演算法小課堂——最小生成樹Kruskal
- 前言
- 演算法原理
- 代碼實作
- 演算法實操
- UVA1395——苗條的生成樹
- 題目
- 分析
- 代碼實作
- 樣例測驗
- UVa1151——買還是建
- 題目
- 分析
- 代碼實作
- 樣例測驗
- 結語
前言
??hello,大家好吖,上周我們講解了 Floyd演算法,不知大家還有沒有印象嘞~,今天我們來講解一下最小生成樹,簡單又實用的策略優化演算法
演算法原理
??最小生成樹(Kruskal 演算法)適用于求解連通所有節點所需花費最小的問題,最形象的例子就是: 有n個村子,每個村子與其他村子修筑連通的道路需要花費一定金額,怎么樣在保證所有村子連通的情況下使花費最少呢?
??最小生成樹本質是貪心,從耗費最少的邊開始,不斷加入集合,直到所有節點都連通,
??首先,我們將所有的邊按照權重(消耗值)進行從小到大排序,這里我們需要一個集合來存盤最后選出的滿足條件的邊,然后遍歷排序后的邊,如果起點終點不在一個集合,則將終點加入起點的集合中,如果已經在一個集合里,說明前面用更少的消耗(之前從小到大排列的作用)達到了相同的效果,則不采用這條邊,
??可以發現,這個演算法程序主要是連通分量的查詢和合并,需要知道任意兩個節點是不是在同一個連通分量中,根據需要還要合并兩個連通分量,這里說的連通分量可以認為是邊的集合,不唯一,

??存盤連通分量我們可以想到鏈表或者鄰接矩陣,查詢連通我們可以使用DFS或者BFS,但是是對于圖結構而言,而且這種思路會比較復雜點,查詢上效率不高, 坦白說就是費勁
??這里一般教科書推薦是并查集(Union-Find Set),可以把每個連通分量看成一個集合,該集合包含了在這個連通分量的所有節點,而我們不需要去考慮連通的方式,比如順序或者連通的形式,只需要考慮它是不是我的崽,查詢的程序簡單了,合并的程序利用集合的基本操作就可以完成,整個程序就可以比較簡潔,
??下面我們用例子來演示一下:
??比如我們通過查詢邊已經得到三個不同的連通分量如下:
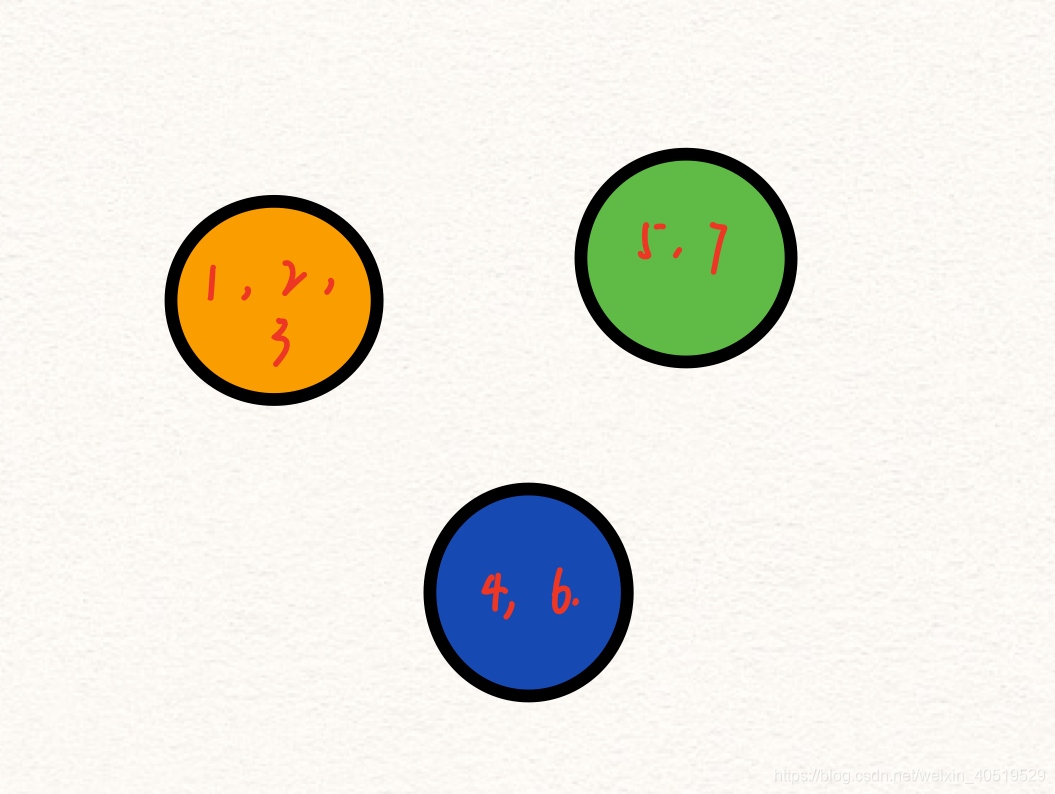
??然后如果橙子集合中的任意一個節點有連接藍色集合里的任意一個節點的邊(查詢是不是同一個連通分量),且為當前下一步的最優,則接下來的連通分量會進行合并:
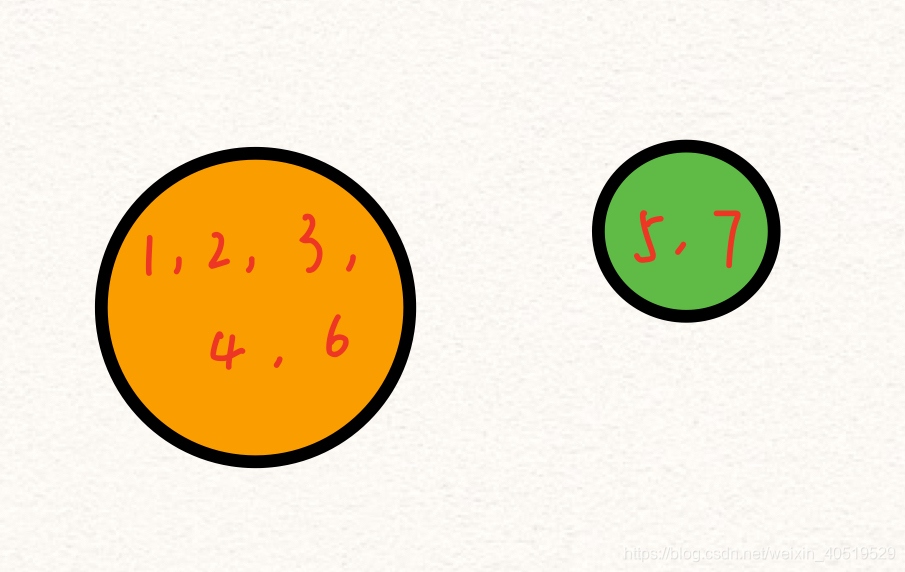
??演算法的終止條件可以是遍歷完所有的邊,也可以是當連通分量有n-1個時(n個節點的圖其無環連通邊的個數為n-1),既然要耗費最少,那自然是沒有多余的邊,
代碼實作
??首先我們需要實作并查集的類及相應的方法,
class Union_find_set:
"""
the implementation of union_find_set
"""
def __init__(self, identity, subset):
# identity: 標號,即所屬連通分量的標簽
# subset: 當前集合的資料
self.identity = identity
self.set = set()
if isinstance(subset, set):
self.set = subset
elif isinstance(subset, list) or isinstance(subset, tuple):
for item in subset:
self.set.add(item)
else:
raise ValueError("Subset should be list or set or tuple type")
# 獲取當前連通分量的標簽
def get_id(self):
return self.identity
# 設定當前連通分量的標簽
def set_id(self, value):
self.identity = value
return
# 獲取當前連通分量的節點資料
def get_set(self):
return (i for i in self.set)
# 設定當前連通分量的節點資料
def set_set(self, s):
self.set = s
return
# 回傳當前連通分量與其他連通分量的并集
def union(self, other):
return self.set.union(other.set)
??然后我們來看看Kruskal演算法的實作(以開頭作為解釋的問題為例:有n個村子m條待修的路,每條路連通兩個村子,且耗費一定金額,求使所有村子互通的最少金額)
def Mini_spanning_tree():
"""
implement Mini_spanning_tree using Union-Find set
"""
# 資料讀入
n, k = list(map(int, input().split()))
data = []
for i in range(k):
data.append(list(map(int, input().split())))
data = sorted(data, key=lambda x: x[2])
# 總耗費
tot = 0
# 選出的邊集合
path = []
s = dict()
# 初始化: 節點各自為營
for i in range(n+1):
s[i] = Union_find_set(i, [i])
# 遍歷
for d in data:
u, v, w = d
# 編號不同且路徑小于n-1,連通情況下路徑數量等于節點數-1
if s[u].get_id() != s[v].get_id() and len(path) < n - 1:
# 修改節點v所在連通分量里所有節點的標簽號
for i in s[v].get_set():
s[i].set_id(s[u].get_id())
# 獲取節點u和節點v各自所在的連通分量的并集
temp = s[u].union(s[v])
# 將并集里的所有節點的連通分量設定成該并集,即每個節點的并查集類都存盤有其所屬連通分量的所有資料資訊
for t in temp:
s[t].set_set(temp)
tot += w
path.append(d)
print("Total comsuption: {}".format(tot))
# print("The path is belowing:")
# print(*path)
return
??測驗一下例子:
>>> Mini_spanning_tree()
6 9
1 2 4
1 3 -1
2 3 3
2 4 5
4 5 10
2 6 10
3 6 10
4 6 1
5 6 1
Total comsuption: 9
The path is belowing:
[1, 3, -1] [4, 6, 1] [5, 6, 1] [2, 3, 3] [2, 4, 5]
演算法實操
UVA1395——苗條的生成樹
題目
??給出一個n(n≤100)節點的圖,求苗條度(最大邊減最小邊的值)盡量小的生成樹,
分析
??根據 《演算法競賽入門》 第2版的內容,這個題目是想要得出一個最值,那程式自然是回圈判斷,消耗最少的最小生成樹不一定是最苗條的,我們還是先按邊權值從小到大排序,
對于一個邊的區間 [L,R](L+n-1 ≤ R ≤ k),如果這些邊使得所有節點全部連通,那么一定存在苗條度不大于 w[R] - w[L] 的生成樹,如果從L起連續n-1條邊就可以使節點全部連通,那么其苗條度最小,如果不行,增大R,把新加入的邊與之前生成的連通集合一起做 Kruskal,直到所有節點連通,更新L,繼續列舉R,
代碼實作
def UVA_1395():
# 資料讀入,單次測驗
n, k = list(map(int, input().split()))
data = []
for i in range(k):
data.append(list(map(int, input().split())))
data = sorted(data, key=lambda x: x[2])
# 最小耗費,初始化為最大消耗的邊
min_tot = data[-1][2]
# 最小生成樹函式,給定資料范圍和并查集,回傳連通的路徑節點list
def Kruskal(sub_data, s, path):
# sub_data: 用來更新的資料
# s: 并查集
# path: 連通的路徑節點list
nonlocal n
for d in sub_data:
u, v, w = d
# 編號不同且路徑小于n-1,連通情況下路徑數量等于節點數-1
if s[u].get_id() != s[v].get_id() and len(path) < n - 1:
# 修改節點v所在連通分量里所有節點的標簽號
for i in s[v].get_set():
s[i].set_id(s[u].get_id())
# 獲取節點u和節點v各自所在的連通分量的并集
temp = s[u].union(s[v])
# 將并集里的所有節點的連通分量設定成該并集,即每個節點都存盤有其所屬連通分量的所有資料資訊
for t in temp:
s[t].set_set(temp)
path.append(d)
return path
# 特殊測驗例子:只有一條路,兩個節點
if n == 2 and k == 1:
print(0)
return
# 不滿足連通條件要求的邊數量
elif k < n-1:
print(-1)
return
# 有最小生成樹方案標志
flag = False
# 根據連通的邊數量限制,起點遍歷范圍為[0, k-(n-1)-1]
for s in range(k - (n - 1)):
# 每次列舉L要重新生成并查集
uf_set.clear()
for i in range(k):
uf_set[i] = Union_find_set(i, [i])
# 如果從L到L+n-1的邊可以連通,那就是該情況的“最苗條”解
path = Kruskal(data[s:s + n], uf_set, [])
# print(path)
if len(path) == n - 1:
min_tot = min(min_tot, path[-1][2] - path[0][2])
flag = True
continue
# 如果不可以連通,則列舉R
else:
for v in range(s + n, k):
# 記得把第一次Kruskal生成的path傳入
path = Kruskal(data[s:v + 1], uf_set, path)
# print(s, v, path)
if len(path) == n - 1:
min_tot = min(min_tot, path[-1][2] - path[0][2])
flag = True
break
else:
continue
if flag:
print(min_tot)
else:
print(-1)
return
樣例測驗
>>> UVA_1395()
5 8
1 2 1
2 3 100
3 4 100
4 5 100
1 5 50
2 5 50
3 5 50
4 1 150
[output]
50
>>> UVA_1395()
5 10
1 2 110
1 3 120
1 4 130
1 5 120
2 3 110
2 4 120
2 5 130
3 4 120
3 5 110
4 5 120
[output]
0
>>> UVA_1395()
5 10
1 2 9384
1 3 887
1 4 2778
1 5 6916
2 3 7794
2 4 8336
2 5 5387
3 4 493
3 5 6650
4 5 1422
[output]
1686

UVa1151——買還是建
題目
??平面上有n個點,為了讓n個點連通,你可以新建一些邊,建造邊的費用等于兩個端點坐標距離的平方,另外還提供q個套餐可供購買,購買了第i個套餐,則該套餐中所有的節點變得相互連通,求出能夠使所有節點連通且花費最少的方案,給出其花費,
分析
??根據 《演算法競賽入門》 第2版的內容,由于買了套餐相當于添加了一些權重為0的邊,我們可以去列舉購買套餐的方案,然后去分別進行Kruskal,得出最優解,但是這樣做的復雜度規模太大了,列舉需要 2 q 2^q 2q, 排序需要 O ( n 2 l o g n ) O(n^2 logn) O(n2logn),排序之后Kruskal演算法的時間復雜度為 n 2 n^2 n2, 因此總的時間復雜度為 O ( 2 q ( n 2 + n 2 l o g n ) ) O(2^q (n^2+n^2logn)) O(2q(n2+n2logn)),
??這里我們需要先求一次原始圖的最小生成樹,再結合套餐的列舉去求新的最小生成樹,結合Kruskal,即最小生成樹的特性,排序較后或者兩端已經是在同一個連通分量里的邊不會去考慮,而題目里的套餐其實是增加了權重為0的邊,即在原本的邊排序的最前面插入一些邊,那么在考慮到原始圖構成的最小生成樹的情況下,我們只是加入了一些權重為0的邊,肯定也可以使所有節點連通,因為本來就可以連通了嘛,我們都求了一次Kruskal了,
??所以,原來被原始圖的Kruskal所拋棄的邊,再后續結合套餐的Kruskal中依舊會被拋棄,就會大大減少需要check的邊數量,復雜度就會降下來,
代碼實作
def UVa1151():
# 讀入資料
n, k = list(map(int, input().split()))
sub_net = []
for i in range(k):
sub_net.append(list(map(int, input().split())))
# 注意題目給的序號是從1開始的,一個小坑
for j in range(sub_net[i][0]):
sub_net[i][2 + j] -= 1
# 存盤坐標
city = []
for i in range(n):
city.append(list(map(int, input().split())))
# 原題的意思應該是距離的平方!
Get_dis = lambda x, y: (
(city[x][0] - city[y][0]) ** 2 + (city[x][1] - city[y][1]) ** 2)
# 存盤邊
edges = []
for i in range(n):
for j in range(i + 1, n):
edges.append([i, j, Get_dis(i, j)])
# 排序
edges = sorted(edges, key=lambda x: x[2])
# Kruskal演算法
def Kruskal(sub_data, s, path):
# sub_data: 用來更新的資料
# s: 并查集
# path: 連通的路徑節點list
nonlocal n
for d in sub_data:
u, v, w = d
# 編號不同且路徑小于n-1,連通情況下路徑數量等于節點數-1
if s[u].get_id() != s[v].get_id() and len(path) < n - 1:
# 修改節點v所在連通分量里所有節點的標簽號
for i in s[v].get_set():
s[i].set_id(s[u].get_id())
# 獲取節點u和節點v各自所在的連通分量的并集
temp = s[u].union(s[v])
# 將并集里的所有節點的連通分量設定成該并集,即每個節點都存盤有其所屬連通分量的所有資料資訊
for t in temp:
s[t].set_set(temp)
path.append(d)
return path
# 初始化并查集
s = dict()
for i in range(len(edges)):
s[i] = Union_find_set(i, [i])
# 得到原始圖的最小生成樹
path = Kruskal(edges, s, [])
# 輸出
ans_tot = sum([p[2] for p in path]) # 總耗費
ans_path = [] # 邊
ans_plan = 0 # 方案列舉的二進制數
# 二進制列舉購買方案的種類
for i in range(1, 2**k, 1):
tot = 0
path_copy = path.copy()
for j in range(k):
# 二進制的每一位代表該方案是否購買
if (i >> j) & 1:
tot += sub_net[j][1]
for m in range(sub_net[j][0]-1):
path_copy.append([sub_net[j][m+2], sub_net[j][m+3], 0])
# 排序
path_copy = sorted(path_copy, key=lambda x: x[2])
# 初始化并查集
s.clear()
for idx in range(len(path_copy)):
s[idx] = Union_find_set(idx, [idx])
new_path = Kruskal(path_copy, s, [])
# 計算消耗
tot = sum([p[2] for p in new_path]) + tot
# 更新
if tot < ans_tot:
ans_tot = tot
ans_path = new_path
ans_plan = i
# 列印最佳方案
print("The Optimal Plan: ")
for i in range(k):
if (ans_plan >> i) & 1:
print("Buy sub_net {}".format(i+1))
for p in ans_path:
if p[2] != 0:
print("Build edge from node {} to node {}".format(p[0], p[1]))
print("Total money: {}".format(ans_tot))
return
樣例測驗
>>> UVa1151()
7 3
2 4 1 2
3 3 3 6 7
3 9 2 4 5
0 2
4 0
2 0
4 2
1 3
0 5
4 4
[output]
The Optimal Plan:
Buy sub_net 1
Buy sub_net 2
Build edge from node 0 to node 4
Build edge from node 1 to node 2
Build edge from node 1 to node 3
Total money: 17
結語
??最小生成樹是策略優化型演算法,在演算法題目中也比較常見,掌握起來也并不困難,
??題目的代碼實作都是小刀自己手敲,可能會出現bug,如有錯誤,還望指正,如果覺得這篇blog解答了你的疑惑或者讓你有所識訓,那就點個贊吧~


轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/257218.html
標籤:python