前言:
8個小時內完成爬蟲,資料清洗并可視化,因為自己也是小白,做的時候時間還挺趕的,很多地方沒有做到完美,比如一些資料清洗的步驟走了捷徑,有不足的地方,歡迎大神們留言指教,
selenium :3.141.0
pyecharts:1.9.0
1.Selenium爬取資訊
我個人是喜歡用selenium做爬蟲的,可以享受web自動化的這個程序,因為要爬取的東西不是很多,如果要爬取很多內容的同學,還是老老實實用request的吧,
此次爬取的是51job前程無憂,這里的url可以替換成你想查詢的該網站的任何職業或者崗位,
爬取幾個我們需要的重要資訊,包括:職位名稱,發布日期,工資,學歷要求,經驗要求,作業地點等等等,
網速快的同學記得把睡眠時間調短一些,不然真的會爬很久,我自己大概爬了7.8分鐘吧
from selenium import webdriver
import pandas as pd
import time
wd = webdriver.Chrome()
wd.get('https://search.51job.com/list/000000,000000,0000,00,9,99,%25E5%25BB%25BA%25E7%25AD%2591%25E8%25AE%25BE%25E8%25AE%25A1,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=')
wd.implicitly_wait(10)
max_pages = 100
titles = []
times = []
wages = []
infos = []
company_names = []
company_infos = []
company_atrri = []
def get_data(titles,times,wages,infos,company_names,company_infos,company_atrri):
#獲取職位名稱
title0 = wd.find_elements_by_css_selector('.jname.at')
for each_title in title0:
titles.append(each_title.text)
#獲取發布時間
time0 = wd.find_elements_by_css_selector('.time')
for each_time in time0:
times.append(each_time.text)
#獲取工資資訊
wage0 = wd.find_elements_by_css_selector('.sal')
for each_wage in wage0:
wages.append(each_wage.text)
#獲取更多職位資訊
info0 = wd.find_elements_by_css_selector('.d.at')
for each_info in info0:
infos.append(each_info.text)
#獲取公司資訊
company_name0 = wd.find_elements_by_css_selector('.cname.at')
for each_c_name in company_name0:
company_names.append(each_c_name.text)
#獲取更多公司資訊
company_info0 = wd.find_elements_by_css_selector('.dc.at')
for each_c_info in company_info0:
company_infos.append(each_c_info.text)
#獲取公司性質
company_atrri0 = wd.find_elements_by_css_selector('.int.at')
for each_c_attr in company_atrri0:
company_atrri.append(each_c_attr.text)
for i in range(max_pages):
print(f'正在爬取第{i}頁')
get_data(titles,times,wages,infos,company_names,company_infos,company_atrri)
wd.find_element_by_css_selector('.next').click()
time.sleep(5) # 網速快的同學,請在這里操作,過快的操作可能會被檢驗出IP例外
data = {'崗位名稱': titles,
'發布時間':times,
'薪酬':wages,
'更多職位資訊':infos,
'公司名稱':company_names,
'公司更多資訊':company_infos,
'公司性質':company_atrri
}
df = pd.DataFrame(data)
df.to_csv('建筑崗位資訊.csv')
wd.quit()
最后將爬取的5000條資訊轉存為CSV格式,
下面是部分結果展示:

2 . Pandas清洗資料
這里清洗資料的作業是比較亂的,因為對我來說時間太緊了,下次會發一個另外的爬蟲悉尼房價的代碼,想對來說清洗很多,
清洗資料的幾個主要目的:
- 工資的單位是不統一的,有些是年,有些是月;有些是萬,有些是千,(可以從上圖中看到),為此得統一單位,
- 工資是一個范圍,這個范圍不利于我們后續的可視化和分析,我這是用的split,用正則運算式也是可以的,把上限和下限取出來求一個平均值,
- 需要把經驗要求,上班地點和學歷要求提出來作為一個單獨的特征進行分析,
- 嗷對!還有一個很重要的點,一共爬取了5000條資訊,但其中只有2500條是建筑設計師,所以同學們在自己做其他崗位職業分析的時候記得看看自己爬取的資料有沒有這個問題,
- 節省時間(偷懶)把不符合,麻煩處理的樣本直接刪了,
import pandas as pd
pd.set_option('display.max_columns', None)
df = pd.read_csv('建筑崗位資訊.csv')
df = df.iloc[:2500,:] # 只取建筑設計師,其他相關崗位全部洗掉
#print(df['薪酬'])
#統一一下單位,因為時間原因,把年薪,和以千為單位的資料全部洗掉掉了,如果認真做,千萬不要洗掉,每一條資料都很重要
wage_types = []
wage_types2 = []
year = ['年']
month = ['月']
wagek = ['千']
wagew = ['萬']
df.loc[:, "薪酬"] = df["薪酬"].astype('str')
for i in range(len(df['薪酬'])):
if any(key in df['薪酬'][i] for key in year):
wage_types.append('年薪')
elif any(key in df['薪酬'][i] for key in month):
wage_types.append('月薪')
else:
wage_types.append("None")
df['薪酬型別1'] = wage_types
df = df[df['薪酬型別1'] != 'None']
df = df[df['薪酬型別1'] != '年薪']
df.drop(columns = ['Unnamed: 0'],inplace = True)
df = df.reset_index(drop=True)
df.loc[:,'薪酬'] = df['薪酬'].str.replace("/月",'').astype('str')
for i in range(len(df['薪酬'])):
if any(key in df['薪酬'][i] for key in wagek):
wage_types2.append('千')
elif any(key in df['薪酬'][i] for key in wagew):
wage_types2.append('萬')
df['薪酬型別2'] = wage_types2
#把數字后面的單位(千萬)提出來
for i in range(len(df['薪酬'])):
if df['薪酬型別2'][i] == '千':
df['薪酬'][i] = df['薪酬'][i].replace('千', '')
elif df['薪酬型別2'][i] == '萬':
df['薪酬'][i] = df['薪酬'][i].replace('萬', '')
#找出工資的上下線
min_wage = []
max_wage = []
for i in range(len(df['薪酬'])):
try:
min_wage0= df['薪酬'][i].split("-")[0]
max_wage0 = df['薪酬'][i].split("-")[1]
min_wage.append(min_wage0)
max_wage.append(max_wage0)
except:
min_wage0 = 0
max_wage0 = 0
min_wage.append(min_wage0)
max_wage.append(max_wage0)
df['minwage'] = min_wage
df['maxwage'] = max_wage
df['minwage'] = df["minwage"].astype('float')
df['maxwage'] =df["maxwage"].astype('float')
areas = []
exps = []
degrees = []
for i in range(len(df['更多職位資訊'])):
area = df['更多職位資訊'][i].split('|')[0]
areas.append(area)
exp = df['更多職位資訊'][i].split('|')[1]
exps.append(exp)
try:
degree = df['更多職位資訊'][i].split('|')[2]
degrees.append(degree)
except:
degree = "None"
degrees.append(degree)
df['上班地點'] = areas
df['經驗要求'] = exps
df['學歷要求'] = degrees
df = df[df['薪酬型別2'] != '千']
df.drop(['薪酬','更多職位資訊','薪酬型別1'],axis = 1,inplace = True)
df['薪酬'] = (df['minwage']+df['maxwage'])/2
df.drop(['minwage','maxwage','薪酬型別2'],axis = 1,inplace = True)
df= df[df['薪酬'] != 0]
df = df.reset_index(drop=True)
df.to_csv('清洗過后的資料.csv')
下面是部分結果展示:
3.Pyecharts可視化
pyecharts真的是神仙工具,除了網上的教程不那么詳細之外,幾乎找不到啥子缺點(好像這是我自己的缺點,,,),pyecharts輸出的是html檔案,可以用瀏覽器打開,并且都是互動式體驗,個人覺得和tableau做出來的圖差距不大了,還有各種像水滴圖,旭日圖各種各樣的圖都ok!度娘良心出品,當然也沒有忘記我們的老朋友matlibplot,下面也有用它做做圖,具體選用什么可視庫大家隨喜好就好,
在可視化的基礎上我寫了一些自己的結論不一定對,(畢竟這行業我也不是太了解)
import pandas as pd
from pyecharts.charts import Pie,Bar
from pyecharts import options as opts
import matplotlib.pyplot as plt
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei']
pd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)
#這部分資料groupby手滑被我刪了,自己groupby一下吧,實在不會,代碼和下面的上班地點是一樣的
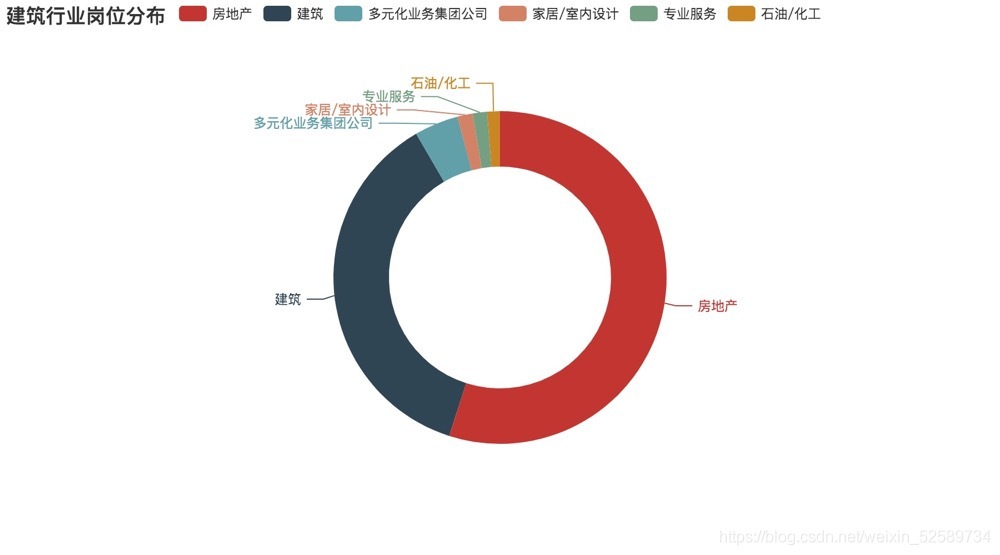
cate = ['房地產', '建筑', '多元化業務集團公司', '家居/室內設計','專業服務','石油/化工']
values = [935,624,73,25,24,21]
pie = (Pie()
.add('',[list(z) for z in zip(cate,values)],
radius=['40%','60%'],
label_opts=opts.LabelOpts(is_show=True),
)
.set_global_opts(title_opts=opts.TitleOpts(title = '建筑行業崗位分布'),
legend_opts=opts.LegendOpts(is_show=True))
)
pie.render("社招-建筑行業崗位分布.html")
df = pd.read_csv("清洗過后的資料.csv")
#print(df.groupby('公司性質')['薪酬'].mean())
"""
崗位更多的集中在房地產(甲方)和建筑事務所/設計院(乙方)
傳統建筑行業的平均薪酬在1.303w每個月,房地產行業的平均薪酬在1.85W每個月,平均薪酬最高的是采礦頁2.75w每個月,
但是這個統計不完全正確,單純的比較不具有意義,因為同時應該考慮到房地產行業是否對經驗或者學歷要求更高,
"""
#上班地點可視化
area_group = df.groupby('上班地點').count()
#print(area_group.sort_values(by = '薪酬',ascending= False))
cate = ["異地招聘",'深圳南山', '深圳福田', '廣州天河', '成都高新','上海','上海浦東','廣州','成都','南京']
values = [174,41,37,32,32,28,26,22,21,18]
pie = (Pie()
.add('',[list(z) for z in zip(cate,values)],
radius=['40%','60%'],
label_opts=opts.LabelOpts(is_show=True),
)
.set_global_opts(title_opts=opts.TitleOpts(title = '建筑行業地區分布'),
legend_opts=opts.LegendOpts(is_show=True))
)
pie.render("社招-建筑行業地區分布.html")
#print(df.groupby('上班地點')['薪酬'].mean())
"""
建筑設計師的需求想對來說比較分散,全國各地都有需要,不像一些特殊崗位如金融,計算機的需求會比較聚集在超一線城市,
在不考慮經驗的情況下,可以看超一線城市的平均薪酬是高于一般一線城市的,大約在1.8+W的位置,
不過東莞,四川,重慶等特殊地區對建筑設的需求明顯大于其他同類城市的,
"""
#學歷要求
degree_group = df.groupby('學歷要求').count()
#print(degree_group.sort_values(by = '薪酬',ascending= False))
cate = ["本科",'大專', '未知', '碩士', '中專']
values = [1343,267,39,10,1]
bar = (Bar()
.add_xaxis(cate)
.add_yaxis('', values)
.set_series_opts(label_opts=opts.LabelOpts(is_show=True, font_size=15))
.set_global_opts(title_opts=opts.TitleOpts(title='社招-建筑行業學歷要求'),
xaxis_opts=opts.AxisOpts(name='學歷要求'),
yaxis_opts=opts.AxisOpts(name='樣本數量'))
)
bar.render('社招-建筑行業學歷要求.html')
print(df.groupby('學歷要求')['薪酬'].mean())
"""
根據爬取到的1600多條建筑師招聘資訊來看,學歷和薪酬之間不存在明顯的線性關系,(在更高維度或者更多樣本的時候,可能可以夠找到一些關系)
通常來說我們認為建筑設計師對于學歷并沒有太硬性的要求,更多的還是個人技能的要求,
"""
#經驗要求
exp_group = df.groupby('經驗要求').count()
#print(exp_group.sort_values(by = '薪酬',ascending= False))
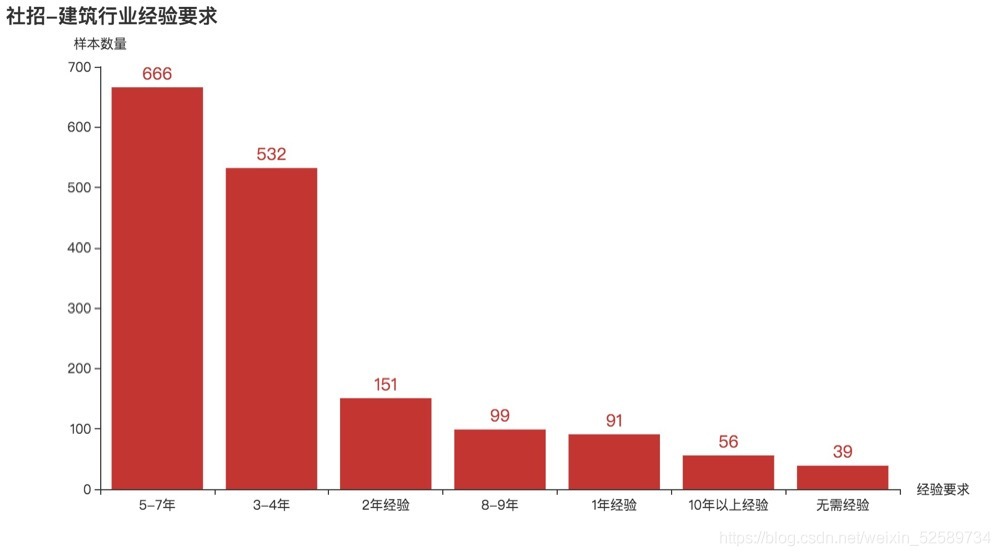
cate = ["5-7年",'3-4年', '2年經驗', '8-9年', '1年經驗','10年以上經驗','無需經驗']
values = [666,532,151,99,91,56,39]
bar = (Bar()
.add_xaxis(cate)
.add_yaxis('', values)
.set_series_opts(label_opts=opts.LabelOpts(is_show=True, font_size=15))
.set_global_opts(title_opts=opts.TitleOpts(title='社招-建筑行業經驗要求'),
xaxis_opts=opts.AxisOpts(name='經驗要求'),
yaxis_opts=opts.AxisOpts(name='樣本數量'))
)
bar.render('社招-建筑行業經歷要求.html')
#print(df.groupby('經驗要求')['薪酬'].mean())
"""
可以看出3到7年占了幾乎3分之2的樣本,說明這個時間段才是建筑設計師的黃金時間,
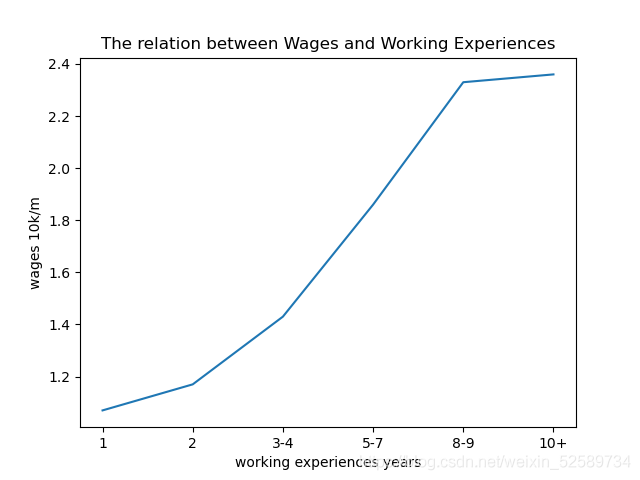
與學歷不同,薪酬和作業經歷之間存在一個明顯的正相關關系,10年以上的平均工資在2.36w/月,
而一年作業經驗的1.07W/月,2年1.17w/月.
"""
'''
x = ['1','2','3-4','5-7','8-9','10+']
y= [1.07,1.17,1.43,1.86,2.33,2.36]
plt.xlabel('working experiences')
plt.ylabel('wages')
plt.title("The relation between Wages and Working Experiences")
plt.plot(x,y)
plt.savefig("作業經驗和工資關系.png")'''
pyecharts的部分結果展示:
《建筑崗位的行業分布》
《作業經驗和招聘數量》
折線圖還是matplotlib吧:
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/255579.html
標籤:python
上一篇:python繪圖 ——蠟筆小新