前言??
本文的文字及圖片來源于網路,僅供學習、交流使用,不具有任何商業用途,如有問題請及時聯系我們以作處理,
前文內容??
Python爬蟲入門教程01:豆瓣Top電影爬取
Python爬蟲入門教程02:小說爬取
Python爬蟲入門教程03:二手房資料爬取
Python爬蟲入門教程04:招聘資訊爬取
Python爬蟲入門教程05:B站視頻彈幕的爬取
Python爬蟲入門教程06:爬取資料后的詞云圖制作
Python爬蟲入門教程07:騰訊視頻彈幕爬取
Python爬蟲入門教程08:爬取csdn文章保存成PDF
Python爬蟲入門教程09:多執行緒爬取表情包圖片
Python爬蟲入門教程10:彼岸壁紙爬取
Python爬蟲入門教程11:新版王者榮耀皮膚圖片的爬取
Python爬蟲入門教程12:英雄聯盟皮膚圖片的爬取
Python爬蟲入門教程13:高質量電腦桌面壁紙爬取
Python爬蟲入門教程14:有聲書音頻爬取
Python爬蟲入門教程15:音樂網站資料的爬取
PS:如有需要 Python學習資料 以及 解答 的小伙伴可以加點擊下方鏈接自行獲取
python免費學習資料以及群交流解答點擊即可加入
基本開發環境??
- Python 3.6
- Pycharm
相關模塊的使用??
import os
import concurrent.futures
import requests
import parsel
安裝Python并添加到環境變數,pip安裝需要的相關模塊即可,
一、??確定需求

雖然上面顯示需要付費下載,但是一樣可以免費下載,
二、??網頁資料分析
打開開發者工具,點擊播放音頻,在Media中會加載出音頻的url地址,

如果想要驗證這個鏈接是否是音頻的真實下載地址,可以復制鏈接粘貼到新的視窗中,
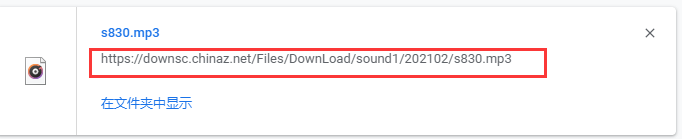
它會自動下載一個音頻檔案,并且這個音頻檔案是可以播放的,和網頁上面的音頻聲音是可以對上的,
事實證明這個就是我們要獲取音頻地址,

https://downsc.chinaz.net/Files/DownLoad/sound1/202102/s830.mp3
老思路了,復制鏈接中的某些引數在開發者工具中進行搜索,很明顯 s830 就是音頻的ID了,

搜索 s830 找到來源,發現網頁頁面中自帶有下載地址,獲取音頻下載地址之后需要自己拼接url,
網頁資料不復雜,相對而言還是比較簡單的,
1、請求當前網頁資料,獲取音頻地址以及音頻標題
2、保存下載就可以了
三、??代碼實作
獲取音頻ID以及音頻標題
def main(html_url):
html_data = https://www.cnblogs.com/Qqun821460695/p/get_response(html_url).text
selector = parsel.Selector(html_data)
lis = selector.css('#AudioList .container .audio-item')
for li in lis:
name = li.css('.name::text').get().strip()
src = https://www.cnblogs.com/Qqun821460695/p/li.css('audio::attr(src)').get()
audio_url = 'https:' + src
save(name, audio_url)
print(name, audio_url)
保存資料
def save(name, audio_url):
header = {
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
audio_content = requests.get(url=audio_url, headers=header).content
path = 'audio\\'
if not os.path.exists(path):
os.mkdir(path)
with open(path + name + '.mp3', mode='wb') as f:
f.write(audio_content)
這里想要重新給一個headers引數,不然會下載不了,代碼會一直運行,但是沒有反應
多執行緒爬取
if __name__ == '__main__':
executor = concurrent.futures.ThreadPoolExecutor(max_workers=5)
for page in range(1, 31):
url = f'https://sc.chinaz.com/yinxiao/index_{page}.html'
# main(url)
executor.submit(main, url)
executor.shutdown()

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/257021.html
標籤:Python