本文由『Go開源說』第四期 go-zero 直播內容修改整理而成,視頻內容較長,拆分成上下篇,本文內容有所刪減和重構,
大家好,很高興來到“GO開源說” 跟大家分享開源專案背后的一些故事、設計思想以及使用方法,今天分享的專案是 go-zero,一個集成了各種工程實踐的 web 和 rpc 框架,我是Kevin,go-zero 作者,我的 github id 是 kevwan,
go-zero 概覽
go-zero 雖然是20年8月7號才開源,但是已經經過線上大規模檢驗了,也是我近20年工程經驗的積累,開源后得到社區的積極反饋,在5個多月的時間里,獲得了6k stars,多次登頂github Go語言日榜、周榜、月榜榜首,并獲得了gitee最有價值專案(GVP),開源中國年度最佳人氣專案,同時微信社區極為活躍,3000+人的社區群,go-zero愛好者們一起交流go-zero使用心得和討論使用程序中的問題,
go-zero 如何自動管理快取?
快取設計原理
我們對快取是只洗掉,不做更新,一旦DB里資料出現修改,我們就會直接洗掉對應的快取,而不是去更新,
我們看看洗掉快取的順序怎樣才是正確的,
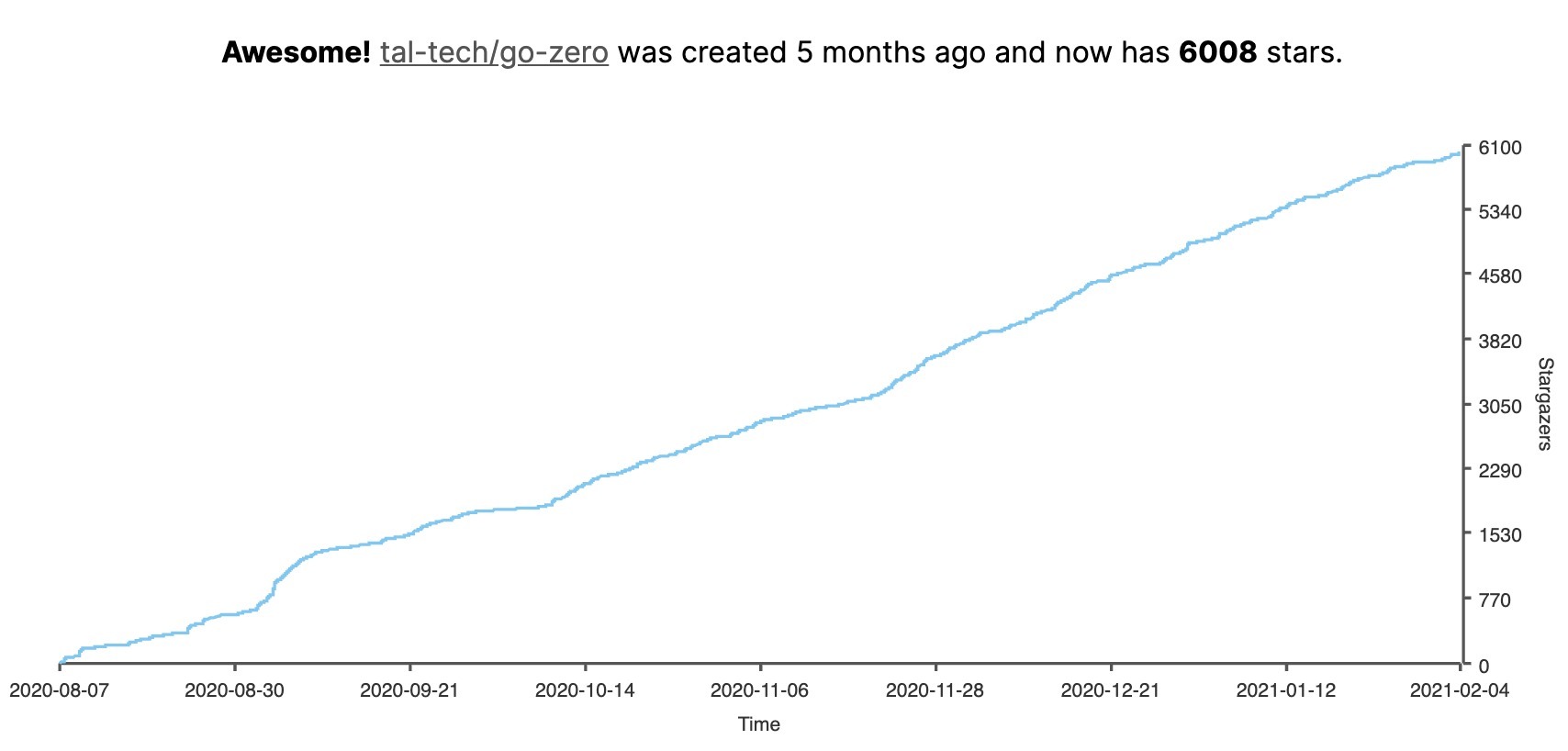
- 先洗掉快取,再更新DB
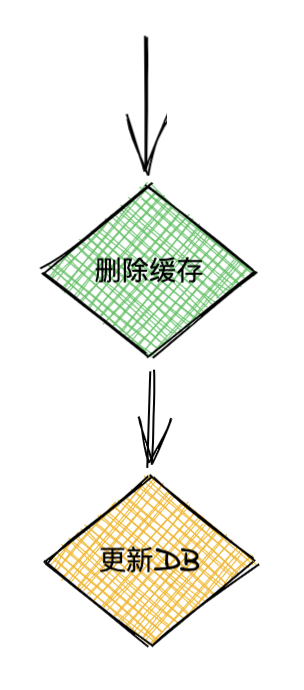
我們看兩個并發請求的情況,A請求需要更新資料,先洗掉了快取,然后B請求來讀取資料,此時快取沒有資料,就會從DB加載資料并寫回快取,然后A更新了DB,那么此時快取內的資料就會一直是臟資料,知道快取過期或者有新的更新資料的請求,如圖
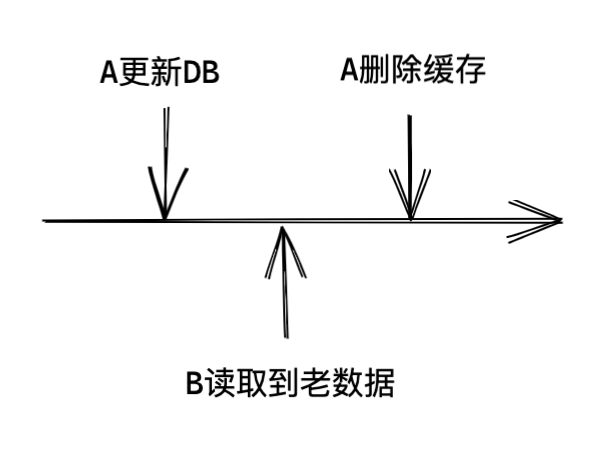
- 先更新DB,再洗掉快取
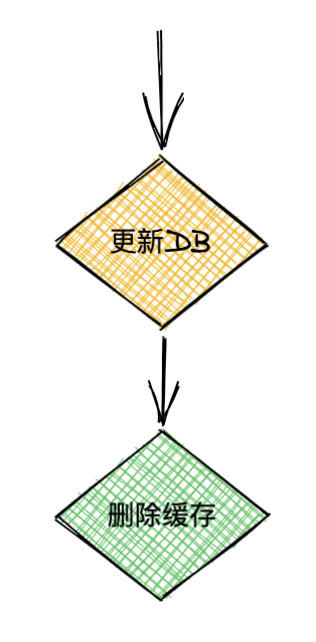
A請求先更新DB,然后B請求來讀取資料,此時回傳的是老資料,此時可以認為是A請求還沒更新完,最終一致性,可以接受,然后A洗掉了快取,后續請求都會拿到最新資料,如圖
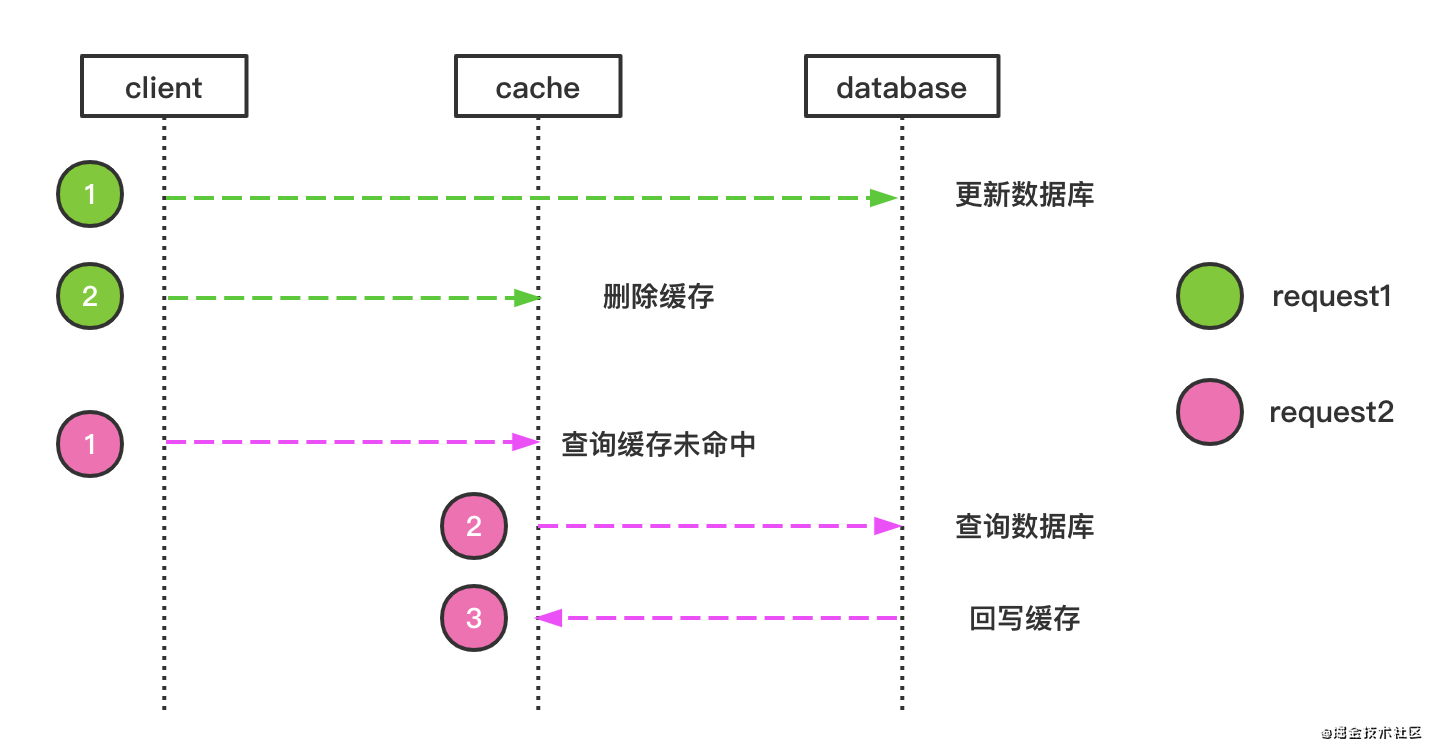
讓我們再來看一下正常的請求流程:
- 第一個請求更新DB,并洗掉了快取
- 第二個請求讀取快取,沒有資料,就從DB讀取資料,并回寫到快取里
- 后續讀請求都可以直接從快取讀取
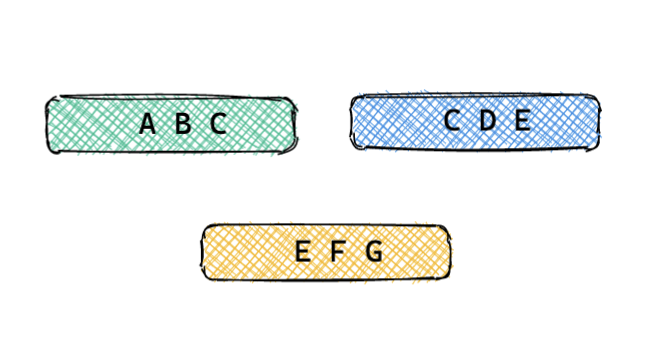
我們再看一下DB查詢有哪些情況,假設行記錄里有ABCDEFG七列資料:
- 只查詢部分列資料的請求,比如請求其中的ABC,CDE或者EFG等,如圖
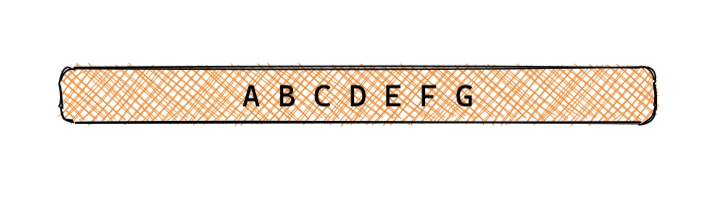
- 查詢單條完整行記錄,如圖
- 查詢多條行記錄的部分或全部列,如圖
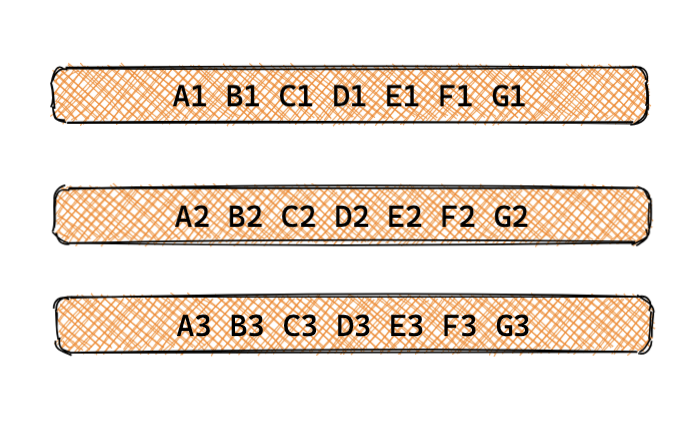
對于上面三種情況,首先,我們不用部分查詢,因為部分查詢沒法快取,一旦快取了,資料有更新,沒法定位到有哪些資料需要洗掉;其次,對于多行的查詢,根據實際場景和需要,我們會在業務層建立對應的從查詢條件到主鍵的映射;而對于單行完整記錄的查詢,go-zero 內置了完整的快取管理方式,所以核心原則是:go-zero 快取的一定是完整的行記錄,
下面我們來詳細介紹 go-zero 內置的三種場景的快取處理方式:
-
基于主鍵的快取
PRIMARY KEY (`id`)這種相對來講是最容易處理的快取,只需要在
redis里用primary key作為key來快取行記錄即可, -
基于唯一索引的快取
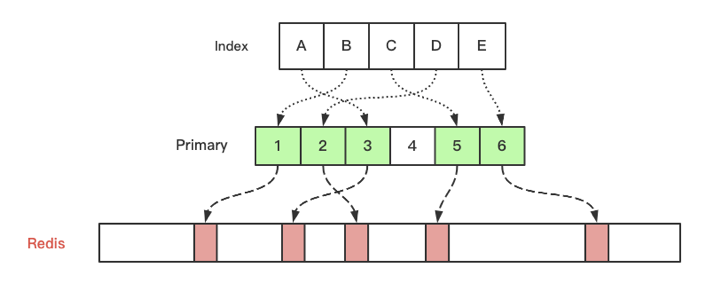
在做基于索引的快取設計的時候我借鑒了
database索引的設計方法,在database設計里,如果通過索引去查資料時,引擎會先在索引->主鍵的tree里面查找到主鍵,然后再通過主鍵去查詢行記錄,就是引入了一個間接層去解決索引到行記錄的對應問題,在 go-zero 的快取設計里也是同樣的原理,基于索引的快取又分為單列唯一索引和多列唯一索引:
-
單列唯一索引如下:
UNIQUE KEY `product_idx` (`product`) -
多列唯一索引如下:
UNIQUE KEY `vendor_product_idx` (`vendor`, `product`)
但是對于 go-zero 來說,單列和多列只是生成快取
key的方式不同而已,背后的控制邏輯是一樣的,然后 go-zero 內置的快取管理就比較好的控制了資料一致性問題,同時也內置防止了快取的擊穿、穿透、雪崩問題(這些在 gopherchina 大會上分享的時候仔細講過,見后續 gopherchina 分享視頻),另外,go-zero 內置了快取訪問量、訪問命中率統計,如下所示:
dbcache(sqlc) - qpm: 5057, hit_ratio: 99.7%, hit: 5044, miss: 13, db_fails: 0可以看到比較詳細的統計資訊,便于我們來分析快取的使用情況,對于快取命中率極低或者請求量極小的情況,我們就可以去掉快取了,這樣也可以降低成本,
-
快取代碼解讀
1. 基于主鍵的快取邏輯
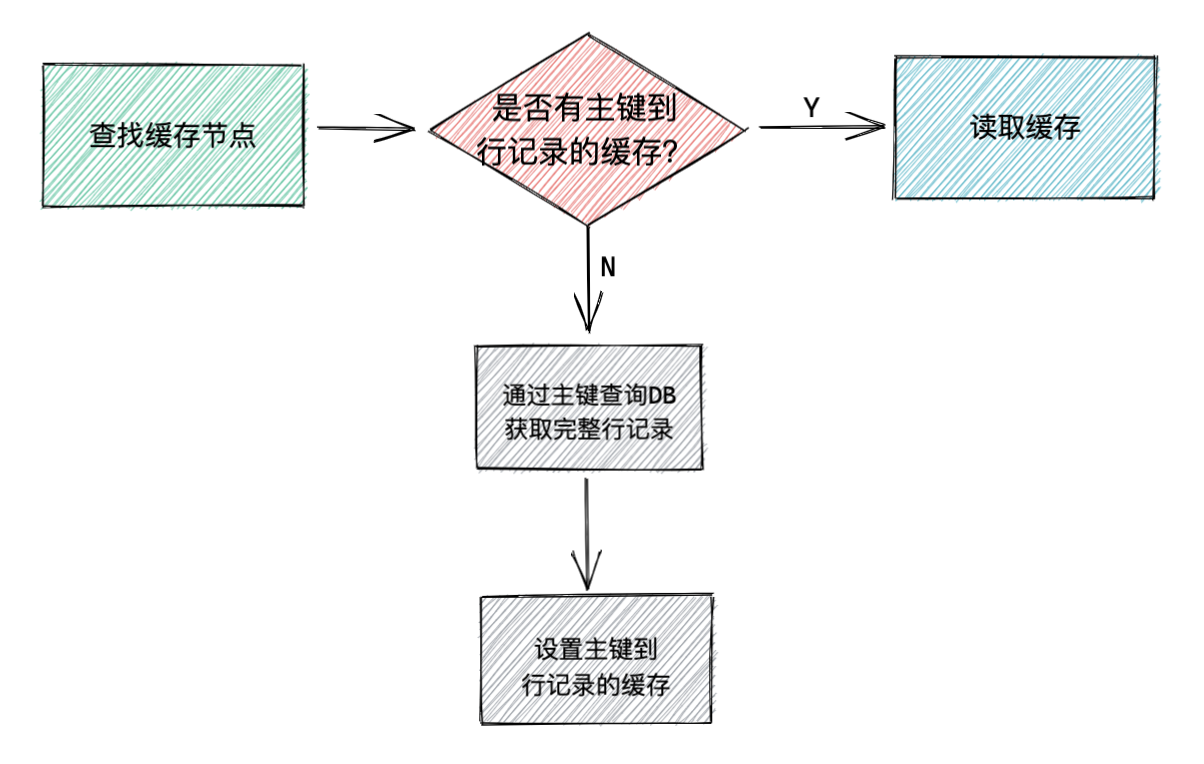
具體實作代碼如下:
func (cc CachedConn) QueryRow(v interface{}, key string, query QueryFn) error {
return cc.cache.Take(v, key, func(v interface{}) error {
return query(cc.db, v)
})
}
這里的 Take 方法是先從快取里去通過 key 拿資料,如果拿到就直接回傳,如果拿不到,那么就通過 query 方法去 DB 讀取完整行記錄并寫回快取,然后再回傳資料,整個邏輯還是比較簡單易懂的,
我們詳細看看 Take 的實作:
func (c cacheNode) Take(v interface{}, key string, query func(v interface{}) error) error {
return c.doTake(v, key, query, func(v interface{}) error {
return c.SetCache(key, v)
})
}
Take 的邏輯如下:
- 用
key從快取里查找資料 - 如果找到,則回傳資料
- 如果找不到,用
query方法去讀取資料 - 讀到后呼叫
c.SetCache(key, v)設定快取
其中的 doTake 代碼和解釋如下:
// v - 需要讀取的資料物件
// key - 快取key
// query - 用來從DB讀取完整資料的方法
// cacheVal - 用來寫快取的方法
func (c cacheNode) doTake(v interface{}, key string, query func(v interface{}) error,
cacheVal func(v interface{}) error) error {
// 用barrier來防止快取擊穿,確保一個行程內只有一個請求去加載key對應的資料
val, fresh, err := c.barrier.DoEx(key, func() (interface{}, error) {
// 從cache里讀取資料
if err := c.doGetCache(key, v); err != nil {
// 如果是預先放進來的placeholder(用來防止快取穿透)的,那么就回傳預設的errNotFound
// 如果是未知錯誤,那么就直接回傳,因為我們不能放棄快取出錯而直接把所有請求去請求DB,
// 這樣在高并發的場景下會把DB打掛掉的
if err == errPlaceholder {
return nil, c.errNotFound
} else if err != c.errNotFound {
// why we just return the error instead of query from db,
// because we don't allow the disaster pass to the DBs.
// fail fast, in case we bring down the dbs.
return nil, err
}
// 請求DB
// 如果回傳的error是errNotFound,那么我們就需要在快取里設定placeholder,防止快取穿透
if err = query(v); err == c.errNotFound {
if err = c.setCacheWithNotFound(key); err != nil {
logx.Error(err)
}
return nil, c.errNotFound
} else if err != nil {
// 統計DB失敗
c.stat.IncrementDbFails()
return nil, err
}
// 把資料寫入快取
if err = cacheVal(v); err != nil {
logx.Error(err)
}
}
// 回傳json序列化的資料
return jsonx.Marshal(v)
})
if err != nil {
return err
}
if fresh {
return nil
}
// got the result from previous ongoing query
c.stat.IncrementTotal()
c.stat.IncrementHit()
// 把資料寫入到傳入的v物件里
return jsonx.Unmarshal(val.([]byte), v)
}
2. 基于唯一索引的快取邏輯
因為這塊比較復雜,所以我用不同顏色標識出來了回應的代碼塊和邏輯,block 2 其實跟基于主鍵的快取是一樣的,這里主要講 block 1 的邏輯,
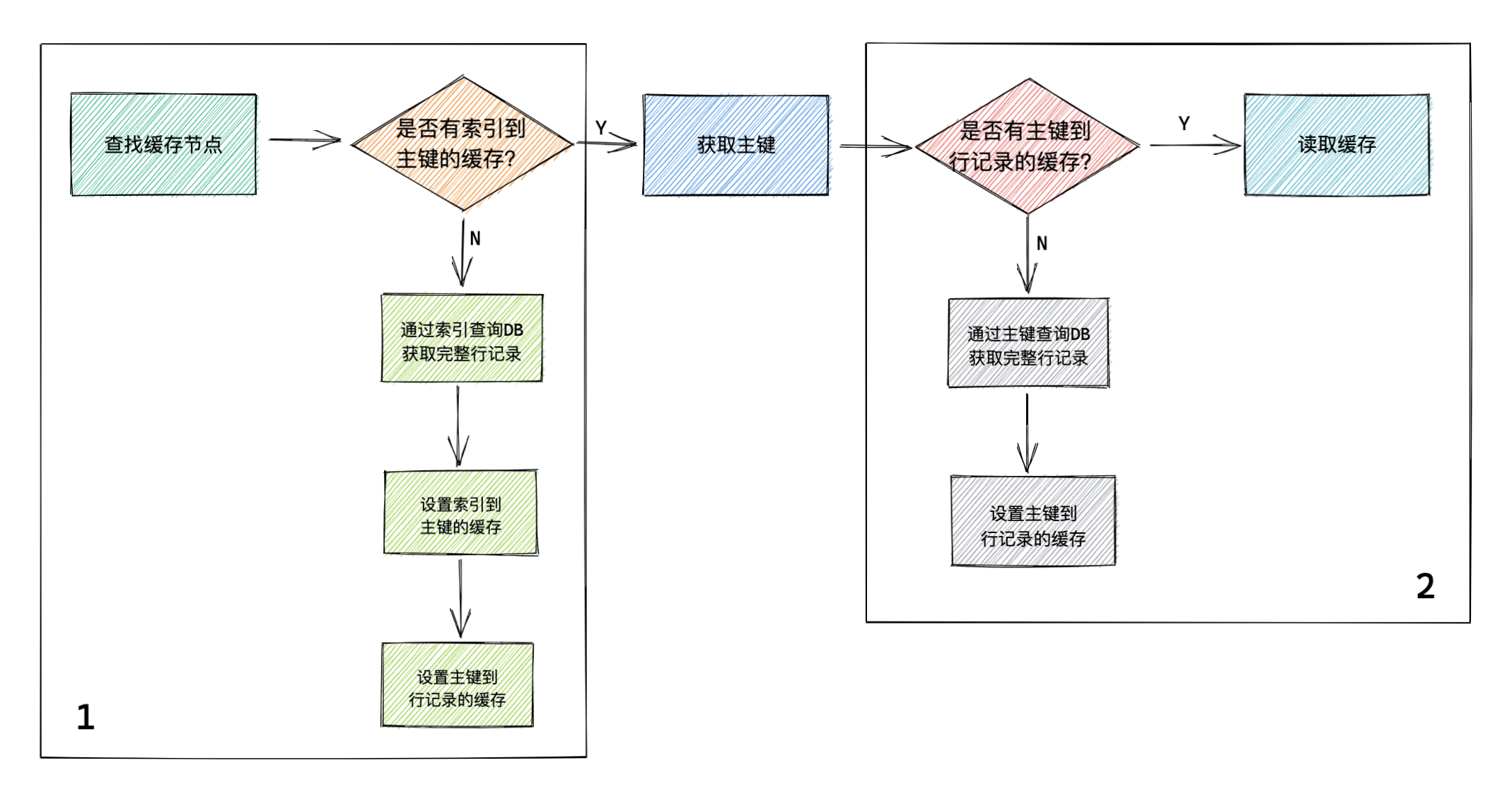
代碼塊的 block 1 部分分為兩種情況:
-
通過索引能夠從快取里找到主鍵
此時就直接用主鍵走
block 2的邏輯了,后續同上面基于主鍵的快取邏輯 -
通過索引無法從快取里找到主鍵
- 通過索引從DB里查詢完整行記錄,如有
error,回傳 - 查到完整行記錄后,會把主鍵到完整行記錄的快取和索引到主鍵的快取同時寫到
redis里 - 回傳所需的行記錄資料
- 通過索引從DB里查詢完整行記錄,如有
// v - 需要讀取的資料物件
// key - 通過索引生成的快取key
// keyer - 用主鍵生成基于主鍵快取的key的方法
// indexQuery - 用索引從DB讀取完整資料的方法,需要回傳主鍵
// primaryQuery - 用主鍵從DB獲取完整資料的方法
func (cc CachedConn) QueryRowIndex(v interface{}, key string, keyer func(primary interface{}) string,
indexQuery IndexQueryFn, primaryQuery PrimaryQueryFn) error {
var primaryKey interface{}
var found bool
// 先通過索引查詢快取,看是否有索引到主鍵的快取
if err := cc.cache.TakeWithExpire(&primaryKey, key, func(val interface{}, expire time.Duration) (err error) {
// 如果沒有索引到主鍵的快取,那么就通過索引查詢完整資料
primaryKey, err = indexQuery(cc.db, v)
if err != nil {
return
}
// 通過索引查詢到了完整資料,設定found,后面直接使用,不需要再從快取讀取資料了
found = true
// 將主鍵到完整資料的映射保存到快取里,TakeWithExpire方法已經將索引到主鍵的映射保存到快取了
return cc.cache.SetCacheWithExpire(keyer(primaryKey), v, expire+cacheSafeGapBetweenIndexAndPrimary)
}); err != nil {
return err
}
// 已經通過索引找到了資料,直接回傳即可
if found {
return nil
}
// 通過主鍵從快取讀取資料,如果快取沒有,通過primaryQuery方法從DB讀取并回寫快取再回傳資料
return cc.cache.Take(v, keyer(primaryKey), func(v interface{}) error {
return primaryQuery(cc.db, v, primaryKey)
})
}
我們來看一個實際的例子
func (m *defaultUserModel) FindOneByUser(user string) (*User, error) {
var resp User
// 生成基于索引的key
indexKey := fmt.Sprintf("%s%v", cacheUserPrefix, user)
err := m.QueryRowIndex(&resp, indexKey,
// 基于主鍵生成完整資料快取的key
func(primary interface{}) string {
return fmt.Sprintf("user#%v", primary)
},
// 基于索引的DB查詢方法
func(conn sqlx.SqlConn, v interface{}) (i interface{}, e error) {
query := fmt.Sprintf("select %s from %s where user = ? limit 1", userRows, m.table)
if err := conn.QueryRow(&resp, query, user); err != nil {
return nil, err
}
return resp.Id, nil
},
// 基于主鍵的DB查詢方法
func(conn sqlx.SqlConn, v, primary interface{}) error {
query := fmt.Sprintf("select %s from %s where id = ?", userRows, m.table)
return conn.QueryRow(&resp, query, primary)
})
// 錯誤處理,需要判斷是否回傳的是sqlc.ErrNotFound,如果是,我們用本package定義的ErrNotFound回傳
// 避免使用者感知到有沒有使用快取,同時也是對底層依賴的隔離
switch err {
case nil:
return &resp, nil
case sqlc.ErrNotFound:
return nil, ErrNotFound
default:
return nil, err
}
}
所有上面這些快取的自動管理代碼都是可以通過 goctl 自動生成的,我們團隊內部 CRUD 和快取基本都是通過 goctl 自動生成的,可以節省大量開發時間,并且快取代碼本身也是非常容易出錯的,即使有很好的代碼經驗,也很難每次完全寫對,所以我們推薦盡可能使用自動的快取代碼生成工具去避免錯誤,
Need more?
如果你想要更好的了解 go-zero 專案,歡迎前往官方網站上學習具體的示例,
視頻回放地址
https://www.bilibili.com/video/BV1Jy4y127Xu
專案地址
https://github.com/tal-tech/go-zero
歡迎使用 go-zero 并 star 支持我們!
go-zero 系列文章見『微服務實踐』公眾號
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/257008.html
標籤:Go