可視化展示
看完記得點個贊喲
微博炫酷可視化音樂組合版來了!
專案介紹
背景
現階段,微博、抖音、快手、嘩哩嘩哩、微信公眾號已經成為不少年輕人必備的“生活神器”,在21世紀的今天,你又是如何獲取外界的資訊資源的?相信很多小伙伴應該屬于下面這一種型別的:
事情要想知道快,抖音平臺馬上拍;
微博熱搜刷一刷,聚焦熱點不愁賣;
閑來發呆怎么辦, B 站抖音快手來;
要是深夜無聊備,微信文章踩一踩;
哈哈哈,小小的活躍一下氣氛
在這個萬物互聯的時代,已不再是那個“從前慢,車馬慢......”的飛鴿傳書三月天的時代了,資料每一天都有人在產生,也有人時刻在收集和監控資料,更是有人不斷地在分析和利用資料產生潛在的價值,
專案概覽
本次專案選取的是微博熱搜資料,爬取加資料分析和可視化展示,基于微博熱搜的娛樂專案,
本次資料是選取之前的,并不是最新的微博資料,當然可以自己去運行代碼就可以爬取最新的資料了!
微博熱搜資料爬取
部分代碼展示
微博熱度動態輪播圖
部分代碼展示
原始碼點擊此處下載
微博話題定位追蹤可視化
部分原始碼展示
原始碼點擊此處下載
爬取微博熱搜文章評論詞云分析
部分原始碼展示
點擊此處下載原始碼
近期微博熱搜話題詞云展示
點擊此處下載原始碼
其他專案點擊此處
專案代碼展示
微博熱搜資料爬取
選取微博熱搜榜官網,網址如下:
https://s.weibo.com/top/summary?cate=realtimehot&sudaref=s.weibo.com&display=0&retcode=6102
1.通過簡單對網頁的決議與觀察我們可以定位我們所需要的資料標簽值,決定我們應該用什么決議庫,可以用Xpath、正則運算式、beautifulsoup都可以實作功能,本次選取的是beautifulsoup進行對資料表的決議,
2.同時我們需要注意的是微博反爬的措施,我們需要加入自己的請求頭,我們借用一個第三方庫,它可以隨機產生一個可用的請求頭來偽裝我們的軟體,模擬瀏覽器進行資料抓取:from fake_useragent import UserAgent
3.微博熱搜是每一分鐘更新一次,我們需要用到定時爬取的模塊,每一分鐘爬取需要的資料:import schedule
4.每一分鐘爬取一次,一個小時爬取60種類資料,建議爬取開啟5-7小時,讓電腦自動抓取資料,那么就需要用到延時模塊了:import time
5.微博抓取的資料有排名、熱搜標題、熱度,為了我們方便展示和資料分析,我們需要給它加上時間戳,自動獲取當前時間,引進:from datetime import datetime
6.資料爬取好之后我們需要存盤,我們采用pandas這個強大的資料分析庫,進行資料的存盤:import pandas as pd
部分代碼展示
from fake_useragent import UserAgent
import schedule
import pandas as pd
from datetime import datetime
import requests
from bs4 import BeautifulSoup
import time
ua = UserAgent() # 解決了我們平時自己設定偽裝頭的繁瑣,此庫自動為我們彈出一個可用的模擬瀏覽器
url = "https://s.weibo.com/top/summary?cate=realtimehot&sudaref=s.weibo.com&display=0&retcode=6102"
headers = {"User-Agent": ua.random}
get_info_dict = {} # 創建一個資料字典
count = 0
a = 1
def main():
global url, get_info_dict, count, a
get_info_list = []
html = requests.get(url, headers).text # 回傳網頁原始碼為txt文本
# 定時爬蟲
schedule.every(1).minutes.do(main) # 根據微博每隔一分鐘更新一次資料,我們就每隔一分鐘爬取資料
while True:
time.sleep(2)
schedule.run_pending() # 執行可執行結構
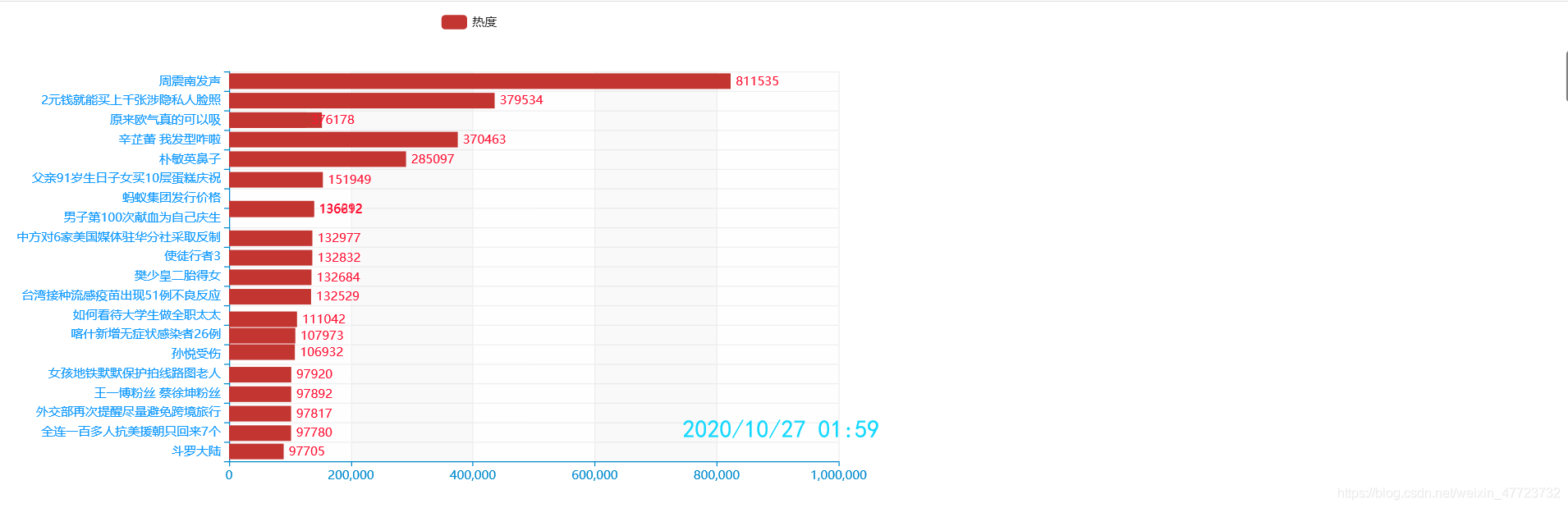
微博熱度動態輪播圖
可視化基于pyecharts這個強大的庫,適合做這種比較炫酷的可視化展示,輪播圖是如何去實作資料迭代展示的,我們一共爬取了多少次就會有多少次迭代回圈,第一次提取出資料進行可視化,第二次繼續提取,如果第二次的資料與第一次的資料不一樣那么動態效果也就自然顯示出來了,這樣不斷的去展示效果,再去設定一些引數:比如播放的幀數時間間隔等,那種動態的效果就會出來了,
部分代碼展示
df = pd.read_csv('夜間微博.csv', encoding='gbk')#解碼,注意這里不能使用utf-8,因為CSV檔案使用gbk編碼
t = Timeline({"theme": ThemeType.MACARONS}) # 定制主題——動態直方圖
for i in range(389):#這里的引數設定為我們總共了爬取的多少次更新動態資料
bar = (
Bar()
.add_xaxis(list(df['關鍵詞'][i*20: i*20+20][::-1])) # x軸資料
.add_yaxis('熱度', list(df['熱度'][i*20: i*20+20][::-1])) # y軸資料
.reversal_axis() # 翻轉
.set_global_opts( # 全域配置項
title_opts=opts.TitleOpts( # 標題配置項
title=f"{list(df['時間'])[i*20]}",
pos_right="5%", pos_bottom="15%",
title_textstyle_opts=opts.TextStyleOpts(
font_family='KaiTi', font_size=24, color='#14d8ff'#顏色配置去:https://encycolorpedia.cn/ff1493查詢設定
)
),
xaxis_opts=opts.AxisOpts( # x軸配置項
splitline_opts=opts.SplitLineOpts(is_show=True),#降序排序,從大到小,默認為升序
),
yaxis_opts=opts.AxisOpts( # y軸配置項
splitline_opts=opts.SplitLineOpts(is_show=True),
axislabel_opts=opts.LabelOpts(color='#149bff')
)
)
.set_series_opts( # 系列配置項
label_opts=opts.LabelOpts( # 標簽配置
position="right", color='#ff1435')原始碼點擊此處下載
微博話題定位追蹤可視化
對爬取的資料知識簡單的輪播圖展示熱度,顯得有點單調了,選取自己喜歡的話題去追蹤定位它在這一個時間段里面的熱度趨勢,采用pyecharts這個動態折線圖的展示效果,再結合Python原生態的演算法添加資料,兩者結合在一起如虎添翼,
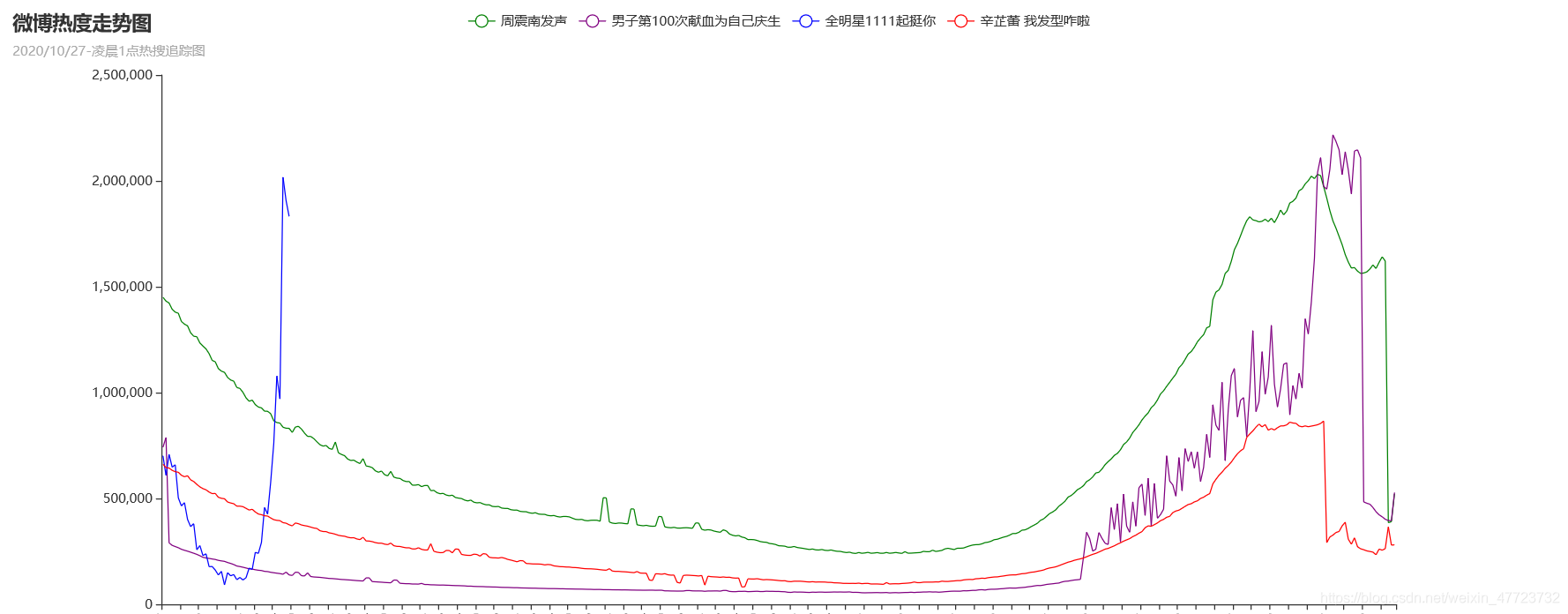
部分原始碼展示
c = (
Line(init_opts=opts.InitOpts(width="1400px", height="600px")) # 畫布大小
.add_xaxis(x_data) # 添加x軸
.add_yaxis('周震南發聲', y_1data, is_symbol_show=False, color=['red']) # 添加第一個y軸
.add_yaxis('男子第100次獻血為自己慶生', y_2data, is_symbol_show=False, color=['blue'])
.add_yaxis('全明星1111起挺你', y_3data, is_symbol_show=False, color=['purple'])
.add_yaxis('辛芷蕾 我發型咋啦', y_4data, is_symbol_show=False, color=['green'])
.set_global_opts(
title_opts=opts.TitleOpts(title='微博熱度走勢圖', subtitle="2020/10/27-凌晨1點熱搜追蹤圖"),
# 設定x軸的label字體的走向,由于x軸過多,顯示不全,在這調整旋轉角度
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=90)),
# 下面這是調整是否可以縮放的
datazoom_opts=opts.DataZoomOpts(is_show=True),
)
)with open(r"熱度跟蹤圖.txt", 'w', encoding="utf-8") as fi:
for q in ll:
fi.write('"' + q + '"' + ",")
print("恒定時間寫入成功!!")
fi.write('\n熱搜標題1:{}\n'.format(a))
for w in ls:
fi.write(w + ",")
print("追蹤熱度1號寫入成功!!")
fi.write('\n熱搜標題2:{}\n'.format(b))
for w in lk:
fi.write(w + ",")
print("追蹤熱度2號寫入成功!!")
fi.write('\n熱搜標題3:{}\n'.format(c))
for w in lf:
fi.write(w + ",")
print("追蹤熱度3號寫入成功!!")
fi.write('\n熱搜標題4:{}\n'.format(d))
for w in le:
fi.write(w + ",")
print("追蹤熱度4號寫入成功!!")原始碼點擊此處下載
爬取微博熱搜文章評論詞云分析
結合抓包工具和瀏覽器的模擬點擊,爬取微博文章評論,利用這個自動輸出展示詞云,讓我們快速理解關于該話題文章的熱搜趨勢和熱點,來看看周震南事件到底是什么東東

部分原始碼展示
import requests
import json
import pprint
import re
def get_comments(url):
headers={
"cookie":"WEIBOCN_FROM=1110006030; SUB=_2A25ykBYoDeRhGeNL6VQX9SzOzz-IHXVuerpgrDV6PUJbkdANLVnxkW1NSP633HCwOYWsoKRdojJu08k0-l9OKPoi; SUHB=09P9SVp1GiU0Dz; _T_WM=46932887560; XSRF-TOKEN=f40f69; MLOGIN=1; M_WEIBOCN_PARAMS=uicode%3D20000061%26fid%3D4563689719990147%26oid%3D4563689719990147",
"Accept":"application/json, text/plain, */*",
"MWeibo-Pwa":"1",
"Referer":"https://m.weibo.cn/detail/4563874994983986",
"User-Agent":"Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Mobile Safari/537.36",
"X-Requested-With":"XMLHttpRequest",
"X-XSRF-TOKEN":"50171a"
}
res=requests.get(url,headers=headers)
ids=re.findall('u524d","id":"(.*?)",',res.text)
file=open("評論.txt", "w", encoding='utf-8')
for id in ids:
s_url="https://m.weibo.cn/comments/hotflow?id={}&mid={}&max_id_type=0".format(id,id)
print(s_url)
sing_res = requests.get(url=s_url, headers=headers)
sing_data = json.loads(sing_res.text)
users = sing_data['data']['data']
age_urls = re.findall('"profile_url":"(.*?)",', res.text)with open(r"評論.txt",encoding="utf-8") as file:
a=file.read()
b=jieba.lcut(a)
for x in b:
if x in ",,、;:‘’“”【】《》?、.!…\n":
continue
else:
if len(x) == 1:
ll.append(x)
elif len(x) == 2:
lg.append(x)
elif len(x) == 3:
lk.append(x)
elif len(x)== 4:
lj.append(x)
# lp.append(x)
for i in lg:
lp.append(i)
for p in lk:
lp.append(p)
for f in lj:
lp.append(f)
點擊此處下載原始碼
近期微博熱搜話題詞云展示
爬取近期一個月的微博熱搜話題,看看大家最近都在聚焦什么,不多說了,這里涉及到的一些引數,首先請求頭,cookies,能加的都加,我們只需要獲取文字標題,可以通過Xpath來解決,原始碼里面是利用beautifulsoup這個一樣的道理,最后輸出為一個文本格式即可,抓包工具還是比較好的,一些看不到的資料我們可以通過這個神器來解決,自然動態加載還是Ajax都不是問題了,


點擊此處下載原始碼
其他專案點擊此處
基于pyecharts可視化展示,動態可視化效果,后期在專欄《資料可視化之美》里面詳細介紹pyecharts的用法和展示案例
每文一語
微 言細詞覽無余
博 文入目皆可析
數 秒分取千萬條
據 重方解圖表均
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/260064.html
標籤:python
上一篇:python基礎語法學習筆記