第三方庫需求
- requests(爬蟲所需)
- BeautifulSoup(爬蟲所需)
- docx(匯入word檔案所需)
代碼
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
from docx import Document
def crawler(i):
target = 'http://book.sbkk8.com/waiguo/dongyeguiwu/eyi/'+str(206670-i)+'.html'
req = requests.get(url = target)#向網站發送請求
req.encoding = "gbk"#設定編碼格式為gbk模式,防止出現中文亂碼
html = req.text
bf = BeautifulSoup(html,features='lxml')
texts = bf.find_all('div',id='content') #尋找對應的標簽值
'''
注意單引號,class后有下劃線,因為class是關鍵字
class屬性是"nr_nr"的標簽是唯一的
'''
document.add_paragraph(texts[0].text)#只回傳文本內容,并將其寫入檔案
if __name__ == "__main__":
document = Document()#創建檔案物件
for i in range (0,14):
crawler(i)
print('正在爬取第%d章'%(i+1))
print('爬取完畢!')
document.save('惡意.docx')#保存檔案
代碼選講
- 分章節爬取小說的方法
本文以http://book.sbkk8.com/waiguo/dongyeguiwu/eyi/
為例:
小說第一章的網址為:
http://book.sbkk8.com/waiguo/dongyeguiwu/eyi/206670.html
小說最后一章的網址為:
http://book.sbkk8.com/waiguo/dongyeguiwu/eyi/206657.html
章節數加一,最后的數字減一,于是我們可以用一個通式構造各章節小說的網址,之后在主函式里遍歷即可,
'http://book.sbkk8.com/waiguo/dongyeguiwu/eyi/'+str(206670-i)+'.html'
- beautifulsoup爬取網頁的特定內容
我們想要爬取的是小說的正文部分,選中正文部分,點擊檢查:
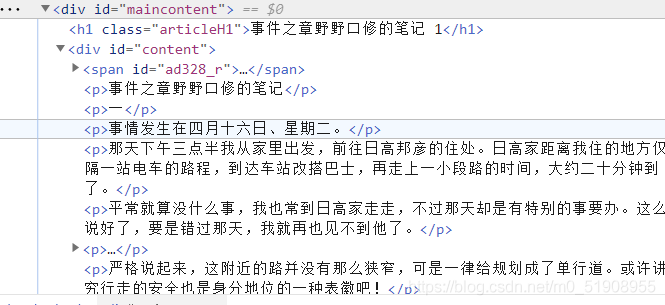
可以看到,正文部分所對應的標簽值是'div',id='content',于是我們可以通過texts = bf.find_all('div',id='content')來查找正文,效果
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/256386.html
標籤:python