requests與Beautifulsoup的使用之爬蟲獲取豆瓣電影top250
- requests與Beautifulsoup簡介
- 安裝
- 功能簡介
- 本次的任務
- 爬蟲前的準備——網頁分析
- 具體代碼
- 一步步分析
- 初級完整版——只訪問一頁
- 最終完整版——多頁連續訪問并寫入txt
本文適合稍微有一點基礎的用戶,在閱讀本文前,你至少需要大致了解:
(1)python的基本語法
(2)python庫的pip安裝
(3)HTML標簽相關
本文選用的python IDE為pycharm,python和pycharm的安裝不在此文贅述,
requests與Beautifulsoup簡介
安裝
Windows+r打開cmd命令提示符,利用pip install 命令安裝兩個庫即可,
具體安裝命令如下:
pip install requests
pip install beautifulsoup4
回車即開始安裝,
如果回車后為空則說明未安裝pip模塊,解決方法可以百度一下,
安裝成功后在pycharm中新建一個檔案輸入
import requests
from bs4 import BeautifulSoup
若未出現紅色下劃線與報錯資訊則基本可以確定安裝成功,
功能簡介
個人理解:
requests庫的作用就是模擬人去訪問網頁的動作,因此其包含了網頁爬蟲的基本方法,如獲取網頁內容、提交用戶上傳表單等等;
而Beautifulsoup庫的作用就是模擬人訪問網頁得到資訊的程序,最終目的是通過訪問網頁獲得你想得到的資訊,
總而言之,不太嚴謹的說,requests負責和網頁互動,而beautifulsoup負責得到你想要的資訊,
本次的任務
獲取豆瓣電影top250的中文名稱和其對應的排名并將其寫入一個txt檔案,
網址:豆瓣電影top250
爬蟲前的準備——網頁分析
目前來說,使用瀏覽器自帶的開發除錯工具進行分析即可,打開瀏覽器(本文用的chrome),按下F12或Fn+F12即可調出該工具,效果如下:
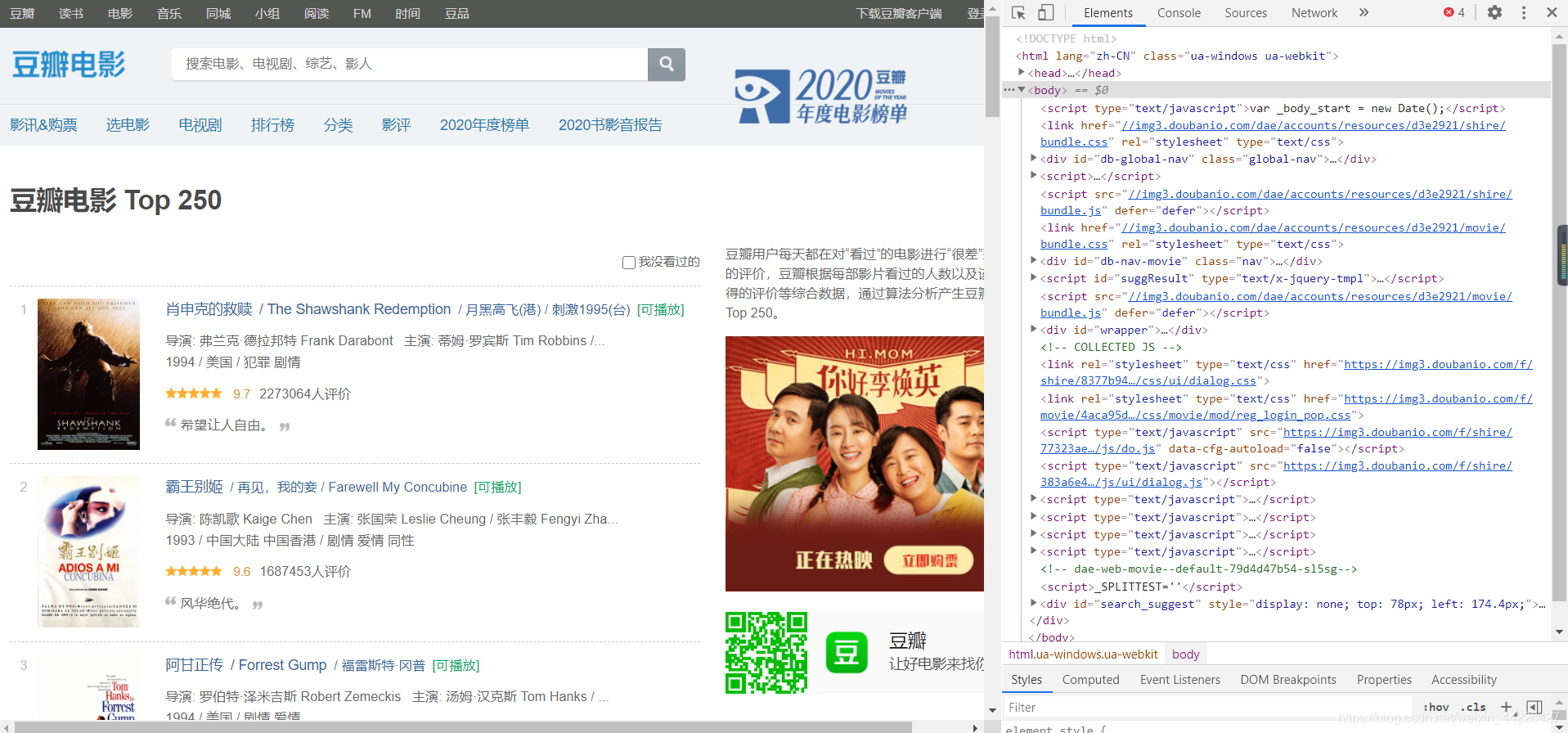
我們要獲得的是電影名,在網頁的主體部分,所以應該關注body標簽,將滑鼠放到各個標簽上,左邊對應的部分就會變色,如下圖:
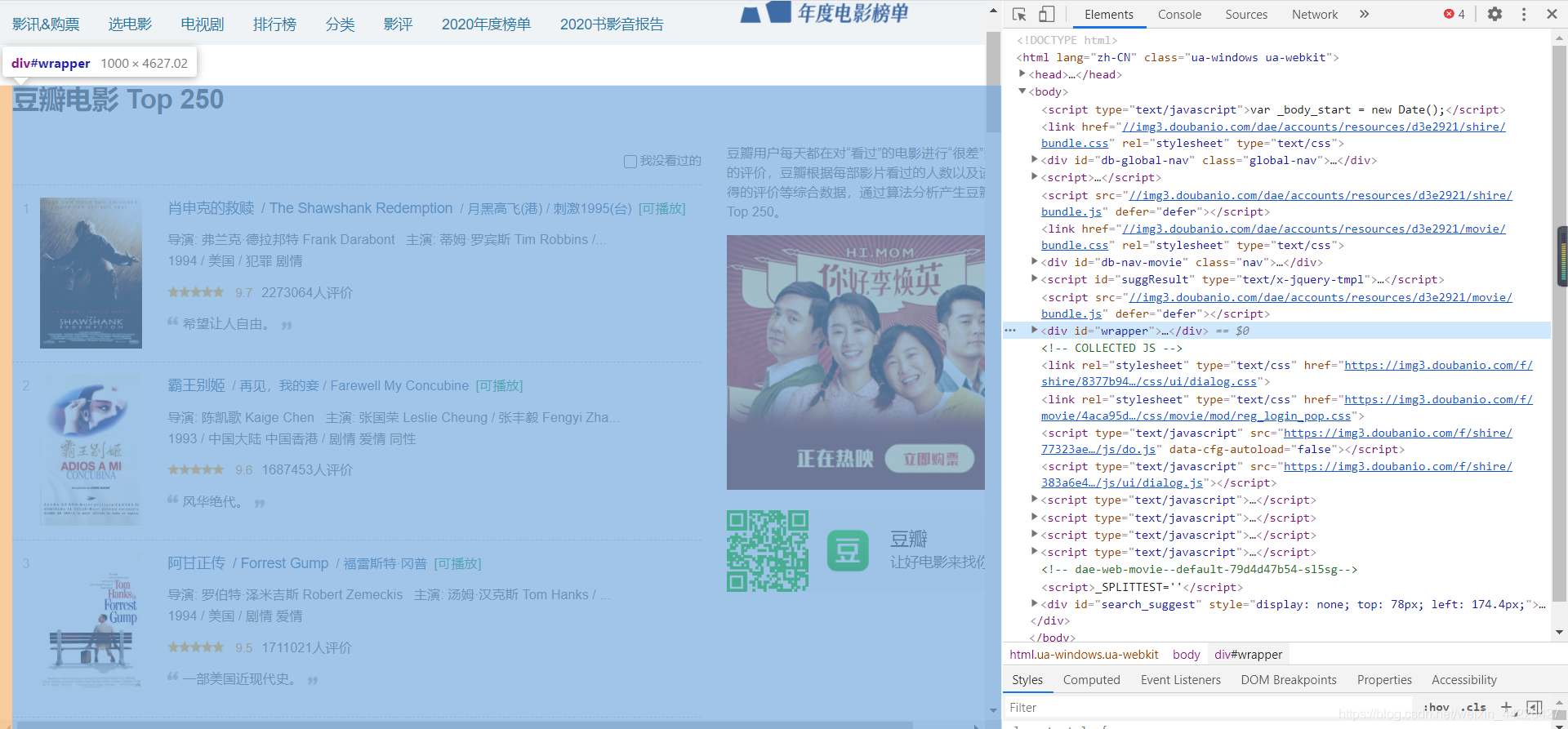
可以看出我們將滑鼠放在了一個id為wrapper的div標簽上右邊對應的區域就會變色,可以發現電影名在這個區域內,于是我們層層展開標簽,發現class名為hd的div標簽就是最小的一個div標簽了:
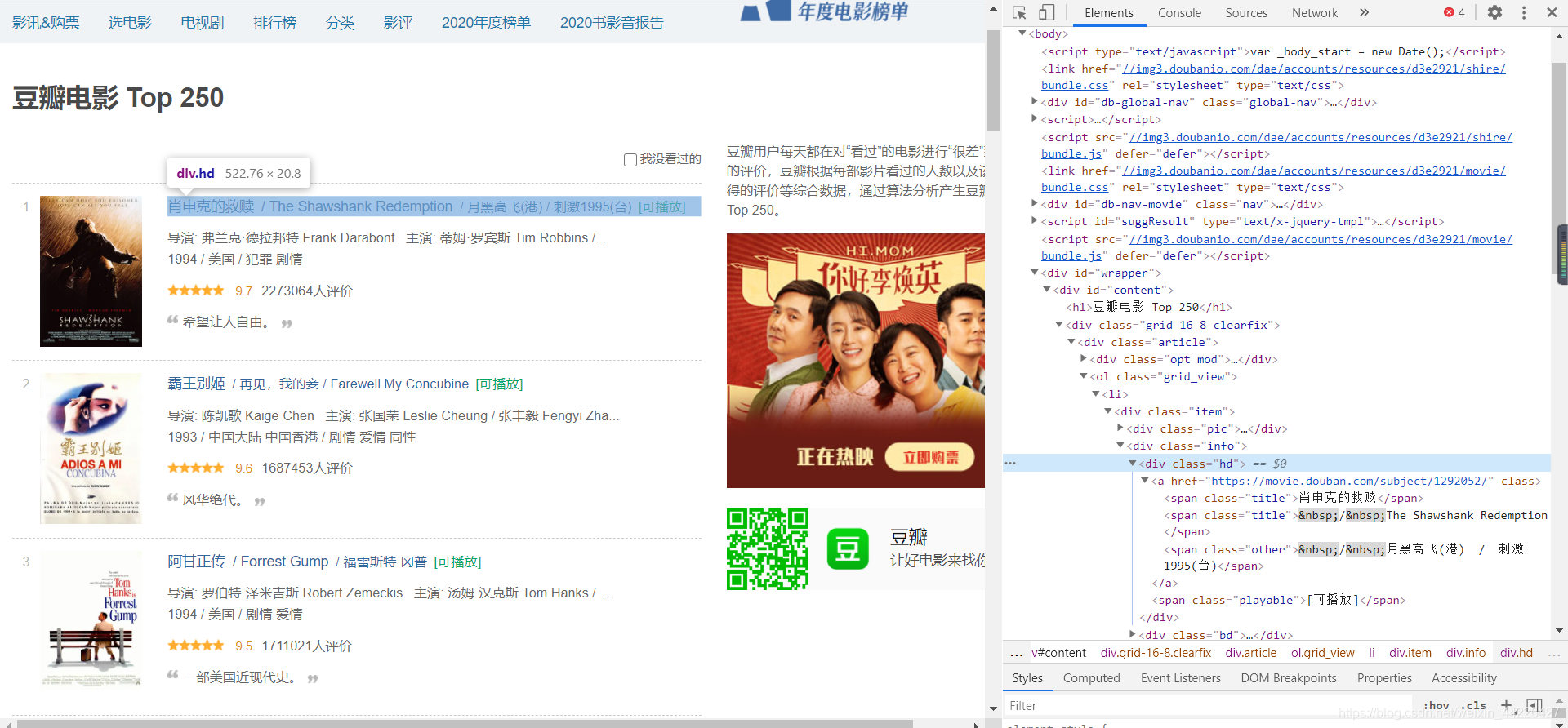
然后我們只需要獲取里面的這個div標簽下的第一個span標簽就是電影的中文名,
這樣我們就找到了我們要找的資訊,開始寫代碼,
具體代碼
一步步分析
首先,我們直接用requests的get方法獲取網站的狀態碼,看看結果:
import requests
url='https://movie.douban.com/top250'
data=requests.get(url).status_code
print(data)
輸出結果為418,這說明網站存在反爬程式,因此我們需要加一個請求頭來模擬瀏覽器訪問,如下:
import requests
url='https://movie.douban.com/top250'
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36'
}
data=requests.get(url=url,headers=headers).status_code
print(data)
這里輸出結果為200,表明成功訪問,
將后面的status_code換成content再輸出一遍試試,
發現輸出了一堆不是人話的東西,
再改成
data=requests.get(url=url,headers=headers).content.decode()

發現輸出的是帶標簽的整個網頁資訊,那么怎么提取出其中的人話呢,這時候就需要beautifulsoup出場了,
首先先建立一個beautifulsoup物件:
page=requests.get(url=url,headers=headers).content
soup=BeautifulSoup(page)
根據前面的分析,要找class名為hd的div標簽,且要找到這一頁所有的這個標簽,所以用find_all方法:
content=soup.find_all('div', class_="hd")
隨后用一個回圈讀出每一個類名hd的div中的第一個span標簽中的資料,并加上序號即可:
i=0
for k in content:
a=k.find_all('span')
# print(a)
i=i+1
print(i,a[0].string)
初級完整版——只訪問一頁
import requests
from bs4 import BeautifulSoup
url='https://movie.douban.com/top250'
def download_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36'
}
data=requests.get(url,headers=headers).content
return data
if __name__=='__main__':
# print(download_page(url).decode())
soup=BeautifulSoup(download_page(url))
# print(soup.prettify())
content=soup.find_all('div', class_="hd")
# print(content)
print(soup.title.string)
i=0
for k in content:
a=k.find_all('span')
# print(a)
i=i+1
print(i,a[0].string)
最終完整版——多頁連續訪問并寫入txt
多頁連續訪問:
觀察每一頁的網頁url,發現第二頁為
https://movie.douban.com/top250?start=25&filter=
因此第一頁可看作start=0,第三頁為start=50…以此類推,所以用一個回圈實作了翻頁(本質是訪問了一組不同的網頁):
for i in range(10):
url = 'https://movie.douban.com/top250?start=' + str(i*25) + '&filter='
寫入txt:
加入python檔案操作,用open()方法打開檔案,write()方法改寫,close()方法關閉檔案,
import requests
from bs4 import BeautifulSoup
f = open("檔案位置路徑\檔案名.txt","w")
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.80 Safari/537.36'
}
for i in range(10):
url = 'https://movie.douban.com/top250?start=' + str(i*25) + '&filter='
data = requests.get(url, headers=headers).content
soup = BeautifulSoup(data)
content = soup.find_all('div', class_="hd")
# print(soup.title.string)
j = 0
for k in content:
a = k.find_all('span')
# print(a)
j = j + 1
print(j+25*i, a[0].string)
f.write(str(j+25*i))
f.write(" ")
f.write(a[0].string)
f.write("\n")
f.close()
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/260057.html
標籤:python
上一篇:python之星河戰爭游戲