一、二叉樹
1??二叉查找樹的特點就是左子樹的節點值比父親節點小,而右子樹的節點值比父親節點大,如圖:
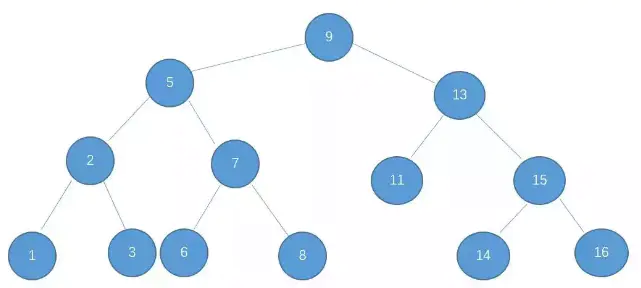
基于二叉查找樹的這種特點,在查找某個節點的時候,可以采取類似于二分查找的思想,快速找到某個節點,n 個節點的二叉查找樹,正常的情況下,查找的時間復雜度為 O(logN),之所以說是正常情況下,是因為二叉查找樹有可能出現一種極端的情況,例如:
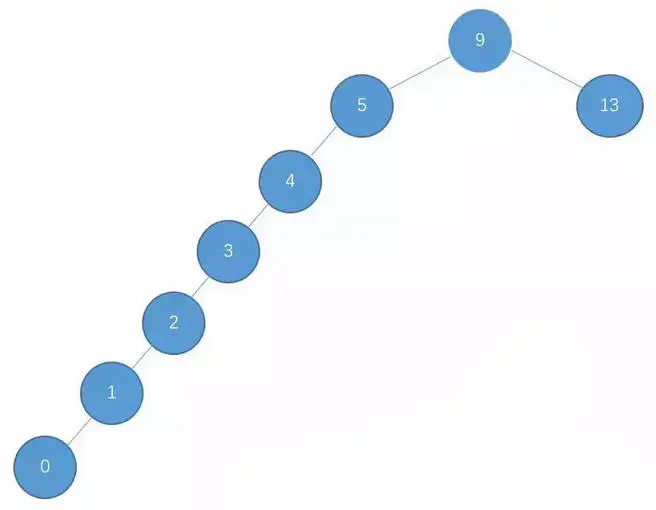
這種情況也是滿足二叉查找樹的條件,然而,此時的二叉查找樹已經近似退化為一條鏈表,這樣的二叉查找樹的查找時間復雜度頓時變成了 O(n),由此必須防止這種情況發生,為了解決這個問題,于是引申出了平衡二叉樹,
二、平衡二叉樹
1??概念
平衡二叉樹是基于二分法的策略提高資料的查找速度的二叉樹的資料結構,
2??規則
平衡二叉樹是采用二分法思維把資料按規則組裝成一個樹形結構的資料,用這個樹形結構的資料減少無關資料的檢索,大大的提升了資料檢索的速度;平衡二叉樹的資料結構組裝程序有以下規則:
①非葉子節點只能允許最多兩個子節點存在,
②每一個非葉子節點資料分布規則為左邊的子節點小當前節點的值,右邊的子節點大于當前節點的值(這里值是基于自己的演算法規則而定的,比如hash值),
平衡樹的層級結構:平衡二叉樹的查詢性能和樹的層級(高度h)成反比,h值越小查詢越快,為了保證樹的結構左右兩端資料大致平衡,降低二叉樹的查詢難度一般會采用一種演算法機制實作節點資料結構的平衡,實作了這種演算法的有比如Treap、紅黑樹,使用平衡二叉樹能保證資料的左右兩邊的節點層級相差不會大于1,通過這樣避免樹形結構由于洗掉增加變成線性鏈表影響查詢效率,保證資料平衡的情況下查找資料的速度近于二分法查找:
3??平衡二叉樹特點:
①非葉子節點最多擁有兩個子節點,
②非葉子節點值大于左邊子節點、小于右邊子節點,
③樹的左右兩邊的層級數相差不會大于1,
④沒有值相等重復的節點,
三、紅黑樹
1??為什么有了平衡樹還需要紅黑樹?
雖然平衡樹解決了二叉查找樹退化為近似鏈表的缺點,能夠把查找時間控制在 O(logn),不過卻不是最佳的,因為平衡樹要求每個節點的左子樹和右子樹的高度差至多等于1,這個要求實在是太嚴了,導致每次進行插入/洗掉節點的時候,幾乎都會破壞平衡樹的第二個規則,進而都需要通過左旋和右旋來進行調整,使之再次成為一顆符合要求的平衡樹,
2??紅黑樹的特性
顯然,如果在插入、洗掉很頻繁的場景中,平衡樹需要頻繁調整,這會使平衡樹的性能大打折扣,為了解決這個問題,于是有了紅黑樹,紅黑樹具有如下特點:
①每個節點或者是黑色,或者是紅色,
②根節點是黑色,
③每個葉子節點(NIL)是黑色, [注意:這里葉子節點,是指為空(NIL或NULL)的葉子節點]
④如果一個節點是紅色的,則它的子節點必須是黑色的,
⑤從一個節點到該節點的子孫節點的所有路徑上包含相同數目的黑節點,[這里指到葉子節點的路徑]
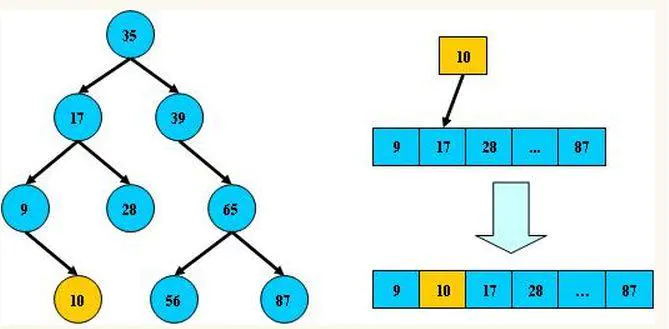
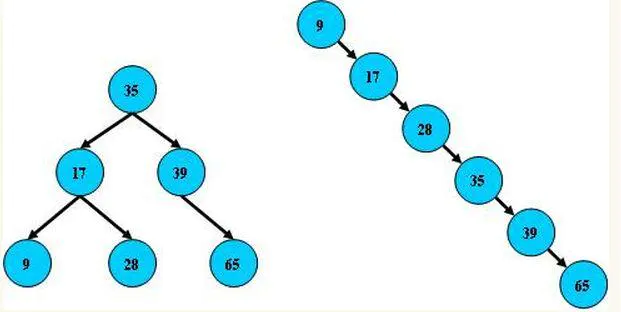
包含n個內部節點的紅黑樹的高度是 O(log(n)),如圖:

3??紅黑樹的使用場景
java中使用到紅黑樹的有TreeSet和JDK1.8的HashMap,紅黑樹的插入和洗掉都要滿足以上5個特性,操作非常復雜,為什么要使用紅黑樹?原因:
紅黑樹是一種平衡樹,復雜的定義和規則都是為了保證樹的平衡性,如果樹不保證平衡性就是下圖:很顯然這就變成一個鏈表了,
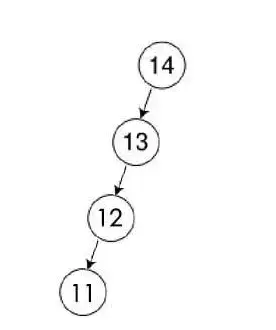
保證平衡性的最大的目的就是降低樹的高度,因為樹的查找性能取決于樹的高度,所以樹的高度越低搜索的效率越高!
四、B樹(B-tree)
B樹和B-tree,其實是同一種樹,
1??概念
B樹和平衡二叉樹稍有不同的是B樹屬于多叉樹又名平衡多路查找樹(查找路徑不只兩個),資料庫索引技術里大量使用B樹和B+樹的資料結構,
2??規則
①排序方式:所有節點關鍵字是按遞增次序排列,并遵循左小右大原則,
②子節點數:非葉子節點的子節點數>1,且<=M ,且M>=2,空樹除外(注:M階代表一個樹節點最多有多少個查找路徑,M=M路,當M=2則是2叉樹,M=3則是3叉),
③關鍵字數:枝節點的關鍵字數量大于等于ceil(m/2)-1個且小于等于M-1個(注:ceil()是個朝正無窮方向取整的函式,如ceil(1.1)結果為2),
④所有葉子節點均在同一層、葉子節點除了包含了關鍵字和關鍵字記錄的指標外也有指向其子節點的指標只不過其指標地址都為null對應下圖最后一層節點的空格子,
用一個圖和一個實際的例子來理解B樹(便于理解直接用實際字母的大小來排列C>B>A):

3??B樹的查詢流程
如要從上圖中找到E,查找流程如下:
①獲取根節點的關鍵字進行比較,當前根節點關鍵字為M,E<M(26個字母順序),所以往找到指向左邊的子節點(二分法規則,左小右大,左邊放小于當前節點值的子節點、右邊放大于當前節點值的子節點),
②拿到關鍵字D和G,D<E<G 所以直接找到D和G中間的節點,
③拿到E和F,因為E=E,所以直接回傳關鍵字和指標資訊(如果樹結構里面沒有包含所要查找的節點則回傳null),
4??B樹的插入節點流程
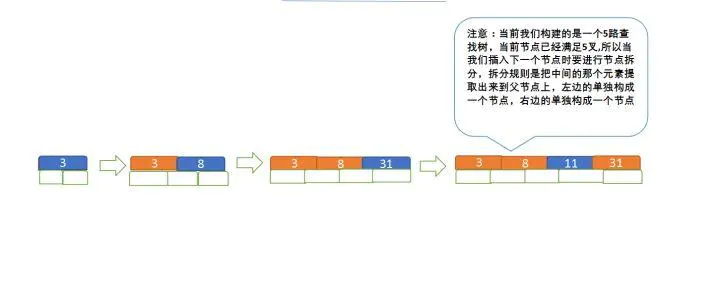
定義一個5階樹(平衡5路查找樹),現在要把3、8、31、11、23、29、50、28這些數字構建出一個5階樹出來,遵循規則:
①節點拆分規則:當前是要組成一個5路查找樹,那么此時m=5,關鍵字數必須<=5-1(這里關鍵字數>4就要進行節點拆分),
②排序規則:滿足節點本身比左邊節點大,比右邊節點小,
先插入 3、8、31、11:
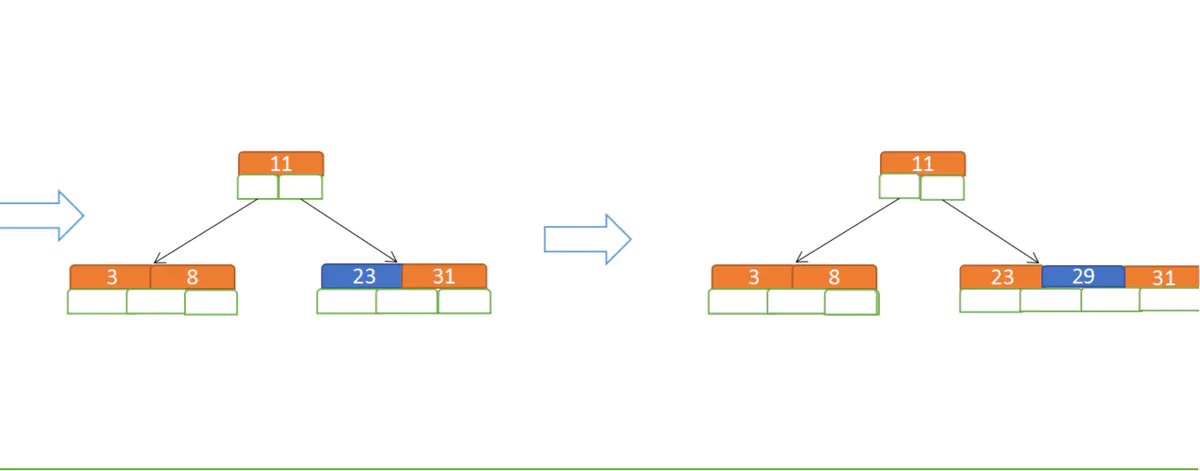
再插入23、29:
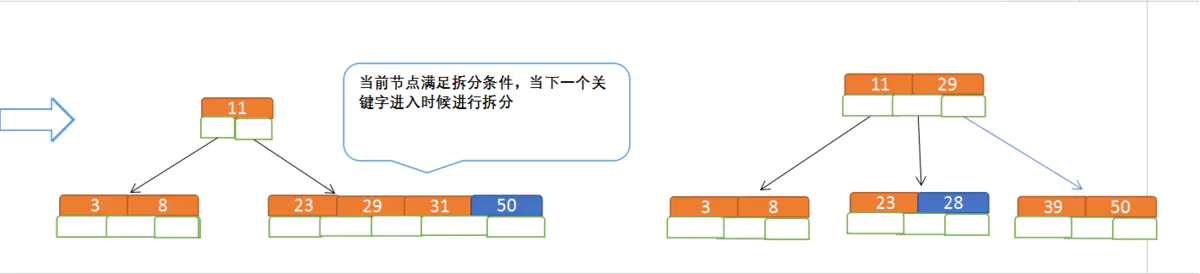
再插入50、28:
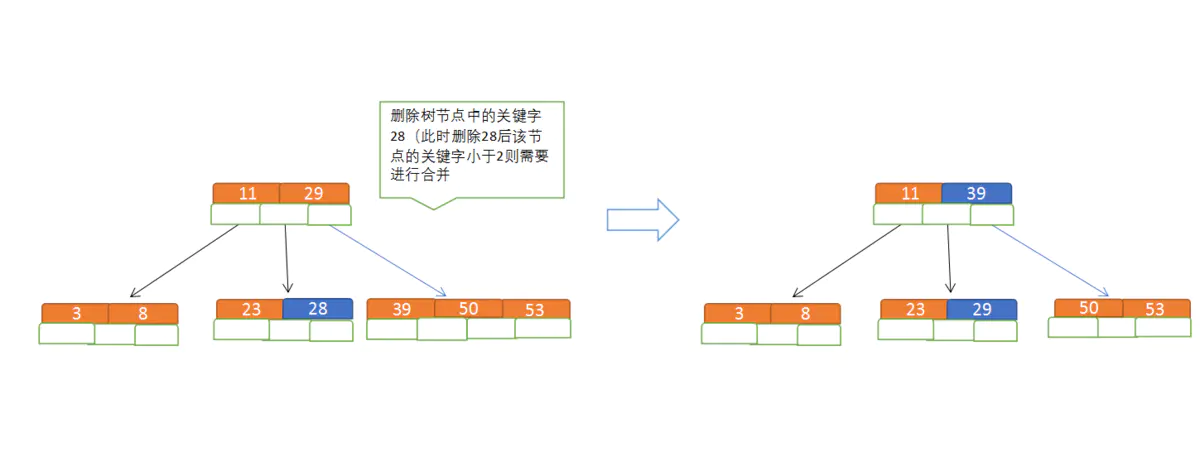
5??B樹節點的洗掉
規則:
①節點合并規則:當前是要組成一個5路查找樹,那么此時m=5,關鍵字數必須大于等于ceil(5/2)(這里關鍵字數<2就要進行節點合并),
②滿足節點本身比左邊節點大,比右邊節點小的排序規則,
③關鍵字數小于二時先從子節點取,子節點沒有符合條件時就向父節點取,取中間值往父節點放,
特點:
B樹相對于平衡二叉樹的不同是,每個節點包含的關鍵字增多了,特別是在B樹應用到資料庫中的時候,資料庫充分利用了磁盤塊的原理(磁盤資料存盤是采用塊的形式存盤的,每個塊的大小為4K,每次IO進行資料讀取時,同一個磁盤塊的資料可以一次性讀取出來)把節點大小限制和充分使用在磁盤快大小范圍;把樹的節點關鍵字增多后樹的層級比原來的二叉樹少了,減少資料查找的次數和復雜度,
五、B+樹
1??概念
B+樹是B樹的一個升級版,B+樹更充分的利用了節點的空間,讓查詢速度更加穩定,其速度完全接近于二分法查找,為什么說B+樹查找的效率要比B樹更高、更穩定?
2??規則
①B+跟B樹不同,B+樹的非葉子節點不保存關鍵字記錄的指標,只進行資料索引,這樣使得B+樹每個非葉子節點所能保存的關鍵字大大增加,
②B+樹葉子節點保存了父節點的所有關鍵字記錄的指標,所有資料地址必須要到葉子節點才能獲取到,所以每次資料查詢的次數都一樣,
③B+樹葉子節點的關鍵字從小到大有序排列,左邊結尾資料都會保存右邊節點開始資料的指標,
④非葉子節點的子節點數=關鍵字數(百度百科,根據各種資料,這里有兩種演算法的實作方式,另一種為非葉節點的關鍵字數=子節點數-1(維基百科),雖然資料排列結構不一樣,但其原理還是一樣的,Mysql 的 B+樹是用第一種方式實作),
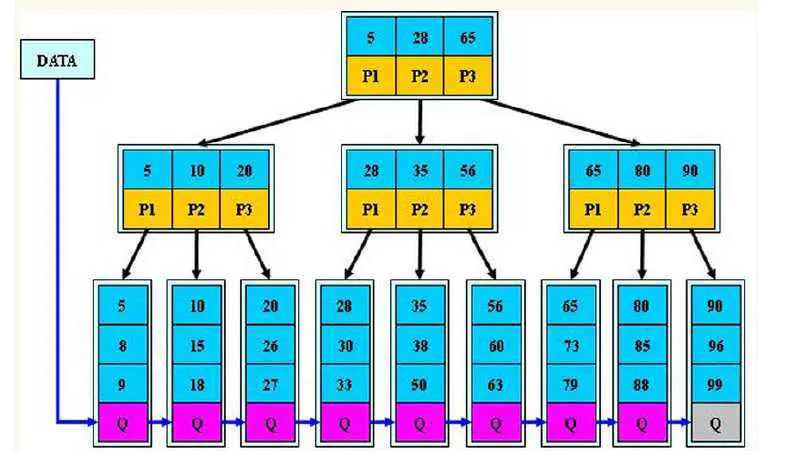
百度百科演算法結構示意圖
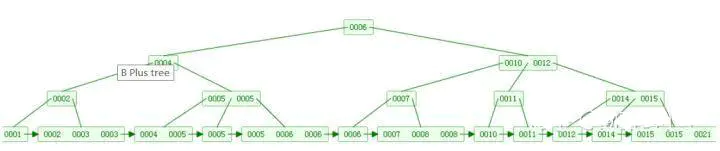
維基百科演算法結構示意圖
3??特點
①B+樹的層級更少:相較于B樹B+每個非葉子節點存盤的關鍵字數更多,樹的層級更少所以查詢資料更快,
②B+樹查詢速度更穩定:B+所有關鍵字資料地址都存在葉子節點上,所以每次查找的次數都相同所以查詢速度要比B樹更穩定,
③B+樹天然具備排序功能:B+樹所有的葉子節點資料構成了一個有序鏈表,在查詢大小區間的資料時候更方便,資料緊密性很高,快取的命中率也會比B樹高,
④B+樹全節點遍歷更快:B+樹遍歷整棵樹只需要遍歷所有的葉子節點即可,而不需要像B樹對每一層進行遍歷,這有利于資料庫做全表掃描,
⑤B樹相對于B+樹的優點是,如果經常訪問的資料離根節點很近,而B樹的非葉子節點本身存有關鍵字其資料的地址,所以這種資料檢索的時候會要比B+樹快,
六、B*樹
1??規則
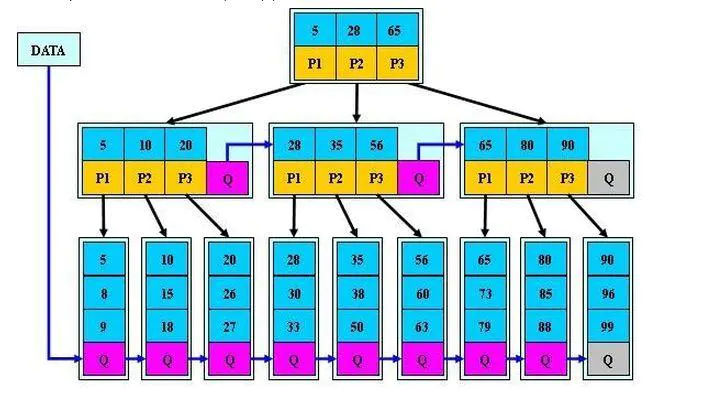
B樹是B+樹的變種,區別如下:
①首先是關鍵字個數限制問題,B+樹初始化的關鍵字初始化個數是cei(m/2),B樹的初始化個數為cei(2/3m),
②B+樹節點滿時就會分裂,而B樹節點滿時會檢查兄弟節點是否滿(因為每個節點都有指向兄弟的指標),如果兄弟節點未滿則向兄弟節點轉移關鍵字,如果兄弟節點已滿,則從當前節點和兄弟節點各拿出1/3的資料創建一個新的節點出來,
2??特點
在B+樹的基礎上因其初始化的容量變大,使得節點空間使用率更高,而又存有兄弟節點的指標,可以向兄弟節點轉移關鍵字的特性使得B*樹額分解次數變得更少;
七、 總結
1??相同思想和策略
從平衡二叉樹、B樹、B+樹、B*樹總體來看它們的貫徹的思想是相同的,都是采用二分法和資料平衡策略來提升查找資料的速度,
2??不同的方式的磁盤空間利用
不同點是它們一個一個在演變的程序中通過IO從磁盤讀取資料的原理進行一步步的演變,每一次演變都是為了讓節點的空間更合理的運用起來,從而使樹的層級減少達到快速查找資料的目的,
作者:日常更新
鏈接:https://www.jianshu.com/p/b597aa97c9de
歡迎關注公眾號 【碼農開花】一起學習成長
我會一直分享Java干貨,也會分享免費的學習資料課程和面試寶典
回復:【計算機】【設計模式】【面試】有驚喜哦
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/255844.html
標籤:其他
上一篇:C/C++編程筆記:C ++中用于動態記憶體的new和delete運算子
下一篇:python協程