文章目錄
- 資料歸一化、標準化、正則化
- 1、歸一化
- 2、標準化
- 3、正則化
- 4、代碼測驗
- 4.1 導庫
- 4.2 創建資料
- 4.3 查看原始資料的均值、方差
- 4.4 歸一化
- 4.5 標準化
- 4.6 正則化
資料歸一化、標準化、正則化
1、歸一化
是將資料放縮到0~1區間,利用公式(x-min)/(max-min)
2、標準化
將資料轉化為標準的正態分布,均值為0,方差為1
3、正則化
正則化的主要作用是防止過擬合,對模型添加正則化項可以限制模型的復雜度,使得模型在復雜度和性能達到平衡,
常用的正則化方法有L1正則化和L2正則化,L1正則化和L2正則化可以看作是損失函式的懲罰項,所謂“懲罰”就是對損失函式中的某些引數做一些限制,
4、代碼測驗
4.1 導庫
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import Normalizer
4.2 創建資料
x=np.random.randint(1,1000,(10000,5))
x=pd.DataFrame(x)
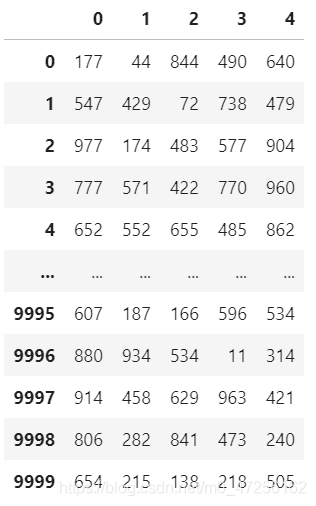
4.3 查看原始資料的均值、方差
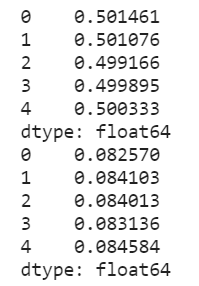
display(x.mean())
display(x.var())

4.4 歸一化
from sklearn.preprocessing import MinMaxScaler
x_min=MinMaxScaler().fit_transform(x)
x_min=pd.DataFrame(x_min)
display(x_min.mean())
display(x_min.var())
4.5 標準化
from sklearn.preprocessing import StandardScaler
x_std=StandardScaler().fit_transform(x)
x_std=pd.DataFrame(x_std)
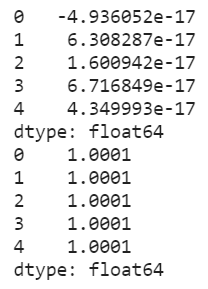
display(x_std.mean())
display(x_std.var())
4.6 正則化
from sklearn.preprocessing import Normalizer
x_nor=Normalizer().fit_transform(x)
x_nor=pd.DataFrame(x_nor)

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/259239.html
標籤:python
上一篇:Python程式打包成.exe檔案(彈窗惡搞小程式附原始碼)
下一篇:Python資料分析學習筆記#1