寫在前面
這篇博客是我在澤哥的鼓勵下,對本學期在西北農林科技大學園藝學院304的試驗內容的一個總結,同時我也覺得在液質、氣質等一些由儀器標準化輸出報告的試驗中,非常適合引入程式腳本去處理試驗結果,這樣的話,能夠大大減少試驗員的時間,讓他們有更多的時間去投入到價值更高的作業中去,
對樣品編號程序的優化
問題背景:
在樣品編號時,由于軟體提供的自增工具(Autoincrement),只能適用于數字或著最后一位為數字的情況,但是在試驗里,樣品命名中至少都會包含兩個以上的變數,而且在命名是如果僅僅使用數字時,對于不同樣品的區分也不夠直觀,
解決方法:
通常串列的分割符號是“\n”,因此只需要使用在將樣品命名提前命名好,然后樣品名字用“\n”拼接,即可直接復制到excel、analyst和multiquant等軟體,大大節約了在操作軟體是樣品名稱不直觀和樣品名稱輸入時間太長的問題,
python代碼實作:
#trial_name.py
import pyperclip
from itertools import product
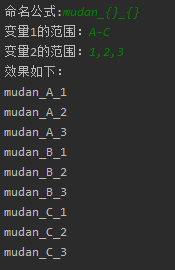
name_formula = input("名稱公式:")
#統計變數的個數
var_num = name_formula.count("{}")
#把{}替換為%s,以串列和元組的形式填充字串
name_formula = name_formula.replace('{}', '%s')
factors = []
for i in range(0, var_num):
factor = input("變數{}的范圍:".format(i+1))
if "-" in factor:
li = [chr(i) for i in range(ord(factor[0]), ord(factor[-1])+1)]
factors.append(li)
elif ',' in factor:
li = factor.split(',')
factors.append(li)
text =""
#排列組合
for i in product(*factors):
#結果拼接
text = text + name_formula%i +"\n"
#將結果寫入剪貼板
pyperclip.copy(text)
示例:
上述程式使用要點:
- 每一個{}代表一個變數,{}可以出現在公式的任何位置;
- 變數范圍輸入有兩種,①用”-“連接,通過ASCII自增的方式創建變數串列,意味著可以用字母,阿拉伯數字,羅馬數字等,只要ASCII相近的字符都可以使用;②用”,“分隔,該方法必須窮舉出該變數所有的值,這種方法繁瑣,但具有普適性,
液相質譜儀docx報告的資料提取
問題背景:
此處定位西北農林科技大學園藝學院304液相質譜儀,樣品的譜圖經過multiquant軟體確定峰面積之后,可以匯出docx的報告檔案,通常我們從這個報告檔案通過復制黏貼的方式將資料篩選出來,效率低下,并且報告檔案中含有大量圖片,導致檔案篇幅很長,目標資料分散,
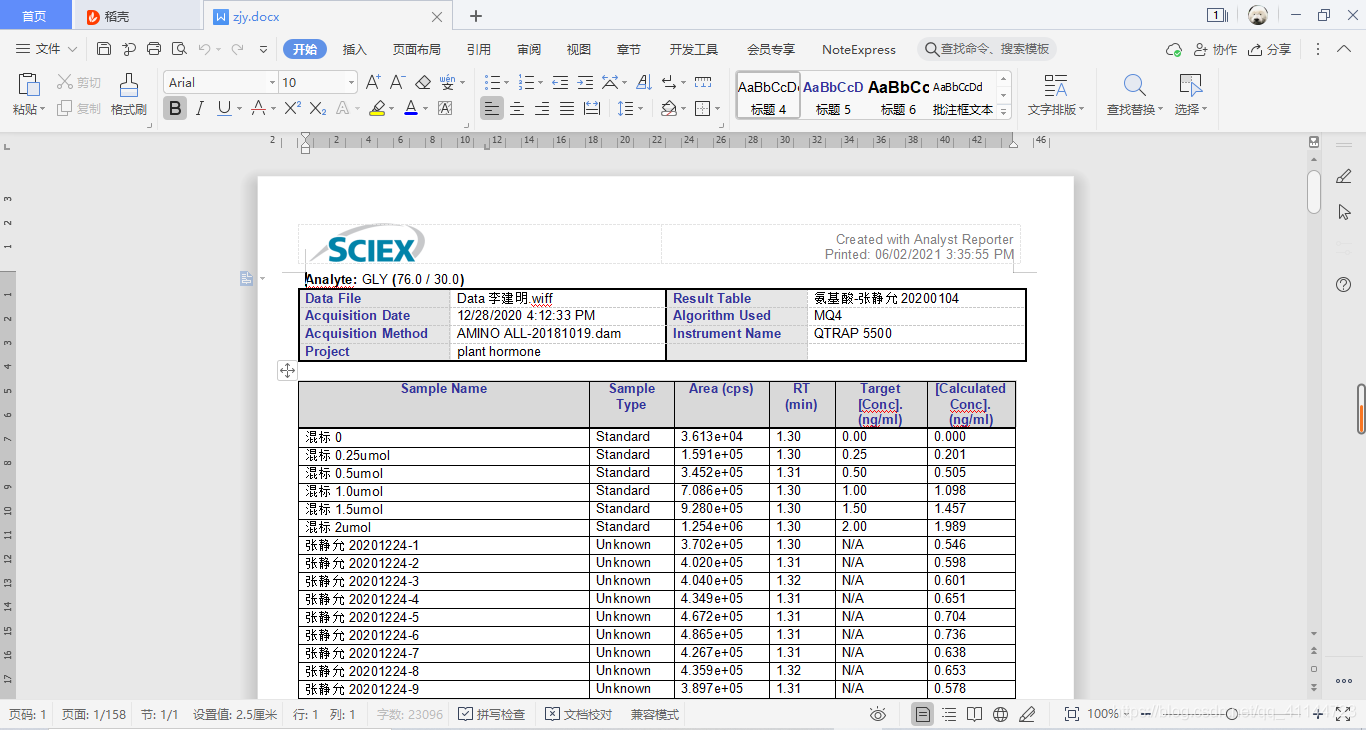
如上圖,這是一個含有102個樣品的液相質譜報告,報告篇幅達到了158頁,由此可見,使用復制黏貼的方式篩選資料無疑是復雜耗時并且效率低下的,
解決方法:
python有一個第三庫docx庫能夠準確的決議docx檔案,因此可以用腳本實作資料的篩選,獲取檔案中的文本后,用正則篩選出檢測物質的名稱,然后獲取檔案中的表格篩選出資料,具體方法如下,
r
import argparse
import os
from docx import Document
import re
import pandas as pd
import sys
#設定外部引數,默認獲取表格第六列,默認檔案輸出路徑為桌面
parser = argparse.ArgumentParser(description='液相質譜儀docx報告處理.')
parser.add_argument('-i', dest='infile', help='docx報告的檔案路徑 ',required=True)
parser.add_argument('-o', dest='outfile', help='輸出資料檔案名 ', required=True)
parser.add_argument('-c', '--column', type=int, choices=[1, 2, 3, 4, 5], help="select the column you want to deal with", default=5)
parser.add_argument('-v', '--path', help="輸出檔案存放目錄", default='C:\\Users\\biashap\\Desktop\\')
args = parser.parse_args()
#判斷輸入和輸出檔案的型別
if args.infile[-5:] != ".docx" or args.outfile[-4:] != ".csv":
print("請用-h引數查看,腳本外部引數要求!")
sys.exit()
#判斷路徑是否存在
if not os.path.exists(args.path):
print("{}, 這個目錄不存在!".format(args.path))
sys.exit()
#開始決議檔案
document = Document(args.infile)
#從每個段落里獲取檢測物質的名字
paras = document.paragraphs
subjects = []
for para in paras:
if para.text.strip(' \n') != '':
temp = re.search("Analyte: (.*?)\(",para.text)
subjects.append(temp.group(1))
else:
continue
#獲取檔案中的表格
tables = document.tables
# 獲取所有樣品的名稱
trials = []
for row in tables[1].rows[1:]:
trials.append(row.cells[0].text)
#篩選出目標資料
result = []
for table in tables[1::len(trials)+2]:
temp = []
for row in table.rows[1:]:
#args.column即為要獲取的表格的列
temp.append(row.cells[args.column].text)
result.append(temp)
#將資料構成字典,存入pandas資料框
mydic = dict()
mydic['trials'] = trials
if len(subjects) == len(result):
for i in range(len(subjects)):
mydic[subjects[i]] = result[i]
df = pd.DataFrame(mydic)
#輸出資料檔案,args.path和args.file拼接輸出路徑
df.to_csv(args.path+args.outfile, sep=',', index=False)
#資料輸出成功信號
print('ok')
else:
#檢測數目和篩選出的資料數目不一致,程式執行失敗信號,并輸出檢測物質的數目和篩選結果的數目
print("錯誤長度不匹配我!", len(subjects), len(result))
運行示例:
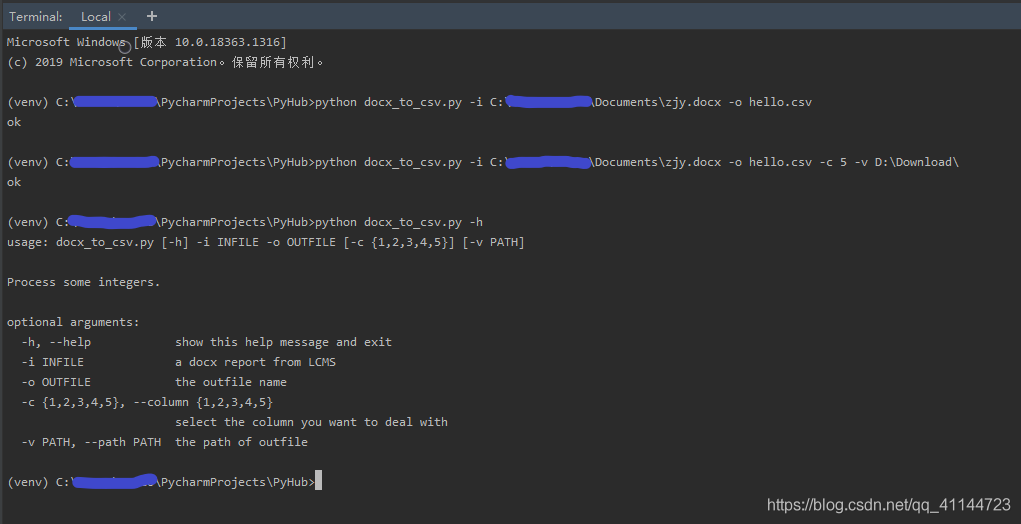
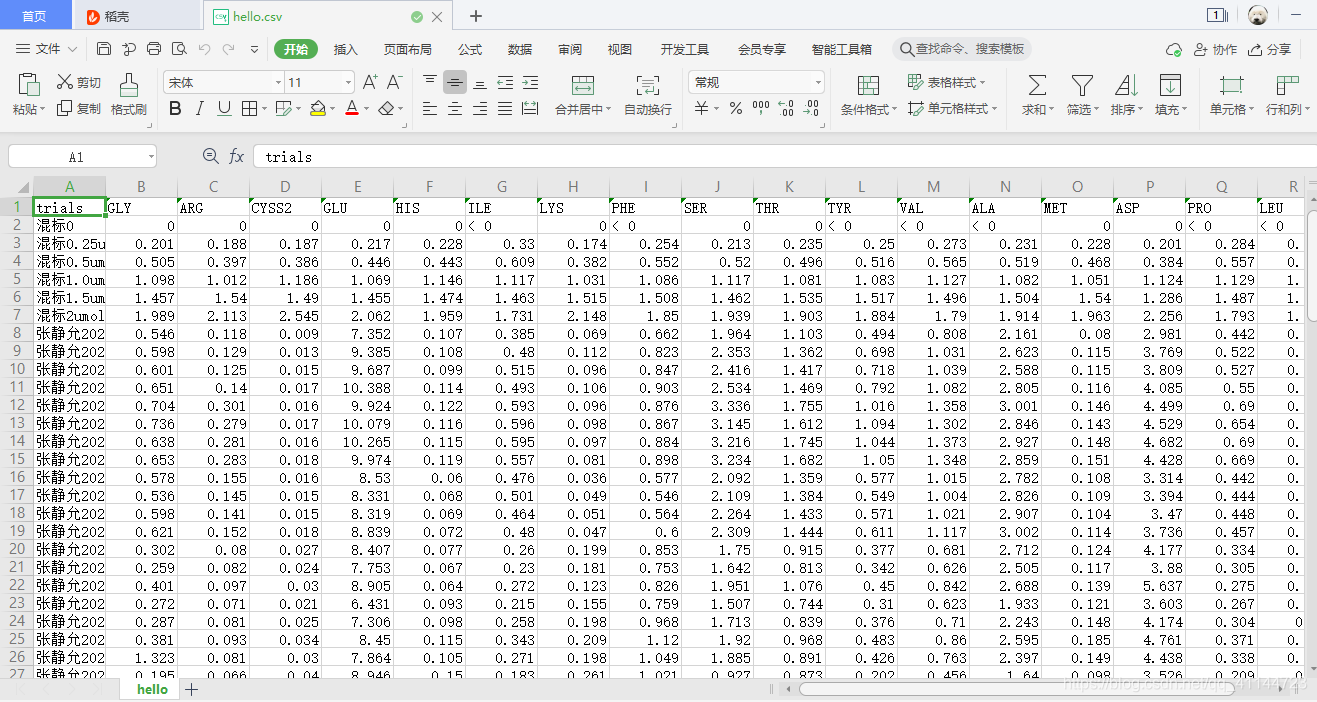
-c和-v都是可選引數,可以通過-h查看各引數的要求,資料整理后的csv檔案效果如下圖:
氣相色譜儀pdf報告的資料提取
問題背景:
此處定位西北農林科技大學園藝學院304氣相色譜儀,進行氣相色譜試驗時,經過軟體openLAB的處理,每一個樣品的色譜報告會單獨寫在一個pdf檔案中,檔案中包含這個樣品每個被檢測物質的濃度保留時間等資訊,雖然該軟體也能保存為txt格式,但是操作較為繁瑣,由于資料分散在各個檔案中,進行聚合整理時,只能單個復制黏貼,非常耗時低效,
解決方法:
openLAB加工的pdf結構簡單且沒有經過加密,可以被python的pdfplumber庫準確的決議,并且資料在pdf檔案中以表格的形式呈現,可以使用正則運算式準確的定位和提取,具體方法如下:
1.pdfplumber決議pdf報告并且原文轉存為txt
import pdfplumber
import pandas as pd
import sys
import os
#獲取目標檔案目錄和該目錄下所有pdf檔案
if os.path.exists(sys.argv[1]):
pdf_reports = os.listdir(sys.argv[1])
pdf_reports = [x for x in pdf_reports if x[-4:] == '.pdf']
if not pdf_reports:
raise Exception('該目錄下沒有pdf報告!')
else:
raise Exception('這個目錄不存在!')
# 核驗輸出路徑的有效性
if sys.argv[2][-1] != '/':
raise Exception('the s')
else:
if not os.path.exists(sys.argv[2]):
os.mkdir(sys.argv[2])
#提取pdf資訊并轉存為txt檔案
for report in pdf_reports:
with pdfplumber.open(sys.argv[1]+report) as pdf:
content = ''
#len(pdf.pages)為PDF檔案頁數
for i in range(len(pdf.pages)):
#pdf.pages[i] 是讀取PDF檔案第i+1頁
page = pdf.pages[i]
#page.extract_text()函式即讀取文本內容,下面這步是去掉檔案最下面的頁碼
page_content = '\n'.join(page.extract_text().split('\n')[2:-1])
content = content + page_content + '\n'
f = open(sys.argv[2]+report.replace('.pdf', '.txt'), 'w')
f.write(content)
f.close()
2.從txt文本中提取出資料資訊
import argparse
import re
import pandas as pd
import os
parser = argparse.ArgumentParser(description="從txt文本中提取資訊.")
parser.add_argument('-i', '--indir', help="txt報告存在目錄", required=True)
parser.add_argument('-o', "--outfile", help="輸出資料檔案目錄")
args = parser.parse_args()
if os.path.exists(args.indir):
txt_reports = os.listdir(args.indir)
txt_reports = [x for x in txt_reports if x[-4:] == '.txt']
if not txt_reports:
raise Exception("該目錄下沒有報告檔案!")
else:
raise Exception("該檔案路徑不存在")
#
f = open(args.indir+txt_reports[0])
temp = re.search("(-+\|)+-+\s?(.*?)(=+)", f.read(), re.S)
data_tab = temp.group()
data_tab = data_tab.split('\n')[1:-4]
for i in data_tab[::-1]:
if ("[" in i) or ("保留時間" in i) or ("-" in i and "|" in i):
data_tab.remove(i)
data_tab = [(' '.join(x.split()).split()) for x in data_tab]
df = pd.DataFrame(data_tab)
df = df.loc[:,5]
wanted = pd.DataFrame(columns=df)
wanted.insert(loc=0, column='trial', value="")
#
for report in txt_reports:
f = open(args.indir+report, 'r')
temp = re.search("(-+\|)+-+\s?(.*?)(=+)", f.read(), re.S)
data_tab = temp.group()
data_tab = data_tab.split('\n')[1:-4]
for i in data_tab[::-1]:
if ('[' in i) or ("保留" in i) or ("-" in i and "|" in i):
data_tab.remove(i)
data_tab = [(' '.join(x.split()).split()) for x in data_tab]
df = pd.DataFrame(data_tab)
df = df.loc[:,(4,5)]
df.set_index(5, inplace=True)
df =df.T
df.insert(loc=0,column='trial', value=report[:-4])
wanted = wanted.append(df)
wanted.to_csv(args.outfile, sep=',')
資料處理
在獲得試驗資料后,由于經常會設定3個以上的重復,并且重復之間還存在一定的資料波動,這些重復處理和重復間的波動會影響試驗員對于資料質量和趨勢的判斷,如果能夠在第一時間,將資料整理成為平均值和方差的形式,那么資料的展現會更加的直觀,均值的變化體現資料的趨勢,方差則體現了資料的質量,另外,資料這樣處理之后非常便于后續的繪圖作業,以excel舉例,個人認為excel繪制帶誤差線的柱狀圖和條形圖是非常麻煩的,需要另外計算出方差(不過本人excel技術也非常的爛,所以這里說的可能不對,畢竟excel實在是一個強大的軟體),因此計算出資料的均值和方差,無論后期制表還是繪圖都有幫助,另外,試驗資料的存盤大多非常標準,這意味著非常便于計算機程式的處理,下面是我的實作方法:
import sys
import numpy as np
import pandas as pd
import argparse
import os
#設定資料精度
pd.set_option('precision', 2)
parser = argparse.ArgumentParser(description="這是一個計算資料平均值和方差的函式.")
parser.add_argument('-i', '--infile', help="輸入檔案路徑", required=True)
parser.add_argument('-o', '--outdir', help="輸出檔案的存放路徑", required=True)
parser.add_argument('-f', '--formula', help="資料檔案中資料的處理公式")
args = parser.parse_args()
print(args.formula)
if args.infile[-4:] != '.csv':
print("輸入檔案不是一個csv檔案!")
sys.exit()
if args.outdir[-1] != '/' :
print("輸出檔案不是一個目錄!")
sys.exit()
else:
if not os.path.exists(args.outdir):
print("輸出檔案存放目錄不存在,請先創建!")
sys.exit()
df = pd.read_table(args.infile,sep=',')
#去除樣品名稱中的重復序號
df.trial = df.trial.apply(func = lambda x:x[:-2])
df.set_index('trial', inplace=True)
if args.formula:
args.formula = args.formula.replace('x', 'df')
args.formula = args.formula[2:]
df = eval(args.formula)
grouped = df.groupby(by=['trial'])
mean = ["np.mean" for i in df.columns]
mean = dict(zip(df.columns, mean))
data_mean = grouped.aggregate({key:eval(value) for key,value in mean.items()}).round(2)
data_mean.to_csv(args.outdir+"data_mean.csv", sep=',')
std = ["np.std" for i in df.columns]
std = dict(zip(df.columns, std))
data_std = grouped.aggregate({key:eval(value) for key, value in std.items()}).round(2)
data_std.to_csv(args.outdir+"data_std.csv",sep=',')
result = data_mean.astype('str') + "±" + data_std.astype('str')
result.to_csv(args.outdir+'result.csv', sep=',')
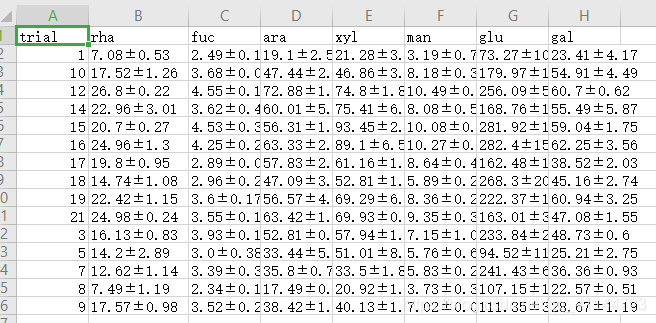
在這段代碼里面,存在一些個性化的設定,例如樣品名稱列的命名,資料的存盤格式和習慣等,格式個人喜歡用csv,存盤方式本人喜歡用spss的那種形式,一下是最終結果的效果展示,
原始檔案的存盤格式:
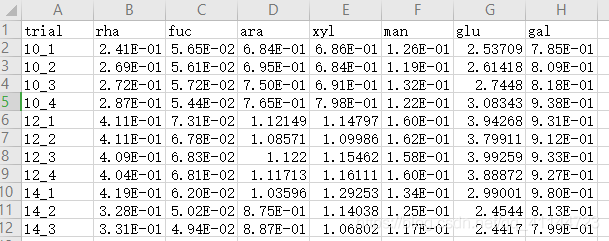
輸出的均值和方差形式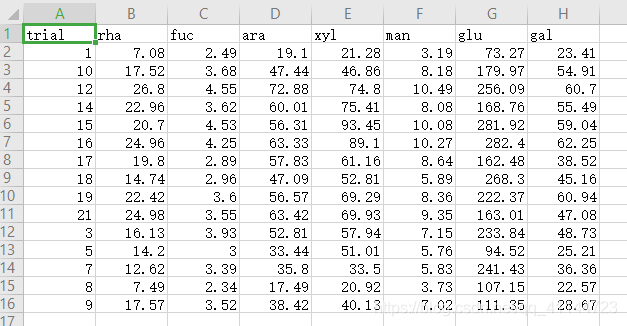
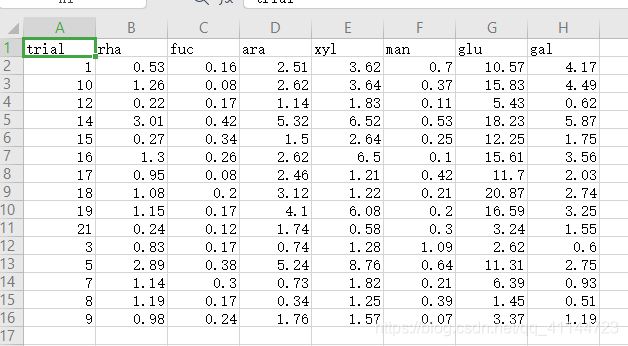
最終結果:
展望
- 本博客中提到的一些腳本仍然存在很多個性化的地方,還可以再提高,增強普適性,最好的結果就是同樣需求的試驗員可以下載后直接使用,漸少大家的資料處理時間和所有研究員總體的重復作業量,
- 在液相質譜儀和氣相色譜報告被處理后,可以再撰寫一個腳本,自動地判斷出處理的重復性,設定3%、5%等閾值分別用紅、黃、綠作為資料背景,可視化的展現該處理的資料質量,
- 為了更好的服務沒有編程基礎的試驗員,在時間充裕的情況下,可以考慮用PC搭建一個簡易的網站,開放API,使得上述腳本可以在網頁端直接呼叫,無需下載和編程環境的配置,并且該網站單次實際訪問量很小,PC完全可以滿足性能需求,可行性很高,
- 在本學期本人還接觸到一種儀器,具體名稱我忘記了,好像叫x射線重金屬檢測儀,該儀器可以同時檢測多種重金屬元素和一些其他元素,在園藝領域具有很好的應用前景,但是該儀器和氣相一樣,一個樣品生成一個資料報告,并且該報告為工程檔案,只能由特定軟體打開,加之資料分散度很高,處理難度很大,應該尋求一種更高效的方式解決,
- 我會一直尋找對于試驗員來說最高效的方法,將試驗員從低價值作業中擺脫出來,是一件極具意義的事情,2021再加油!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/259244.html
標籤:python