Python基礎(資料型別)
有問題可以?QQ:1606269318來交流溝通,
以下全是干貨,對剛學Python是挺有幫助的,
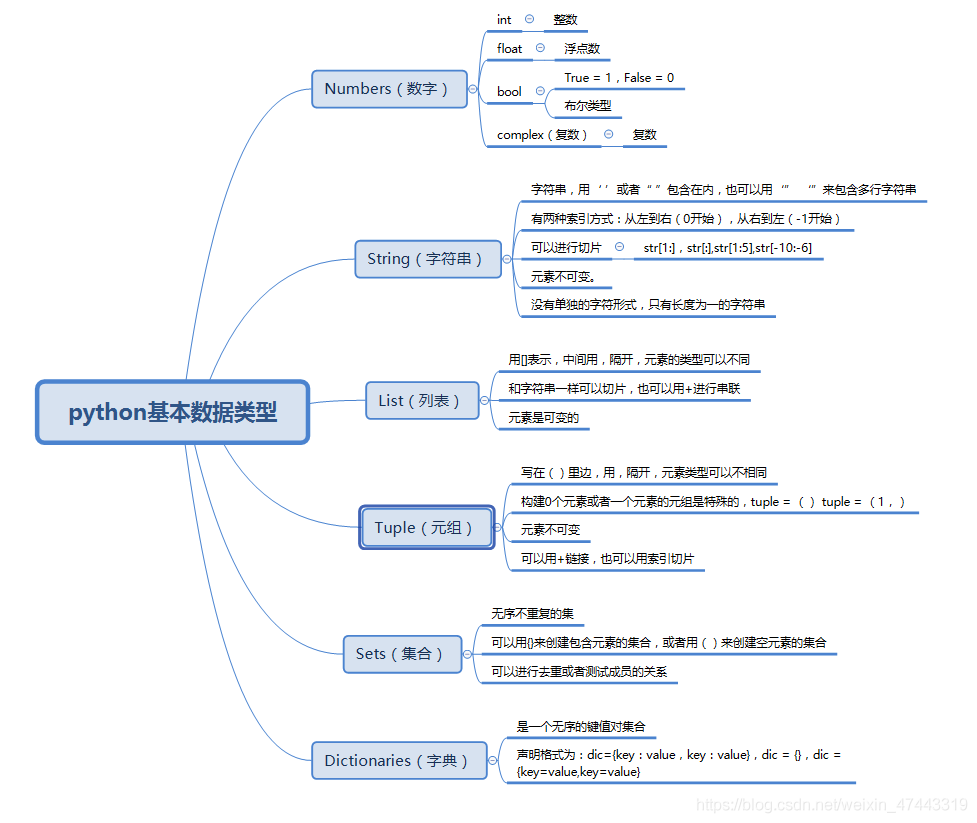
1、Numbers(數字):
1)整數(int)
通常被稱為是整型或整數,可以是正整數或負整數,不帶小數點,
> num2 = 1
> print(“num2–>”,num2,type(num2))
num2–> 1 <class ‘int’>
2)浮點數(float)
浮點型由整數部分與小數部分組成,
> num1 = 1.1
> print(“num1–>”,num1,type(num1))
num1–> 1.1 <class ‘float’>
3)布爾型別(bool)
布爾型別分為Ture和False
在Python3中True=1,False=0
> print(type(True))
True–> <class ‘bool’>
> print(type(False))
False–> <class ‘bool’>
4)復數(complex)
復數由實數部分和虛數部分構成,可以用a + bj,或者complex(a,b)表示, 復數的實部a和虛部b都是浮點型,
> aComplex = 1.56 + 1.2j
> print(“aComplex–>”,type(aComplex))
aComplex–> <class ‘complex’>
5)String(字串):
字串定義:
字串可以用""或’'來定義
PS: 符號都是英文的符號
> str1 = ‘string_test1’
> print(type(str1))
<class ‘str’>
> str2 = “string_test2”
> print(type(str2))
<class ‘str’>
比較字串內容是否相同:
用"=="來比較兩個字串內的value值是否相同,回傳值為布林值
> print (“比較結果–>”,str1 == str2)
比較結果–> False
#相同的話就回傳True
is:比較兩個字串的id值,
print (“比較結果–>”,str1 is str2)
比較結果–> False
#相同的話就回傳True
比較字串長度是否相等:
len():顯示字串的長度,回傳數字整型然后進行長度的比較,回傳值為布林值,
> str1 = ‘string_test1’
> int1 = len(str1)
> str2 = ‘string_test2’
> int2 =len(str2)
> print(“比較結果–>”,int1 == int2)
> 比較結果–> True
#不相同的話就回傳False
2、運算子、轉義字符、占位符、內置函式
1)運算子:
常用的比較運算子:
>、<、> = 、< =、==
比較的規則為:從第一個字符開始比較,排序在前邊的字母為小,當一個字串全部字符和另一個字串的前部分字符相同時,長度長的字串為大,
常用的字符運算子:
+、*、[]、[:]、in、not in、r/R
+,字串連接
> str3 = ‘love’
> str4 = ‘me’
> print(‘輸出結果–>’,str3+str4)
輸出結果–> loveme
*,重復輸出字串
> print(‘輸出結果–>’,str3*3)
輸出結果–> lovelovelove
[],通過索引獲取字串中的字符
> print(‘輸出結果–>’,str3[0])
輸出結果–> l
#默認是從0開始起始
[:],截取字串
> print(‘輸出結果–>’,str3[2:])
輸出結果–> ve
#截前不截后,[2:9:2]這個的意思是取某個字串的第二個到第九個,步長為2(間隔2個)
> str4 = ‘123456789’
> print(‘輸出結果–>’,str4[2:8:2])
輸出結果–> 357
in,成員運算子,檢索字串中是否包含給定的字串,回傳值為布林值
> str3 = ‘love’
> result= “l” in str3
> print(‘比較結果–>’,result)
比較結果–> True
not in,成員運算子,檢索字串中是否包含給定的字串,回傳值為布林值
> result= “l” not in str3
> print(‘比較結果–>’,result)
比較結果–> False
r和R,非轉義原生字符,簡單來說就是寫啥列印出啥
> print(‘輸出結果–>’,r’eric\n你好啊!’)
輸出結果–> eric\n你好啊!
> print(‘輸出結果–>’,R’eric\n你好啊!’)
輸出結果–> eric\n你好啊!
2)轉義字符:
| 轉義字符 | 描述 |
|---|---|
| \(在行尾時) | 續行符 |
| \\ | 反斜杠符號(\) |
| \’ | 單引號(’) |
| \" | 雙引號(") |
| \a | 響鈴 (會發出滴的一聲) |
| \b | 退格(洗掉\b前第一個字串) |
| \e | 轉義 |
| \000 | 空(代表空) |
| \n | 換行 |
| \v | 縱向制表符 |
| \t | 橫向制表符(TAB) |
| \r | 回車(取\r后的字串) |
| \f | 換頁 |
| \oyy | 八進制,yy代表的字符,例如: \o12 代表換行 |
| \xyy | 十六進制,yy代表的字符,例如: \ox0a 代表換行 |
| other | 其他的字符以普通格式輸出 |
3)占位符:
在輸出里占位的符號
| 占位符 | 轉換 |
|---|---|
| %c | 字符 |
| %s | 通過str()字串來格式化 |
| %i | 有符號十進制整數 |
| %d | 有符號十進制整數 |
| %u | 無符號十進制整數 |
| %o | 八進制整數 |
| %x | 十六進制整數(大小寫字母) |
| %X | 十六進制整數(大小寫字母) |
| %e | 索引符號(小寫“e”) |
| %E | 索引符號(大寫“E”) |
| %f | 浮點實數 |
| %g | %f和%e的簡寫 |
| %G | %f和%E的簡寫 |
4)內置函式:
| 內置函式 | 描述 |
|---|---|
| string.capitalize() | 將字串的第一個字符轉換為大寫 |
| string.center(width、fillchar) | 回傳一個指定長度的寬度width居中的字串,fillchar為填充的字符,默認為空格 |
| string.count(str) | 回傳str在string里面出現的次數 |
| string.dencode(‘utf-8’) | 把str里面的內容編碼 |
| string.decode(‘utf-8’) | 把str里面的內容解碼 |
| string.isdigit() | 判斷是否為數字 |
| string.isalpha() | 判斷是否為字母 |
| string.lstrip() | 去除string左側的空格 |
| string.rstrip() | 去除string右側的空格 |
| string.strip() | 去除字串前后的空格 |
| srting.splist() | 分割字串并寫入串列中 |
| ’ '.join(list) | 以空格來拼接list里面的元素 |
| string.lower() | 轉換字串中所有大寫的為小寫 |
| string. upper() | 轉換字串所有為大寫 |
| string.title() | 轉換字串中所有第一個字串為大寫 |
| string. max(str) | 回傳str中最大的字母 |
| string. min(str) | 回傳str中最小的字母 |
| string. isupper() | 如果字串中包含至少一個區分大小寫的字符,并且所有這些(區分大小寫的)字符都是大寫,回傳值為True,否則False |
| string. islower | 如果字串中包含至少一個區分大小寫的字符,并且所有這些(區分大小寫的)字符都是小寫,回傳值為True,否則False |
| string. istitle | 如果字串是標題化則回傳True,否則False |
| string. isnumeric | 如果字串中全是數字字符,回傳True,否則False |
| string. rfind | 從右側檢索(倒敘)想要查的字串或者字符,并列印其位置數字,如果未查到回傳-1 |
| string. find | 可以正序(左側)查找到想要查到的字串或者字符,并列印其位置數字,如果未查到回傳-1 |
| string. replace | replace(old,new,[max]) max代表替換幾次 |
| len(string) | 統計string的長度 |
3、List(串列):
1)創建串列
list = [] #空串列
list = [“value”,154,‘a’] #串列中的內容可以是不同型別的
2)更新串列
串列是可以變更的型別
list = [“aaa”,“bbb”,111,222]
list[1] = “ccc” #將串列的第二個元素更改為"ccc"
3)查看串列內的指定元素
list[1] #查看串列的第二個元素
list[-1] #查看串列的倒數第一個元素
4)洗掉串列的元素
del list[1] #洗掉串列第二個元素
5)串列腳本運算子
串列對+ 和*的運算子與字串相似,+號用于組合串列,*號用于重復串列,
如下表:
| Python運算式 | 結果 | 描述 |
|---|---|---|
| len([1,2,3]) | 3 | 長度 |
| [1,2,3]+[4,5,6] | [1,2,3,4,5,6] | 組合 |
| [“Python”]*4 | [‘Python’, ‘Python’, ‘Python’, ‘Python’] | 重復 |
| 3 in [1,2,3] | True | 判斷元素是否存在于串列 |
| for i in [1,2,3]:print(i,end=’ ') | 1 2 3 | 迭代 |
串列切片截取:
> list1 = [1,2,3,4]
> print(list1[1:4])
[2,3,4]
串列的拼接:
> list1 = [1,2,3,4]
> print(list1 + [“a”,“b”,“c”])
[1, 2, 3, 4, ‘a’, ‘b’, ‘c’]
串列在末尾添加物件:
> list1 = [1,2,3,4]
> list1.append(“aa”)
> print(list1)
[1, 2, 3, 4, ‘aa’]
統計某個str,在串列出現的次數:
> list1 = [1,2,3,3]
> print(list1.count(3))
2
向串列添加另外一個串列的內容:
> list1 = [1,2,3,3]
> list2 = [‘a’,‘b’]
> list1.extend(list2)
> print(list1)
[1, 2, 3, 3, ‘a’, ‘b’]
檢索串列里指定的值的第一次匹配到的索引位置:
> list2 = [‘a’,‘b’]
> print(“第一個匹配b的位置為:”,list2.index(“b”))
第一個匹配b的位置為: 1
在串列指定位置插入物件:
> list2 = [‘a’,‘b’]
> list2.insert(0,“w”)
> print(list2)
[‘w’, ‘a’, ‘b’]
移除串列中指定元素索引位置的物件:
#移除list2中的b
> list2 = [‘a’,‘b’,‘c’]
> list2.pop(1)
> print(list2)
[‘a’, ‘c’]
移除串列中指定元素第一個匹配到的物件:
#移除list2中的第一個a
> list2 = [‘a’,‘b’,‘c’,‘a’]
> list2.remove(‘a’)
> print(list2)
[‘b’, ‘c’, ‘a’]
反向排序串列的物件:
> list2 = [‘a’,‘b’,‘c’]
> list2.reverse()
> print(list2)
[‘c’, ‘b’, ‘a’]
自定義串列輸出降序還是升序:
#自定義串列物件降序輸出
> list2 = [‘a’,‘d’,‘c’]
> list2.sort(reverse=True)
> print(list2)
[‘d’, ‘c’, ‘a’]
#自定義串列物件升序輸出
> list1 = [1,2,3,3] list2 = [‘a’,‘d’,‘c’]
> list2.sort(reverse=False)
> print(list2)
[‘a’, ‘c’, ‘d’]
清空串列物件:
> list2 = [‘a’,‘d’,‘c’]
> list2.clear()
> print(“list2–>”,list2)
list2–> []
復制串列物件:
> list2 = [‘a’,‘d’,‘c’]
> list3 = list2.copy()
> print(“list3:”,list3,“list2:”,list2)
list3: [‘a’, ‘d’, ‘c’] list2:[‘a’, ‘d’, ‘c’]
4、Tuple(元組):
Python的元組與串列類似,不同之處在于元組的元素不能修改,
元組使用小括號來表示,
1)創建元組
創建空的元組:
> tup = ()#創建空元組
> print(“tup的內容:”,tup)
tup的內容: ()
創建一個元組:
> tup1 = (‘aa’,‘bb’,‘cc’)
> print(“tup1內容:”,tup1)
tup1內容: (‘aa’, ‘bb’, ‘cc’)
注意:
> tup1 = (‘aa’,) #創建只有單個元素的元組的時候需要加個逗號,不然創建的是str
> print(“tup1的型別為:”,type(tup1),“tup1的內容為:”,tup1)
tup1的型別為: <class ‘tuple’> tup1的內容為: (‘aa’,)
2)查看元組
元組也可以用下表索引來查看元組中的值,和字串、串列一樣:
> tup1 = (‘aa’,‘bb’,‘cc’)
> print(tup1[0])
tup1[0]的值: aa
> print(tup1[0:3:1])
tup1[0:3:1]的值: (‘aa’, ‘bb’, ‘cc’)
3)修改元組
元組的元素值是不允許修改的,但是卻可以進行連接組合,
> tup2 = (‘aa’,‘bb’,‘cc’) tup3 = (‘11’,‘22’)
> print(‘合并結果為:’,tup2 + tup3)
合并結果為: (‘aa’, ‘bb’, ‘cc’, ‘11’, ‘22’)
tup2 [0] = “c” #元組不允許修改元素內的值,這樣操作會報錯
4)洗掉元組
元組中的元素值是不允許洗掉的,但是可以用del來洗掉整個元組
> tup5 = (“aaa”,)
> del tup5
print(tup)
#這個時候會報錯,因為tup被del洗掉了,不只是洗掉tup內的值,而是洗掉元組本身
5)元組運算子
與字串一樣,元組之間可以使用+號和*號進行運算,
6)元組內置函式
| 方法及描述 | 實體 |
|---|---|
| len(tuple) 計算元組中元素個數 | tup = (‘aa’,‘bb’) len(tup) #2 |
| max(tuple) 回傳元組中最大的元素 | tup = (‘aa’,‘bb’) max(tup) #bb |
| min(tuple) 回傳元組中最小的元素 | tup = (‘aa’,‘bb’) min(tup) #aa |
| tuple(list) 將串列轉換為元組 | list=[‘11’,‘22’ tup=tuple(list)] |
5、Sets(集合):
Python set是基本資料型別的一種集合型別,它有可變集合(set())和不可變集合(frozenset)兩種,集合是一個無序的,不重復的資料組合,主要作用為:去重(把一個串列變成集合,就自動去重了),測驗兩組資料的交集、差集、并集等,set里面可以是多種資料型別(但不能是串列,集合,字典,可以是元組),
1)創建集合set
使用大括號或者set()來創建集合,如果想要創建空集合,必須使用set()來創建,
空集合:
> set2 = set()
> print(“set2的內容:”,set2,“set2的型別為:”,type(set2)) set2的內容:
set() set2的型別為: <class ‘set’>
創建個集合:
> set1 = {‘aa’,‘cc’,‘bb’}
> print(“set1的型別為:”,type(set1),“set1的內容:”,set1)
set1的型別為: <class ‘set’> set1的內容: {‘bb’, ‘aa’, ‘cc’}
2)為集合添加元素
set1.add(“dd”)#在集合后邊添加"dd",如果添加的元素是重復的,則不會進行操作
> set1 = {‘aa’,‘cc’,‘bb’}
> set1.add(‘dd’)
> print(“set1的內容:”,set1)
set1的內容: {‘dd’, ‘aa’, ‘cc’, ‘bb’}
3)更新集合
s.update(x) #x可以是串列,元組,字典等,x可以有多個,用逗號分開,但是x不能是單獨的數字(添加多個數字字符或者字串)
> listing = [‘ab’,12]
> set3 = {1,“a”}
> set3.update(listing)
> print(“set3內容:”,set3,“set3型別:”,type(set3))
set3內容: {1, 12, ‘a’, ‘ab’} set3型別: <class ‘set’>
set2.update(1)#會被報錯
set2.update(“sss”)#只會添加一個"s"
> set2.update(‘sss’)
> print(“set2內容為:”,set2)
set2內容為: {‘s’}
4)洗掉元素
seting.discard(“ab”)#洗掉s中的"ab"元素,如果"ab”不存在,不會進行操作,不報錯,
> seting = {‘ab’,‘bc’,12}
> seting.discard(‘ab’)
> print(“seting的內容為:”,seting)
seting的內容為: {‘bc’, 12}
seting.remove(“12”)#移除s中的"12"元素,如果“12“不存在,會報錯,
> seting = {‘ab’,‘bc’,12}
> seting.remove(12)
> print(“seting的內容為:”,seting)
seting的內容為: {‘ab’, ‘bc’}
seting.pop()#隨機洗掉并回傳集合seting中某個值,因為set是無序的,所以pop洗掉的只是隨機的一個元素,
> seting = {‘ab’,‘bc’,12}
> seting.pop()
> print(“seting的內容為:”,seting)
#隨機洗掉一個元素
seting.clear()#清空s中的所有元素
> seting = {‘ab’,‘bc’,12}
> seting.clear()
> print(“seting的內容為:”,seting)
seting的內容為: set()
5)集合內置函式和實體
| 方法及描述 | 實體 |
|---|---|
| x in s | s={‘a’,‘b’} x=‘b’ print(x in s) #結果回傳True |
| union() | c = s.union(x) #c的結果為s和x的并集,不改變s, x可以是串列,元組,字典 |
| intersection() | c = s.intersection(x) #c的結果為s和x的交集,不改變s, x可以是串列,元組,字典 |
| difference() | c = s.difference #c的值=集合s中而不再集合x中的元素的集合,不改變集合s,x也可以是串列,元組和字典 |
| symmetric_difference() | c = s.symmetric_difference() #c的值=s和集合x的對稱差集,即只在其中一個集合中出現的元素,不改變集合s |
| issubset() | c = s.issubset(x) #判斷集合s是否是集合x的子集,回傳值為布林值 |
| issuperset() | c = s.issuperset(x) #判斷集合x是否是集合s的子集,回傳值為布林值 |
| isdisjoint() | c = s.isdisjoint(x) # 判斷s和s1是否完全沒有任何交集,回傳值為布林值 |
6)集合運算子:
s1 & s2 #求兩個集合的交集
s1 | s2 #求兩個集合的并集
s1 - s2 #求s1減去s2的差集
s1 ^ s2 #求兩個集合的對稱差集(對稱差值:不包含同時存在兩個集合的值)
6、Dictionaries(字典):
字典是另一種可變容器模型,且可存盤任意型別物件,
字典的每個鍵值(key=>value)對用冒號(:)分割,每個對之間用逗號(,)分割,整個字典包括在花括號中:
1)創建字典:
鍵必須是唯一的,但值則不必,值可以取任何資料型別,但鍵必須是不可變的,如字串,數字或元組,
格式:dic = {key:value,key1:value1}
> dic = {“name”:“eric”,“pass”:123}
> print(“dic的型別為:”,type(dic),“dic的內容為:”,dic) dic的型別為:<class ‘dict’>
dic的內容為: {‘name’: ‘eric’, ‘pass’: 123}
2)訪問字典里面的值:
根據鍵來查看值:
> dic = {“name”:“eric”,“pass”:123}
> print(“name這個鍵對應的值為:”,dic[‘name’])
name這個鍵對應的值為: eric
3)更新字典:
1)根據鍵修改值:
> dic = {“name”:“eric”,“pass”:123}
> dic[“name”] = “lucky”
> print(“修改后的值為:”,dic)
修改后的值為: {‘name’: ‘lucky’, ‘pass’: 123}
2)添加新的元素(鍵值對)
> dic = {“name”:“eric”,“pass”:123}
> dic[“age”] = 23
print(“添加后的值為:”,dic)
添加后的值為: {‘name’: ‘lucky’, ‘pass’: 123, ‘age’: 23}
4)洗掉字典元素:
1)洗掉指定的鍵
> dic = {“name”:“eric”,“pass”:123}
> del dic[“pass”]
> print(“洗掉后的值為:”,dic)
洗掉后的值為: {‘name’: ‘eric’}
2)洗掉所有的元素
> dic = {“name”:“eric”,“pass”:123}
> dic.clear()
> print(“clear后的值:”,dic)
clear后的值: {}
3)洗掉字典
> dic = {“name”:“eric”,“pass”:123}
> del dic
NameError: name ‘dic’ is not defined
5、字典鍵的特性
字典值可以是任何的Python物件,既可以是標準的物件,也可以是用戶定義的,但是鍵不行,
1)不允許同一個鍵出現兩次,創建時如果同一個鍵被賦值兩次,后一個值會被記住:
> dict = {‘age’:10,‘name’:“wang”,‘age’:18}
> print(dict)
{‘age’: 18,‘name’: ‘wang’}
2)鍵必須不可變,可以用數字、字串或者元組,可變型別不能作為鍵,比如串列,
6、字典內置函式和方法
Python字典包含了以下內置函式:
| 函式 | 描述 |
|---|---|
| len(dict) | 計算字典元素個數,即鍵的個數 |
| str(dict) | 輸出字典,可以列印成字串格式 |
| clear() | 洗掉字典內所有元素 |
| c = dic.copy() | 回傳一個字典的淺復制 |
| formkeys() | 創建一個新的字典,以序列seq中元素做字典的鍵,val為字典所有鍵對應的初始值 |
| values() | 以串列回傳字典中的所有值 |
| keys() | 以串列回傳字典中的所有鍵 |
| pop(key[,default]) | 洗掉字典指定鍵key所對應的值,回傳值為被洗掉的值,key值必須給出,否則,回傳default |
| popitem() | 隨機洗掉字典中的一對鍵和值(一般洗掉末尾對), |
| items() | 以串列回傳可遍歷的(鍵,值)元組陣列 |
| key in dict | 如果鍵在字典dict里回傳True,否則回傳False |
| get(key) | 回傳指定鍵的值,如果值不在字典中回傳default值 (默認為none) |
注意:
fromkeys 方法只用來創建新字典,不負責保存,如果想要保存要把它賦值給其他的變數
> seq = (‘Google’, ‘Runoob’, ‘Taobao’)
> dict = dict.fromkeys(seq)
> print(“新字典為 : %s” % str(dict))
新字典為 : {‘Google’: None, ‘Runoob’: None,‘Taobao’: None} dict = dict.fromkeys(seq, 10)
> print (“新字典為 : %s” % str(dict))
新字典為 : {‘Google’: 10, ‘Runoob’: 10, ‘Taobao’: 10}
pop()
> dic = {‘age’:10,‘name’:“wang”}
> print(dic.pop(‘age’))
洗掉的值為: 10
> print(dic)
dic字典的內容還有: {‘name’: ‘wang’}
popitem()
> dic = {‘age’:10,‘name’:“wang”}
> print(“洗掉的值為:”,dic.popitem())
洗掉的值為:(‘name’, ‘wang’)
> print(“dic字典的內容還有:”,dic)
dic字典的內容還有: {‘age’: 10}
get()
> dic = {‘age’:10,‘name’:“wang”}
print(“檢索的結果為:”,dic.get(“a”))
“檢索的結果為:”,None
print(“檢索的結果為:”,dic.get(“age”)) "
檢索的結果為:",10
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/255218.html
標籤:python
上一篇:一些python函式的語法