資料挖掘-資料離散化 python實作
# -*-coding:utf-8-*-
"""
Author: Thinkgamer
Desc:
代碼4-2 基于資訊熵的資料離散化
"""
import numpy as np
import math
class DiscreteByEntropy:
def __init__(self, group, threshold):
self.maxGroup = group # 最大分組數
self.minInfoThreshold = threshold # 停止劃分的最小熵
self.result = dict() # 保存劃分結果
# 準備資料
def loadData(self):
data = np.array(
[
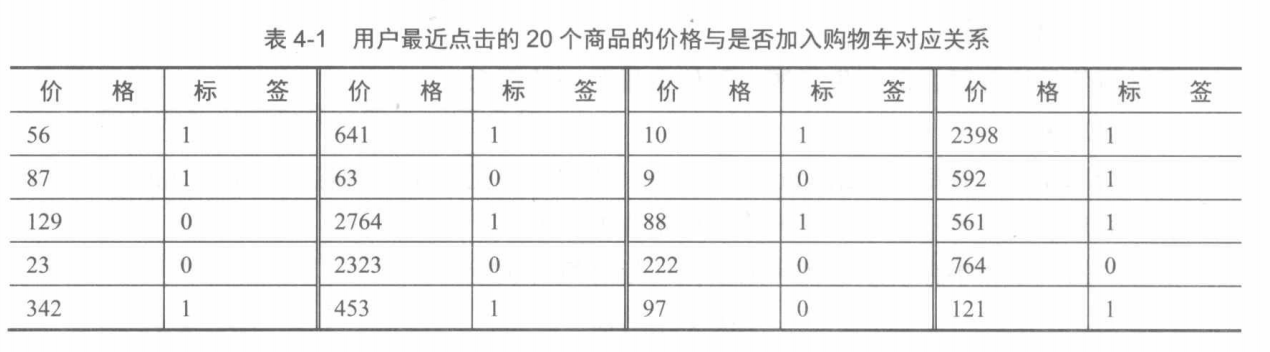
[56, 1], [87, 1], [129, 0], [23, 0], [342, 1],
[641, 1], [63, 0], [2764, 1], [2323, 0], [453, 1],
[10, 1], [9, 0], [88, 1], [222, 0], [97, 0],
[2398, 1], [592, 1], [561, 1], [764, 0], [121, 1],
]
)
return data
# 計算按照資料指定資料分組后的香農熵
def calEntropy(self, data):
numData = len(data)
labelCounts = {}
for feature in data:
# 獲得標簽
oneLabel = feature[-1]
# 如果標簽不在新定義的字典里創建該標簽值
labelCounts.setdefault(oneLabel, 0)
# 該類標簽下含有資料的個數
labelCounts[oneLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
# 同類標簽出現的概率
prob = float(labelCounts[key]) / numData
# 以2為底求對數
shannonEnt -= prob * math.log(prob, 2)
return shannonEnt
# 按照調和資訊熵最小化原則分割資料集
def split(self, data):
# inf為正無窮大
minEntropy = np.inf
# 記錄最終分割索引
index = -1
# 按照第一列對資料進行升序排序
sortData = data[np.argsort(data[:, 0])]
# 初始化最終分割資料后的熵
lastE1, lastE2 = -1, -1
# 回傳的資料結構,包含資料和對應的熵
S1 = dict()
S2 = dict()
for i in range(len(sortData)):
# 分割資料集
splitData1, splitData2 = sortData[: i + 1], sortData[i + 1 :]
entropy1, entropy2 = (
self.calEntropy(splitData1),
self.calEntropy(splitData2),
) # 計算資訊熵
entropy = entropy1 * len(splitData1) / len(sortData) + \
entropy2 * len( splitData2) / len(sortData)
# 如果調和平均熵小于最小值
if entropy < minEntropy:
minEntropy = entropy
index = i
lastE1 = entropy1
lastE2 = entropy2
S1["entropy"] = lastE1
S1["data"] = sortData[: index + 1]
S2["entropy"] = lastE2
S2["data"] = sortData[index + 1 :]
return S1, S2, entropy
# 對資料進行分組
def train(self, data):
# 需要遍歷的key
needSplitKey = [0]
# 將整個資料作為一組
self.result.setdefault(0, {})
self.result[0]["entropy"] = np.inf
self.result[0]["data"] = data
group = 1
for key in needSplitKey:
S1, S2, entropy = self.split(self.result[key]["data"])
# 如果滿足條件
if entropy > self.minInfoThreshold and group < self.maxGroup:
self.result[key] = S1
newKey = max(self.result.keys()) + 1
self.result[newKey] = S2
needSplitKey.extend([key])
needSplitKey.extend([newKey])
group += 1
else:
break
if __name__ == "__main__":
dbe = DiscreteByEntropy(group=6, threshold=0.5)
data = dbe.loadData()
dbe.train(data)
print("result is {}".format(dbe.result))
- 結果
result is {0: {'entropy': 0.0, 'data': array([[9, 0]])}, 1: {'entropy': 0.0, 'data': array([[342, 1],
[453, 1],
[561, 1],
[592, 1],
[641, 1]])}, 2: {'entropy': 0.0, 'data': array([[129, 0],
[222, 0]])}, 3: {'entropy': 1.0, 'data': array([[ 764, 0],
[2323, 0],
[2398, 1],
[2764, 1]])}, 4: {'entropy': 0.9544340029249649, 'data': array([[ 10, 1],
[ 23, 0],
[ 56, 1],
[ 63, 0],
[ 87, 1],
[ 88, 1],
[ 97, 0],
[121, 1]])}}
Process finished with exit code 0
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/259739.html
標籤:python
下一篇:力扣刷題筆記:765.情侶牽手(暴力解法,速度超93.97%的提交,空間超62%的提交,大年初三的困難題,就這。。。)