前言
- 如果不明白如何對其進行爬取的程序,那么請參考: https://www.jianshu.com/p/65f8e46034fc 將為您解釋其基本的實作程序,
- 主要原因:唧唧下不了番劇,
- 網路不好會彈出請求地址失敗的資訊,
- SESSDATA 需在 Cookie 查看, 沒有則登錄嘗試,與會員視頻有密切聯系,
(1)Login (account, password) -> POST 形式提交資料 (密碼被加密后提交) -> 沒有回傳值,但自動在 Response Headers 設定了 set-cookie,里面也就包含了 SESSDATA 等資訊,也就是說,SESSDATA的獲取需要登錄,
(2)賬戶密碼為隱私資料,這里就用 xxx 替代,
(3)制作繁瑣,請自行查看,
Request URL
https://passport.bilibili.com/x/passport-login/web/login
Response Headers
access-control-allow-credentials: true
access-control-allow-headers: Origin,No-Cache,X-Requested-With,If-Modified-Since,Pragma,Last-Modified,Cache-Control,Expires,Content-Type,Access-Control-Allow-Credentials,DNT,X-CustomHeader,Keep-Alive,User-Agent,X-Cache-Webcdn,x-bilibili-key-real-ip,x-backend-bili-real-ip
access-control-allow-origin: https://passport.bilibili.com
bili-status-code: 0
bili-trace-id: 2bca58efea602525
cache-control: no-cache
content-length: 343
content-type: application/json; charset=utf-8
date: Thu, 11 Feb 2021 12:40:54 GMT
expires: Thu, 11 Feb 2021 12:40:53 GMT
set-cookie: SESSDATA=xxx; Path=/; Domain=bilibili.com; Expires=Tue, 10 Aug 2021 12:24:13 GMT; HttpOnly
set-cookie: bili_jct=667e147fa375f1da305e76654d4db3ff; Path=/; Domain=bilibili.com; Expires=Tue, 10 Aug 2021 12:24:13 GMT
set-cookie: DedeUserID=15687846; Path=/; Domain=bilibili.com; Expires=Tue, 10 Aug 2021 12:24:13 GMT
set-cookie: DedeUserID__ckMd5=1da4abd91d4728b0; Path=/; Domain=bilibili.com; Expires=Tue, 10 Aug 2021 12:24:13 GMT
set-cookie: sid=6k8eebr6; Path=/; Domain=bilibili.com; Expires=Tue, 10 Aug 2021 12:24:13 GMT
status: 200
x-cache-webcdn: BYPASS from ks-gz-webcdn-08
Form Data
source: main_web
username: xxx
password: xxx
keep: true
token: 254dc3aa330846aa8f1b0181e000e57e
go_url: https://passport.bilibili.com/account/security#/home
challenge: ef0a6e536d322765695e5be56582f651
validate: bfd8921294fe572577ada80b00c9dd7e
seccode: bfd8921294fe572577ada80b00c9dd7e|jordan
- 可下載視頻型別為官方與自上傳,小視頻沒怎么用,所以不太清楚是否可行,
- 想要 exe 方式打開的朋友,請自行打包,如有問題,請參考網上 pyinstaller 安裝: https://blog.csdn.net/qq_44737094/article/details/105970391?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_baidulandingword-6&spm=1001.2101.3001.4242
效果圖
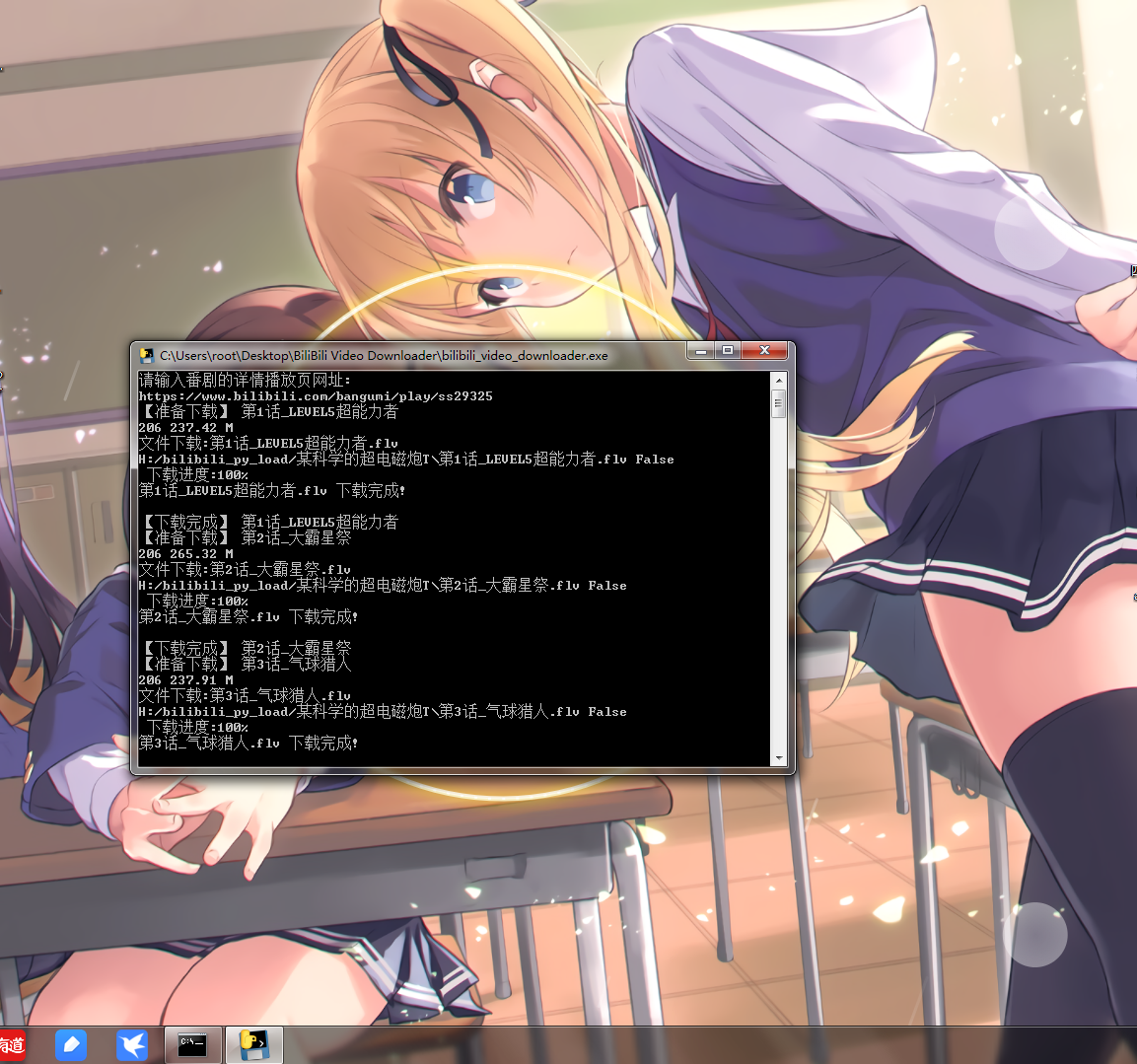
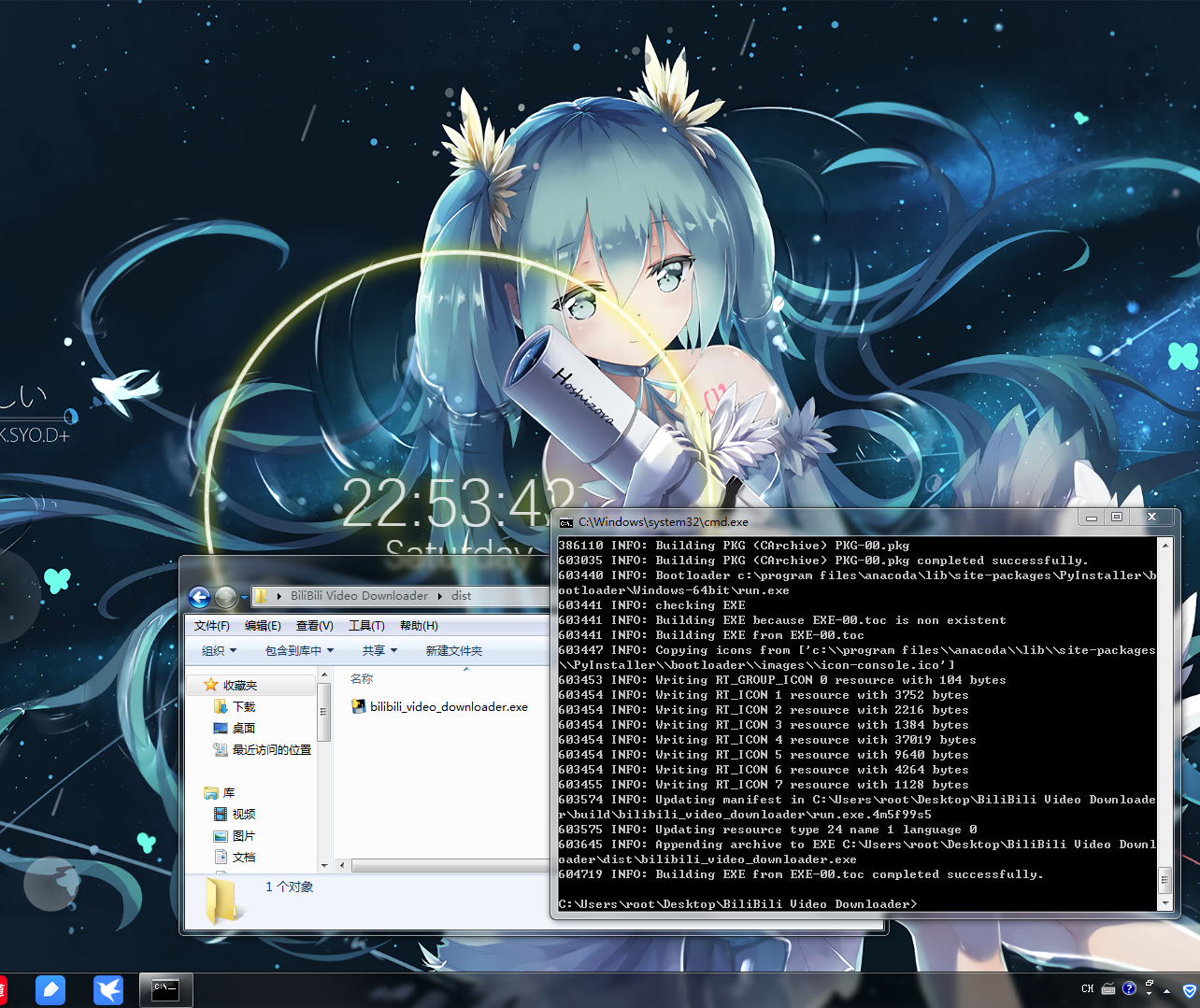
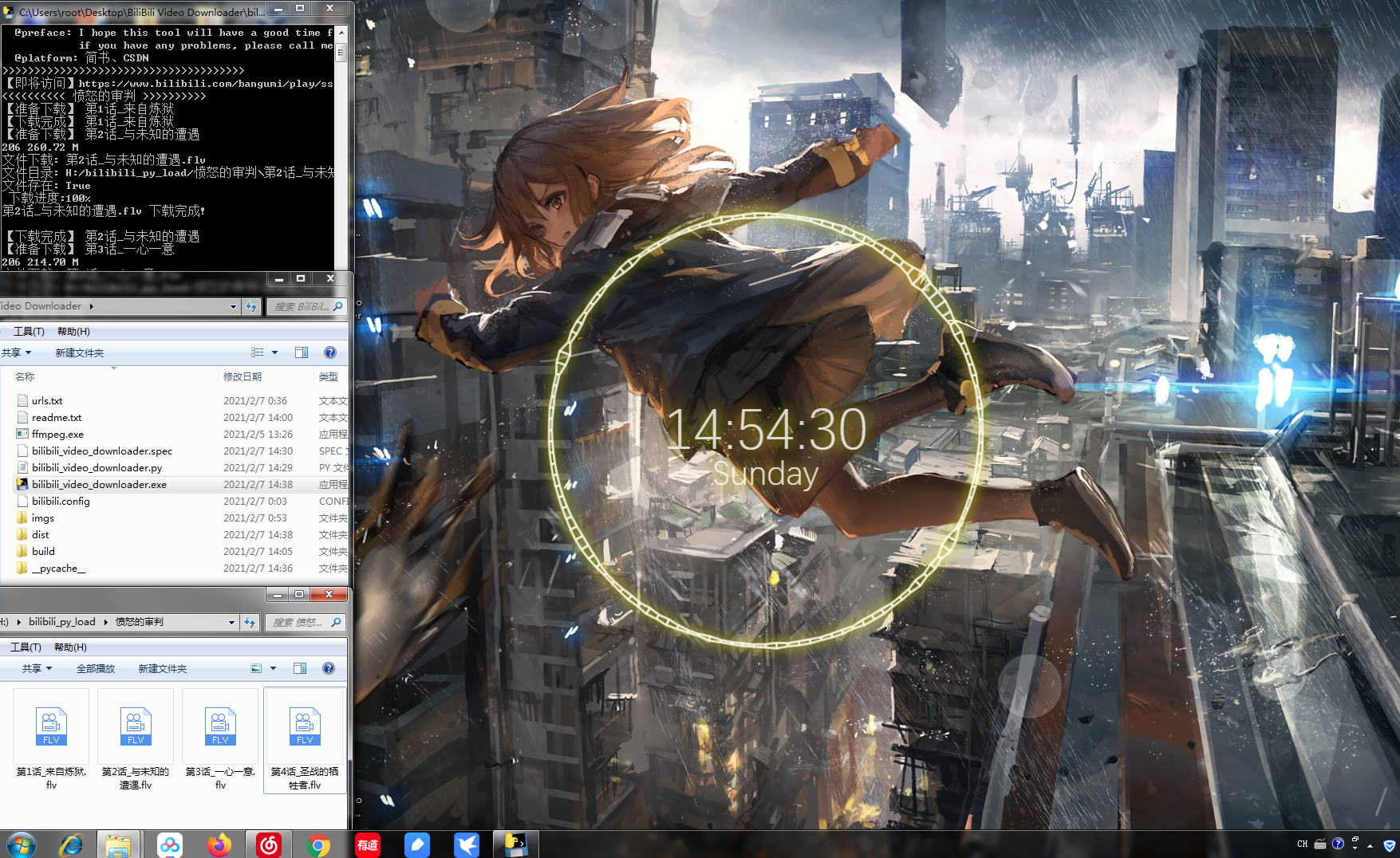
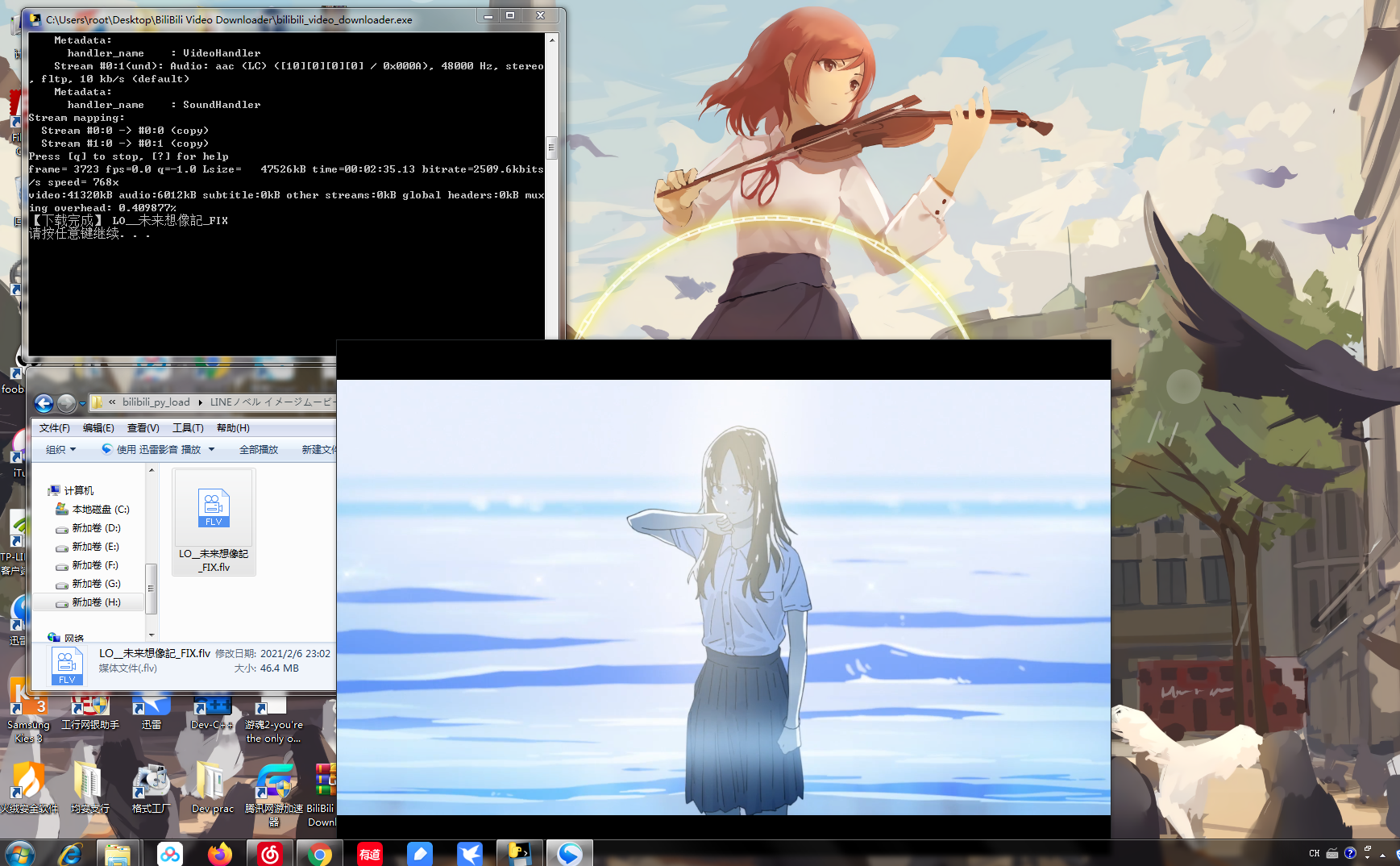
原始碼
bilibili-video-downloader.py
import requests
import json
import os
import time
from os.path import join
from lxml import etree
'''
讀取組態檔
'''
with open('./bilibili.config', 'r') as fp:
for line in fp.readlines():
cont = line.split('=')
if cont[0].find('FFMPEG_PATH') > -1:
ffmpeg_path = cont[1].strip()[1:-1]
elif cont[0].find('VIDEO_DIRECTORY') > -1:
v_dir_path = cont[1].strip()[1:-1]
elif cont[0].find('VIDEO_QUALITY') > -1:
v_eq = int(cont[1].strip())
elif cont[0].find('VIDEO_WAY') > -1:
v_fnval = int(cont[1].strip())
elif cont[0].find('SESSDATA') > -1:
f_sessdata = cont[1].strip()[1:-1]
elif cont[0].find('EPISODE_COMMAND') > -1:
EPISODE_COMMAND = cont[1].strip()
elif cont[0].find('VIDEO_URL_MODE ') > -1:
vu_mode = cont[1].strip()
elif cont[0].find('VIDEO_URL_FILE_PATH') > -1:
vuf_path = cont[1].strip()[1:-1]
fp.close()
'''
修改下列字符為window可用的檔案名
['\\', '/', ':', '*', '?', '<', '>', '|']
也就是說,把上述串列的符號,統一替換為另一種可用符號,
為求快,就統一,下劃線 _
'''
def local_filename_win_auto(name, s_sign='_'):
ban_sign = ['\\', '/', ':', '*', '?', '<', '>', '|']
name_arr = list(name)
for i in range(0, len(name_arr)):
if name[i] in ban_sign:
name_arr[i] = s_sign
return ''.join(name_arr)
# local_filename_win_auto("第15話_奧托·蘇文/相信的理由.flv")
'''
command = '1, 3, 4, 5, 29- 50, 66, 11-20'
, - 普通分隔 -> 單個數字
- - 數字范圍 -> 范圍數字
'''
def get_num_list_from_str(command):
its = command.split(',')
other_arr = []
main_arr = []
for it in its:
if it.find('-') > -1:
rs = it.split('-')
other_arr.append([i for i in range(int(rs[0]), int(rs[1]) + 1)])
else:
main_arr.append(int(it))
for arr in other_arr:
main_arr += arr
return main_arr
'''
https://api.bilibili.com/pgc/player/web/playurl?
cid=286965803& - cid
bvid=BV1QT4y1A7xq& - bvid
qn=0& - video quality[112, 80, 64, 32, 16, 0] - 0 是根據網速自動更換播放源檔案
type=&
otype=json - response data type
ep_id=373888 - episode id
fourk=1&
fnver=0&
fnval=80& - 視頻的傳輸型別 - [80:m4s視頻與音頻檔案分開, 112:等:flv, 1:mp4 流暢 360] - 其他的自行探索
'''
def get_url_type(url):
if url.find('www.bilibili.com/video') > -1:
return 1
elif url.find('www.bilibili.com/bangumi/play/') > -1:
return 2
else:
return -1
def get_video_api(url_type):
if url_type == 1:
return "https://api.bilibili.com/x/player/playurl"
elif url_type == 2:
return "https://api.bilibili.com/pgc/player/web/playurl"
'''
video accept info:
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
'accept_format': 'hdflv2,flv,flv720,flv480,mp4',
'accept_description': ['高清 1080P+', '高清 1080P', '高清 720P', '清晰 480P', '流暢 360P'],
'accept_quality': [112, 80, 64, 32, 16],
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
Conclude as follows:
1. 視頻播放型別有兩種:1) 現成的格式檔案 2) 視頻和音頻分流的 m4s
2. 視頻格式以 flv 為主,除了 流暢360P 為 mp4 格式
'''
def video_api(url, eq, fnval, **kwargs):
url_type = get_url_type(url)
api_url = get_video_api(url_type)
params = {
"otype": "json",
"qn": eq,
"fnval": fnval
}
for k, v in kwargs.items():
params[k] = v
# print(params, api_url, url)
'''
網頁原版的請求頭
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
headers = {
"cookie": "_uuid=2F78CD5C-87D5-33B4-5B07-85F0193F954375729infoc; sid=5y5w2c9c; DedeUserID=15687846; "
"DedeUserID__ckMd5=1da4abd91d4728b0; buvid3=08D5F52E-A4F4-4DC0-A9C5-97F623DFAF90138399infoc; "
"CURRENT_FNVAL=80; blackside_state=1;"
"LIVE_BUVID=AUTO4616018298606670; SESSDATA=xxx; "
"bili_jct=5d2cdd00ee83e17ae39ad2cbe8f777c1; CURRENT_QUALITY=0; bg_view_36101=374479; "
"bg_view_36168=373889%7C373888; bp_video_offset_15687846=487791466020378892; PVID=2 ",
"origin": "https://www.bilibili.com",
"referer": f"https://www.bilibili.com/bangumi/play/ep{ep_id}",
"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/85.0.4183.121 Safari/537.36 "
}
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
Cookie 的 SESSDATA 與賬戶或會員的檢測有關
如果 SESSDATA 失效,則自行去網上找
翻看方式:
Browser -> Press F12(具體看瀏覽器 and System) -> Application -> Storage
-> Cookies(http://www.bilibili.com) -> Name:SESSDATA, Value:???(就是這個東東)
'''
headers = {
"cookie": f"SESSDATA={f_sessdata}",
"referer": url,
"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/85.0.4183.121 Safari/537.36 "
}
return requests.get(url=api_url, headers=headers, params=params).json()
'''
通過啊B的不同api,與引數,回傳相應的資料,這里主要是視頻下載的資料
'''
# print(video_api("https://www.bilibili.com/video/BV18V411o7YX", eq=64, fnval=80,
# cid=174780228, bvid='BV18V411o7YX', ep_id=3))
# print(video_api("https://www.bilibili.com/bangumi/play/ss29325", eq=64, fnval=80,
# cid=144089354, bvid='BV11J411E731', ep_id=307248))
"""
考慮日常檔案單位問題,這里的范圍僅適用于日常大部分
1 byte = 8 bit
1 MB = 1024 byte
1 GB = 1024 MB
1 TB = 1024 GB
"""
def format_byte(size, show_bit=1, sign='', d_num=2):
# init
names = ['B', 'KB', 'M', 'G', 'T']
arr = [0 for i in range(0, 5)]
result = ['' for i in range(0, show_bit)]
decimal_mode = False
# 計算各單位的值并存盤
for i in range(0, len(names)):
arr[i] = size % 1024
size = int(size / 1024)
# 計算可用于展示的最大單位
s_inx = len(names) - 1
while arr[s_inx] == 0:
s_inx -= 1
# 弄個小數位,好看點,比如: 1G and 1.56G
if show_bit == 1 and not d_num <= 0:
decimal_mode = True
show_bit = 2
# 可用數量的索引計算 = (需求 <= 計算可用)
s_num = s_inx + 1 if s_inx + 1 - show_bit < 0 else show_bit
# 根據可用數量,進行區域展示陣列單位的拼接
if decimal_mode:
return f"{str(arr[s_inx])}.{str(int(arr[s_inx - 1] / 1024 * 1000))[:2]} {names[s_inx]}"
else:
for i in range(0, s_num):
result[i] = f"{str(arr[s_inx - i])}{names[s_inx - i]}"
# 反轉并拼接展示陣列
return sign.join(result)
'''
https://xy183x237x74x212xy.mcdn.bilivideo.cn:4483
/upgcxcode/03/58/286965803/286965803-1-30102.m4s?
expires=1612373226&
platform=pc&
ssig=xUQa_u7j0UWOBVR0kS8O5w&
oi=3746188697&
trid=aebf0cf2f1d44761b0b27f027045be66p&nfc=1&
nfb=maPYqpoel5MI3qOUX6YpRA==&
mcdnid=1001353&
mid=15687846&
orderid=1,3&
agrr=0&logo=60000001
'''
def bilibili_download(url, ep_id, directory, filename):
path = join(directory, filename)
headers = {
"accept": "*/*",
"accept-encoding": "identity",
"accept-language": "zh-CN,zh;q=0.9",
"origin": "https://www.bilibili.com",
"range": "bytes=0-", # 視頻位元組回應范圍 0- 為全部位元組
"referer": f"https://www.bilibili.com/bangumi/play/ep{ep_id}", # 視頻請求頁面
"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/85.0.4183.121 Safari/537.36 "
}
res = requests.get(url=url, stream=True, headers=headers)
full_size = content_length = int(res.headers['content-length'])
mode = 'wb'
# 根據本地檔案的狀態進行功能的調整
if os.path.exists(path):
if full_size == int(os.path.getsize(path)):
return True
elif full_size > int(os.path.getsize(path)):
mode = 'ab'
headers['range'] = f"bytes={os.path.getsize(path)}-"
res = requests.get(url=url, stream=True, headers=headers)
content_length = int(res.headers['content-length'])
else:
os.remove(path)
# Prepare to download and print some message on the console
print(res.status_code, filename)
print("請求地址: %s" % url)
print("剩余位元組: %s" % format_byte(content_length))
print("檔案目錄: %s" % path)
print("檔案存在: %s" % os.path.exists(path))
# Download process
with open(path, mode) as f:
for chunk in res.iter_content(chunk_size=1024 * 1024):
if chunk:
f.write(chunk)
print(f'\r 下載進度:{int(int(os.path.getsize(path)) / full_size * 100)}%',
end='', flush=True)
f.close()
# Finish download and tell clients who can quit
if full_size == os.path.getsize(path):
print("\n%s 下載完成!\n" % filename)
return True
else:
print("\n%s 下載未完成!\n" % filename)
return False
# The ffmpeg util is used to join videos split more than two parts
def video_join(directory, video_path, audio_path, new_path):
cur_dir = os.getcwd()
os.chdir(directory)
'''
>>>>>>>>>>>>>>>>>>>>>>>
os.system 執行狀態碼
0 - success
其他數字 - other errors
>>>>>>>>>>>>>>>>>>>>>>>>
詳情參考 CSDN 的文章: https://blog.csdn.net/lwgkzl/article/details/81060016
'''
cmd_status = os.system(f"ffmpeg -i {video_path} -i {audio_path} -codec copy {new_path}")
if not cmd_status == 0:
cmd_status = os.system(f"{join(ffmpeg_path, 'ffmpeg.exe')} "
f"-i {video_path} -i {audio_path} "
f"-codec copy {new_path}")
os.chdir(cur_dir)
return cmd_status == 0
'''
BiliBili Crawl Robot
Here will feedback url type num and data as a result so as to parse json data simply
Basic Info:
[epList]
1. bv_id - bvid
2. cid - cid
3. ep_id - id 集號
4. ep_title - longTitle 劇集名稱
5. ep_num - title 具體集數位置
[mediaInfo]
6. title - title 番劇名稱
7. ssid - ssId 番劇號
'''
def parse_basic_info_from_detail_page(url):
html = requests.get(url).text
parser = etree.HTML(html)
scripts = parser.xpath("//script")
info_head = "window.__INITIAL_STATE__"
info_tail = ";(function"
url_type = get_url_type(url)
data = {}
for script in scripts:
body = script.xpath("text()")
if len(body) == 0:
continue
elif body[0].find(info_head) == 0:
data = json.loads(body[0][len(info_head) + 1:body[0].rfind(info_tail)])
break
return url_type, data
# 這是無episode的version
# parse_basic_info_from_detail_page("https://www.bilibili.com/video/BV12v4y1o7wr")
# parse_basic_info_from_detail_page("https://www.bilibili.com/video/BV18V411o7YX")
'''
data -> 開始: [videoData(videos[視頻的p數], pages[各p的資訊](cid, part[p名], page[p的序號]))]
視頻和番劇的資料回傳格式不一樣,等待調整 !!!
'''
'''
通過 url 決議檔案名
url: https://www.abc.com/video/bv1234/1234.m4s?bv=1234&date=1234455656
在這里的 url 中, ? 后面的則為由 & 所分割的查詢引數 params
也就是 params 中有 bv = 1234 和 date = 1234455656
問號前的 // 開始,到第一個 / 之前的為域名加主機的內容
/ 之后的則為服務器的具體目錄,這里最后的后綴是 .m4s 這證明這是一個視頻檔案,可用于下載
考慮到后面的 params 可能存在重復的 ? 這里就分開進行,先找最左邊的問號,并切開取問號前的內容
之后,找最右邊的 / 切開并取其右邊的內容, 這樣就最大可能完整地取出檔案名
'''
def parse_filename(url):
# Obtain filename by url parsing
sl_url = url[url.rfind('/') + 1:]
sl_url_arr = sl_url.split('&')
if len(sl_url_arr) == 1:
filename = sl_url
else:
filename = sl_url_arr[0][:sl_url_arr[0].rfind('?')]
return filename
'''
番劇詳情頁的決議,也就是具體播放頁面,不是 ss 號那個頁面
'''
def video_download(url, cid, bvid, ep_id=-1, root='./', title='', eq=80, fnval=80):
suffix = 'mp4' if eq == 16 else 'flv'
new_name = f"{'_'.join(title.split(' '))}.{suffix}"
new_file = join(root, new_name)
res_status = False
# 有 ep_id 的是官方訂閱視頻,沒有的,則是 UP主 自行上傳的視頻,前者的vip視頻居多
if ep_id == -1:
v = video_api(url, eq=eq, fnval=fnval, cid=cid, bvid=bvid)
else:
v = video_api(url, eq=eq, fnval=fnval, cid=cid, bvid=bvid, ep_id=ep_id)
# 請求狀態反饋
if int(v.get('code')) == -10403:
print(f"【請求失敗】 {title}")
return res_status
'''
有會員的番劇無法獲取權限時,狀態為 -10403
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
{'code': -10403, 'message': '大會員專享限制'}
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
成功如下:
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
{'code': 0, 'message': 'success', ...}
>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
PS: 需要請求頭提交cookie的用戶資料
'''
result = v.get('result')
if result is None:
result = v.get('data')
print(f"【準備下載】 {title}")
try:
'''
兩種型別的api檔案
1. video + audio => m4s => video_join => flv/mp4/...
2. durl => flv/mp4 => ...
'''
if result.get('durl') is not None:
f_url = result.get('durl')[0].get('url')
f_status = bilibili_download(f_url, ep_id, root, new_name)
if f_status:
print(f"【下載完成】 {title}")
res_status = True
elif result.get('dash') is not None:
eq_range = result.get('accept_quality')
dash = result.get('dash')
videos = dash.get('video')
audio = dash.get('audio')[0]
eq_exists = eq in eq_range
v_urls = []
if not eq_exists:
if eq > eq_range[0]:
eq = eq_range[0]
elif eq < eq_range[len(eq_range) - 1]:
eq = eq_range[len(eq_range) - 1]
for video in videos:
if video.get('id') == eq:
v_urls.append(video.get('base_url'))
print(f"【視頻質量】 {eq}")
for k, v_url in enumerate(v_urls):
a_url = audio.get('base_url')
v_name = f'v_{parse_filename(v_url)}'
a_name = f'a_{parse_filename(a_url)}'
video_file = join(root, v_name)
audio_file = join(root, a_name)
# 判斷該檔案是否存在
if os.path.exists(new_file):
if os.path.getsize(new_file) == 0:
os.remove(new_file)
else:
return True
# 下載視頻檔案并獲取檔案的下載狀態
v_status = bilibili_download(v_url, ep_id, root, v_name)
a_status = bilibili_download(a_url, ep_id, root, a_name)
# 判斷是否滿足視頻拼接的條件(檔案完整性)
if not v_status or not a_status:
return res_status
# 視頻拼接,并洗掉原有的 m4s 檔案
reduce_status = video_join(root, v_name, a_name, new_name)
os.remove(video_file)
os.remove(audio_file)
print(f"【{'下載完成' if reduce_status else f'拼接失敗_{str(k + 1)}'}】 {title}")
if reduce_status:
res_status = True
break
return res_status
except Exception as e:
print(f"【!下載出錯】 {title}")
print(">>>>>>>>>>>>>>>>>>>>>")
print(repr(e))
print(">>>>>>>>>>>>>>>>>>>>>")
def videos_download(url, root='./', eq=80, fnval=80, new_dir=True, s_time=2, d_range=False, dv_command=None):
# 通過頁面,獲取該視頻的集數,及其相應的 BV, ID, CID 資訊
info = parse_basic_info_from_detail_page(url)
m_info = {}
if info[0] == 1:
m_info = info[1].get('videoData')
fnval = 80 # UP主 上傳的那些視頻,不是 80 的話,好像無法獲取視頻的下載資料
elif info[0] == 2:
m_info = info[1].get('mediaInfo')
# 新建視頻名稱的下載目錄
if new_dir:
root = join(root, local_filename_win_auto(m_info.get('title')))
if not os.path.exists(root):
os.mkdir(root)
if d_range and dv_command is None:
dv_command = input("請輸入您所需的集數[逗號','分隔,區間就用'-']: Such as: 1, 2-3, 4\n")
print(f"<<<<<<<<<< {m_info.get('title')} >>>>>>>>>>")
if info[0] == 1:
bv_id = m_info.get('bvid')
episode_num = m_info.get('videos')
pages = m_info.get('pages')
for i in get_num_list_from_str(dv_command) if d_range else range(0, episode_num):
# 通過上述資訊,請求視頻的具體資訊
video_download(url, pages[i].get('cid'), bv_id, -1, root,
f"第{pages[i].get('page')}話_{local_filename_win_auto(pages[i].get('part'))}", eq, fnval)
# 暫停 2s 防止被 ban
time.sleep(s_time)
elif info[0] == 2:
ep_list = info[1].get('epList')
# 逐集下載
for i in get_num_list_from_str(dv_command) if d_range else range(0, len(ep_list)):
# 通過上述資訊,請求視頻的具體資訊
video_download(url, ep_list[i].get('cid'), ep_list[i].get('bvid'), ep_list[i].get('id'), root,
f"第{ep_list[i].get('title')}話_{local_filename_win_auto(ep_list[i].get('longTitle'))}",
eq, fnval)
# 暫停 2s 防止被 ban
time.sleep(s_time)
'''
下載成功的案例
Time: 2021-02-05 15:32
'''
# 番劇: 黑神
# videos_download("https://www.bilibili.com/bangumi/play/ep33376", "H:/bilibili_py_load/")
# 番劇: Re:從零開始的異世界生活 第二季 后半
# videos_download("https://www.bilibili.com/bangumi/play/ss36429", "H:/bilibili_py_load/")
"""
資訊獲取
https://api.bilibili.com/x/player/v2?
cid=290412211&aid=416423565&
bvid=BV1NV411B74z&
season_id=36168&
ep_id=373889
比如下面: 視頻的原 aid, ip 資訊, 賬戶資訊, 區域 vip 資訊
{"aid": 416423565,"bvid": "BV1NV411B74z","ip_info": {...},"name": "mvlg_fms", ...}
由于這個對于視頻下載而言,作用不大,所以這里就簡略地過一下,畢竟分析時順便看到這玩意,
用戶資訊的顯示可能是因為你保存了密碼,或者在使用賬戶,一般而言,用戶資訊記錄在 Cookie 中,
"""
'''
位元組格式轉換測驗
'''
# print(format_byte(248347827))
# print(format_byte(1360485139))
'''
功能測驗
'''
# video_download("https://www.bilibili.com/video/BV12v4y1o7wr", 291293061, 'BV12v4y1o7wr', eq=32, root=v_dir_path)
# print(video_api("https://www.bilibili.com/video/BV18V411o7YX", eq=32, fnval=80,
# cid=174780228, bvid='BV18V411o7YX'))
# print(parse_basic_info_from_detail_page("https://www.bilibili.com/video/BV12v4y1o7wr"))
# videos_download("https://www.bilibili.com/video/BV12v4y1o7wr")
# videos_download("https://www.bilibili.com/video/BV18V411o7YX", eq=32)
if __name__ == '__main__':
'''
ffmpeg 檔案的目錄請自行設定于相關的組態檔 bilibili.config
設定方法: FFMPEG_PATH = "H:/"
這里的讀取方式可以使用逐行的正則公式 r'.*?FFMPEG_PATH.*?=.*?\".*?\"'
為求方便,快速,find 指令就算了,不想要的配置請自行洗掉
ffmpeg 是視頻處理主要使用的工具,詳情百度
不使用組態檔的人,自行使用以下代碼設定
# v_dir_path = input("請輸入視頻檔案的存盤路徑:\n")
# v_eq = int(input("[0, 1, 2, 3, 4] 清晰度 與 數字 成反比 - 請輸入數字:\n"))
# v_eqs = [112, 80, 64, 32, 16]
'''
print(">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>")
print(" @author: mvlg")
print(" @function: One downloader is used to download most part of video in bilibili we want")
print(" @preface: I hope this tool will have a good time for you")
print(" if you have any problems, please call me or send mail")
print(" @platform: 簡書、CSDN")
print(">>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>")
vd_urls = []
d_command = not EPISODE_COMMAND == "False"
# 以下皆可以在組態檔中自行設定
if vu_mode == "False":
while True:
v_res = input("請輸入番劇的詳情播放頁網址: \n"
"退出 - 請輸入 q | Q | quit | exit\n")
if v_res in ['q', 'Q', 'quit', 'exit']:
break
vd_urls.append(v_res)
else:
fp = open(vuf_path, 'r')
for line in fp.readlines():
if line.startswith('#'):
continue
vd_urls.append(line.strip())
fp.close()
for vd_url in vd_urls:
print(f"【即將訪問】{vd_url}")
try:
videos_download(vd_url, v_dir_path, eq=v_eq, fnval=v_fnval,
dv_command=d_command)
except Exception as e:
print(f"【!視頻下載主程式出錯】 {vd_url}")
print(">>>>>>>>>>>>>>>>>>>>>")
print(repr(e))
print(">>>>>>>>>>>>>>>>>>>>>")
time.sleep(5)
os.system("pause")
bilibili.config
FFMPEG_PATH = "./"
VIDEO_DIRECTORY = "H:/bilibili_py_load/"
SESSDATA = " "
VIDEO_QUALITY = 80
VIDEO_WAY = 112
EPISODE_COMMAND = False
VIDEO_URL_MODE = True
VIDEO_URL_FILE_PATH = "./urls.txt"
urls.txt
# 這里的 # 號開頭為注釋
https://www.bilibili.com/bangumi/play/ss36362
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/259479.html
標籤:python