文章目錄
- 一、前言
- 二、資料查看和預處理
- 三、資料分析
這短短的一生,我們最終都會失去
你不妨大膽一些
愛一個人,攀一座山,追一個夢
一、前言
資料來源:http://www.zhenai.com/zhenghun/
本文利用 Python 分析了按城市尋找所有地區的征婚資訊,看看相親男女的畫像,
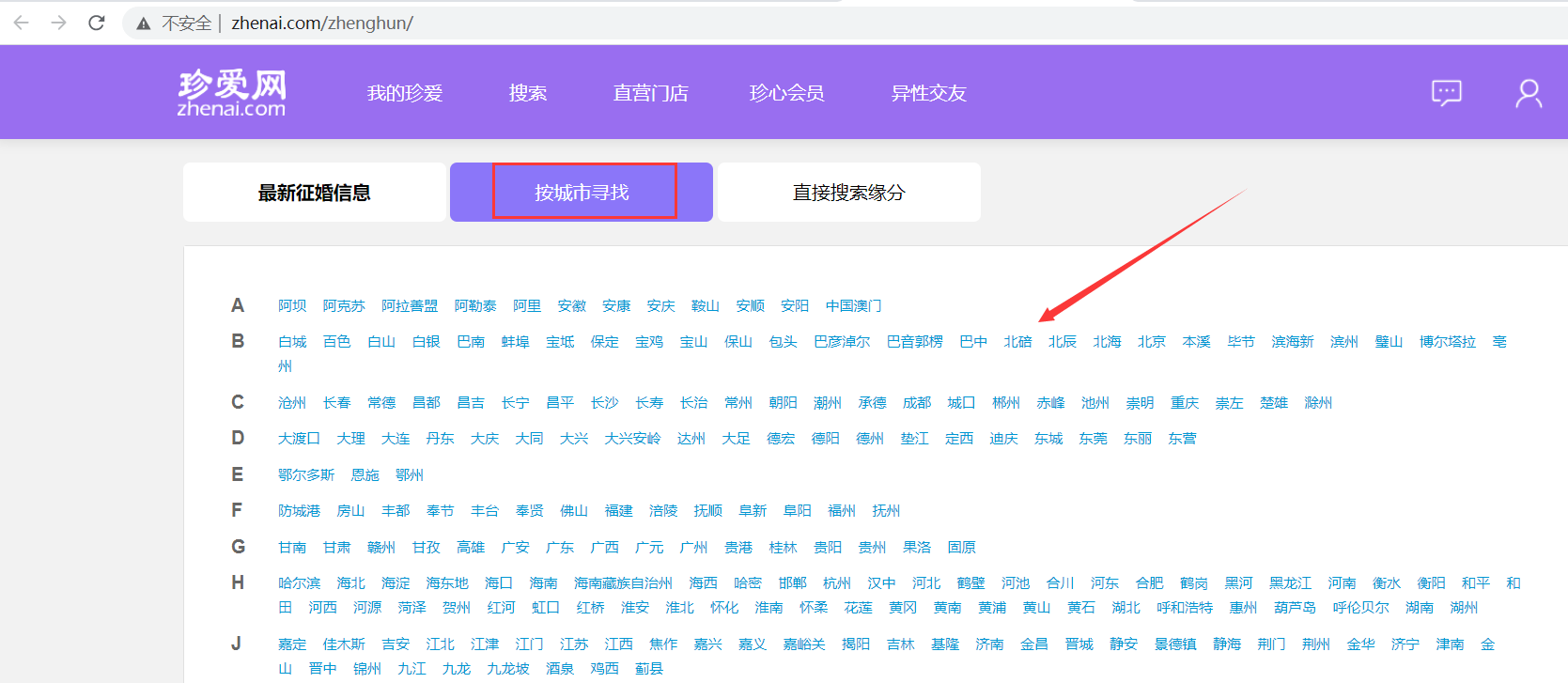
二、資料查看和預處理
匯入用到的庫
import pandas as pd
import re
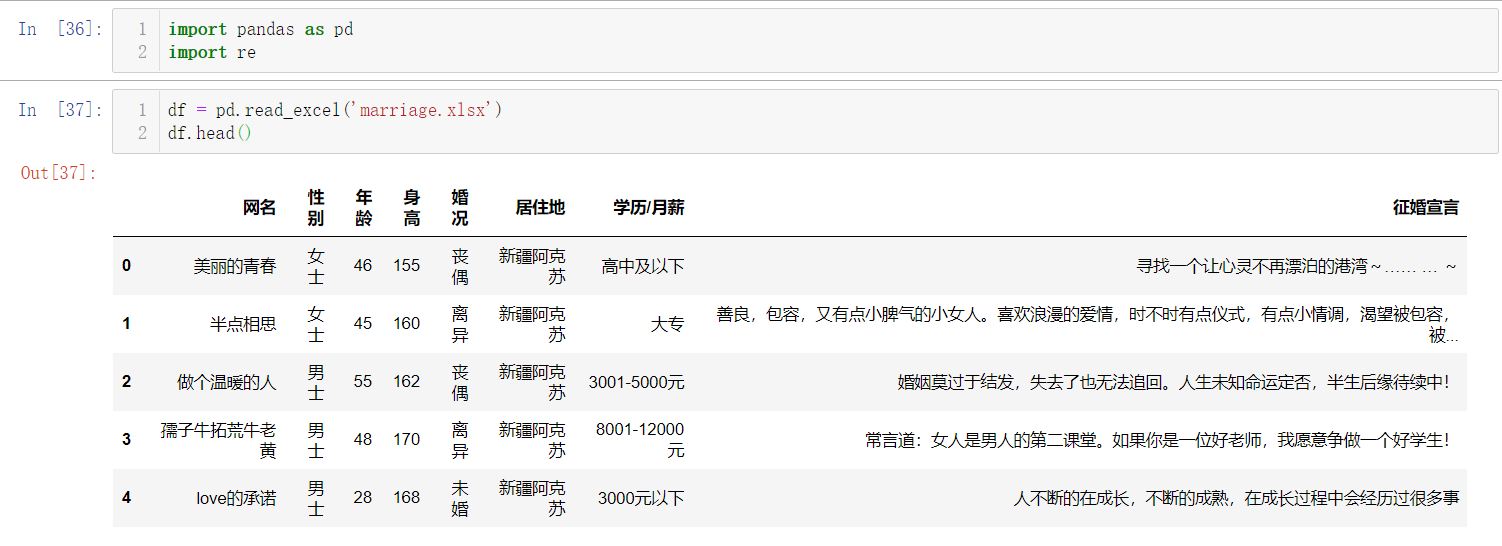
讀取資料,查看前 5 行
df = pd.read_excel('marriage.xlsx')
df.head()
結果如下:
查看索引、資料型別和記憶體資訊
df.info()
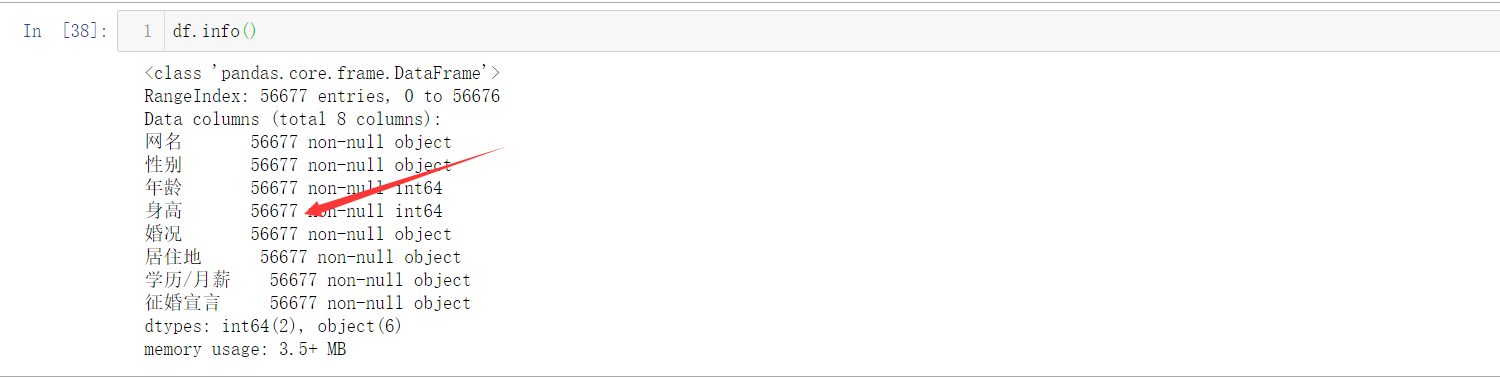
可以看到資料沒有缺失值,
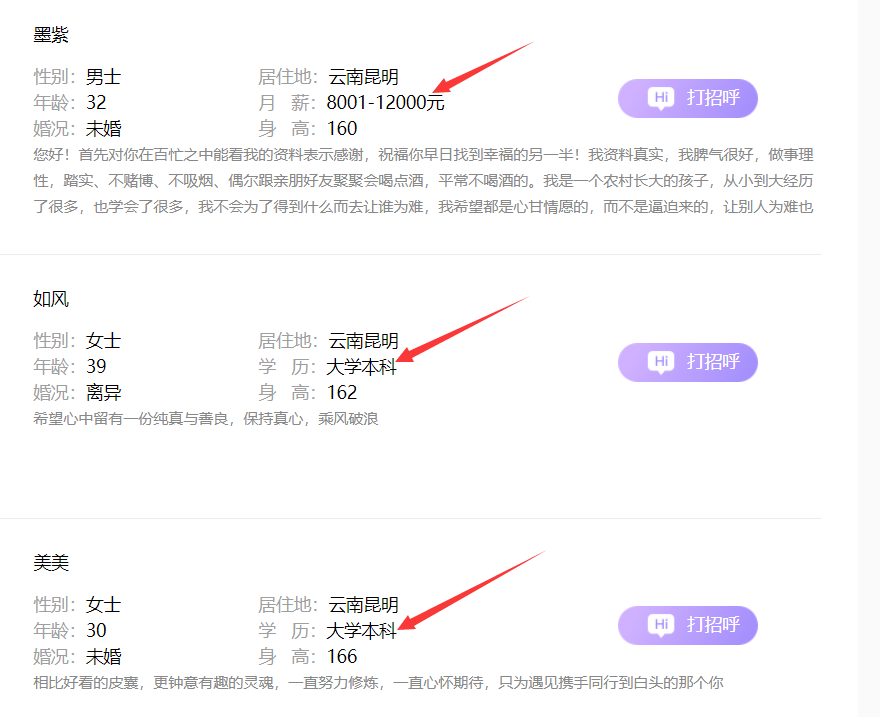
獲取到的資料里,居住地是各地區的,為了便于分析,需要處理成省級行政區,學歷/月薪那一列資料,有些是月薪,有些是學歷,可以分別處理成兩列資料,是學歷的,提取出學歷層次,月薪標記為 “未知”;是月薪的,提取出月薪并計算,學歷標記為 “未知”,
# 獲取34個省級行政區域,包括23個省,5個自治區,4個直轄市,2個特別行政區的名稱
with open('地區.txt', 'r', encoding='utf-8') as f:
area = f.read().split('\n')
print(area)
print(len(area))
結果如下:
['北京', '上海', '天津', '重慶', '黑龍江', '吉林', '遼寧', '內蒙古', '河北', '新疆', '甘肅', '青海', '陜西', '寧夏', '河南', '山東', '山西', '安徽', '湖北', '湖南', '江蘇', '四川', '貴州', '云南', '廣西', '西藏', '浙江', '江西', '廣東', '福建', '臺灣', '海南', '香港', '澳門']
34
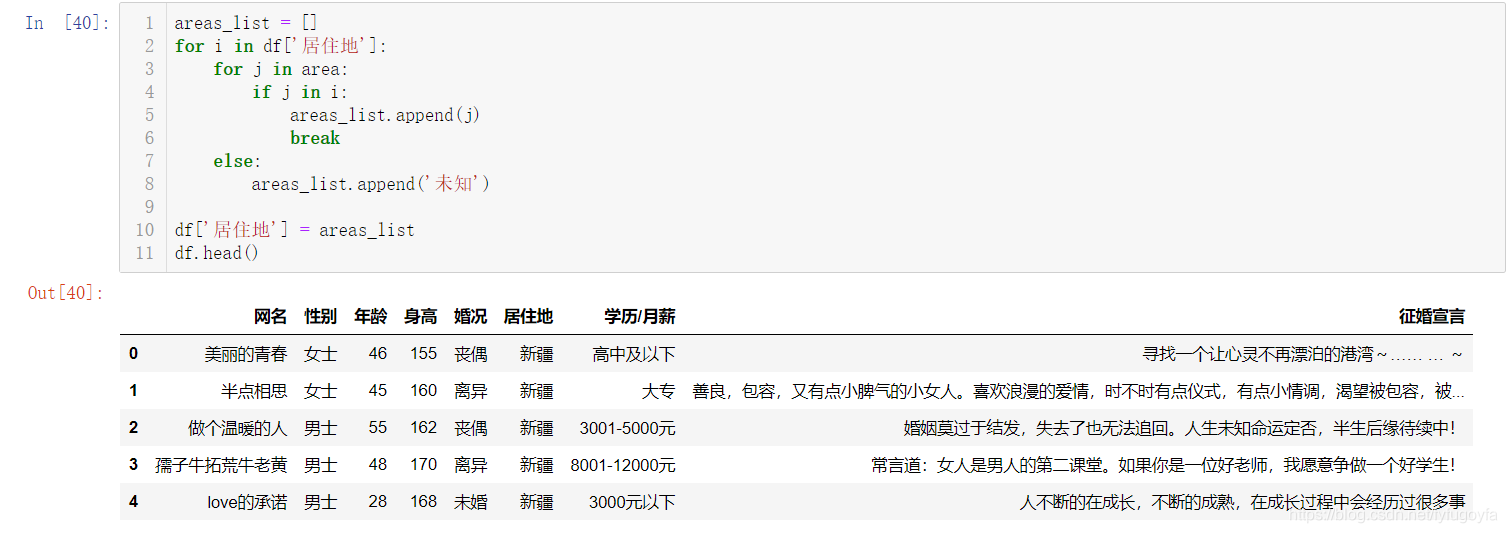
areas_list = []
for i in df['居住地']:
for j in area:
if j in i:
areas_list.append(j)
break
else:
areas_list.append('未知')
df['居住地'] = areas_list
df.head()
結果如下:
with open('學歷.txt', 'r', encoding='utf-8') as fp:
edu = fp.read().split('\n')
print(edu)
結果如下:
['博士', '碩士', '本科', '大專', '中專', '高中', '初中', '小學']
salary_list = []
edu_list = []
for item in df['學歷/月薪']:
if '元' in item: # 這一列的資料是表達月薪的話 計算
data = re.findall('\d+', item)
data = [int(x) for x in data]
salary = int(sum(data) / len(data)) # 取整
salary_list.append(salary)
edu_list.append('未知')
else:
salary_list.append('未知')
for e in edu:
if e in item:
edu_list.append(e)
break
else:
edu_list.append('未知')
print(len(edu_list))
print(len(salary_list))
df['學歷'] = edu_list
df['月薪'] = salary_list
df.head()
結果如下:

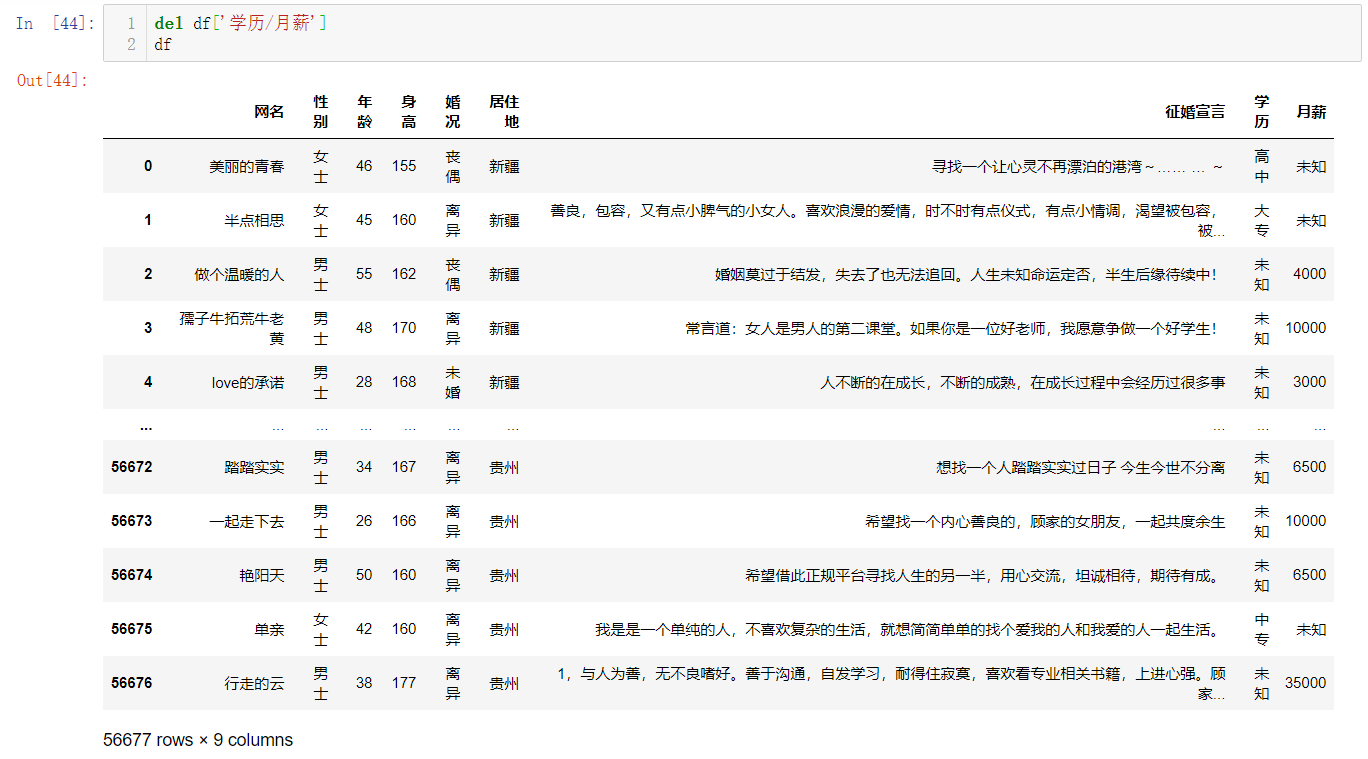
這時候資料處理好了,可以刪掉學歷/月薪這一列,再重新保存到Excel,
del df['學歷/月薪']
df
df.to_excel('處理后資料.xlsx', index=False)
三、資料分析
相親男女占比情況如何?
# -*- coding: UTF-8 -*-
"""
@File :男女占比情況.py
@Author :葉庭云
@CSDN :https://yetingyun.blog.csdn.net/
"""
import pandas as pd
import collections
from pyecharts.charts import Pie
from pyecharts import options as opts
from pyecharts.globals import ThemeType, CurrentConfig
# 參考本地js資源渲染
CurrentConfig.ONLINE_HOST = 'D:/python/pyecharts-assets-master/assets/'
# 提取資料
df = pd.read_excel('處理后資料.xlsx')
gender = list(df['性別'])
# 統計男女人數
gender_count = collections.Counter(gender).most_common()
pie = Pie(init_opts=opts.InitOpts(theme=ThemeType.MACARONS))
# 富文本效果 環圖
pie.add('性別', data_pair=gender_count, radius=["40%", "55%"],
label_opts=opts.LabelOpts(
position="outside",
formatter="{a|{a}}{abg|}\n{hr|}\n {b|{b}: }{c} {per|{d}%} ",
background_color="#eee",
border_color="#aaa",
border_width=1,
border_radius=4,
rich={
"a": {"color": "#999", "lineHeight": 22, "align": "center"},
"abg": {
"backgroundColor": "#e3e3e3",
"width": "100%",
"align": "right",
"height": 22,
"borderRadius": [4, 4, 0, 0],
},
"hr": {
"borderColor": "#aaa",
"width": "100%",
"borderWidth": 0.5,
"height": 0,
},
"b": {"fontSize": 16, "lineHeight": 33},
"per": {
"color": "#eee",
"backgroundColor": "#334455",
"padding": [2, 4],
"borderRadius": 2,
},
},
),)
pie.set_global_opts(title_opts=opts.TitleOpts(title='相親男女占比情況'))
pie.set_colors(['red', 'blue']) # 設定顏色
pie.render('男女占比情況.html')
結果如下:
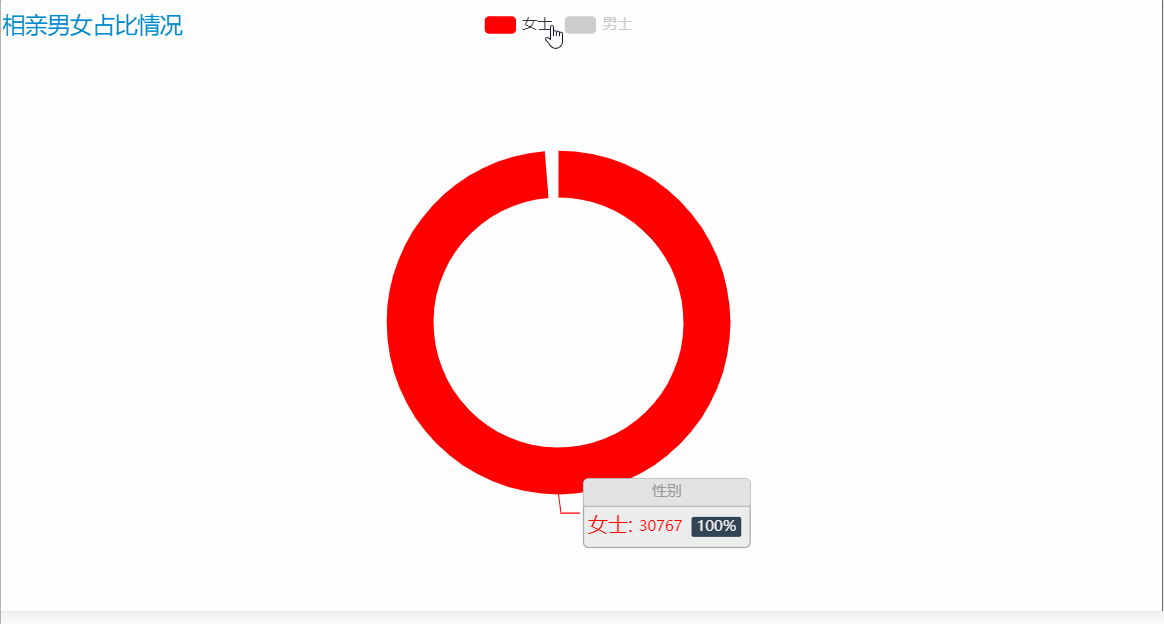
相親男女中男士有 25910 人,占比45.72%;女士有 30767 人,占比54.28%,參加相親人數中女士多于男士,
相親男女年齡分布?
# -*- coding: UTF-8 -*-
"""
@File :年齡分布.py
@Author :葉庭云
@CSDN :https://yetingyun.blog.csdn.net/
"""
import pandas as pd
import collections
from pyecharts.charts import Bar
from pyecharts.globals import ThemeType, CurrentConfig
from pyecharts import options as opts
CurrentConfig.ONLINE_HOST = 'D:/python/pyecharts-assets-master/assets/'
df = pd.read_excel('處理后資料.xlsx')
age = list(df['年齡'])
age_count = collections.Counter(age).most_common()
# 按年齡排序
age_count.sort(key=lambda x: x[0])
age = [x[0] for x in age_count]
nums = [y[1] for y in age_count]
# print(age_count)
bar = Bar(init_opts=opts.InitOpts(theme=ThemeType.MACARONS))
bar.add_xaxis(age)
bar.add_yaxis('人數', nums) # 資料多的時候設定不顯示標簽
bar.set_global_opts(title_opts=opts.TitleOpts(title='相親男女年齡分布'))
# 標記最大值 最小值 平均值 標記平均線
bar.set_series_opts(label_opts=opts.LabelOpts(is_show=False),
markpoint_opts=opts.MarkPointOpts(
data=[
opts.MarkPointItem(type_="max", name="最大值"),
opts.MarkPointItem(type_="min", name="最小值"),
opts.MarkPointItem(type_="average", name="平均值")]),
markline_opts=opts.MarkLineOpts(
data=[
opts.MarkLineItem(type_="average", name="平均值")]))
bar.render('年齡分布.html')
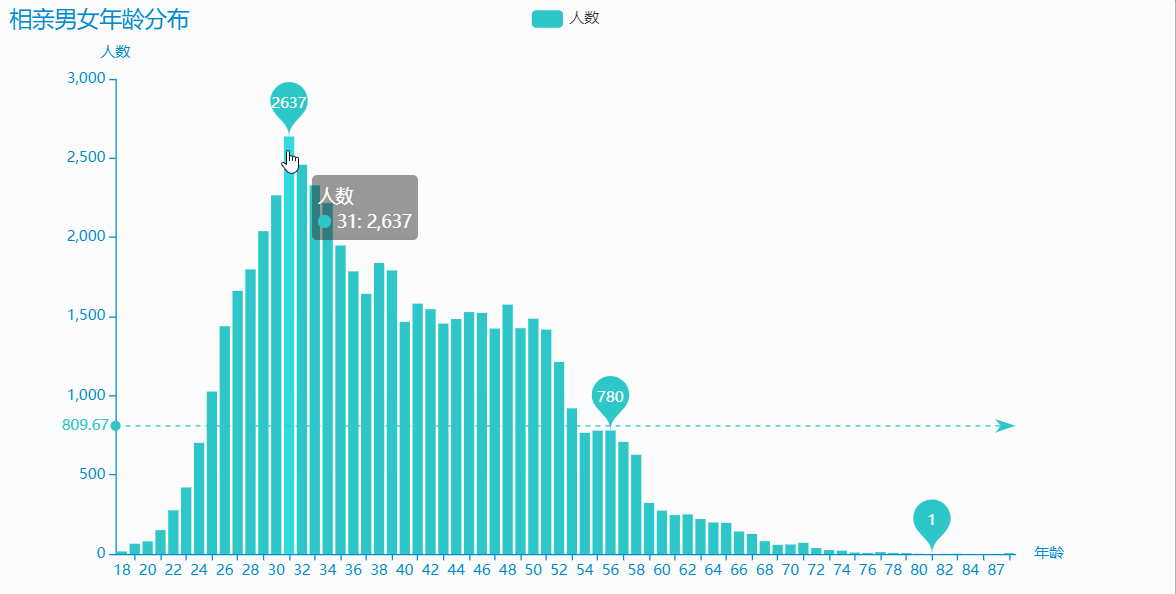
31歲的相親男女人數最多,有 2637 人,各個年齡段都有一定數量的人,我們將年齡小于等于 20 歲,大于等于 70 歲的相親男女資料單獨提取出來看看,
import pandas as pd
df = pd.read_excel('處理后資料.xlsx')
df1 = df[df['年齡'] <= 20]
df2 = df1['婚況'].value_counts() # 統計小于等于20歲的相親男女的婚況
print(df2)
結果如下:
未婚 153
離異 6
喪偶 2
Name: 婚況, dtype: int64
大部分是未婚,年紀輕輕就那么急著相親嗎?再看看婚況是離異、喪偶的資料,
import pandas as pd
df = pd.read_excel('處理后資料.xlsx')
df1 = df[df['年齡'] <= 20]
df3 = df1[df1['婚況'] == '離異']
print(df3)
結果如下:
網名 性別 ... 學歷 月薪
17425 微風輕起 男士 ... 未知 50000
29645 媳婦 女士 ... 大專 未知
30398 仙妹 女士 ... 高中 未知
30485 會員1415395937 男士 ... 未知 35000
36684 微笑著變老 女士 ... 高中 未知
49864 風吹動了風玲 女士 ... 高中 未知
[6 rows x 9 columns]
月薪寫著50000、35000的男士有些顯眼啊,取資料集中查看,
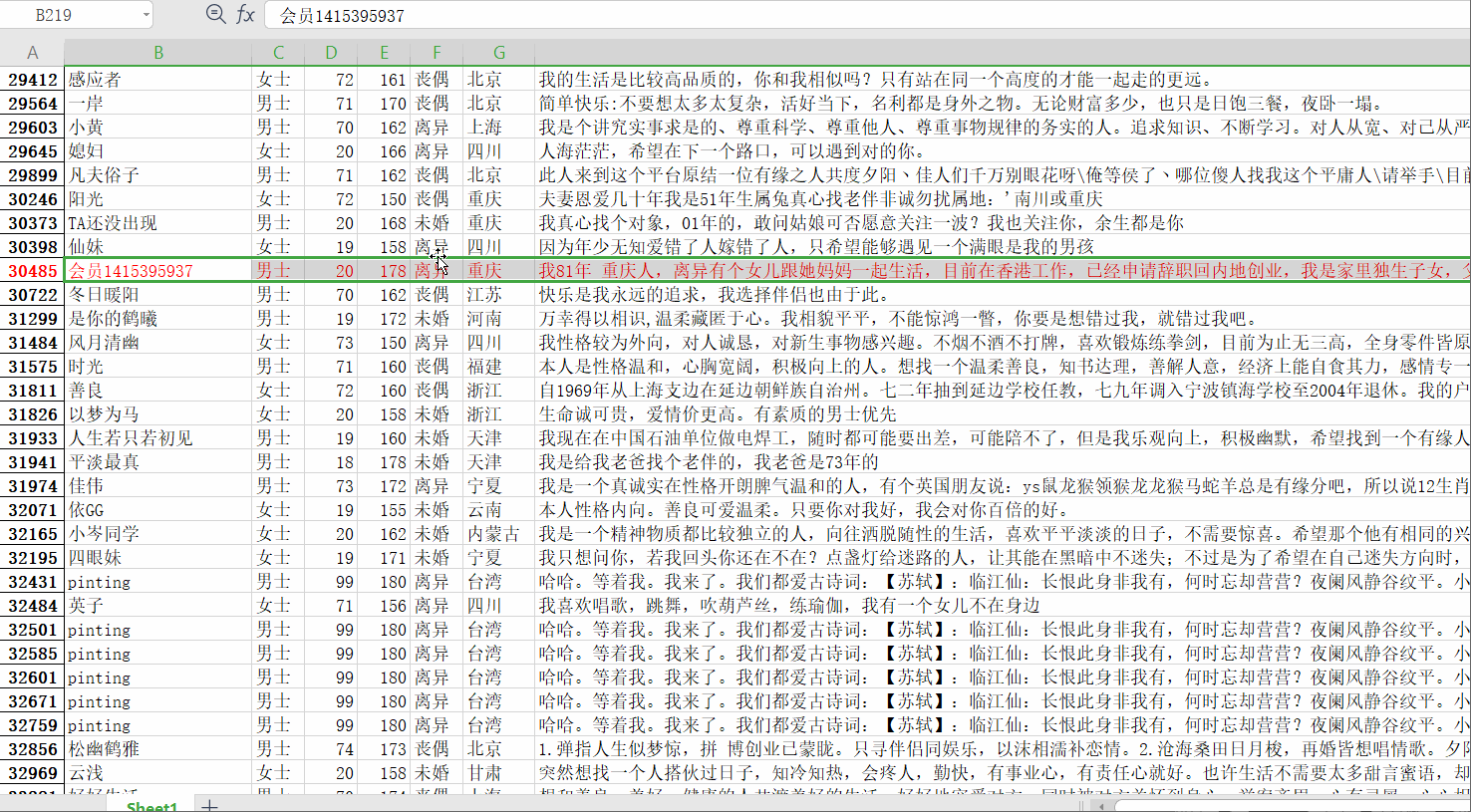
月薪 50000 的微風輕起,征婚資訊年齡寫的19,征婚宣言里又寫到 1994 年 26 歲;月薪 35000 的會員某某某,征婚資訊年齡寫的20,征婚宣言里又寫到 81 年的,看來網站里年齡、身高這些資訊真實性值得懷疑,
相親男女婚況?
# -*- coding: UTF-8 -*-
"""
@File :男女占比情況.py
@Author :葉庭云
@CSDN :https://yetingyun.blog.csdn.net/
"""
import pandas as pd
import collections
from pyecharts.charts import Pie
from pyecharts import options as opts
from pyecharts.globals import ThemeType, CurrentConfig
# 參考本地js資源渲染
CurrentConfig.ONLINE_HOST = 'D:/python/pyecharts-assets-master/assets/'
# 提取資料 婚況不為未填寫的
df = pd.read_excel('處理后資料.xlsx')
data = df[df['婚況'] != '未填寫']
# 統計各婚況相親男女人數
data_count = collections.Counter(data['婚況']).most_common()
print(data)
c = (
Pie()
.add(
"婚況",
data_count,
radius=["40%", "55%"],
label_opts=opts.LabelOpts(
position="outside",
formatter="{a|{a}}{abg|}\n{hr|}\n {b|{b}: }{c} {per|{d}%} ",
background_color="#eee",
border_color="#aaa",
border_width=1,
border_radius=4,
rich={
"a": {"color": "#999", "lineHeight": 22, "align": "center"},
"abg": {
"backgroundColor": "#e3e3e3",
"width": "100%",
"align": "right",
"height": 22,
"borderRadius": [4, 4, 0, 0],
},
"hr": {
"borderColor": "#aaa",
"width": "100%",
"borderWidth": 0.5,
"height": 0,
},
"b": {"fontSize": 16, "lineHeight": 33},
"per": {
"color": "#eee",
"backgroundColor": "#334455",
"padding": [2, 4],
"borderRadius": 2,
},
},
),
)
.set_colors(["#8B008B", "#FF1493", "#000000"])
.set_global_opts(title_opts=opts.TitleOpts(title="相親男女婚況"))
.render("pie_rich_label.html")
)
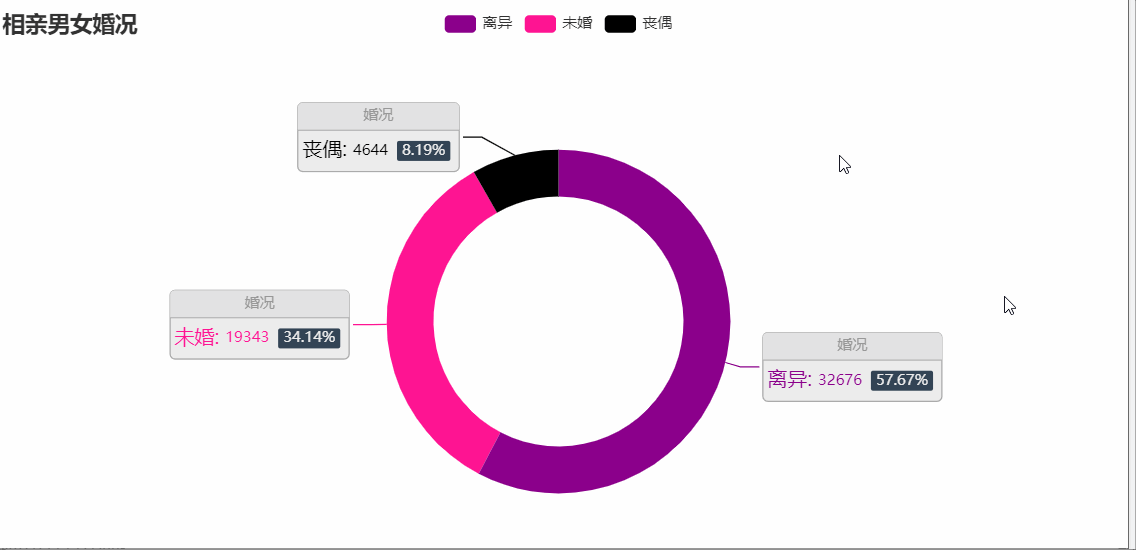
相親男女婚況,離異的占比57.67%,未婚占比34.14%,喪偶占比8.19%,
相親男女學歷分布情況?
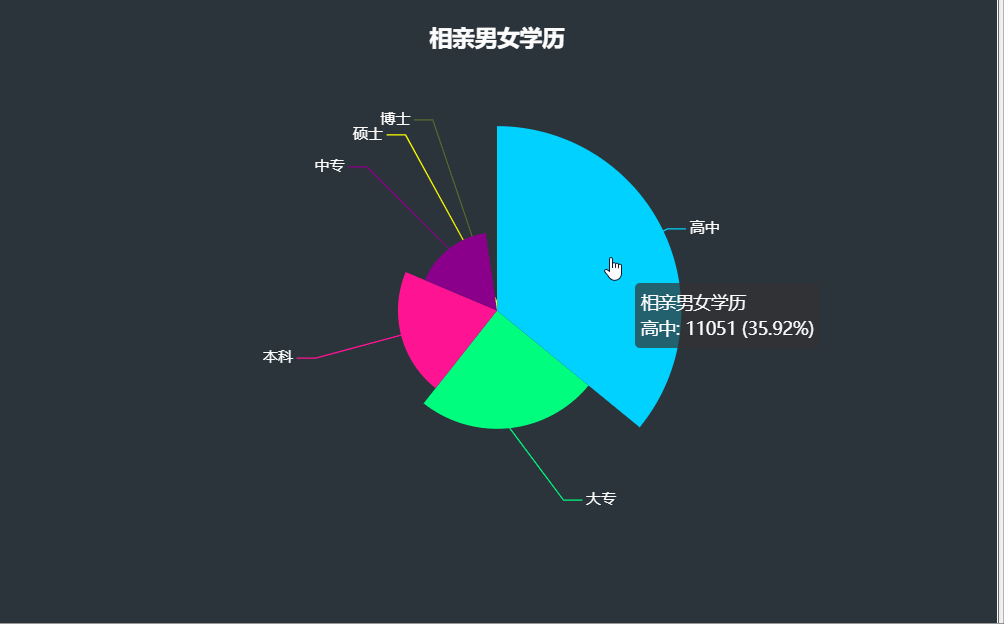
相親男女學歷大部分在高中(35.92%)、大專(24.72%),有近六成的相親男女,本科占比20.7%,中專占比16.35%,碩士、博士高學歷的相親男女人數較少,分別占比2.14%,0.17%,
相親男女地區分布?
# -*- coding: UTF-8 -*-
"""
@File :地區分布.py
@Author :葉庭云
@CSDN :https://yetingyun.blog.csdn.net/
"""
import pandas as pd
import collections
from pyecharts import options as opts
from pyecharts.charts import Geo
from pyecharts.globals import ChartType
from pyecharts.globals import ThemeType, CurrentConfig
CurrentConfig.ONLINE_HOST = 'D:/python/pyecharts-assets-master/assets/'
df = pd.read_excel('處理后資料.xlsx')
area = list(df['居住地'])
area_count = collections.Counter(area).most_common(34)
print(area_count)
# 初始化配置項 背景顏色 大小 主題
geo = Geo(init_opts=opts.InitOpts(width='1000px', height='600px', theme=ThemeType.DARK))
# 設定是否顯示省份
geo.add_schema(maptype='china', label_opts=opts.LabelOpts(is_show=True))
# 繪制什么型別圖 熱力圖 漣漪圖等
geo.add('相親男女人數', data_pair=area_count, type_=ChartType.EFFECT_SCATTER)
geo.set_series_opts(label_opts=opts.LabelOpts(is_show=False)) # 不顯示資料標簽
geo.set_global_opts(title_opts=opts.TitleOpts(title="相親男女地區分布"),
visualmap_opts=opts.VisualMapOpts(max_=5000, is_piecewise=True, # 劃磁區間是否精確
pieces=[{"max": 1000, "min": 100, "label": "100-1000", "color": "#708090"}, # 分段 添加圖例注釋 和顏色
{"max": 1500, "min": 1001, "label": "1001-1500", "color": "#00008B"},
{"max": 2000, "min": 1501, "label": "1501-2000", "color": "#483D8B"},
{"max": 2500, "min": 2001, "label": "2001-2500", "color": "#1E90FF"},
{"max": 3000, "min": 2501, "label": "2501-3000", "color": "#8B008B"},
{"max": 5000, "min": 3001, "label": ">=3000", "color": "#FF0000"}])
)
geo.render('地區分布.html')
結果如下:
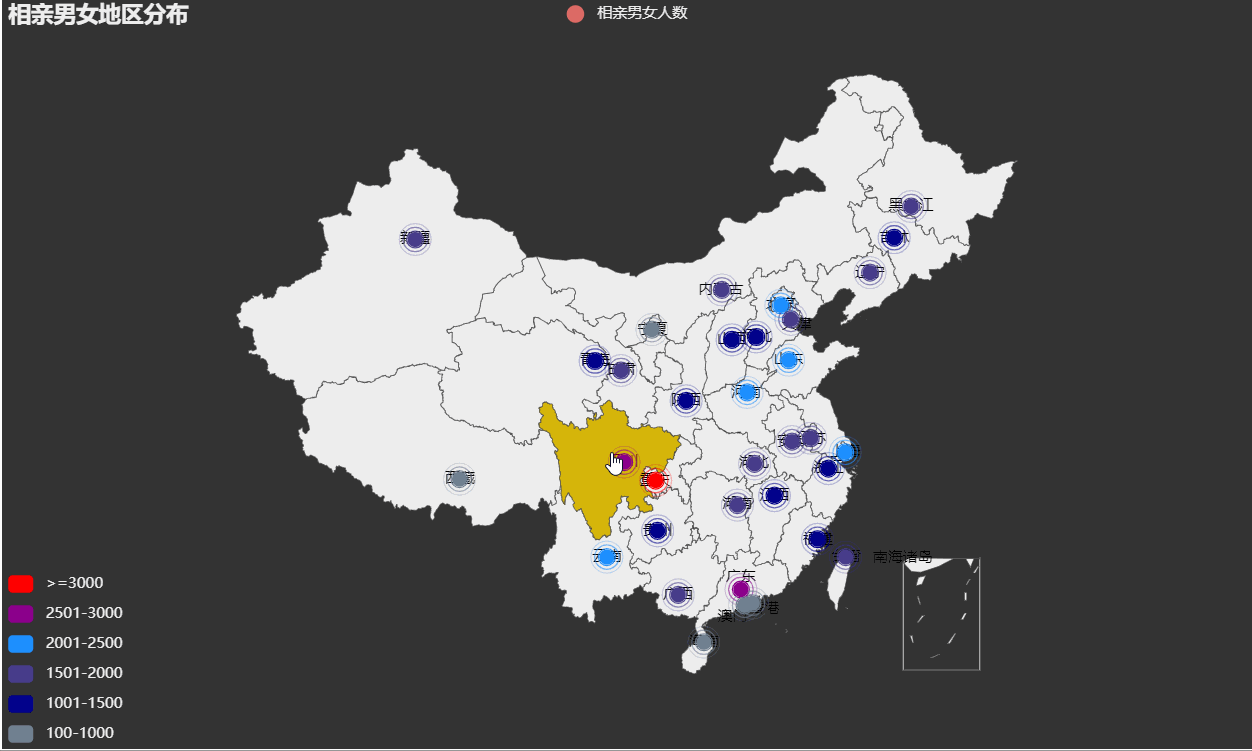
[('重慶', 4436), ('廣東', 2637), ('四川', 2519), ('山東', 2398), ('河南', 2160), ('上海', 2156), ('云南', 2039), ('北京', 2037), ('臺灣', 1997), ('安徽', 1920), ('江蘇', 1919), ('天津', 1918), ('黑龍江', 1918), ('湖南', 1800), ('新疆', 1799), ('遼寧', 1680), ('甘肅', 1680), ('廣西', 1679), ('湖北', 1679), ('內蒙古', 1559), ('山西', 1440), ('福建', 1440), ('江西', 1440), ('浙江', 1440), ('陜西', 1439), ('河北', 1439), ('青海', 1339), ('貴州', 1200), ('吉林', 1080), ('西藏', 942), ('寧夏', 702), ('海南', 360), ('香港', 353), ('澳門', 117)]
征婚宣言一般是介紹自己情況,表達對另一半的要求和期望,下面我們分別來看看相親男女征婚宣言里關鍵詞都有些什么,
# -*- coding: UTF-8 -*-
"""
@File :征婚宣言詞云.py
@Author :葉庭云
@CSDN :https://yetingyun.blog.csdn.net/
"""
import pandas as pd
import jieba
import collections
import re
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
# 提取性別 征婚宣言這兩列資料就好
df = pd.read_excel('處理后資料.xlsx')[['性別', '征婚宣言']]
# df1 = df[df['性別'] == '女士']['征婚宣言']
df2 = df[df['性別'] == '女士']['征婚宣言']
# 讀取停用詞資料
with open('stop_words.txt', encoding='utf-8') as f:
con = f.read().split('\n') # 得到每一行的停用詞
stop_words = set()
for i in con:
stop_words.add(i)
result_list = []
for data in df2:
# 文本預處理 去除一些無用的字符 只提取出中文出來
new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)
new_data = "/".join(new_data)
# 文本分詞
seg_list_exact = jieba.cut(new_data, cut_all=True)
# 去除停用詞和單個詞
for word in seg_list_exact:
if word not in stop_words and len(word) > 1:
result_list.append(word)
print(result_list)
# 篩選后統計
word_counts = collections.Counter(result_list)
mask_ = 255 - np.array(Image.open('woman_mask.png'))
# 繪制詞云
my_cloud = WordCloud(
background_color='white', # 設定背景顏色 默認是black
mask=mask_,
font_path='simhei.ttf', # 設定字體 顯示中文
max_font_size=112, # 設定字體最大值
min_font_size=12, # 設定字體最小值
random_state=88 # 設定隨機生成狀態,即多少種配色方案
).generate_from_frequencies(word_counts)
# 繪制詞云
plt.figure(figsize=(8, 5), dpi=200)
# 顯示生成的詞云圖片
plt.imshow(my_cloud, interpolation='bilinear')
# 顯示設定詞云圖中無坐標軸
plt.axis('off')
plt.savefig('woman_cloud.png', dpi=200)
plt.show()
結果如下:


相親男女征婚宣言里,喜歡、希望、生活、善良、真誠、真心、幸福、性格都是出現頻率高的詞語,

作者:葉庭云
公眾號:微信搜一搜【修煉Python】 分享Python爬蟲、資料分析、資料可視化、機器學習有關知識和實體;也分享實用的資料教程、軟體工具、學習檔案和簡歷模板,發現求知的樂趣,在不斷總結和學習中進步,堅持輸出優質文章,期待你的關注,一起交流學習,互相成就,
本文僅用于交流學習,未經作者允許,禁止轉載,更勿做其他用途,違者必究,
發現求知的樂趣,在不斷總結和學習中進步,與諸君共勉,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/258189.html
標籤:python