這里是個人吐槽,可略過
不知道大家寫爬蟲的時候有沒有遇到過這種情況,看到那種表格形式的資料,就很頭疼,因為我們要一個一個地去決議他們,
在決議網頁資料地時候,我本人比較喜歡用xpath,拿企查查為例,下面是我是小白的時候寫的代碼(太菜了)…

def get_the_information(company_url):
company_url = company_url
# print(company_url)
r = requests.get(company_url, headers=headers)
# print(r.text)
html = etree.HTML(r.text)
First_list = []
try:
company_name = html.xpath('//h1/text()')[0]
except Exception as e:
company_name = ''
# print(company_name)
try:
phone = html.xpath('//span[@class="cvlu"]/span[2]/text()')[0]
except Exception:
phone = '無'
# print(phone)
try:
date = html.xpath('//table[@class="ntable"]//tr[1]/td[@class=""][2]/text()')[0].replace('\n', '').replace(' ',
'')
except Exception:
date = ''
# print(date)
try:
status = html.xpath('//table[@class="ntable"]//tr[1]/td[@class=""][1]/text()')[0].replace('\n', '').replace(' ',
'')
except Exception as e:
status = '無'
# print(status)
try:
address = html.xpath('//table[@class="ntable"]//tr[8]/td/span/a/text()')[0].replace('\n', '').replace(' ', '')
except Exception:
address = '無'
try:
Subscribed_capital = int(
html.xpath('//section[@id="Cominfo"]//table[@class="ntable"]//tr[2]/td[2]/text()')[0].replace('\n',
'').replace(
' ', '').split('萬')[0]) / 10000
# print(Subscribed_capital)
Paid_capital = int(
html.xpath('//section[@id="Cominfo"]//table[@class="ntable"]//tr[2]/td[4]/text()')[0].replace('\n',
'').replace(
' ', '').split('萬')[0]) / 10000
# print(Paid_capital)
except Exception:
pass
try:
Legal_representative = re.findall('<a href=".*?" class="bname"><h2 class="seo font-20">(.*?)</h2></a>', r.text)[
0]
except Exception:
Legal_representative = '無'
print(Legal_representative)
# print(Legal_representative)
unMain_HTML = html.xpath('//div[@id="employeeslist"]/table[@class="ntable ntable-odd"]//tr')
# print(unMain_HTML)
First_list.append(company_name)
First_list.append(phone)
First_list.append(date)
First_list.append(status)
First_list.append(address)
First_list.append(Subscribed_capital)
First_list.append(Paid_capital)
First_list.append(Legal_representative)
unMain_information = []
for html in unMain_HTML:
two_information = []
try:
name = html.xpath('td[2]//span[@class="seo font-14"]/text()')[0]
position = html.xpath('td[@class="text-center"]/text()')[0].replace('\n', '').replace(' ', '')
two_information.append(name)
two_information.append(position)
unMain_information.append(two_information)
# print(two_information)
except Exception:
pass
# print(unMain_information)
Main_HTML = html.xpath('//div[@id="ChangelistTable"]//table[@class="ntable"]//tr')
Main_information = []
for html in Main_HTML:
One_informatin = []
Change_data = html.xpath('./td[2]/text()')[0]
Change_information = html.xpath('./td[3]/text()')[0].replace('\n', '').replace(' ', '')
try:
Change_before = html.xpath('./td[4]//a/text()')[0].replace('\n', '').replace(' ', '')
except Exception:
Change_before = ' '
try:
Change_after = html.xpath('./td[5]//a/text()')[0].replace('\n', '').replace(' ', '')
except Exception:
Change_after = ' '
One_informatin.append(Change_data)
One_informatin.append(Change_information)
One_informatin.append(Change_before)
One_informatin.append(Change_after)
Main_information.append(One_informatin)
# for m in Main_information:
# print(m)
# print(First_list)
# print(unMain_information)
return First_list, unMain_information, Main_information
現在回頭看我寫的代碼,簡直不忍直視,這么一大坨,就為了決議一個表格(我淦),
隨著技術的沉淀,現在學到了很多有用的庫,通過參考這些庫,我的代碼可以做到25行搞定這種網頁表格(連帶保存),下面就給大家分享一下我的方法!
第一步——匯入用到的庫
import requests
from lxml import etree
import pandas as pd
import numpy as np
第二步——請求資料
headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",}
url = 'https://www.qcc.com/firm/8c9f7ddc1a7bcee3d1f7676773fe9404.html'
s = requests.Session()
r = s.get(url, headers=headers)
第三步(關鍵)——找到<table標簽
至于為什么找<table 標簽,我解釋一下,是因為我們需要使用到pandas庫中的 read_html方法,它可以自動把網頁原始碼代碼種,table標簽中的表格資料,轉換成串列,
table標簽的樣式:
<table border="1">
<tr>
<th></th>
<th></th>
</tr>
<tr>
<td></td>
<td></td>
</tr>
</table>
拿企查查為例,我們在網頁源代碼種找到table標簽的位置
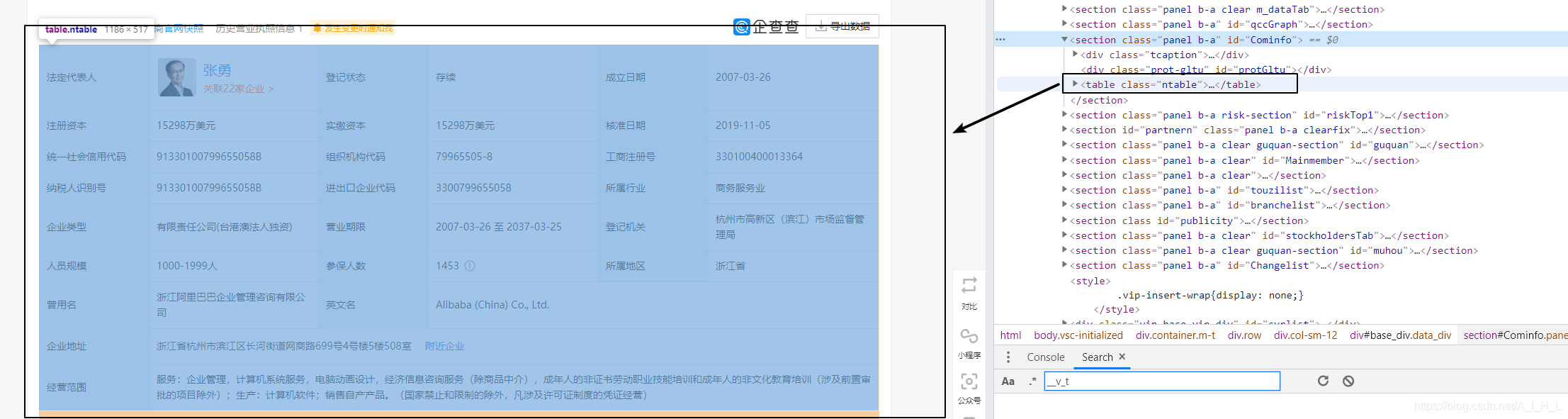
下面我們要做的就是把table標簽的源代碼給爬下來
html = etree.HTML(r.text)
table = html.xpath('//section[@id="Cominfo"]/table[@class="ntable"]')[0]
div_str = etree.tostring(table)
第四步——使用read_html()
我們只需要把div_str 放到read_html()的第一個引數的位置,后面接上編碼,讓header=1(作用是讓第一行資料當表頭,否則會多出來一行數字),因為回傳的是個串列,我們接收第一個即可
df = pd.read_html(div_str, encoding='utf8', header=1)[0]
print(df)
結果如下:

我們把它的值遍歷一下看看是什么
for i in df.values:
print(i)
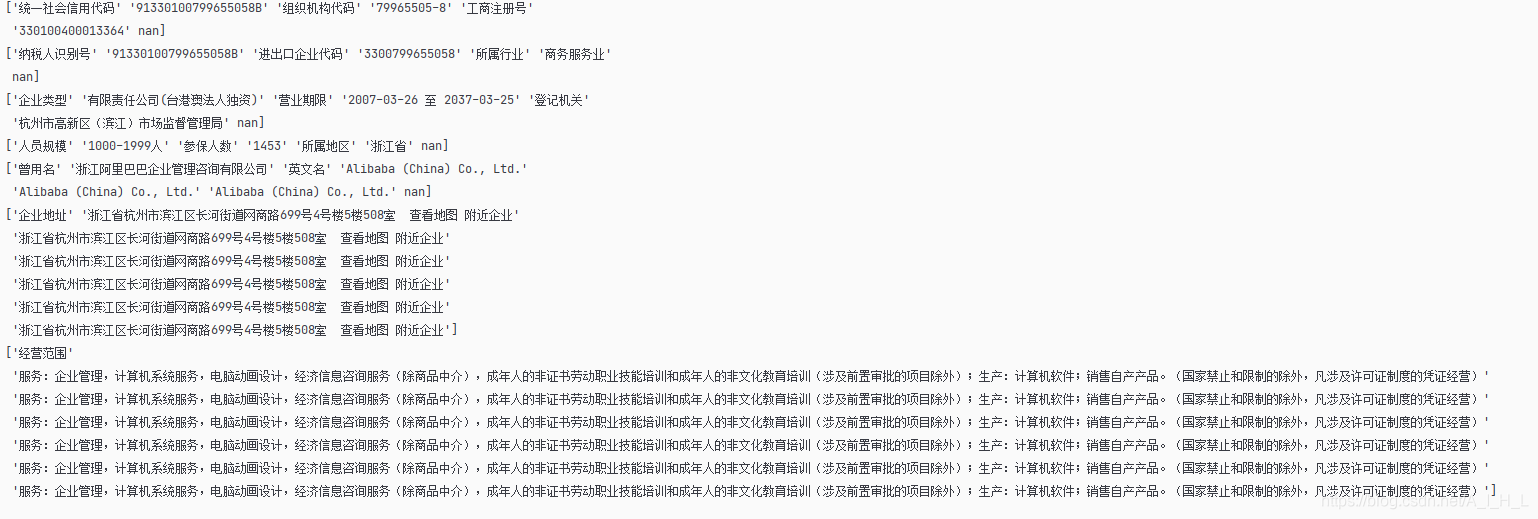
原來是這樣的,跟網頁中的表格格式基本一致,但是這并不是我們想要的形式,我們需要的是一個字典,是鍵值對,
此時我們就需要把這些表格處理一下了,
第五步——處理資料
這里可以觀察到,每個串列的鍵和值都是緊挨的,而且第一個是鍵,第二個是值,有的串列會有很多重復值,并且串列的最后會有個‘nan’,我們需要把他去掉,
for i in df.values:
l = list(i[:-1])
l2 = list(set(l))
l2.sort(key=l.index)
print(l2)
此時的輸出結果是這樣的:

離成功又近了一步!
加下來要做的就是把表格中的資料,轉換成鍵值對的形式,以便于我們存盤為csv
這里我是用的是numpy中的串列分割,我把每個串列的元素以2為單位進行分割,得到若干小串列,然后字典的鍵就是串列的第一個值,字典的值就是串列的第二個值!
dict = {}
for i in df.values:
l = list(i[:-1])
l2 = list(set(l))
l2.sort(key=l.index)
arry_list = np.array_split(l2, len(l2) / 2)
for L in arry_list:
L = list(L)
dict[L[0]] = L[1]
print(dict)
輸出結果如下:

第六步——保存成表格
在得到字典后,我們要做的就是把它轉換成dataframe,再使用pd.to_csv(),保存到本地
具體操作如下:
data = pd.DataFrame(dict, index=['阿里巴巴'])
print(data)
data.to_csv('阿里.csv')
第七步——查收資料

整體代碼如下:
import requests
from lxml import etree
import pandas as pd
import numpy as np
headers = {"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36",}
url = 'https://www.qcc.com/firm/8c9f7ddc1a7bcee3d1f7676773fe9404.html'
s = requests.Session()
r = s.get(url, headers=headers)
html = etree.HTML(r.text)
table = html.xpath('//section[@id="Cominfo"]/table[@class="ntable"]')[0]
div_str = etree.tostring(table)
df = pd.read_html(div_str, encoding='utf8', header=1)[0]
dict = {}
for i in df.values:
l = list(i[:-1])
l2 = list(set(l))
l2.sort(key=l.index)
arry_list = np.array_split(l2, len(l2) / 2)
for L in arry_list:
L = list(L)
dict[L[0]] = L[1]
print(dict)
data = pd.DataFrame(dict, index=['阿里巴巴'])
print(data)
data.to_csv('阿里.csv')
注意事項:我們使用pandas和numpy得到的表格,需要使用list()強轉一下,否則不能直接操作!
學到的話給博主點個關注哦~
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/254948.html
標籤:python
上一篇:爬蟲初體驗——python爬取學院教師公開資訊并存入Excel表格
下一篇:ML之xgboost:解讀用法之xgboost庫的core.py檔案中的get_score(importance_type=self.importance_type)方法