目錄
- 中國天氣網爬蟲資料可視化
- 爬蟲功能
- 網頁分析
- 以華北地區為例分析網頁源代碼
- 1.以谷歌瀏覽器為例分析
- 2. 提取特征標簽
- 3.分析源代碼
- 利用requests庫獲取目標網頁源代碼
- 利用BeautifulSoup庫提取天氣資訊
- 港澳臺地區代碼分析
- 分析資料
- 資料可視化
- 結果展示
- 總結
- 最后附整個源代碼!
中國天氣網爬蟲資料可視化
感謝閱讀最愛小魚果的博客,
本篇博客在于記錄本人學習爬蟲程序中的一些專案案例,如有錯誤還請大家批評指正!
爬蟲功能
大家好,我來講講怎么用python對中國天氣網進行爬取并且對爬取到的資料進行資料可視化的顯示:
- 爬取全國各個城市的氣溫(最高氣溫,最低氣溫);
- 獲取全國城市中氣溫最低和最高的前十名城市(地區)進行可視化操作(以直方圖的形式給出展示形式為 .html格式)
網頁分析
首先打開中國天氣網,找到全國各個區域(華北、東北、華東、華中、華南、西北、西南、港澳臺)天氣資訊,
以華北地區為例分析網頁源代碼
1.以谷歌瀏覽器為例分析
打開谷歌瀏覽器,打開華北地區天氣預報,滑鼠右鍵點擊 檢查,找到Elements
如圖所示:
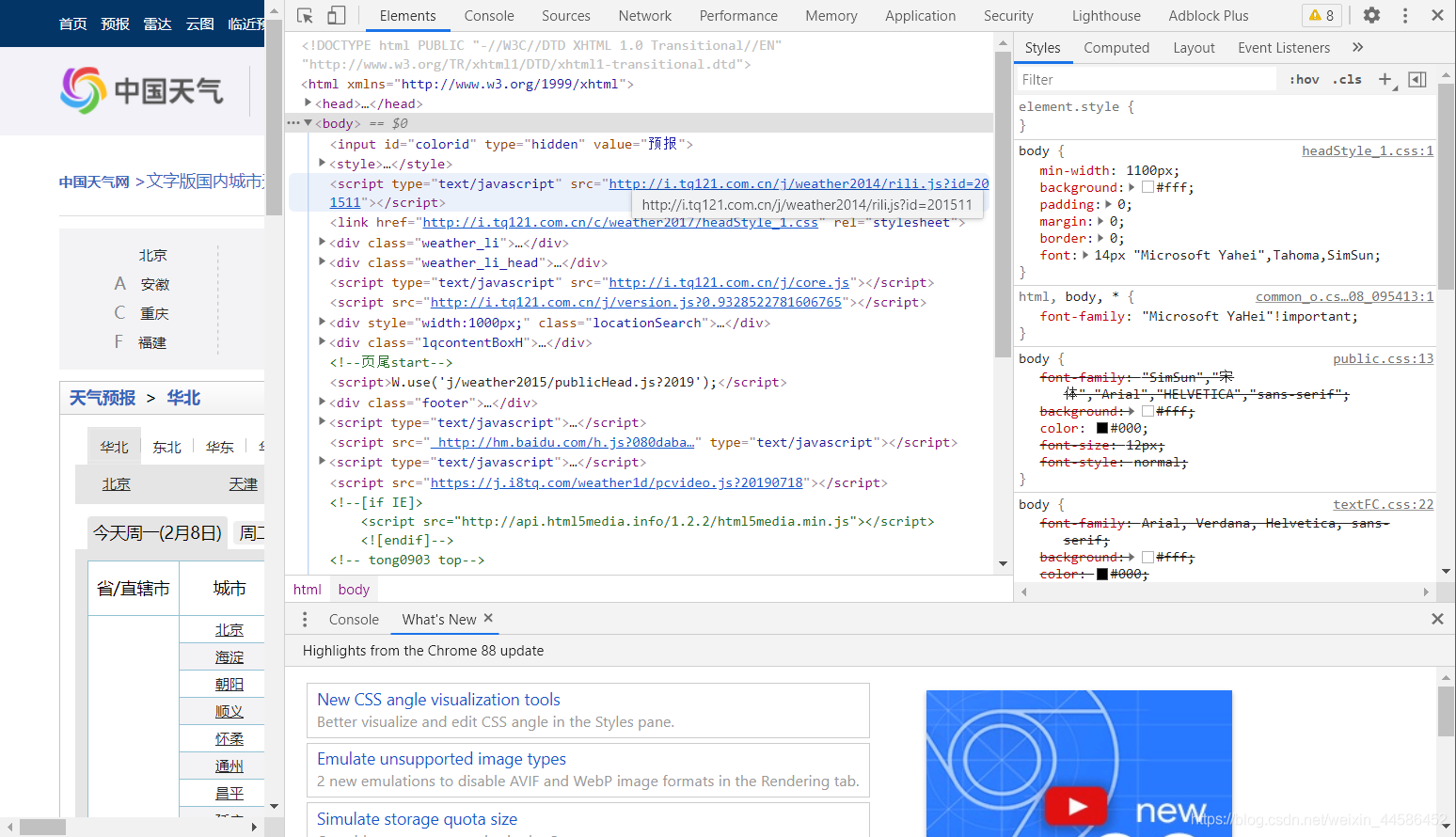
2. 提取特征標簽
找到我們所需要的資訊所在的網頁源代碼特征標簽
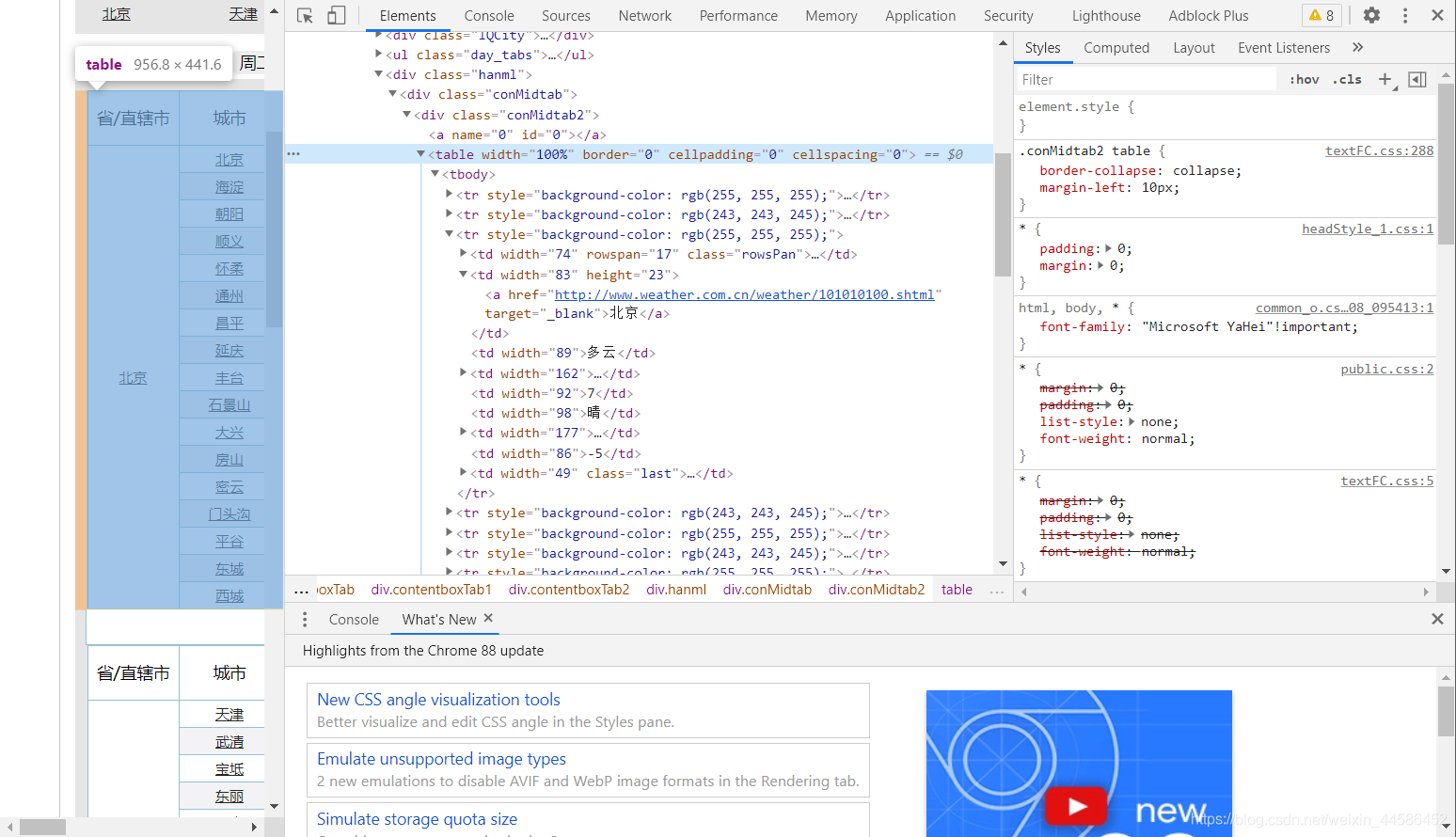
獲取所有<tably>標簽,
分析可知所有城市天氣資訊在<tably>標簽下的<tr>標簽
獲取所有<tr>標簽,
在對應的<tr>標簽中找到城市所在代碼區域:

3.分析源代碼
分析網頁源代碼可知,前兩個<tr>標簽為表頭資訊,第一個<td>標簽為省會(直轄市),為冗余資訊,
利用requests庫獲取目標網頁源代碼
若沒有安裝則運行cmd命令,輸入pip install requests
# utf-8
import requests
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',
# 'Referer': 'http://www.weather.com.cn/textFC/hb.shtml'
} # 模擬瀏覽器
response = requests.get(url=url, headers=header) # 發送get命令
text = response.content.decode('utf-8') # 解碼方式為utf-8
利用BeautifulSoup庫提取天氣資訊
上面我們分析了目標網頁源代碼,知道了我們所需要的資訊所在的區域,利用BeautifulSoup庫獲取,
若沒有安裝則運行cmd命令,輸入pip install bs4進行安裝
# utf-8
from bs4 import BeautifulSoup
ALL_DATA = []
# text用requests庫獲取
soup = BeautifulSoup(text,'lxml') # 以lxml方式決議
conMidtab = soup.find('div',class_='conMidtab')
tables = conMidtab.find_all('table')
for table in tables:
trs = table.find_all('tr')[2:]
for tr in trs:
tds = tr.find_all('td')
chengs = list(tds[-8].stripped_strings)[0] # 倒數第8個為城市資訊
maxtemp = list(tds[-5].stripped_strings)[0] # 倒數第5個位最高氣溫
mintemp = list(tds[-2].stripped_strings)[0] # 倒數第2個為最低氣溫
ALL_DATA.append({"城市":chengs,"最高氣溫":int(maxtemp),"最低氣溫":int(mintemp)})
ALL_DATA就是我們所需要的全部資訊,
港澳臺地區代碼分析
因為在港澳臺地區天氣資料的網頁代碼,并不知道嚴格的標準html語法,<tably>標簽并不成對出現,因此使用lxml決議就會出錯,這里應該使用容錯能力強的html5lib進行決議,但是html5lib進行決議的話會比使用lxml決議慢不少,因此除港澳臺以為我們依然采用lxml進行決議,
若沒有安裝則運行cmd命令,輸入pip install html5lib進行安裝
urls = {
'http://www.weather.com.cn/textFC/hb.shtml',
'http://www.weather.com.cn/textFC/db.shtml',
'http://www.weather.com.cn/textFC/hd.shtml',
'http://www.weather.com.cn/textFC/hz.shtml',
'http://www.weather.com.cn/textFC/hn.shtml',
'http://www.weather.com.cn/textFC/xb.shtml',
'http://www.weather.com.cn/textFC/xn.shtml'
}
for url in urls:
parse_page(url,'lxml')
url_gat = 'http://www.weather.com.cn/textFC/gat.shtml'
parse_page(url_gat,'html5lib')
分析資料
將ALL_DATA進行排序,獲取前十位資料(最低氣溫)和后十位資料(最高氣溫),
ALL_DATA.sort(key=lambda data:data["最低氣溫"])
min_data = ALL_DATA[:10]
max_data = ALL_DATA[-10:-1]
資料可視化
這里要用到pyecharts庫
安裝方法:運行cmd命令,輸入pip install bs4
cities_min = list(map(lambda x:x["城市"], min_data))
cities_max = list(map(lambda x:x["城市"], max_data))
min_temp = list(map(lambda x:x["最低氣溫"], min_data))
max_temp = list(map(lambda x: x["最高氣溫"], max_data))
bar1 = Bar()
bar1.add_xaxis(cities_min)
bar1.add_yaxis("氣溫/℃", min_temp)
bar1.set_global_opts(title_opts={"text": "中國城市氣溫排行榜", "subtext": "最低氣溫"})
bar1.render("最低氣溫.html")
bar2 = Bar()
bar2.add_xaxis(cities_max)
bar2.add_yaxis("氣溫/℃", max_temp)
bar2.set_global_opts(title_opts={"text": "中國城市氣溫排行榜", "subtext": "最高氣溫"})
bar2.render("最高氣溫.html")
結果展示
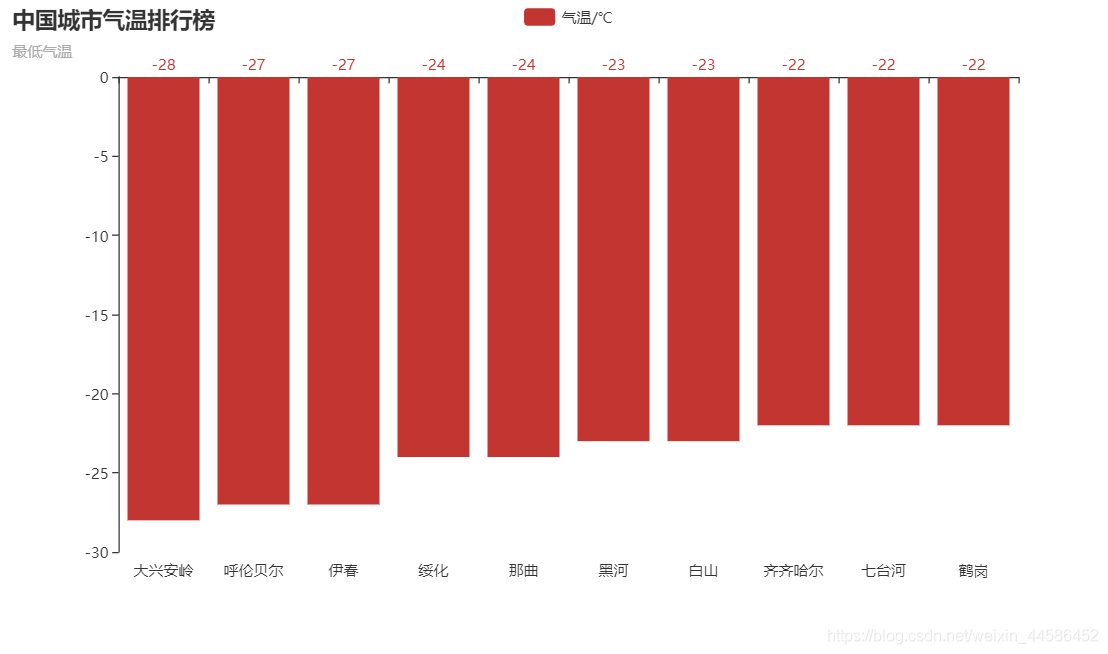
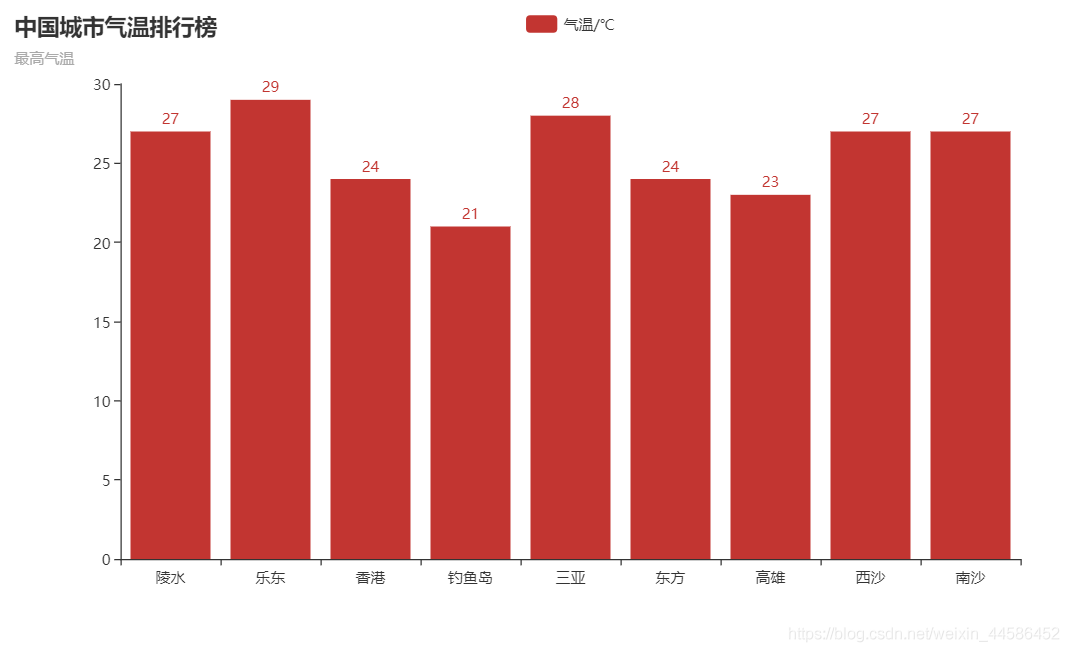
在代碼所在目錄自動生成 最低氣溫.html檔案和最高氣溫.html檔案,
打開檔案:最低氣溫.html
2021.2.28
打開檔案:最高氣溫.html
2021.2.28
總結
首先分析網頁代碼,找到所需資訊對應的標簽,然后對資訊進行提取,再使用可視化工具庫進行可視化操作,
中國天氣網網站源代碼簡單,易于獲取天氣資訊,非常適合新手來練習,最后附整個源代碼!
重申:本篇博客在于記錄本人學習爬蟲程序中的一些專案案例,如有錯誤還請大家批評指正!
如需參考則請注明出處!感謝大家閱讀!
最后附整個源代碼!
import requests
from bs4 import BeautifulSoup
from pyecharts.charts import Bar
ALL_DATA = []
def parse_page(url,jiex):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',
# 'Referer': 'http://www.weather.com.cn/textFC/hb.shtml'
}
response = requests.get(url=url, headers=header)
text = response.content.decode('utf-8')
soup = BeautifulSoup(text,jiex)
conMidtab = soup.find('div',class_='conMidtab')
tables = conMidtab.find_all('table')
for table in tables:
trs = table.find_all('tr')[2:]
for tr in trs:
tds = tr.find_all('td')
chengs = list(tds[-8].stripped_strings)[0]
maxtemp = list(tds[-5].stripped_strings)[0]
mintemp = list(tds[-2].stripped_strings)[0]
ALL_DATA.append({"城市":chengs,"最高氣溫":int(maxtemp),"最低氣溫":int(mintemp)})
def main():
urls = {
'http://www.weather.com.cn/textFC/hb.shtml',
'http://www.weather.com.cn/textFC/db.shtml',
'http://www.weather.com.cn/textFC/hd.shtml',
'http://www.weather.com.cn/textFC/hz.shtml',
'http://www.weather.com.cn/textFC/hn.shtml',
'http://www.weather.com.cn/textFC/xb.shtml',
'http://www.weather.com.cn/textFC/xn.shtml'
}
for url in urls:
parse_page(url,'lxml')
url_gat = 'http://www.weather.com.cn/textFC/gat.shtml'
parse_page(url_gat,'html5lib')
# 分析資料
ALL_DATA.sort(key=lambda data:data["最低氣溫"])
min_data = ALL_DATA[:10]
max_data = ALL_DATA[-10:-1]
# 資料可視化
cities_min = list(map(lambda x:x["城市"], min_data))
cities_max = list(map(lambda x:x["城市"], max_data))
min_temp = list(map(lambda x:x["最低氣溫"], min_data))
max_temp = list(map(lambda x: x["最高氣溫"], max_data))
bar1 = Bar()
bar1.add_xaxis(cities_min)
bar1.add_yaxis("氣溫/℃", min_temp)
bar1.set_global_opts(title_opts={"text": "中國城市氣溫排行榜", "subtext": "最低氣溫"})
bar1.render("最低氣溫.html")
bar2 = Bar()
bar2.add_xaxis(cities_max)
bar2.add_yaxis("氣溫/℃", max_temp)
bar2.set_global_opts(title_opts={"text": "中國城市氣溫排行榜", "subtext": "最高氣溫"})
bar2.render("最高氣溫.html")
if __name__ == '__main__':
main()
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/258187.html
標籤:python