前情提要
In [ ]
number = 0.5
age = 18
name = 'Molly'
beautiful = True
list1 = [1,'2', True]
tuple1 = (1,'2', True)
dict1 = {'name':'Molly', 'age':18, 'gender':'female'}
set1 = {1,2,3,4,5,5,5}In [ ]
my_number = 3200 # 這是真實的價格
guess_number = input('這臺冰箱多少錢?')
guess_number = int(guess_number)
while True:
if guess_number<my_number:
guess_number = input('猜低了!再猜')
guess_number = int(guess_number)
elif guess_number>my_number:
guess_number = input('猜高了!再猜')
guess_number = int(guess_number)
else:
break
print('\n恭喜您,猜對了!\n')In [ ]
# continue : 跳過本輪
# 列印1-10中的偶數
for i in range(10):
num = i+1
if num%2 != 0:
# 跳過奇數
continue
print(num)
字串進階
字串索引、切片
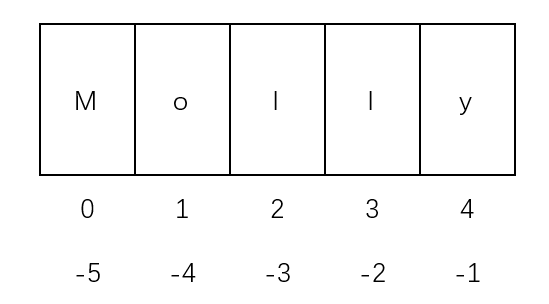
切片的語法:[起始:結束:步長] 字串[start: end: step] 這三個引數都有默認值,默認截取方向是從左往右的 start:默認值為0; end : 默認值未字串結尾元素; step : 默認值為1;
如果切片步長是負值,截取方向則是從右往左的
In [ ]
name = 'molly'
name[1]
name[-4]
name[1:4]
name[::-1]In [ ]
# 小練習
string = 'Hello world!'
string[2]
string[2:5]
string[3:]
string[8:2:-1]In [ ]
for s in string:
print(s)In [ ]
# 如果字串以'p'結尾,則列印
list_string = ['apple','banana_p','orange','cherry_p']
for fruit in list_string:
if fruit[-1] == 'p':
print(fruit)In [ ]
# 如果字串以'pr'結尾,則列印
list_string = ['apple','banana_pr','orange','cherry_pr']
for fruit in list_string:
if fruit.endswith('pr'):
print(fruit)字串常用函式
記不住 找百度 help()
count 計數功能
顯示自定字符在字串當中的個數
In [ ]
my_string = 'hello_world'
my_string.count('o')In [ ]
article = 'Disney and Marvel’s upcoming superhero epic should light the box office on fire when it launches this weekend, with the hopes of setting domestic, international, and global records. In North America alone, “Avengers: Endgame” is expected to earn between $250 million and $268 million in its first three days of release. If it hits the higher part of that range it would qualify as the biggest domestic debut of all time, a distinction currently held by 2018’s “Avengers: Infinity War,” the precursor to “Endgame,” which launched with $257.7 million.'
article.count('and')In [ ]
help(my_string.count)In [ ]
my_string = 'aabcabca'
my_string.count('abca')find 查找功能
回傳從左第一個指定字符的索引,找不到回傳-1
index 查找
回傳從左第一個指定字符的索引,找不到報錯
In [ ]
my_string = 'hello_world'
my_string.find('o')In [ ]
my_string = 'hello_world'
my_string.index('o')In [ ]
my_string = 'hello_world'
my_string.find('a')In [ ]
my_string = 'hello_world'
my_string.index('a')In [ ]
article = 'Disney and Marvel’s upcoming superhero epic should light the box office on fire when it launches this weekend, with the hopes of setting domestic, international, and global records. In North America alone, “Avengers: Endgame” is expected to earn between $250 million and $268 million in its first three days of release. If it hits the higher part of that range it would qualify as the biggest domestic debut of all time, a distinction currently held by 2018’s “Avengers: Infinity War,” the precursor to “Endgame,” which launched with $257.7 million.'
article.find('and')In [ ]
'and' in article
In [ ]
my_string = 'hello_world'
my_string.startswith('hello') # 是否以hello開始
my_string.endswith('world') # 是否以world結尾split 字串的拆分
按照指定的內容進行分割
In [ ]
my_string = 'hello_world'
my_string.split('_')In [ ]
article = 'Disney and Marvel’s upcoming superhero epic should light the box office on fire when it launches this weekend, with the hopes of setting domestic, international, and global records. In North America alone, “Avengers: Endgame” is expected to earn between $250 million and $268 million in its first three days of release. If it hits the higher part of that range it would qualify as the biggest domestic debut of all time, a distinction currently held by 2018’s “Avengers: Infinity War,” the precursor to “Endgame,” which launched with $257.7 million.'
article.split(' ')字串的替換
從左到右替換指定的元素,可以指定替換的個數,默認全部替換
In [ ]
my_string = 'hello_world'
my_string.replace('_',' ')I wish to wish the wish you wish to wish,
but if you wish the wish the witch wishes,
I won't wish the wish you wish to wish.
In [ ]
my_string = "I wish to wish the wish you wish to wish, but if you wish the wish the witch wishes, I won't wish the wish you wish to wish."In [ ]
my_string.replace('wish','wish'.upper(), 3)字串標準化
默認去除兩邊的空格、換行符之類的,去除內容可以指定
In [ ]
my_string = ' hello world\n'
my_string.strip()字串的變形
In [ ]
my_string = 'hello_world'
my_string.upper()
my_string.lower()
my_string.capitalize()字串的格式化輸出
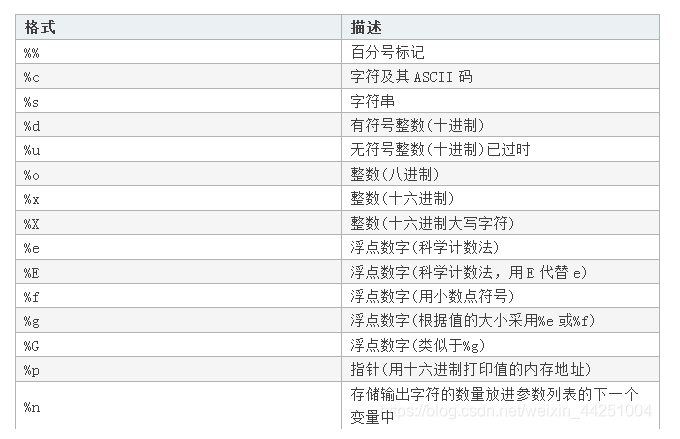
%
重點內容!
In [ ]
accuracy = 80/123
print('老板!我的模型正確率是', accuracy,'!')In [ ]
accuracy = 80/123
print('老板!我的模型正確率是%s!' % accuracy)In [ ]
accuracy = 80/123
print('老板!我的模型正確率是%.2f!' % accuracy)In [ ]
name = 'Molly'
hight = 170.4
score_math = 95
score_english = 89
print('大家好!我叫%s,我的身高是%d cm, 數學成績%.2f分,英語成績%d分' % (name, hight, score_math, score_english))format
In [ ]
"""
指定了 :s ,則只能傳字串值,如果傳其他型別值不會自動轉換
當你不指定型別時,你傳任何型別都能成功,如無特殊必要,可以不用指定型別
"""
print('大家好!我叫{},我的身高是{:d} cm, 數學成績{:.2f}分,英語成績{}分'.format(name, int(hight), score_math, score_english))In [ ]
'Hello, {0}, 成績提升了{1:.1f}分,百分比為 {2:.1f}%'\
.format('小明', 6, 17.523)In [ ]
'Hello, {name:}, 成績提升了{score:.1f}分,百分比為 {percent:.1f}%'\
.format(name='小明',
score=6,
percent = 17.523)一種可讀性更好的方法 f-string
** python3.6版本新加入的形式
In [ ]
name = 'Molly'
hight = 170.4
score_math = 95
score_english = 89
print(f"大家好!我叫{name},我的身高是{hight:.3f} cm, 數學成績{score_math}分,英語成績{score_english}分")
list進階
list索引、切片
In [ ]
list1 = ['a','b','c','d','e','f']
list1[2]
list1[2:5]list常用函式
添加新的元素
In [ ]
list1 = ['a','b','c','d','e','f']
list1.append('g') # 在末尾添加元素
print(list1)
list1.insert(2, 'ooo') # 在指定位置添加元素,如果指定的下標不存在,那么就是在末尾添加
print(list1)In [ ]
list2 = ['z','y','x']
list1.extend(list2) #合并兩個list list2中仍有元素
print(list1)
print(list2)count 計數 和 index查找
In [ ]
list1 = ['a','b','a','d','a','f']
print(list1.count('a')) In [ ]
list1 = ['a','b','a','d','a','f']
print(list1.index('a')) In [ ]
print('a' in list1)洗掉元素
In [ ]
list1 = ['a','b','a','d','a','f']
print(list1.pop(3))
print(list1)
list1.remove('a')
print(list1)串列生成式
Question1: 串列每一項+1
In [ ]
# 有點土但是有效的方法
list_1 = [1,2,3,4,5]
for i in range(len(list_1)):
list_1[i] += 1
list_1 In [ ]
# pythonic的方法 完全等效但是非常簡潔
[n+1 for n in list_1]In [ ]
# 1-10之間所有數的平方
[(n+1)**2 for n in range(10)]In [ ]
# 1-10之間所有數的平方 構成的字串串列
[str((n+1)**2) for n in range(10)]In [ ]
list1 = ['a','b','a','d','a','f']
['app_%s'%n for n in range(10)]In [ ]
list1 = ['a','b','a','d','a','f']
[f'app_{n}' for n in range(10)]Question2: 串列中的每一個偶數項[過濾]
In [ ]
# 有點土但是有效的方法
list_1 = [1,2,3,4,5]
list_2 = []
for i in range(len(list_1)):
if list_1[i] % 2 ==0:
list_2.append(list_1[i])
list_2In [ ]
list_1 = [1,2,3,4,5]
[n for n in list_1 if n%2==0]In [ ]
[n+1 for n in list_1 if n%2==0]In [ ]
# 小練習:0-29之間的奇數
list_1 = range(30)In [ ]
# 字串中所有以'sv'結尾的
list_2 = ['a','b','c_sv','d','e_sv']
[s for s in list_2 if s.endswith('sv')]In [ ]
# 取兩個list的交集
list_A = [1,3,6,7,32,65,12]
list_B = [2,6,3,5,12]
[i for i in list_A if i in list_B]In [ ]
#小練習 在list_A 但是不在list_B中
list_A = [1,3,6,7,32,65,12]
list_B = [2,6,3,5,12]In [ ]
[m + n for m in 'ABC' for n in 'XYZ']
生成器
通過串列生成式,我們可以直接創建一個串列,但是,受到記憶體限制,串列容量肯定是有限的,而且,創建一個包含100萬個元素的串列,不僅占用很大的存盤空間,如果我們僅僅需要訪問前面幾個元素,那后面絕大多數元素占用的空間都白白浪費了,
In [ ]
# 第一種方法:類似串列生成式
L = [x * x for x in range(10)]
g = (x * x for x in range(10))In [ ]
next(g)In [ ]
g = (x * x for x in range(10))
for n in g:
print(n)In [ ]
# 第二種方法:基于函式
# 如何定義一個函式?
def reverse_print(string):
print(string[::-1])
return 'Successful!'In [ ]
ret = reverse_print('Molly')In [ ]
retIn [ ]
# 在IDE里面看得更清晰
def factor(max_num):
# 這是一個函式 用于輸出所有小于max_num的質數
factor_list = []
n = 2
while n<max_num:
find = False
for f in factor_list:
# 先看看串列里面有沒有能整除它的
if n % f == 0:
find = True
break
if not find:
factor_list.append(n)
yield n
n+=1
In [ ]
g = factor(10)In [ ]
next(g)In [ ]
g = factor(100)
for n in g:
print(n)In [ ]
# 練習 斐波那契數列
def feb(max_num):
n_1 = 1
n_2 = 1
n = 0
while n<max_num:
if n == 0 or n == 1:
yield 1
n += 1
else:
yield n_1 + n_2
new_n_2 = n_1
n_1 = n_1 + n_2
n_2 = new_n_2
n += 1
In [ ]
g = feb(20)
for n in g:
print(n)例外與錯誤處理

有的錯誤是程式撰寫有問題造成的,比如本來應該輸出整數結果輸出了字串,這種錯誤我們通常稱之為bug,bug是必須修復的,
有的錯誤是用戶輸入造成的,比如讓用戶輸入email地址,結果得到一個空字串,這種錯誤可以通過檢查用戶輸入來做相應的處理,
In [ ]
list1 = [1,2,3,4,'5',6,7,8]
n=1
for i in range(len(list1)):
print(list1[i])
list1[i]+=1
例外即是一個事件,該事件會在程式執行程序中發生,影響了程式的正常執行,
一般情況下,在 Python 無法正常處理程式時就會發生一個例外,
例外是 Python 物件,表示一個錯誤,
當 Python 腳本發生例外時我們需要捕獲處理它,否則程式會終止執行,
In [ ]
list1 = [1,2,3,4,'5',6,7,8]
n=1
for i in range(len(list1)):
if type(list1[i]) != int:
continue
print(list1[i])
list1[i]+=1
try:
<陳述句> #運行別的代碼
except <名字>:
<陳述句> #如果在try部份引發了'名字'例外
except <名字>,<資料>:
<陳述句> #如果引發了'名字'例外,獲得附加的資料
else:
<陳述句> #如果沒有例外發生
finally:
<陳述句> #有沒有例外都會執行
try 的作業原理是,當開始一個 try 陳述句后,Python 就在當前程式的背景關系中作標記,這樣當例外出現時就可以回到這里,try 子句先執行,接下來會發生什么依賴于執行時是否出現例外,
如果當 try 后的陳述句執行時發生例外,Python 就跳回到 try 并執行第一個匹配該例外的 except 子句,例外處理完畢,控制流就通過整個 try 陳述句(除非在處理例外時又引發新的例外),
如果在 try 后的陳述句里發生了例外,卻沒有匹配的 except 子句,例外將被遞交到上層的 try,或者到程式的最上層(這樣將結束程式,并列印預設的出錯資訊),
In [ ]
list1 = [1,2,3,4,'5',6,7,8]
n=1
for i in range(len(list1)):
try:
list1[i]+=1
print(list1[i])
except:
print('有例外發生')In [ ]
list1 = [1,2,3,4,'5',6,7,8]
n=1
for i in range(len(list1)):
try:
list1[i]+=1
print(list1[i])
except TypeError as e:
print(e)In [ ]
list1 = [1,2,3,4,'5',6,7,8]
n=1
for i in range(len(list1)):
try:
list1[i]+=1
print(list1[i])
except IOError as e:
print(e)
print('輸入輸出例外')
except:
print('有例外發生')In [ ]
list1 = [1,2,3,4,'5',6,7,8]
n=1
for i in range(len(list1)):
print(i)
try:
list1[i]+=1
print(list1)
except IOError as e:
print(e)
print('輸入輸出例外')
except:
print('有錯誤發生')
else:
print('正確執行')
finally:
print('我總是會被執行')In [ ]
list1 = [1,2,3,4,'5',6,7,8]
n=1
for i in range(len(list1)):
print('這是第%s次回圈' % i)
try:
list1[i]+=1
print(list1[i])
except IOError as e:
print(e)
print('輸入輸出例外')
finally: # 有無finally
# 在離開try塊之前,finally中的陳述句也會被執行,
print(f'一般用來做清理作業 這是我第{i}次清理')錯誤的層層傳遞
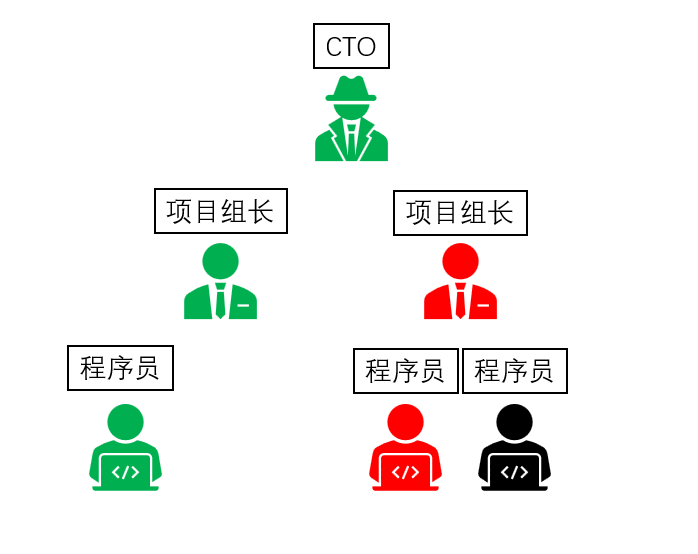
In [ ]
# 例外的層層處理
def worker(s):
# 這是一個函式 后面我們會詳細介紹函式的定義和使用
return 10 / int(s)
def group_leader(s):
return worker(s) * 2
def CTO(s):
return group_leader(s)
CTO('0')In [ ]
# 例外的層層處理
def worker(s):
# 這是一個函式 后面我們會詳細介紹函式如何定義的
try:
rst = 10 / int(s)
except ZeroDivisionError as e:
print(e)
rst = 10 / (float(s)+0.00001)
return rst
def group_leader(s):
return worker(s) * 2
def CTO(s):
return group_leader(s)
CTO('0')In [ ]
CTO('user')In [ ]
# 例外的層層處理
def worker(s):
# 這是一個函式 后面我們會詳細介紹函式如何定義的
try:
rst = 10 / int(s)
except ZeroDivisionError as e:
print(e)
rst = 10 / (float(s)+0.00001)
return rst
def group_leader(s):
try:
rst = worker(s) * 2
except ValueError as e:
print(e)
rst = '請修改輸入'
return rst
def CTO(s):
return group_leader(s)
CTO('user')assert陳述句的使用
In [ ]
assert 1==2In [ ]
assert 1==1In [ ]
# 檢查用戶的輸入
def worker(s):
assert type(s)== int
assert s!=0
rst = 10 / int(s)
return rst
def group_leader(s):
try:
rst = worker(s) * 2
except AssertionError as e:
print('資料型別錯誤')
rst = -1
return rst
def CTO(s):
return group_leader(s)
CTO('user')BUG的除錯和記錄
print大法
In [ ]
list1 = [1,2,3,4,'5',6,7,8]
n=1
for i in range(len(list1)):
print('這是第%s次回圈' % i)
list1[i]+=1
print(list1[i])logging
In [ ]
In [ ]
import logging
logger = logging.getLogger()
formatter = logging.Formatter('%(asctime)s - %(levelname)s - %(message)s')
# Configure stream handler for the cells
chandler = logging.StreamHandler()
chandler.setLevel(logging.INFO)
chandler.setFormatter(formatter)
logger.addHandler(chandler)
logger.setLevel(logging.INFO)
In [ ]
list1 = [1,2,3,4,'5',6,7,8]
for i in range(len(list1)):
logging.info('這是第%s次回圈' % i)
list1[i]+=1
print(list1[i])IDE
小練習 串列
已知一個串列lst = [1,2,3,4,5]
- 求串列的長度
- 判斷6 是否在串列中
- 串列里元素的最大值是多少
- 串列里元素的最小值是多少
- 串列里所有元素的和是多少
- 在數字1的后面新增一個的元素10
- 在串列的末尾新增一個元素20
In [ ]
lst = [1,2,3,4,5]小練習 串列生成式
In [ ]
# 要求你生成一個串列,串列里有10個元素,索引為奇數的元素值為1,索引為偶數的位置值為0,In [ ]
# [m + n for m in 'ABC' for n in 'XYZ']
# 已知lst1=[1,2,3,4,5,6],lst2=[2,4,6]
# 求兩兩相等時,lst1項*lst2項
# [4,16,36]
lst1=[1,2,3,4,5,6]
lst2=[2,4,6]In [ ]
def f(n):
return n*n+2*nIn [ ]
# 把f(n)應用在 lst1=[1,2,3,4,5,6] 中的每一項參考資料:百度飛槳領航團零基礎Python
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/259131.html
標籤:python
上一篇:基于資料庫的代碼自動生成工具,生成JavaBean、生成資料庫檔案、生成前后端代碼等(TableGo v7.0.0版)