
文章目錄
- 前言
- 網站分析
- 獲取所有公開博客的鏈接
- 網頁分析
- 測驗檔案
- 三個問題擺在眼前
- 問題一解決方案:
- 問題二解決方案:
- 問題三解決方案
- 思路一:
- 思路二:
- 思路三:
- 我的選擇
- 結果分析
- 新結果分析
- 界面Xpath
- 爬取一篇博客
- 正則運算式分析
- 正則運算式測驗
- 狀態機
- 保存到檔案
- 獲取全部博客
前言
這次玩點刺激的,爬取我的所有博客,
當然,這事兒只有我能干,你們要爬可以爬自己的,后面我會把代碼和分析結果放出來,
這兩周發生了些不太愉快的事情,反正我現在是挺失望的,
網站分析
獲取所有公開博客的鏈接
剛開始呢,我想找網站地圖,看看能不能找到屬于我的那一塊兒,后來發現是我想多了,網站地圖是有,但是那么多博主,一人搞一個也不太現實,于是這條路就走不通了,
接下來,我又去了“文章管理”界面,但是我馬上就發現了這是一個動態網頁,
我看了看底部的頁碼,十五頁,說多頁多,說少也少,反正就挺尷尬一個數的,
我想了想,這個頁面比主頁要簡單點,抓個包看看吧,
找到了文章ID的包,發現網址單獨拿出來打不開,于是又放棄了,
最后,我又回到了主頁,
底部的頁碼一看,七頁,可以,動手吧,
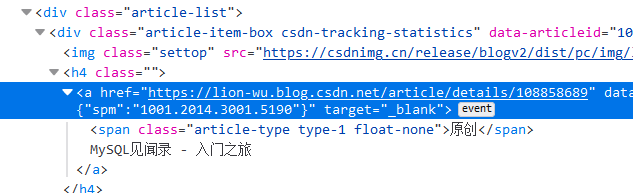
我本來想著,鏈接和標題一起拿了,后來轉念一想,,文章里面也是有標題的,到時候一起拿就好了,
于是開始寫代碼,
有一說一啊,取Xpath的時候,谷歌確實好用,用火狐取出來的Xpath一直放空,谷歌取出來的是相對Xpath,一步到位,
import requests
import threadpool
from lxml import etree
import pandas as pd
cookie = '放你自己的'
header = {
'User-Agent': '放你自己的',
'Connection': 'keep-alive',
'accept': 'application/json, text/javascript, */*; q=0.01',
'Cookie': cookie,
'referer': '放你自己的主頁'
}
url_list = ['https://lion-wu.blog.csdn.net/article/list/1', 'https://lion-wu.blog.csdn.net/article/list/2', 'https://lion-wu.blog.csdn.net/article/list/3', 'https://lion-wu.blog.csdn.net/article/list/4', 'https://lion-wu.blog.csdn.net/article/list/5', 'https://lion-wu.blog.csdn.net/article/list/6', 'https://lion-wu.blog.csdn.net/article/list/7'] # 這個鏈接很有規律的
keep_url_list = [] # 這個用來
def outdata(url):
try:
print('succeed'+url)
res = requests.get(url,headers=header)
wbdata = res.content.decode('UTF-8')
tree = etree.HTML(wbdata)
el_list = tree.xpath('//*[@id="articleMeList-blog"]/div[2]//div/h4/a/@href')
print(el_list)
keep_url_list.append(el_list)
except:
print('failed'+url)
def Thread_Pool(outdata,datalist = None,Thread_num = 5):
'''
執行緒池操作,創建執行緒池、規定執行緒池執行任務、將任務放入執行緒池中、收工
:param outdata: 函式指標,執行緒池執行的任務
:param datalist: 給前面的函式指標傳入的引數串列
:param Thread_num: 初始化執行緒數
:return: 暫無
'''
pool = threadpool.ThreadPool(Thread_num) # 創建Thread_num個執行緒
tasks = threadpool.makeRequests(outdata, datalist) # 規定執行緒執行的任務
# outdata是函式名,datalist是一個引數串列,執行緒池會依次提取datalist中的引數引入到函式中來執行函式,所以引數串列的長度也就是執行緒池所要執行的任務數量,
[pool.putRequest(req) for req in tasks] # 將將要執行的任務放入執行緒池中
pool.wait() # 等待所有子執行緒執行完之后退出
Thread_Pool(outdata,datalist=url_list,Thread_num = 7)
#outdata('https://lion-wu.blog.csdn.net/article/list/1')
u2 = []
for i in keep_url_list:
for j in i:
print(j)
u2.append(j)
pd.DataFrame(u2).to_csv('My_CSDN.csv')
網頁分析
測驗檔案
本文使用測驗檔案:測驗檔案,要自己動手實作的朋友請打開測驗檔案跟著操作,
三個問題擺在眼前
隨便點開了一篇博客的原始碼,看到里面不同的部件有不同的標簽,
那么這里就涉及到了三個問題:
1、我總共用了多少不同的效果?
2、在爬取的時候,如何使不同的標簽下的資料在存盤的時候保持原有的順序
3、標簽的標記是否需要留下
問題一解決方案:
第一個問題好辦,打開編輯界面就可以很清楚的看到所有的效果了:

回憶一下我用過的所有效果,有:
文章標題、文內標題、(目錄)、加黃標、加粗、斜體、無序、有序、待辦、【參考】、【代碼塊】、【圖片】、【表格】、【超鏈接】、【分隔線】
打括號的是不要的,打中括號的是常用的,
那,要怎么看這些效果在原始碼里的體現呢,去找是不可能去找的了,寫一篇博客,把這些功能都包進去測驗就好了,
問題二解決方案:
對于問題二啊,我也糾結了一會兒,因為我不知道Xpath在爬取多個不同標簽的時候能否保留住他們原有的順序,
百度了一會兒,說真的,全是屁話,
于是我就做了個demo測驗了一下:
import requests
from lxml import etree
# 前面這一串不再放出
def outdata(url):
try:
print('succeed'+url)
res = requests.get(url,headers=header)
wbdata = res.content.decode('UTF-8')
tree = etree.HTML(wbdata)
el_list = tree.xpath('//*[@id="articleMeList-blog"]/div[2]//div/h4/a')
for el in el_list:
e = el.xpath('./text() | ./@href')
# 我特地把順序反過來,就是要排除這種可能,因為真的開始爬的時候是不會事先讓你知道順序規律的,也沒有規律可言,
print(e)
except:
print('failed'+url)
outdata('https://lion-wu.blog.csdn.net/article/list/1')
結果證明是成功的,再做點字串切割切掉轉義字符和前后空格就行了,
問題三解決方案
本來以為這個問題是最簡單的,只是我想不想留的問題,后來發現不是這樣的,
思路一:
對于這個問題,如果直接上手去抓標簽里面的文本的話,最終是會丟失掉標簽的,
這個問題我想了想,我們可以先將文章標題取下,
之后取下文章正文部分的全部原始碼,用正則運算式對原始碼中的各標簽打上標記,
之后再用Xpath將文本和鏈接取出來,
結果:轉成字串之后轉不回來了、、、
于是,我又產生了一個想法,
思路二:
首先,非硬性需求的特效就不要了,比方說加粗、斜體、黃標、下劃線這種的,就不要了,無序,有序,待辦歸為一類,也不要了,
這樣一選擇,那么需要注意的特效(單獨再提取一份出來作為標記)就只有:參考、代碼塊、圖片、表格、超鏈接了,
參考,代碼塊只標記首尾,表格把表頭取出之后底下的也只標記首尾,
超鏈接和圖片鏈接需要拿出來,
剩下的就交給匹配演算法的事情了,
就是說,先把文本和鏈接全部提取出來,再重頭提取一些重要資訊,
這個只是復雜度高一些,實作還是沒問題的,
思路三:
在Xpath提取的時候,看看能不能直接對文本進行標記,如果可以的話,那就最好,
我的選擇
我選三,實作了,
方法一里面不是有說,將etree物件轉化為字串嗎?
那我完全可以先把標簽都選下來,我不取文本,我直接轉字串,這樣不就連標簽帶文本全拿下來了嗎?最后我們通過正則運算式將HTML代碼中很長的標簽轉換為比較短的標簽,
來看一下從測驗檔案上抓下來的標簽們:
def outdata(url):
try:
print('succeed'+url)
res = requests.get(url,headers=header)
code = res.apparent_encoding # 獲取url對應的編碼格式
res.encoding = code
wbdata = res.text
tree = etree.HTML(wbdata)
el_list = tree.xpath('//*[@id="content_views"]')
for el in el_list:
# e = etree.tostring(el, encoding=code).decode(code)
# 這一步可以獲取文章主體的原始碼部分
#界面xpath在下面有提供
es = el.xpath('./h1 |./h2 |./h3 |./h4 |./h5 |./h6 |./p |./p/mark |./p/span/span/span/span[2]//span/span[2]'
'|./p/strong |./p/em |./ul//li |./ol//li |./ul//li |./blockquote/p |./pre/code |./p/code '
'|./div/table/thead/tr//th |./div/table/tbody/tr//td |./hr |./p/img |./p/a')
for e in es:
print(etree.tostring(e, encoding=code).decode(code))
print('-----') # 除錯所用,使得結果更清晰
except:
print('failed'+url)
結果:
succeedhttps://lion-wu.blog.csdn.net/article/details/113402976
<p/>
-----
<p/>
-----
<h1><a id="_2"/>一級標題</h1>
-----
<h2><a id="_3"/>二級標題</h2>
-----
<h3><a id="_4"/>三級標題</h3>
-----
<h4><a id="_5"/>四級標題</h4>
-----
<h5><a id="_6"/>五級標題</h5>
-----
<h6><a id="_7"/>六級標題</h6>
-----
<p>這是一篇測驗檔案,現在不知道干嘛用很正常,我在寫一個爬蟲的專案,等我爬蟲自學系列最后一篇出來就知道啦,到時候如果你們想復現的話,直接來我這里拿就好,</p>
-----
<p><span class="katex--display"><span class="katex-display"><span class="katex"><span class="katex-mathml">
a
=
b
+
c
a = b + c
</span><span class="katex-html"><span class="base"><span class="strut" style="height: 0.43056em; vertical-align: 0em;"/><span class="mord mathdefault">a</span><span class="mspace" style="margin-right: 0.277778em;"/><span class="mrel">=</span><span class="mspace" style="margin-right: 0.277778em;"/></span><span class="base"><span class="strut" style="height: 0.77777em; vertical-align: -0.08333em;"/><span class="mord mathdefault">b</span><span class="mspace" style="margin-right: 0.222222em;"/><span class="mbin">+</span><span class="mspace" style="margin-right: 0.222222em;"/></span><span class="base"><span class="strut" style="height: 0.43056em; vertical-align: 0em;"/><span class="mord mathdefault">c</span></span></span></span></span></span></p>
-----
<span class="mord mathdefault">a</span>
-----
<span class="mord mathdefault">b</span>
-----
<span class="mord mathdefault">c</span>
-----
<p><mark>這是突出字體</mark></p>
-----
<mark>這是突出字體</mark>
-----
<p><strong>這是加粗字體</strong></p>
-----
<strong>這是加粗字體</strong>
-----
<p><em>這是斜體</em></p>
-----
<em>這是斜體</em>
-----
<li>這是無序</li>
-----
<li>這還是無序</li>
-----
<hr/>
-----
<li>這是有序</li>
-----
<li>這還是有序</li>
-----
<hr/>
-----
<li class="task-list-item"><input type="checkbox" class="task-list-item-checkbox" disabled="disabled"/> 這是待辦</li>
-----
<li class="task-list-item"><input type="checkbox" class="task-list-item-checkbox" disabled="disabled"/> 這依舊是待辦</li>
-----
<li>這是有序</li>
-----
<li>這還是有序</li>
-----
<hr/>
-----
<p>這里是參考<br/> 這里還是參考</p>
-----
<code class="prism language-python">代碼塊在這里
</code>
-----
<hr/>
-----
<p>這里是參考<br/> 這里還是參考<br/> 這里是參考<br/> 這里還是參考<br/> 這里是參考<br/> 這里還是參考<br/> 這里是參考<br/> 這里還是參考</p>
-----
<code class="prism language-python">代碼塊在這里
</code>
-----
<p><img src="https://img-blog.csdnimg.cn/20210129182417155.jpg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQzNzYyMTkx,size_16,color_FFFFFF,t_70" alt="在這里插入圖片描述"/></p>
-----
<img src="https://img-blog.csdnimg.cn/20210129182417155.jpg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQzNzYyMTkx,size_16,color_FFFFFF,t_70" alt="在这里插入图片描述"/>
-----
<p><a href="https://blog.csdn.net/qq_43762191?spm=1001.2101.3001.5343">超鏈接,順著網線來打我啊!!!</a></p>
-----
<a href="https://blog.csdn.net/qq_43762191?spm=1001.2101.3001.5343">超鏈接,順著網線來打我啊!!!</a>
-----
<hr/>
-----
<p>別忘了下劃線哦<code>這是行代碼</code></p>
-----
<code>這是行代碼</code>
-----
結果分析
分析一下這里的結果,我們才好對下一步進行決策嘛,
1、首先,第一眼就看到了那一大串標簽圍繞的公式了,我不記得我還有沒有帶公式的博客,就留著吧,反正也是一個正則的事情,
2、其次一個很明顯的就是重復問題了,
之前直接提取文本的時候不會出現,因為‘/’僅僅提取當前子路徑下的所有,但是現在轉了字串,那么‘./p’就成了很多個以‘./p’開頭的標簽的上級標簽了,這時候重復的出現就是必然的了,
在取標簽的時候,這似乎是不可調和的矛盾,那就只好在取出標簽之后進行一次去重了,
所以我還得寫一個去重的函式
3、對于上面這個問題,還有一個解決方法,即在取標簽的時候,對于所有以‘./p/’開頭的標簽全部不留,只留下‘./p’,后面取標簽的時候將</p>的優先級設為最低
再看一下效果,
succeedhttps://lion-wu.blog.csdn.net/article/details/113402976
<p/>
-----
<p/>
-----
<h1><a id="_2"/>一級標題</h1>
-----
<h2><a id="_3"/>二級標題</h2>
-----
<h3><a id="_4"/>三級標題</h3>
-----
<h4><a id="_5"/>四級標題</h4>
-----
<h5><a id="_6"/>五級標題</h5>
-----
<h6><a id="_7"/>六級標題</h6>
-----
<p>這是一篇測驗檔案,現在不知道干嘛用很正常,我在寫一個爬蟲的專案,等我爬蟲自學系列最后一篇出來就知道啦,到時候如果你們想復現的話,直接來我這里拿就好,</p>
-----
<p><span class="katex--display"><span class="katex-display"><span class="katex"><span class="katex-mathml">
a
=
b
+
c
a = b + c
</span><span class="katex-html"><span class="base"><span class="strut" style="height: 0.43056em; vertical-align: 0em;"/><span class="mord mathdefault">a</span><span class="mspace" style="margin-right: 0.277778em;"/><span class="mrel">=</span><span class="mspace" style="margin-right: 0.277778em;"/></span><span class="base"><span class="strut" style="height: 0.77777em; vertical-align: -0.08333em;"/><span class="mord mathdefault">b</span><span class="mspace" style="margin-right: 0.222222em;"/><span class="mbin">+</span><span class="mspace" style="margin-right: 0.222222em;"/></span><span class="base"><span class="strut" style="height: 0.43056em; vertical-align: 0em;"/><span class="mord mathdefault">c</span></span></span></span></span></span></p>
-----
<p><mark>這是突出字體</mark></p>
-----
<p><strong>這是加粗字體</strong></p>
-----
<p><em>這是斜體</em></p>
-----
<li>這是無序</li>
-----
<li>這還是無序</li>
-----
<hr/>
-----
<li>這是有序</li>
-----
<li>這還是有序</li>
-----
<hr/>
-----
<li class="task-list-item"><input type="checkbox" class="task-list-item-checkbox" disabled="disabled"/> 這是待辦</li>
-----
<li class="task-list-item"><input type="checkbox" class="task-list-item-checkbox" disabled="disabled"/> 這依舊是待辦</li>
-----
<li>這是有序</li>
-----
<li>這還是有序</li>
-----
<hr/>
-----
<p>這里是參考<br/> 這里還是參考</p>
-----
<code class="prism language-python">代碼塊在這里
</code>
-----
<hr/>
-----
<p>這里是參考<br/> 這里還是參考<br/> 這里是參考<br/> 這里還是參考<br/> 這里是參考<br/> 這里還是參考<br/> 這里是參考<br/> 這里還是參考</p>
-----
<code class="prism language-python">代碼塊在這里
</code>
-----
<p><img src="https://img-blog.csdnimg.cn/20210129182417155.jpg?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzQzNzYyMTkx,size_16,color_FFFFFF,t_70" alt="在這里插入圖片描述"/></p>
-----
<p><a href="https://blog.csdn.net/qq_43762191?spm=1001.2101.3001.5343">超鏈接,順著網線來打我啊!!!</a></p>
-----
<hr/>
-----
<p>別忘了下劃線哦<code>這是行代碼</code></p>
-----
新結果分析
新結果,不論是在重復方面,還是在文字解碼方面,都要優于上面的結果,所以我重新做一次分析,
1、首先,如果判斷出來是公式的話,切分之后去掉空的部分,取倒數第二個元素即可,
2、如果是參考的話,還是換這個標簽:./blockquote來抓取比較好,因為不排除出現單行參考,那就和</p>區分不了了,
這樣獲得的結果就是:
<blockquote>
<p>這里是參考</p>
</blockquote>
或者
<blockquote>
<p>這里是參考<br/> 這里還是參考<br/> 這里是參考<br/> 這里還是參考<br/> 這里是參考<br/> 這里還是參考<br/> 這里是參考<br/> 這里還是參考</p>
</blockquote>
3、在獲取圖片鏈接的時候,要注意將前后剔除干凈,
4、注意行代碼的提取,
5、正則時,既要提取標簽,也要提取出文字,需要注意存放的問題,
其他的也沒有啥了
界面Xpath
首先,標記以及正文部分都在這個標簽之下://*[@id="mainBox"]/main/div[1]
標題在這里://*[@id="articleContentId"]
正文在這里://*[@id="content_views"]
文中標題所在位置:
//*[@id="content_views"]//h1
//*[@id="content_views"]//h2
//*[@id="content_views"]//h3
//*[@id="content_views"]//h4
//*[@id="content_views"]//h5
//*[@id="content_views"]//h6
段落文本所在位置://*[@id="content_views"]//p
黃色標標所在位置://*[@id="content_views"]//p/mark
公式------所在位置://*[@id="content_views"]//p/span/span/span/span[2]//span/span[2]
黑色加粗所在位置://*[@id="content_views"]//p/strong
斜體字—所在位置://*[@id="content_views"]//p/em
無序標簽所在位置://*[@id="content_views"]//ul//li/text()
有序標簽所在位置://*[@id="content_views"]//ol//li/text()
待辦和無序是一樣的,不管了,反正也只是用著好玩,
參考標簽所在位置://*[@id="content_views"]//blockquote/p//text()
代碼塊兒所在位置://*[@id="content_views"]//pre/code/text()
行代碼—所在位置://*[@id="content_views"]//p/code
超鏈接—所在位置://*[@id="content_views"]//p/a
表格表頭所在位置://*[@id="content_views"]//div/table//th
表格內容所在位置://*[@id="content_views"]//div/table//td
下劃線—所在位置://*[@id="content_views"]//hr
圖片://*[@id="content_views"]//p/img
爬取一篇博客
經過上面縝密的分析,我準備完整的爬取一篇博客并保存到正確的檔案中,
爬哪篇呢?自然是測驗檔案了,
正則運算式分析
經過一會兒的努力,我寫出了這樣的正則運算式:
res = re.findall('(<.+?>)',string = string)
#res2 = re.findall('(>.*?<)',string = string)
res2 = re.findall('(>[\s\S]*?<)',string=string)
print(res)
# 因為在提取第二個正則運算式的時候,會帶上‘>’和‘<’,所以需要剔除一下
for r2 in range(len(res2)):
res2[r2] = res2[r2].replace('>', '').replace('<', '').replace('\n', '').strip()
# 在遍歷時修改需要使用下標
# 字串一旦寫完,就不能通過下標對其進行修改
for r3 in res2[:]: # 不用res2[:]的話,遍歷會跳步
if r3 == '':
res2.remove(r3)
result = ''.join(res2) # 這里不應該簡單整合,這個整合給公式就好了,
# 這段操作稍后會單獨整理一份博客,
print(result)
正則運算式測驗
首先,拿最簡單的先試一下:
string = '<h1><a id="_2"/>一級標題</h1>'
['<h1>', '<a id="_2"/>', '</h1>']
一級標題
說明這個運算式初步可用了,
再拿長一點的:
['<p>', '</p>']
這是一篇測驗檔案,現在不知道干嘛用很正常,我在寫一個爬蟲的專案,等我爬蟲自學系列最后一篇出來就知道啦,到時候如果你們想復現的話,直接來我這里拿就好,
應該可以看出來拿的是哪個啊,
接下來,就是我們前面看著就煩的公式部分了,
能否成功呢?
string = '''<p><span class="katex--display"><span class="katex-display"><span class="katex"><span class="katex-mathml">
a
=
b
+
c
a = b + c
</span><span class="katex-html"><span class="base"><span class="strut" style="height: 0.43056em; vertical-align: 0em;"/><span class="mord mathdefault">a</span><span class="mspace" style="margin-right: 0.277778em;"/><span class="mrel">=</span><span class="mspace" style="margin-right: 0.277778em;"/></span><span class="base"><span class="strut" style="height: 0.77777em; vertical-align: -0.08333em;"/><span class="mord mathdefault">b</span><span class="mspace" style="margin-right: 0.222222em;"/><span class="mbin">+</span><span class="mspace" style="margin-right: 0.222222em;"/></span><span class="base"><span class="strut" style="height: 0.43056em; vertical-align: 0em;"/><span class="mord mathdefault">c</span></span></span></span></span></span></p> '''
結果:
['<p>', '<span class="katex--display">', '<span class="katex-display">', '<span class="katex">', '<span class="katex-mathml">', '</span>', '<span class="katex-html">', '<span class="base">', '<span class="strut" style="height: 0.43056em; vertical-align: 0em;"/>', '<span class="mord mathdefault">', '</span>', '<span class="mspace" style="margin-right: 0.277778em;"/>', '<span class="mrel">', '</span>', '<span class="mspace" style="margin-right: 0.277778em;"/>', '</span>', '<span class="base">', '<span class="strut" style="height: 0.77777em; vertical-align: -0.08333em;"/>', '<span class="mord mathdefault">', '</span>', '<span class="mspace" style="margin-right: 0.222222em;"/>', '<span class="mbin">', '</span>', '<span class="mspace" style="margin-right: 0.222222em;"/>', '</span>', '<span class="base">', '<span class="strut" style="height: 0.43056em; vertical-align: 0em;"/>', '<span class="mord mathdefault">', '</span>', '</span>', '</span>', '</span>', '</span>', '</span>', '</p>']
a=b+c
看得出來,很成功啊!!!
但是,等下的演算法里面不能忘記對鏈接的處理,他們可都在標簽里面呢!!!
狀態機
前面的代碼好像還有一點改動,記不得了,
有了這個狀態機,就可以初步的把標簽啥的都打上去了,
當然,還有需要改動的地方,只是目前我覺得性價比不高,就沒寫,
def get_div_name(div_list):
'''
這是一個用于提取標簽的狀態機
:param div_list: 標簽串列
:return: 最終標簽名
'''
if div_list[0] == '<hr/>':
return '【下劃線】'
elif div_list[0][1] == 'h':
hn = re.search('[0-9]{1}',div_list[0]).group(0)
return '【' + hn + '級標題】'
elif div_list[0] == '<li>':
return '【列舉】'
elif div_list[0] == '<li class="task-list-item">':
return '【待辦】'
elif div_list[0] == '<blockquote>':
return '【參考】'
elif '<code class' in div_list[0]:
l = re.search('(-.+?")',div_list[0])
language = l.group(0).replace('-','').replace('"','')
return '【'+language+'語言代碼塊兒】'
elif div_list[0] == '<p>':
if div_list[1] == '</p>':
return '【純文本】'
elif 'katex' in div_list[1]:
return '【公式】'
elif div_list[1] == '<mark>':
return '【黃標突出】'
elif div_list[1] == '<strong>':
return '【加粗】'
elif div_list[1] == '<em>':
return '【斜體】'
elif div_list[1] == '<code>':
return '【行代碼】'
elif 'img' in div_list[1]:
h = re.search('(".+?")',div_list[1])
href = h.group(0).replace('"','').replace('"','')
return '【圖片】:' + href
elif 'href' in div_list[1]:
h = re.search('(".+?")', div_list[1])
href = h.group(0).replace('"', '').replace('"', '')
return '【超鏈接:】'+ href
else:
return ''
else:
return ''
def outdata(url):
try:
print('succeed'+url)
res = requests.get(url,headers=header)
code = res.apparent_encoding # 獲取url對應的編碼格式
res.encoding = code
wbdata = res.text
tree = etree.HTML(wbdata)
el_list = tree.xpath('//*[@id="content_views"]')
for el in el_list:
es = el.xpath('./h1 | ./h2 | ./h3 | ./h4 | ./h5 | ./h6 | ./p |./ul//li | ./ol//li | ./ul//li | ./blockquote | ./pre/code '
'| ./div/table/thead/tr//th | ./div/table/tbody/tr//td | ./hr')
for e in es:
string = etree.tostring(e,encoding=code).decode(code)
res = re.findall('(<.+?>)', string=string)
res2 = re.findall('(>[\s\S]*?<)', string=string)
div_name = get_div_name(res)
for r2 in range(len(res2)):
res2[r2] = res2[r2].replace('>', '').replace('<', '').replace('\n', '').strip()
for r3 in res2[:]: # 不用res2[:]的話,遍歷會跳步
if r3 == '':
res2.remove(r3)
if div_name != '':
res2.insert(0,div_name)
print('\n'.join(res2))
print('-----')
except:
print('failed'+url)
保存到檔案
接近尾聲了啊,
又做了點微調,然后將資料保存到了檔案里面,
def save_to_file(file_name,contant):
'''
這個函式用于將資料寫入到檔案中
:param file_name:檔案名
:param contant: 檔案內容
:return: none
'''
file_path = r'D:\CSDN博客'
if not os.path.exists(file_path): # 如果目標檔案夾不存在
os.mkdir(file_path)
w_file_path = file_path+'\\'+'file_name'+'.txt'
f = open(w_file_path,'w')
for c in contant:
f.write(c)
f.close()
獲取全部博客
其實吧,也就是扔進執行緒池里去處理,
所以就在下面加兩行執行緒池的啟動即可:
url_list = pd.read_csv('My_CSDN.csv')['url']
Thread_Pool(outdata,datalist=url_list,Thread_num = 10)
簡陋了點,但是1.0版本是出來了,接下來就是優化的事情了,
本文代碼還算詳盡,要拿完整代碼,掃旁邊二維碼,后臺回復:“博客”,獲取當前最新版本,
2021.2.1好前會放上第一個版本,
至于私密博客,回頭優化的時候會帶上,

有感情是一回事兒,被欺騙是另一回事兒,被傷過的心還怎么再愛呢?
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/255223.html
標籤:python