B-Tree
B-Tree又叫做B樹,和平衡二叉樹不同的地方在于B樹是多叉樹(平衡多路查找樹),Oracle和MongoDB的索引技術就是基于B樹的資料結構,B樹也可以看作是對2-3查找樹的一種擴展,
一個m階的B-Tree有以下性質
- 每個節點最多有m個子節點;
- 每個非葉子節點(根節點除外)至少含有m/2個子節點;
- 如果根節點不是葉子節點,那么根節點至少有兩個子節點;
- 每個節點上,所有的關鍵字都是有序的,從左到右,依次從小到大排序;
- 每個關鍵字的左子樹的均值小于當前關鍵字,右子樹的均值大于當前關鍵字;
- 每個節點都存有索引和資料;
- 對于一個非葉子節點而言,它最多能存盤m-1個關鍵字;
- 所有葉子節點位于同一層,
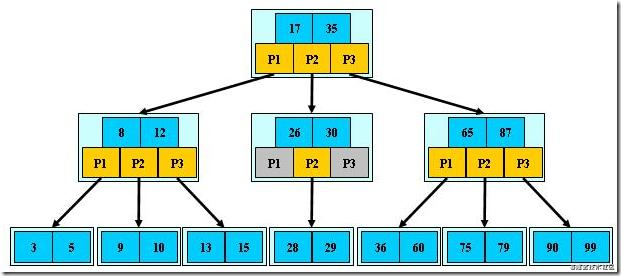
B樹查找
我們以查找13為例子:
第一次磁盤IO:定位到比17小,選擇最左子樹;
第二次磁盤IO:定位到比12大,選擇最右子樹;
第三次磁盤IO:定位到13,查出對應的資料后,查找結束,
B樹插入
對于一個m階B樹,新節點一般是插在葉子層,但是需要根據實際的情況考慮是否需要裂變,
1.若該節點中關鍵碼個數小于m-1,則直接插入;
2.若該節點中關鍵字個數等于m-1,則將進行分裂,以中間關鍵字為界點將節點一分為2,產生一個新的節點,并把中間那個關鍵字插入到父節點中,繼續判斷父節點的關鍵字個數是否等于m-1,依次判斷是否分裂,最壞情況下可一直分裂到根節點,整個樹增加一層,
B樹洗掉
B樹的洗掉也非常復雜
如果關鍵字所在節點的原關鍵樹>=(m/2),說明洗掉后仍可滿足B樹的結構,可以直接干掉,
如果被洗掉后不再滿足B樹的結構,則需要一定的調整程序:
如果其左右兄弟節點中有多余的關鍵字,即與該節點相鄰的節點中關鍵字的數目大于(m/2)-1,就會將兄弟節點中的最大(左兄弟)或者最小(右兄弟)移到夫節點上,然后將雙親節點中小于(右兄弟的上移)或者大于(左節點上移)關鍵字的關鍵字下移到被刪關鍵字的節點中,
如果其左右兄弟都沒有多余關鍵字的時候,情況將變得非常非常復雜;需把洗掉關鍵位元組點與其左(或者右)兄弟節點中的關鍵字合并到(父節點指向該洗掉關鍵位元組點的左(右)兄弟節點的指標)所指向的兄弟節點中去,如果因此父節點中的關鍵字個數小于規定值,則需要對父節點做同樣的處理,最壞情況下會使得整個樹減少一層,
總結
B樹相對于平衡二叉樹的不同是,每個節點包含的關鍵字增多了,特別是在B樹應用到資料庫的時候,資料庫充分利用了磁盤塊的原理(磁盤資料存盤是采用塊的形式存盤的,每個塊的大小為4K,每次IO進行資料讀取時,同一個磁盤塊的資料可以一次性讀取出來)把節點大小限制和充分使用在磁盤塊大小范圍;把樹的節點關鍵字增多后樹的層級比原來的二叉樹少了很多,大大減少了資料查找和比較的次數,提高了效率,
B+樹
B+Tree中如果有N個關鍵字則會擁有n個分支,而B樹中n個關鍵字的節點包含n+1個分支,
B+Tree中,每個非根節點中的關鍵字個數是>=(m/2)且<=m,而B樹是>=(m/2)-1且<=(m-1),
B+Tree中根節點的關鍵字個數是>=1且<=m,而B樹是>=1且<=(m-1),
B+樹是B樹的一個升級版,因為B+Tree非葉子節點不存盤關鍵字記錄的指標,所以其相對于B樹來說B+樹更充分的利用了節點的空間,讓查找速度更加穩定,其速度完全接近于二分查找,
\1. B+樹的非葉子節點不對關鍵字記錄的指標進行保存,只進行資料索引,使得B+樹非葉子節點能保存關鍵字的能力大大提升,而且樹的層級會更少;
2.B+樹葉子節點保存了其父節點的關鍵字記錄的指標,所以每次查詢必須到葉子節點才能真正獲取到相關資料,而且平很多叉樹的特點是所有子節點的層級相差不會超過一,所以查詢速度相對是非常穩定的;
3.B+Tree樹葉子節點的關鍵字從小到大有序排列,左邊結尾資料都會保存右邊節點開始資料的指標;
4.非葉子節點的子節點樹=關鍵字數,
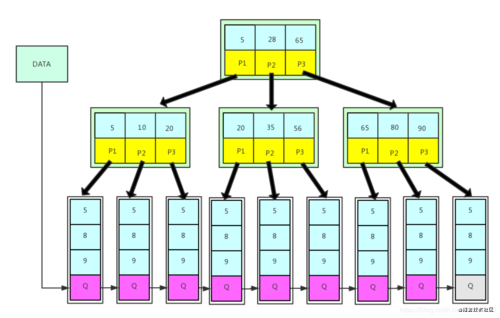
B+樹查找
B+樹的查找規格是B樹一樣,都是按照大小一層一層往下,但是不同點在于其一定會執行到葉子節點,因為只有葉子節點才會存盤資料的指標,
B+樹插入
插入操作全部在葉子節點中進行
1.若為空樹,創建一個葉子節點,然后將記錄插入,同時這個葉子節點也是根節點;
2.若被插入的關鍵字所在的節點,其含有的關鍵字數目小于m,則直接插入;
3.若被插入關鍵字所在的節點的關鍵字數等于m的時候,則需要分裂為兩個節點,并將m/2的關鍵字上移到父節點中,同時判斷父節點的關鍵字個數是否大于m,如果需要分裂繼續按照上面的流程進行分裂,
B+樹洗掉
1.如果要洗掉關鍵字所在節點的關鍵字個數,如果大于m/2,直接洗掉即可;
2.當洗掉關鍵字所在節點的關鍵字個數等于m/2的時候,若兄弟節點中含有多余的關鍵字,也可從兄弟節點中借用關鍵字完成洗掉操作;
3.若兄弟節點沒有多余的關鍵字,則需要與其他兄弟進行合并;
4.如果合并后導致父節點不再符合B+樹的結構,則需要按照上面的規律進行再次結構的調整;
5.注意B+樹的結構(非葉子節點會存盤索引資訊,葉子節點才會存盤資料指標),修改完后還需修改其父節點中的索引值,
總結
\1. B+樹的層級更少;
\2. B+樹查詢速度更加穩定;
3.B+樹天然具備排序功能,由于B+樹所有的葉子節點資料構成了一個有序鏈表,在查詢范圍區間資料的時候會更加方便,資料緊密性很好高;
4.B+樹全節點遍歷更快:B+樹遍歷整棵樹只需要遍歷所有的葉子節點即可,而B樹需要對每一層進行遍歷,所以B+樹更有利于全表掃描;
B*樹
B*樹是B+樹的變種,不同點如下
1.關鍵字個數限制,B+樹初始化的關鍵字的個數是m/2,而B樹的初始化個數是2m/3,所以B樹的層級會更少;
2.B+樹節點滿時就會分裂,而B*樹滿時會檢查兄弟節點是否滿,如果兄弟節點沒有滿的話則會向兄弟節點轉移關鍵字,如果兄弟節點也滿了的話則從當前節點和兄弟節點各拿出1/3的資料創建一個新的節點出來,這個特性使得其相對B+樹分裂的次數也更少;
3.B*樹除了根節點外的非葉子節點也會存盤兄弟節點的指標;
總結
B*樹對比 B+Tree其初始化的容量更大,存盤的關鍵字更多,層級更少,裂變次數也會更少,
來源:https://juejin.cn/post/6910880043980259342
歡迎關注公眾號 【碼農開花】一起學習成長
我會一直分享Java干貨,也會分享免費的學習資料課程和面試寶典
回復:【計算機】【設計模式】【面試】有驚喜哦
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/255464.html
標籤:Java