要說鵝廠良心產品排行,微信讀書絕對名列前茅,今天就來好好聊一聊~~~
1.頁面分析
進入到https://weread.qq.com/web/category/100000頁面,
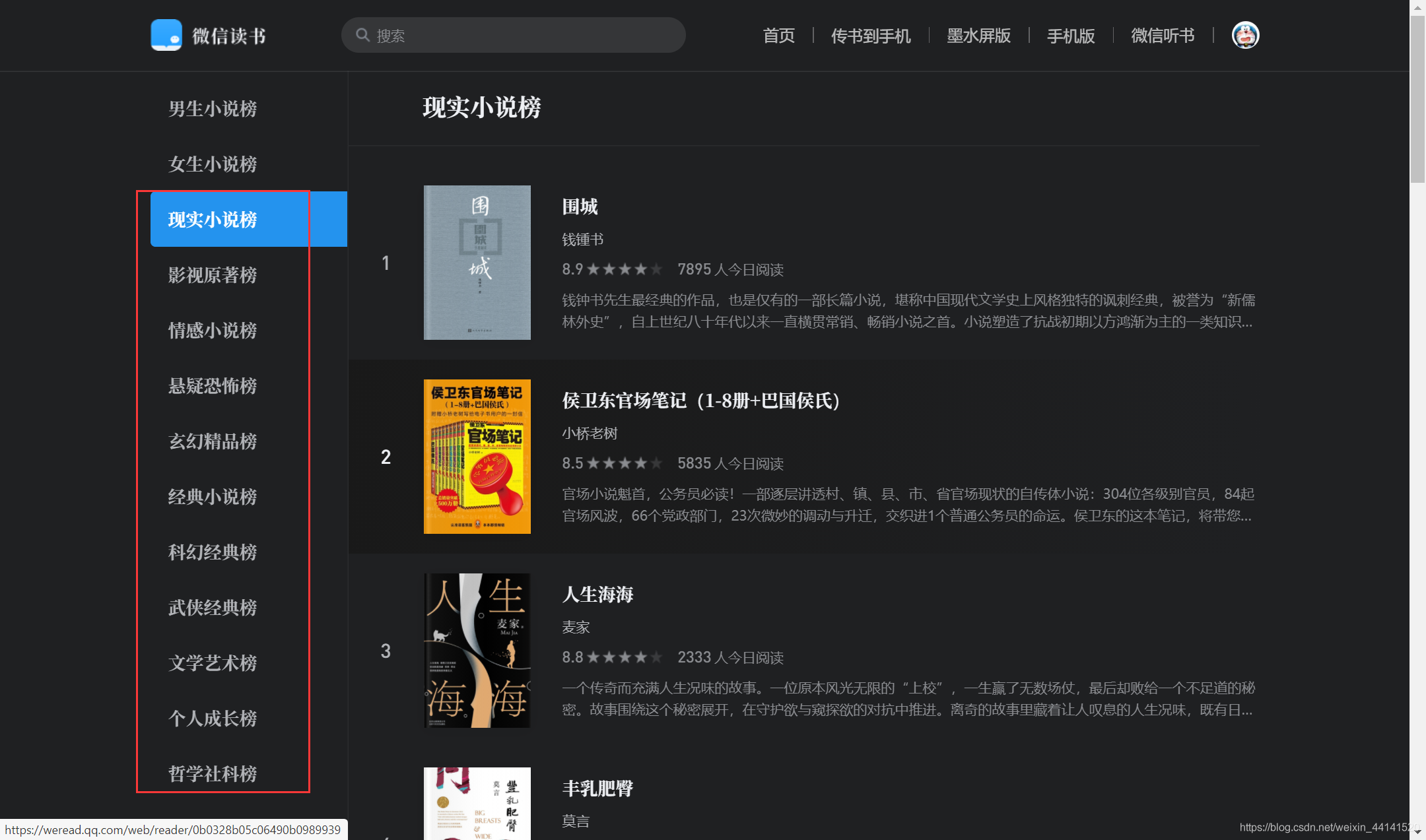
總共有17個專欄(除男生小說榜、女生小說榜),首先看一下這17個專欄頁面URL有什么規律,
https://weread.qq.com/web/category/100000
https://weread.qq.com/web/category/200000
https://weread.qq.com/web/category/300000
……
https://weread.qq.com/web/category/1700000
可以看出,每個鏈接之間只有最后的數字有區別,可以使用串列推導式來將這些鏈接保存在一個串列中,
page_urls = ['https://weread.qq.com/web/category/' + str(i * 100000) for i in range(1, 18)]
下面看一看每個頁面內部有什么細節,
右擊頁面,點擊檢查,然后重繪一下頁面,就發現了問題,
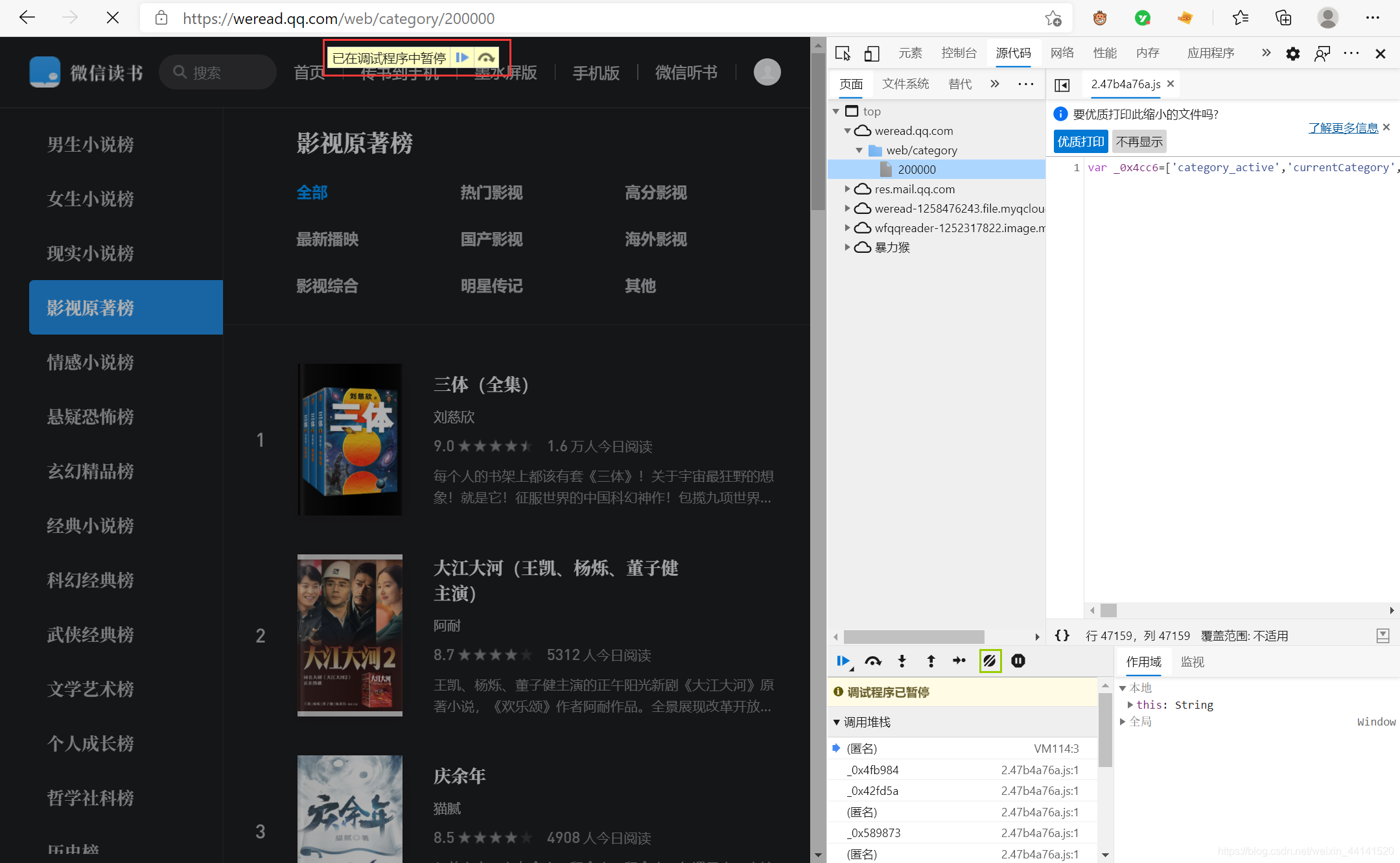
微信讀書這個頁面禁止了頁面除錯功能,可能是做了反爬蟲的考慮,防止我們查看,不過解決這個問題很簡單,點擊一下上圖中綠框中的按鈕,再重繪一下頁面就好了,
查看一下頁面源代碼,我們發現原始碼中只有前20本書的資訊,

再下拉頁面,發現達到第二十本書的時候會自動加載下面的書籍,可以斷言其他的書籍內容都是動態加載得到的,于是查看一下network下的XHR,果然發現每翻20本書都會動態加載一個檔案,
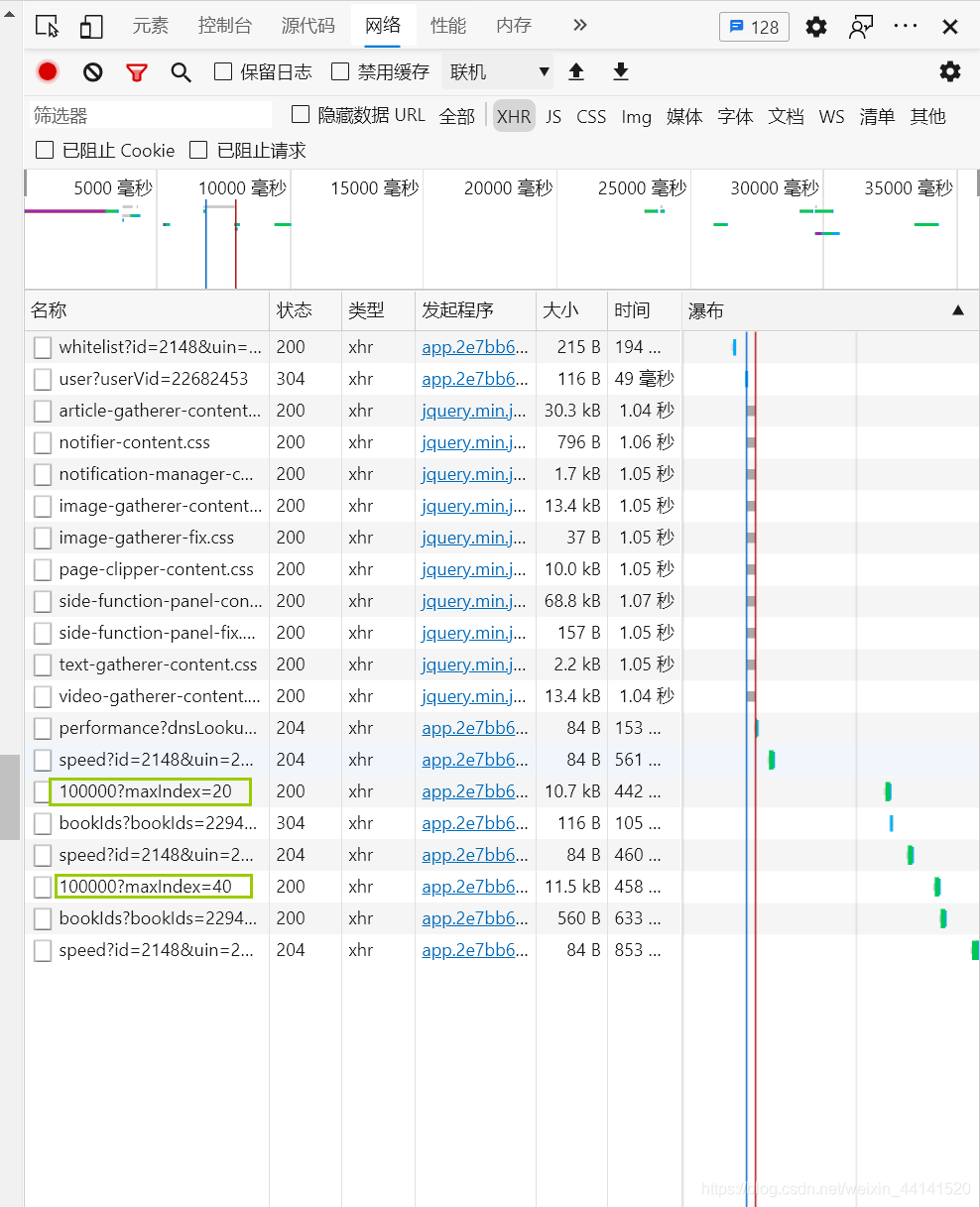
將回應的內容復制出來在https://www.bejson.com/格式化一下,發現后來加載的資訊果然在里面,

再來看一下這些動態加載出來的URL有什么特點,
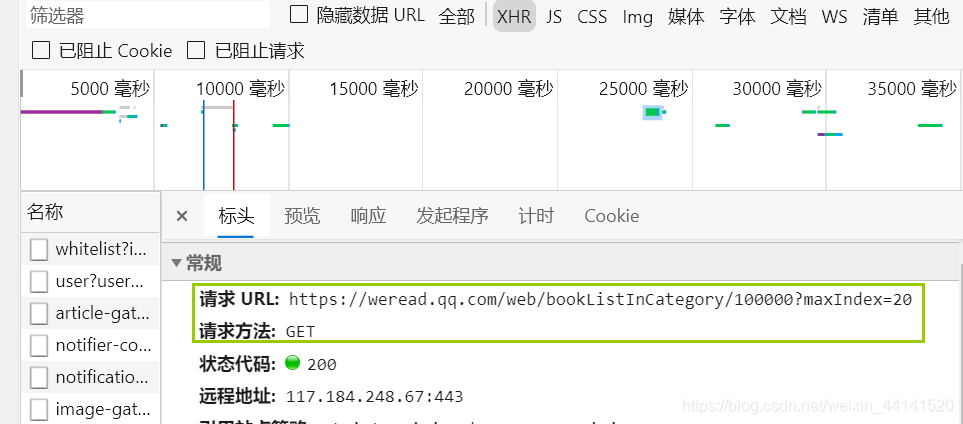
這是一個GET請求,每次加載的鏈接如下:
https://weread.qq.com/web/bookListInCategory/100000?maxIndex=20
https://weread.qq.com/web/bookListInCategory/100000?maxIndex=40
……
https://weread.qq.com/web/bookListInCategory/200000?maxIndex=20
https://weread.qq.com/web/bookListInCategory/200000?maxIndex=40
……
可以得知來自同一個頁面鏈接之間只有maxIndex=不同,依然可以通過串列推導式來將這些鏈接保存在一個串列中,
ajax_urls = ['https://weread.qq.com/web/bookListInCategory/{0}?maxIndex={1}'.format(i * 100000, j) for i in range(1, 18)
for j in range(20, 100, 20)]
2.頁面爬取和決議
上面我們已經得到了所有要爬取的鏈接,就可以通過requests庫來爬取資料了,由于有的資訊存在于頁面源代碼,有的是動態加載出來的,所以打算分開來爬取,并且page_urls中的內容利用xpath決議,ajax_urls中的內容利用正則運算式來決議,
先分析利用page_urls中URL爬取的資訊,這里打算獲取排名、書名、作者、評分、今日閱讀人數、簡介6個資訊,分別復制每個資料的xpath如下:
//*[@id="routerView"]/div[2]/ul/li[1]/div[1]/p
//*[@id="routerView"]/div[2]/ul/li[1]/div[1]/div[2]/p[1]
//*[@id="routerView"]/div[2]/ul/li[1]/div[1]/div[2]/p[2]/a
//*[@id="routerView"]/div[2]/ul/li[1]/div[1]/div[2]/p[3]/span[1]
//*[@id="routerView"]/div[2]/ul/li[1]/div[1]/div[2]/p[3]/span[4]/em
//*[@id="routerView"]/div[2]/ul/li[1]/div[1]/div[2]/p[4]
上面是第一本書的6個資訊的xpath,我們可以從頁面源代碼看出每本書的內容都在同一個ul下的li標簽內,所以只需要將所有的li[1]改成li,然后通過/text()獲取其中的文本內容就可以獲取20本書的內容了,修改后的xpath如下:
//*[@id="routerView"]/div[2]/ul/li/div[1]/p/text()
//*[@id="routerView"]/div[2]/ul/li/div[1]/div[2]/p[1]/text()
//*[@id="routerView"]/div[2]/ul/li/div[1]/div[2]/p[2]/a/text()
//*[@id="routerView"]/div[2]/ul/li/div[1]/div[2]/p[3]/span[1]/text()
//*[@id="routerView"]/div[2]/ul/li/div[1]/div[2]/p[3]/span[4]/em/text()
//*[@id="routerView"]/div[2]/ul/li/div[1]/div[2]/p[4]/text()
再分析動態加載的資料,分析結果如圖:
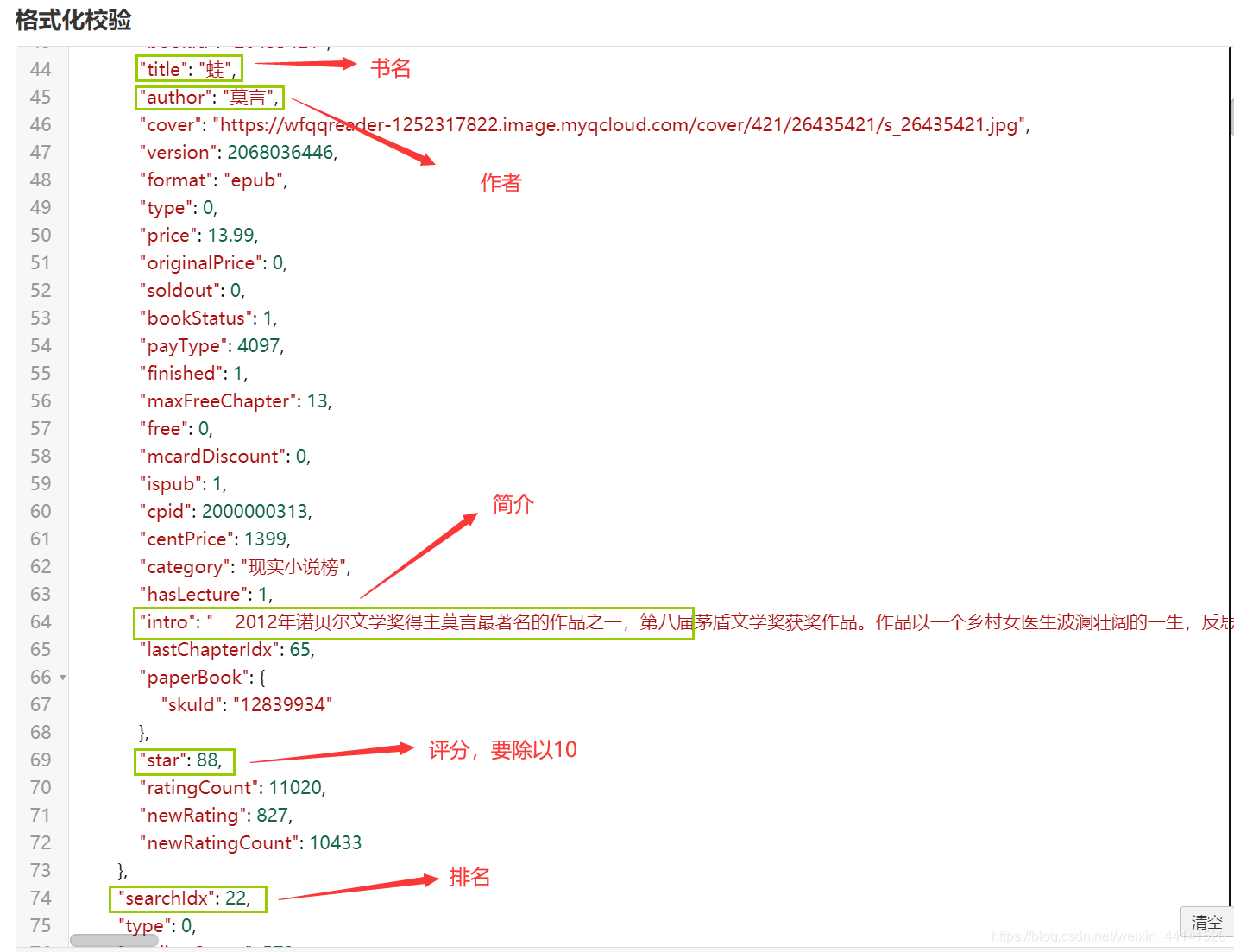

這個很適合使用正則運算式來決議,如下:
index_path = re.compile('"searchIdx":(\d+)')
name_path = re.compile('"title":"(.*?)"')
author_path = re.compile('"author":"(.*?)"')
score_path = re.compile('"star":(\w+)')
number_path = re.compile('"readingCount":(\d+)')
info_path = re.compile('"intro":"(.*?)"', re.S)
3.資料保存到Excel
代碼如下:
class save_excel:
def __init__(self):
self.book = xlwt.Workbook(encoding='utf-8') # 創建workbook物件
self.savepath = "微信讀書Top100.xls"
def writeData1(self, data):
'''
建立sheet表,寫入data1資料
'''
sheet = self.book.add_sheet('微信讀書top100_%s' % data[-1], cell_overwrite_ok=True) # True為每次覆寫以前內容
col = ('id', '書名', '作者', '評分', '閱讀人數', '概況')
for i in range(0, len(col)): # 寫列名
print("寫%d列" % i)
sheet.write(0, i, col[i])
for j in range(0, len(data[i])):
sheet.write(j + 1, i, data[i][j])
def writeData2(self, data):
'''
追加data2資料
'''
sheet = self.book.get_sheet('微信讀書top100_%s' % data[-2])
for i in range(0, 6): # 寫列名
for j in range(int(data[-1]), int(data[-1]) + len(data[i])):
sheet.write(j + 1, i, data[i][j - int(data[-1])])
def saveData(self):
'''
保存到檔案savepath路徑
'''
self.book.save(self.savepath)
4.設定多執行緒
由于要爬取和決議的內容很多,所以設定多執行緒來加速程式的執行,并構造執行緒安全的佇列Queue,代碼如下:
class spider1(threading.Thread):
def __init__(self, page_queue, lock, *args, **kwargs):
super(spider1, self).__init__(*args, **kwargs)
self.page_queue = page_queue
def run(self):
if self.page_queue.empty() != True:
data1 = crawl_and_parse.spider1()
save_excel.writeData1(data1)
else:
return
class spider2(threading.Thread):
def __init__(self, ajax_queue, lock, *args, **kwargs):
super(spider2, self).__init__(*args, **kwargs)
self.ajax_queue = ajax_queue
def run(self):
if self.ajax_queue.empty() != True:
data2 = crawl_and_parse.spider2()
save_excel.writeData2(data2)
else:
return
if __name__ == '__main__':
page_queue = queue.Queue(17)
ajax_queue = queue.Queue(200)
lock = threading.Lock()
save_excel = save_excel()
crawl_and_parse = crawl_and_parse(page_queue, ajax_queue, lock)
for page_url in page_urls:
page_queue.put(page_url)
for ajax_url in ajax_urls:
ajax_queue.put(ajax_url)
for i in range(20):
th1 = spider1(page_queue, lock, name="爬蟲1執行緒%d" % i)
thread_list.append(th1)
for j in range(200):
th2 = spider2(ajax_queue, lock, name="爬蟲2執行緒%d" % j)
thread_list.append(th2)
for t in thread_list:
t.start()
t.join()
5.全部代碼
# -*- coding = utf-8 -*-
# @Time: 2021/2/16 11:10
# @File: spider.py
# @Software: PyCharm
import requests
import threading
import random
import queue
from lxml import etree
import re
import xlwt
import time
page_urls = ['https://weread.qq.com/web/category/' + str(i * 100000) for i in range(1, 18)]
ajax_urls = ['https://weread.qq.com/web/bookListInCategory/{0}?maxIndex={1}'.format(i * 100000, j) for i in range(1, 18)
for j in range(20, 100, 20)]
USER_AGENT = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0)",
"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Maxthon 2.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; TencentTraveler 4.0)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; The World)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Avant Browser)",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)",
]
user_agent = random.choice(USER_AGENT)
headers = {
'User-Agent': user_agent
}
index_path = re.compile('"searchIdx":(\d+)')
name_path = re.compile('"title":"(.*?)"')
author_path = re.compile('"author":"(.*?)"')
score_path = re.compile('"star":(\w+)')
number_path = re.compile('"readingCount":(\d+)')
info_path = re.compile('"intro":"(.*?)"', re.S)
thread_list = []
class save_excel:
def __init__(self):
self.book = xlwt.Workbook(encoding='utf-8') # 創建workbook物件
self.savepath = "微信讀書Top100.xls"
def writeData1(self, data):
'''
建立sheet表,寫入data1資料
'''
sheet = self.book.add_sheet('微信讀書top100_%s' % data[-1], cell_overwrite_ok=True) # True為每次覆寫以前內容
col = ('id', '書名', '作者', '評分', '閱讀人數', '概況')
for i in range(0, len(col)): # 寫列名
print("寫%d列" % i)
sheet.write(0, i, col[i])
for j in range(0, len(data[i])):
sheet.write(j + 1, i, data[i][j])
def writeData2(self, data):
'''
追加data2資料
'''
sheet = self.book.get_sheet('微信讀書top100_%s' % data[-2])
for i in range(0, 6): # 寫列名
for j in range(int(data[-1]), int(data[-1]) + len(data[i])):
sheet.write(j + 1, i, data[i][j - int(data[-1])])
def saveData(self):
'''
保存到檔案savepath路徑
'''
self.book.save(self.savepath)
class crawl_and_parse:
def __init__(self, page_queue, ajax_queue, lock):
self.page_queue = page_queue
self.ajax_queue = ajax_queue
self.lock = lock
def spider1(self):
'''
輸入:page_queue.get()
--------------------------
爬取:requests.get
決議:xpath語法
--------------------------
回傳一個串列檔案data1
'''
data1 = []
self.lock.acquire()
page_url = self.page_queue.get()
print(page_url)
self.lock.release()
req1 = requests.get(page_url, headers=headers)
page_text = req1.text
html = etree.HTML(page_text)
index_s = html.xpath('//*[@id="routerView"]/div[2]/ul/li/div[1]/p/text()')
data1.append(index_s)
names = html.xpath('//*[@id="routerView"]/div[2]/ul/li/div[1]/div[2]/p[1]/text()')
data1.append(names)
authors = html.xpath('//*[@id="routerView"]/div[2]/ul/li/div[1]/div[2]/p[2]/a/text()')
data1.append(authors)
scores = html.xpath('//*[@id="routerView"]/div[2]/ul/li/div[1]/div[2]/p[3]/span[1]/text()')
data1.append(scores)
numbers = html.xpath('//*[@id="routerView"]/div[2]/ul/li/div[1]/div[2]/p[3]/span[4]/em/text()')
data1.append(numbers)
infos = html.xpath('//*[@id="routerView"]/div[2]/ul/li/div[1]/div[2]/p[4]/text()')
data1.append(infos)
search = page_url.split('/')[-1]
data1.append(search)
return data1
def spider2(self):
'''
輸入:ajax_queue.get()
--------------------------
爬取:requests.get
決議:re正則運算式語法
--------------------------
回傳一個串列檔案data2
'''
data2 = []
self.lock.acquire()
ajax_url = self.ajax_queue.get()
print(ajax_url)
self.lock.release()
req2 = requests.get(ajax_url, headers=headers)
resp = req2.text
index_s = re.findall(index_path, resp)
data2.append(index_s)
names = re.findall(name_path, resp)
data2.append(names)
authors = re.findall(author_path, resp)
data2.append(authors)
scores = re.findall(score_path, resp)
scores_convert = []
for score in scores:
score = str(float(score) / 10)
scores_convert.append(score)
data2.append(scores_convert)
numbers = re.findall(number_path, resp)
data2.append(numbers)
infos = re.findall(info_path, resp)
data2.append(infos)
search = ajax_url.split('/')[-1].split('?')[0]
data2.append(search)
start_index = ajax_url.split('=')[-1]
data2.append(start_index)
return data2
class spider1(threading.Thread):
def __init__(self, page_queue, lock, *args, **kwargs):
super(spider1, self).__init__(*args, **kwargs)
self.page_queue = page_queue
def run(self):
if self.page_queue.empty() != True:
data1 = crawl_and_parse.spider1()
save_excel.writeData1(data1)
else:
return
class spider2(threading.Thread):
def __init__(self, ajax_queue, lock, *args, **kwargs):
super(spider2, self).__init__(*args, **kwargs)
self.ajax_queue = ajax_queue
def run(self):
if self.ajax_queue.empty() != True:
data2 = crawl_and_parse.spider2()
save_excel.writeData2(data2)
else:
return
if __name__ == '__main__':
start_time = time.time()
page_queue = queue.Queue(17)
ajax_queue = queue.Queue(200)
lock = threading.Lock()
save_excel = save_excel()
crawl_and_parse = crawl_and_parse(page_queue, ajax_queue, lock)
for page_url in page_urls:
page_queue.put(page_url)
for ajax_url in ajax_urls:
ajax_queue.put(ajax_url)
for i in range(20):
th1 = spider1(page_queue, lock, name="爬蟲1執行緒%d" % i)
thread_list.append(th1)
for j in range(200):
th2 = spider2(ajax_queue, lock, name="爬蟲2執行緒%d" % j)
thread_list.append(th2)
for t in thread_list:
t.start()
t.join()
save_excel.saveData()
end_time = time.time()
print('it costs {}s'.format(end_time - start_time))
我執行了一下,花費了27.73451066017151s,應該還有很多可以優化的點,
6.結果顯示

初學者,水平有限,有問題的地方懇求大佬們的指正,輕噴!!!希望這篇文章可以幫到大家,再會~~~~
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/260415.html
標籤:python