Python網路爬蟲(1):靜態網頁抓取
文章目錄
- Python網路爬蟲(1):靜態網頁抓取
- 前言
- 1 安裝Requests
- 2 獲取回應內容
- 3 定制Requests
- 3.1 傳遞URL引數`params`
- 3.2 定制請求頭`headers`
- 3.3 發送POST請求`data`
- 3.4 超時`timeout`
- 4 requests爬蟲實踐:豆瓣TOP250電影資料
前言
在網站設計中,純粹
HTML格式的網頁通常被稱為靜態網頁,早期的網站一般都是由靜態網頁制作的,
在網路爬蟲中,靜態網頁的資料比較容易獲取,因為所有資料都呈現在網頁的HTML代碼中,
相對而言,使用AJAX動態加載網頁的資料不一定會出現在HTML代碼中,這就給爬蟲增加了困難,
在靜態網頁抓取中,有一個強大的Requests庫能夠讓你輕易地發送HTTP請求,這篇文章主要介紹如何使用Requests庫獲取回應內容,最后可以通過定制Requests的一些引數來滿足我們的需求,
1 安裝Requests
pip install requests
2 獲取回應內容
import requests
r=requests.get('http://www.santostang.com/')
print("文本編碼:", r.encoding)
print("回應狀態碼:", r.status_code)
print("字串方式的回應體:", r.text)
print('位元組方式的回應體:', r.content)
print('Request中內置的JSON解碼器', r.json())
輸出:
本編碼: UTF-8
回應狀態碼: 200
字串方式的回應體: <!DOCTYPE html>...
- 說明
(1)r.encoding是服務器內容使用的文本編碼,
(2)r.status_code用于檢測回應的狀態碼,如果回傳200,就表示請求成功了;如果回傳的是4xx,就表示客戶端錯誤;回傳5xx則表示服務器錯誤回應,我們可以用r.status_code來檢測請求是否正確回應,
(3)r.text是服務器回應的內容,會自動根據回應頭部的字符編碼進行解碼,
(4)r.content是位元組方式的回應體,會自動解碼gzip和deflate編碼的回應資料,
(5)r.json()是Requests中內置的JSON解碼器,
3 定制Requests
有些網頁需要對Requests的引數進行設定才能獲取需要的資料,這包括傳遞URL引數params、定制請求頭headers、發送POST請求data、設定超時timeout 等,
3.1 傳遞URL引數params
- 請求特定的資料,我們需要在URL的查詢字串中加入某些資料,
如:http://httpbin.org/get?key1=value1&key2=value2
- 在Requests中,你可以直接把這些引數保存在字典中,用
params構建至URL中,
例如,傳遞key1=value1和key2=value2到http://httpbin.org/get,可以這樣撰寫:
import requests
key_dict = {'key1': 'value1', 'key2': 'value2'}
r = requests.get('http://httpbin.org/get', params=key_dict)
print('URL已經正確編碼:', r.url)
print("文本編碼:", r.encoding)
print("回應狀態碼:", r.status_code)
print('字串方式的回應體:\n', r.text)
輸出:
URL已經正確編碼: http://httpbin.org/get?key1=value1&key2=value2
文本編碼: utf-8
回應狀態碼: 200
字串方式的回應體:
{
"args": { # 使用get請求,此處的args的key1,key2值會被顯示出來
"key1": "value1",
"key2": "value2"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.25.1",
"X-Amzn-Trace-Id": "Root=1-6026482c-41a9bd646c22ba00497a8a63"
},
"origin": "118.212.203.240",
"url": "http://httpbin.org/get?key1=value1&key2=value2"
}
3.2 定制請求頭headers
請求頭
Headers提供了關于請求、回應或其他發送物體的資訊,
對于爬蟲而言,請求頭十分重要,如果沒有指定請求頭或請求的請求頭和實際網頁不一致,就可能無法回傳正確的結果,
Requests并不會基于定制的請求頭Headers的具體情況改變自己的行為,只是在最后的請求中,所有的請求頭資訊都會被傳遞進去
import requests
# key_dict = {'key1': 'value1', 'key2': 'value2'}
# 指定請求頭
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36 Edg/88.0.705.63',
'Host': 'www.santostang.com'}
# r = requests.get('http://httpbin.org/get', params=key_dict)
r = requests.get('http://www.santostang.com/', headers=headers)
print('URL已經正確編碼:', r.url)
print("文本編碼:", r.encoding)
print("回應狀態碼:", r.status_code)
print('字串方式的回應體:\n', r.text)
輸出:
URL已經正確編碼: http://www.santostang.com/
文本編碼: UTF-8
回應狀態碼: 200
3.3 發送POST請求data
除了
GET請求外,有時還需要發送一些編碼為表單形式的資料,如在登錄的時候請求就為POST,因為如果用GET請求,密碼就會顯示在URL中,這是非常不安全的,
如果要實作POST請求,只需要簡單地傳遞一個字典給Requests中的data引數,這個資料字典就會在發出請求的時候自動編碼為表單形式,
import requests
key_dict = {'key': 'value1', 'key2': 'value2'}
r = requests.post('http://httpbin.org/post', data=key_dict)
print('URL已經正確編碼:', r.url)
print("文本編碼:", r.encoding)
print("回應狀態碼:", r.status_code)
print('字串方式的回應體:\n', r.text)
輸出:
URL已經正確編碼: http://httpbin.org/post
文本編碼: utf-8
回應狀態碼: 200
字串方式的回應體:
{
"args": {}, # 使用post請求,此處的args的key1,key2值會被隱藏
"data": "",
"files": {},
"form": { # form變數的值為key_dict輸入的值
"key": "value1",
"key2": "value2"
},
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Content-Length": "22",
"Content-Type": "application/x-www-form-urlencoded",
"Host": "httpbin.org",
"User-Agent": "python-requests/2.25.1",
"X-Amzn-Trace-Id": "Root=1-60264cca-63d77c2c1c8bcf8c1042057b"
},
"json": null,
"origin": "118.212.203.240",
"url": "http://httpbin.org/post"
}
3.4 超時timeout
有時爬蟲會遇到服務器長時間不回傳,這時爬蟲程式就會一直等待,造成爬蟲程式沒有順利地執行,
因此,可以用Requests在timeout引數設定的秒數結束之后停止等待回應,
意思就是,如果服務器在timeout秒內沒有應答,就回傳例外,一般會把這個值設定為20秒,
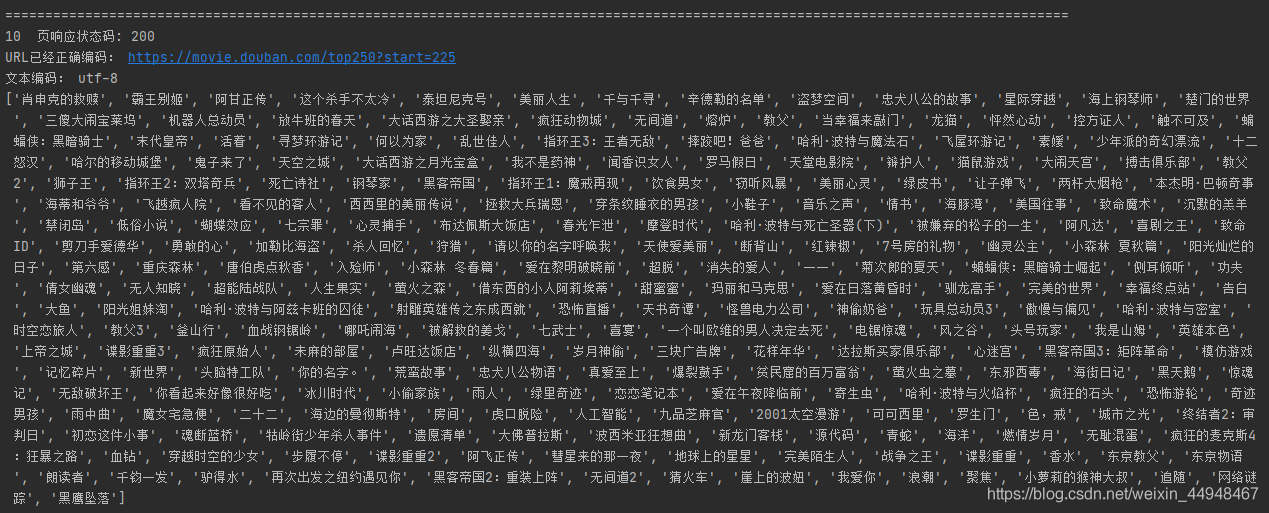
4 requests爬蟲實踐:豆瓣TOP250電影資料
靜態網頁抓取實踐專案的目的是獲取豆瓣電影TOP250的所有電影的名稱,網頁地址為:https://movie.douban.com/top250,在此爬蟲中,將請求頭定制為實際瀏覽器的請求頭,
#! /usr/bin/python
# coding: UTF-8
import requests
from bs4 import BeautifulSoup
def get_movies():
# 定制請求頭 requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36 Edg/88.0.705.63',
'Host': 'movie.douban.com'}
movie_list = []
# 1頁25部電影,for回圈獲取250部
for i in range(0, 10):
link = 'https://movie.douban.com/top250?start=' + str(i*25)
# 發送get請求,設定超時 timeout
r = requests.get(link, headers=headers, timeout=10)
print('================================================================================================================')
# 檢驗狀態
print(str(i+1), ' 頁回應狀態碼:', r.status_code)
print('URL已經正確編碼:', r.url)
print("文本編碼:", r.encoding)
# print(r.text) # r.text里的內容為html文本形式
# 決議網頁
soup = BeautifulSoup(r.text, 'lxml')
div_list = soup.find_all('div', class_='hd')
# div_info_list = soup.find_all('div', class_='item')
# 把電影名保存到movie_list串列中
for each in div_list:
movieName = each.a.span.text.strip()
movie_list.append(movieName) # 把電影都保存到字典后,由下邊的列印陳述句列印出總的list
print(movie_list)
return movie_list
# 呼叫函式
movies = get_movies()
輸出如圖:
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/259472.html
標籤:python
下一篇:Python自動化