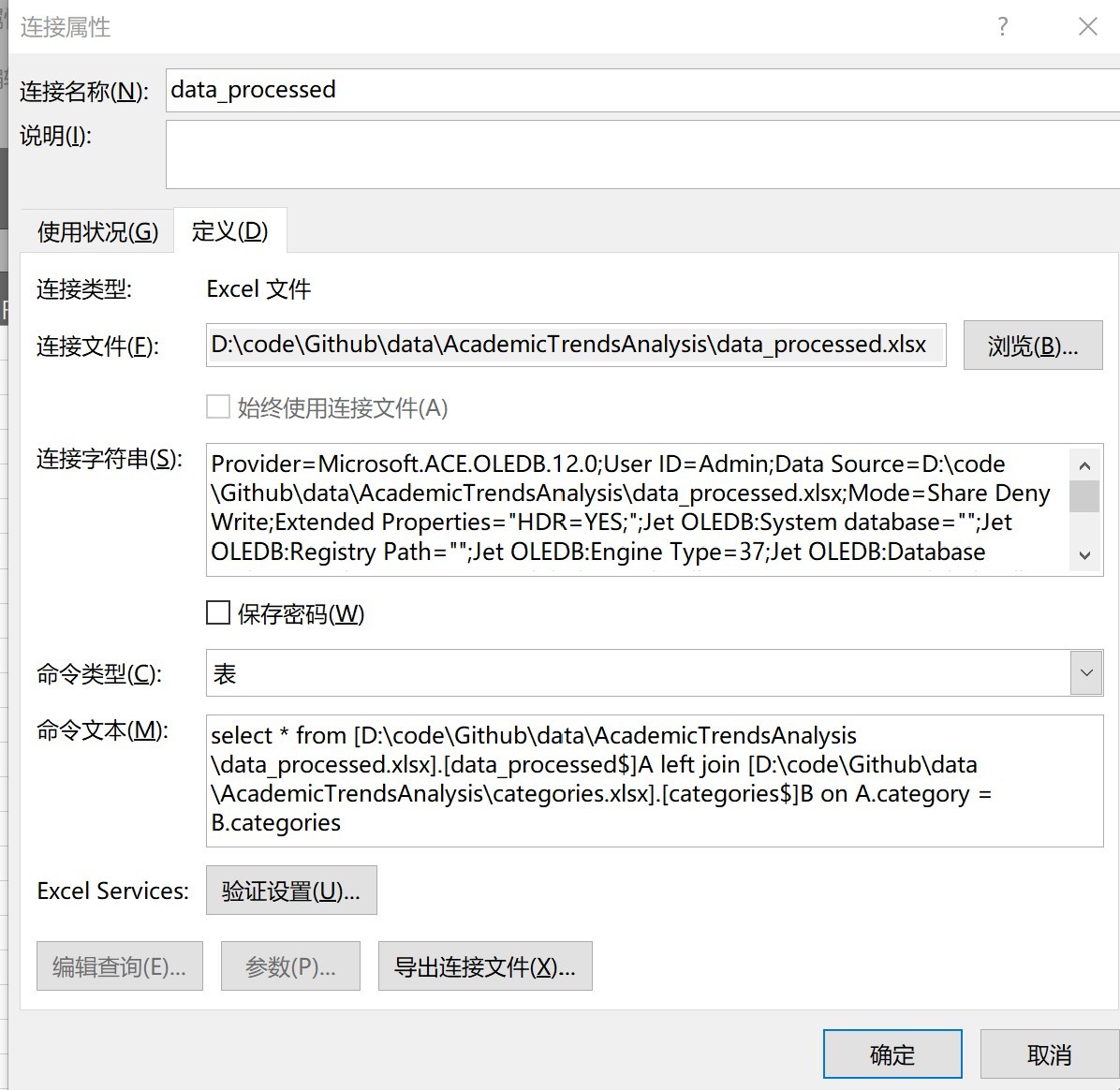
- 更改屬性,輸入sql陳述句:
select * from [D:\code\Github\data\AcademicTrendsAnalysis\data_processed.xlsx].[data_processed$]A left join [D:\code\Github\data\AcademicTrendsAnalysis\categories.xlsx].[categories$]B on A.category = B.categories
3.2不同大類的論文數量隨時間的變化趨勢
- 在資料透視表中選擇
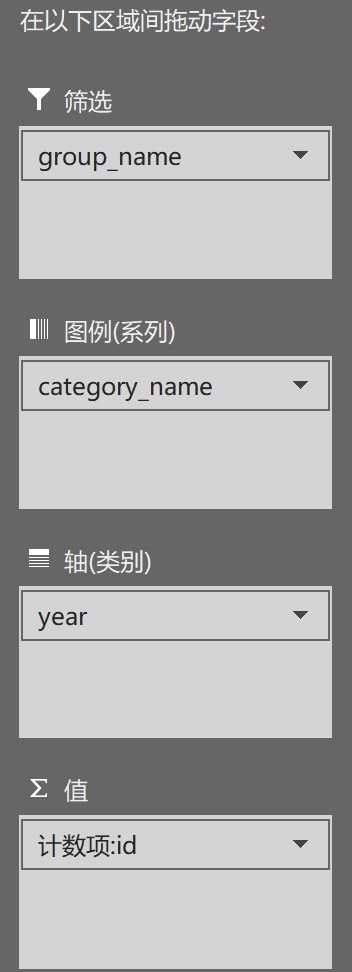
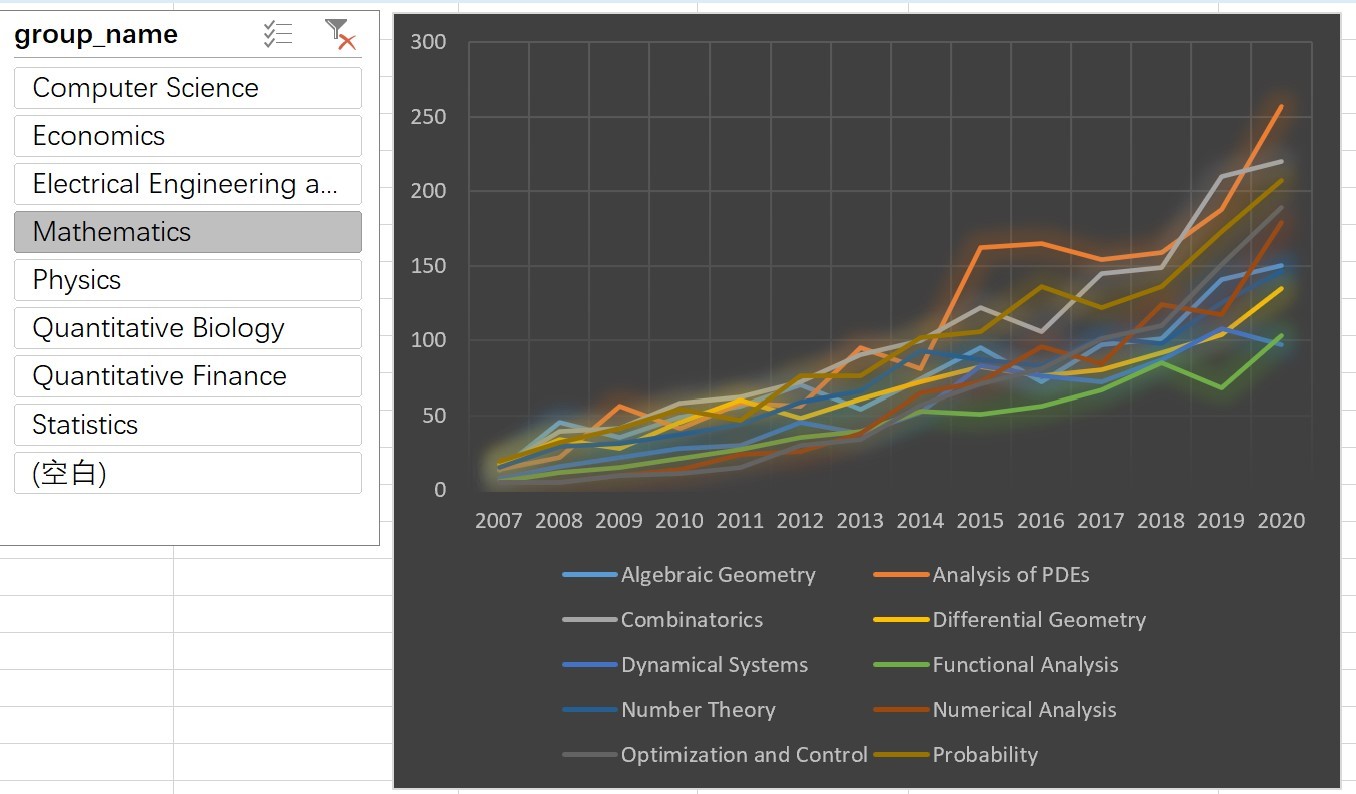
4使用tableau進行分析
4.1計算機領域論文數量差異
4.2計算機領域論文數量變化(top5)
4.3計算機領域論文頁數差異
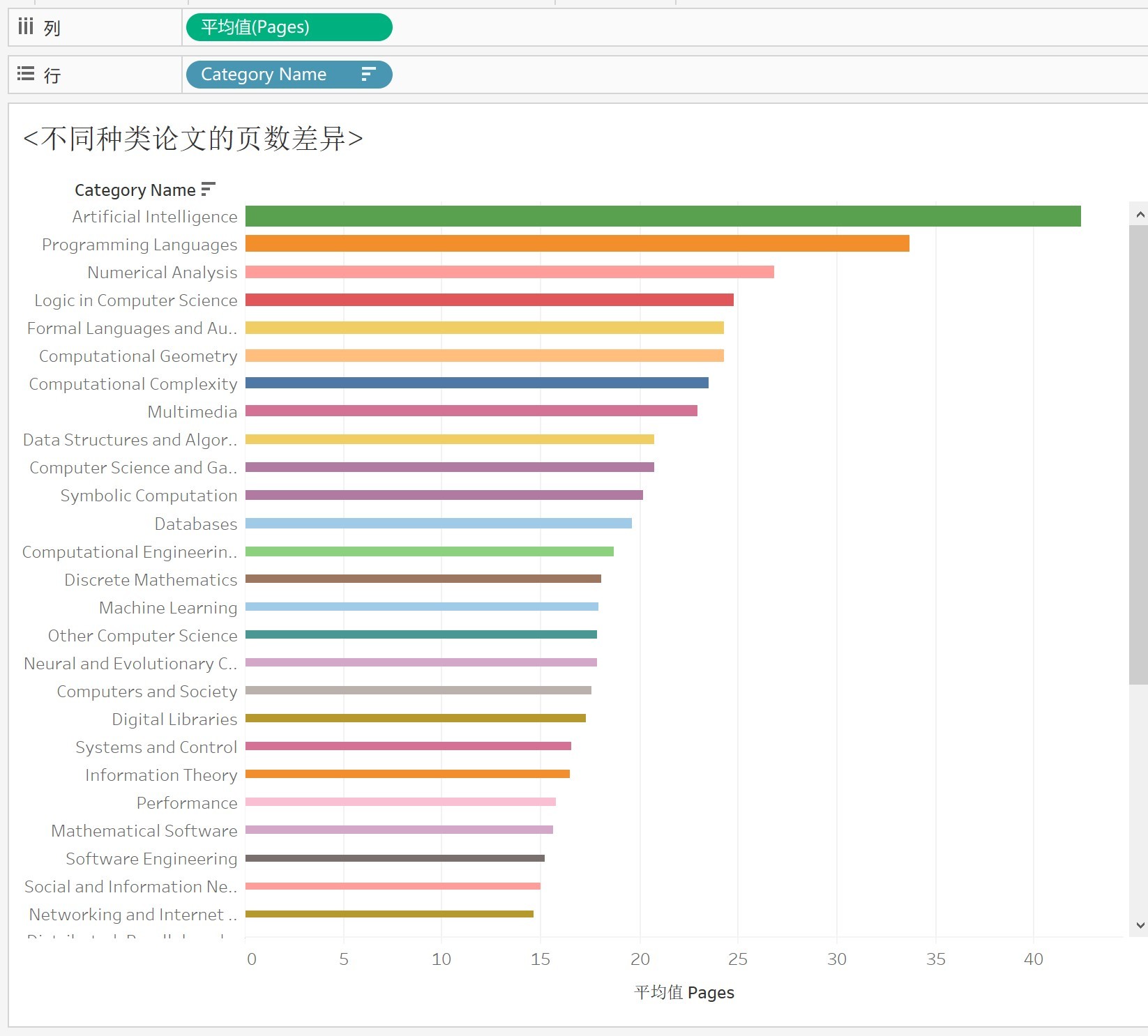
總結
總的來說,python,excel,tableau都能完成上述分析可視化任務,但是各有優缺點:
- python:
- 適合做不規則資料的處理
- 適合進行各種演算法建模
- 適合進行預測分析
- excel:
- 適合小量規則資料的分析與可視化
- 資料格式較為局限,資料量不易過大
- tableau
- 適合大量資料的分析與可視化
- 操作簡單,比python敲代碼作圖更快捷
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/254944.html
標籤:python