歡迎大家來到“Python從零到壹”,在這里我將分享約200篇Python系列文章,帶大家一起去學習和玩耍,看看Python這個有趣的世界,所有文章都將結合案例、代碼和作者的經驗講解,真心想把自己近十年的編程經驗分享給大家,希望對您有所幫助,文章中不足之處也請海涵,Python系列整體框架包括基礎語法10篇、網路爬蟲30篇、可視化分析10篇、機器學習20篇、大資料分析20篇、影像識別30篇、人工智能40篇、Python安全20篇、其他技巧10篇,您的關注、點贊和轉發就是對秀璋最大的支持,知識無價人有情,希望我們都能在人生路上開心快樂、共同成長,
前一篇文章講述了BeautifulSoup技術,它是一個可以從HTML或XML檔案中提取資料的Python庫,一個分析HTML或XML檔案的決議器,包括安裝程序和基礎語法,這篇文章將詳細講解 BeautifulSoup 爬取豆瓣TOP250電影,通過案例的方式讓大家熟悉Python網路爬蟲,同時豆瓣TOP250也是非常適合入門的案例,也能普及簡單的預處理知識, 希望對您有所幫助,本文參考了作者CSDN的文章,鏈接如下:
- https://blog.csdn.net/Eastmount
- https://github.com/eastmountyxz/Python-zero2one
同時,作者新開的“娜璋AI安全之家”將專注于Python和安全技術,主要分享Web滲透、系統安全、人工智能、大資料分析、影像識別、惡意代碼檢測、CVE復現、威脅情報分析等文章,雖然作者是一名技術小白,但會保證每一篇文章都會很用心地撰寫,希望這些基礎性文章對你有所幫助,在Python和安全路上與大家一起進步,
文章目錄
- 一.分析網頁DOM樹結構
- 1.分析網頁結構及簡單爬取
- 2.定位節點及網頁翻頁分析
- 二.爬取豆瓣電影資訊
- 三.鏈接跳轉分析及詳情頁面爬取
- 四.總結
前文賞析:
- [Python從零到壹] 一.為什么我們要學Python及基礎語法詳解
- [Python從零到壹] 二.語法基礎之條件陳述句、回圈陳述句和函式
- [Python從零到壹] 三.語法基礎之檔案操作、CSV檔案讀寫及面向物件
- [Python從零到壹] 四.網路爬蟲之入門基礎及正則運算式抓取博客案例
- [Python從零到壹] 五.網路爬蟲之BeautifulSoup基礎語法萬字詳解
- [Python從零到壹] 六.網路爬蟲之BeautifulSoup爬取豆瓣TOP250電影詳解
前文作者詳細介紹了BeautifulSoup技術,這篇文章主要結合具體實體進行深入分析,講述一個基于BeautifulSoup技術的爬蟲,爬取豆瓣排名前250部電影的資訊,主要內容包括:
- 分析網頁DOM樹結構
- 爬取豆瓣電影資訊串列
- 鏈接跳轉分析
- 爬取每部電影對應的詳細資訊
本文從實戰出發,讓讀者初步了解分析網頁結構方法并呼叫BeautifulSoup技術爬取網路資料,后面章節將進一步深入講解,
一.分析網頁DOM樹結構
1.分析網頁結構及簡單爬取
豆瓣(Douban)是一個社區網站,創立于2005年3月6日,該網站以書影音起家,提供關于書籍、電影、音樂等作品的資訊,其作品描述和評論都是由用戶提供(User-Generated Content,簡稱UGC),是Web 2.0網站中具有特色的一個網站,該網站提供了書影音推薦、線下同城活動、小組話題交流等多種服務功能,致力于幫助都市人群發現生活中有用的事物,
本文主要介紹BeautifulSoup技術爬取豆瓣電影排名前250名的電影資訊,第一部分將介紹分析網頁DOM樹結構,爬取豆瓣的地址為:
- https://movie.douban.com/top250?format=text
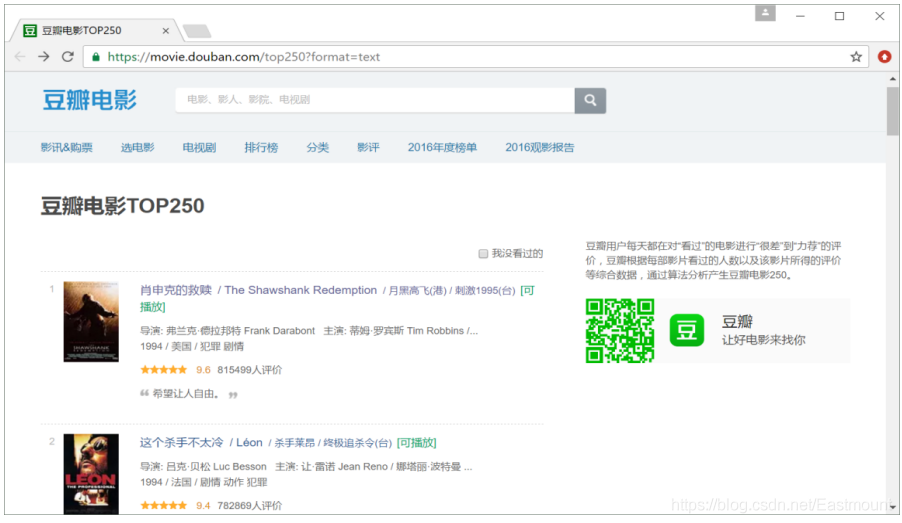
上圖中顯示了豆瓣熱門的250部電影的資訊,包括電影中文名稱、英文名稱、導演、主演、評分、評價數等資訊,接下來需要對其進行DOM樹結構分析,HTML網頁是以標簽對的形式出現,如< html >< /html >、< div >< /div >等,這種標簽對呈樹形結構顯示,通常稱為DOM樹結構,
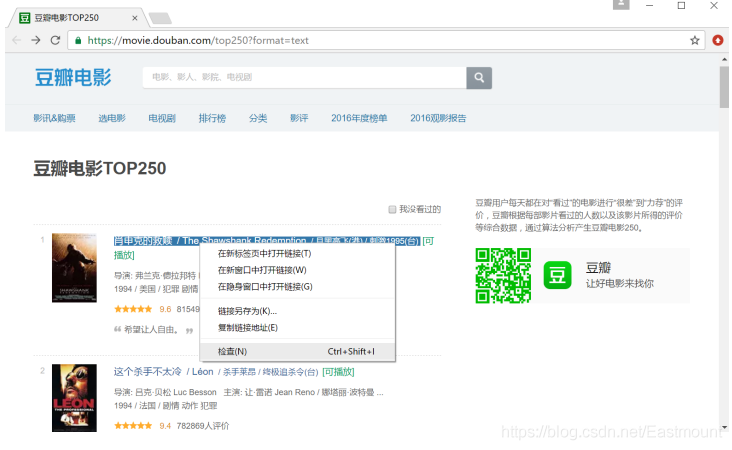
在得到一個網頁之后,我們需要結合瀏覽器對其進行元素分析,比如豆瓣電影網站,選中第一部電影《肖申克的救贖》,右鍵滑鼠“檢查”(Chrome瀏覽器稱為“檢查”,其他瀏覽器可能稱為“審查元素”等),如下圖2所示,
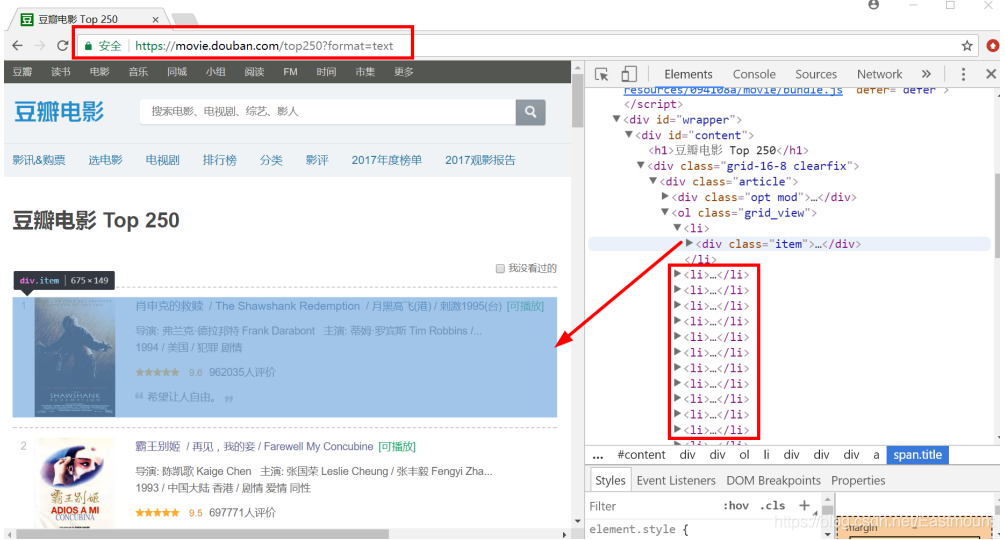
顯示結果如圖3所示,可以發現它是在< div class=”article” >< /div >路徑下,由很多個< li >< /li >組成,每一個< li >< /li >分別對應一部電影的資訊,其中,電影《肖申克的救贖》HTML中對應內容為:
<li><div class="item">......</div></li>
通過class值為“item”可以定位電影的資訊,呼叫BeautifulSoup擴展包的find_all(attrs={“class”:“item”}) 函式可以獲取其資訊,
對應的HTML部分代碼如下:
<li><div class="item">
<div class="pic">
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
<img alt="肖申克的救贖"src="https://img3.doubanio.com/.../p480747492.webp" >
</a>
</div>
<div class="info">...</div>
</div></li>
下面通過Python3代碼可以獲取電影的資訊,呼叫BeautifulSoup中的find_all()函式獲取< div class=’item’ >的資訊,其結果如圖4所示,
test01.py
# -*- coding:utf-8 -*-
# By:Eastmount CSDN
import urllib.request
import re
from bs4 import BeautifulSoup
# 爬蟲函式
def crawl(url, headers):
page = urllib.request.Request(url, headers=headers)
page = urllib.request.urlopen(page)
contents = page.read()
#print(contents)
soup = BeautifulSoup(contents, "html.parser")
print('豆瓣電影250: 序號 \t影片名\t 評分 \t評價人數')
for tag in soup.find_all(attrs={"class":"item"}):
content = tag.get_text()
content = content.replace('\n','') #洗掉多余換行
print(content, '\n')
# 主函式
if __name__ == '__main__':
url = 'http://movie.douban.com/top250?format=text'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
crawl(url, headers)
運行結構如圖4所示,爬取了豆瓣Top250的第一頁電影的資訊,包括序號、影片名、導演及主演資訊、評分、評價人數等,

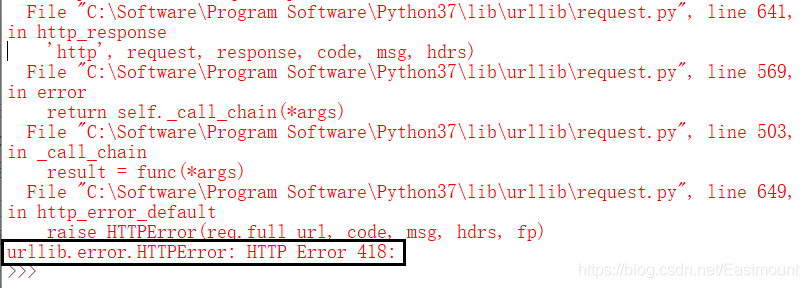
注意:urllib.error.HTTPError: HTTP Error 418
如果直接使用urllib.request.urlopen(url)會提示該錯誤,這是因為爬蟲被攔截,需要模擬瀏覽器訪問,這里可以打開瀏覽器按下F12,找到對應Headers內容,然后在Python代碼中設定User-Agent即可模擬該瀏覽器請求,
urlopen()函式:
- Python2:urllib2.urlopen(url)
- Python3:urllib.request.urlopen(url)
- urlopen()函式用于創建一個表示遠程url的類檔案物件,然后像操作本地檔案一樣操作這個類檔案物件來獲取遠程資料
read()函式:
- 呼叫read()讀取網頁內容并賦值給contents變數
BeautifulSoup函式:
- soup = BeautifulSoup(contents, “html.parser”)
- 呼叫BeautifulSoup決議所抓取網頁原始碼的DOM樹結構
find_all()函式:
- 呼叫BeautifulSoup的find_all()函式獲取屬性class為“item”的所有值,并呼叫代碼content.replace(’\n’,’’)將換行符替換為空值,從而實作洗掉多余換行,最后回圈輸出結果,
2.定位節點及網頁翻頁分析
通過前一部分我們獲取了電影的簡介資訊,但是這些資訊是融合在一起的,而在資料分析時,通常需要將某些具有使用價值的資訊提取出來,并存盤至陣列、串列或資料庫中,比如電影名稱、演員資訊、電影評分等特征,
作者簡單歸納了兩種常見的方法:
- (1) 文本分析,從獲取的電影簡介文本資訊中提取某些特定的值,通常采用字串處理方法進行提取,
- (2) 節點定位,在寫爬蟲程序中定位相關節點,然后進行爬取所需節點操作,最后賦值給變數或存盤到資料庫中,
本部分將結合BeautifulSoup技術,采用節點定位方法獲取具體的值,點開HTML網頁,檢查對應的< li >< /li >節點,可以看到該電影的構成情況,再定位節點內容,如< span class=“title” >節點可以獲取標題,< div class=“star” >節點可以獲取電影評分和評價人數,
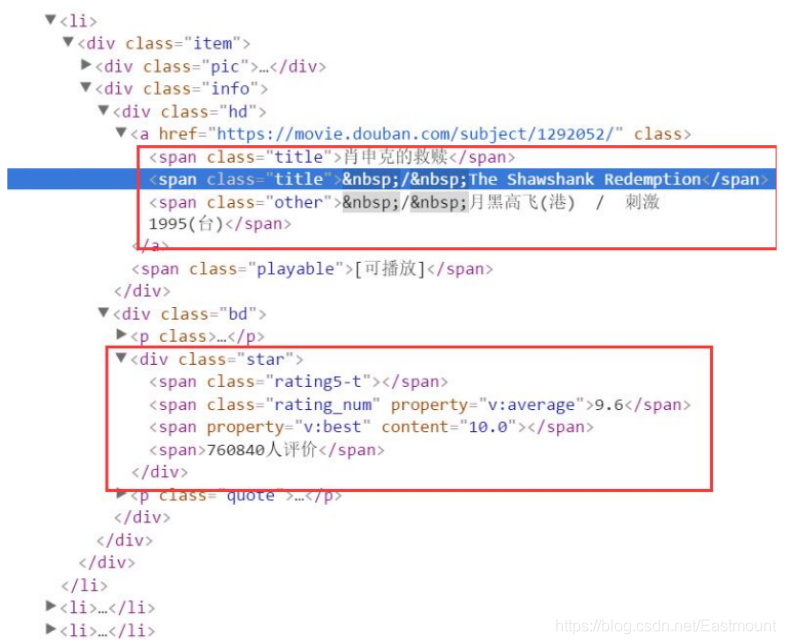
獲取節點的核心代碼如下,定位class屬性為“item”的div布局后,再呼叫find_all()函式查找class屬性為title的標簽,并獲取第一個值輸出,即title[0],接著呼叫find()函式爬取評分資訊,通過get_text()函式獲取內容,
for tag in soup.find_all(attrs={"class":"item"}):
title = tag.find_all(attrs={"class":"title"}) #電影名稱
info = tag.find(attrs={"class":"star"}).get_text() #爬取評分和評論數
print(title[0])
print(info.replace('\n',''))
# <span class="title">肖申克的救贖</span>
# 9.72279813人評價

講到這里,我們第一頁的25部電影資訊就爬取成功了,而該網頁共10頁,每頁顯示25部電影,如何獲取這250部完整的電影資訊呢?這就涉及到鏈接跳轉和網站的翻頁分析,網站的翻頁分析通常有四種方法:
- 點擊下一頁分析url網址,分析它們之間的規律,這種方法的網站通常采用GET方法進行傳值,而有的網站采用區域重繪技術,翻頁后的url仍然不變,
- 獲取“下一頁”或頁碼的超鏈接,再依次呼叫urllib2.urlopen(url)函式訪問URL并實作網頁跳轉,
- 分析網站Networks提交請求的引數,通過Python設定引數實作翻頁,常用于POST表單,
- 采用網頁自動操作技術,獲取下一頁按鈕或超鏈接進行自動點擊跳轉,如selenium技術中的滑鼠點擊事件,
本文主要采用第一種分析方法,后面講述Selenium技術時,會介紹滑鼠模擬點擊事件操作的跳轉方法,

通過點擊圖6中的第2頁、第3頁、第10頁,我們可以看到網頁URL的變化如下,
第2頁URL:https://movie.douban.com/top250?start=25&filter=
第3頁URL:https://movie.douban.com/top250?start=50&filter=
第10頁URL:https://movie.douban.com/top250?start=225&filter=
它是存在一定規律的,top250?start=25表示獲取第2頁(序號為26到50號)的電影資訊;top250?start=50表示獲取第3頁(序號為51到75號)的電影資訊,依次類推,我們寫一個回圈即可獲取完整的250部電影資訊,核心代碼如下:
i = 0
while i<10:
num = i*25 #每次顯示25部 URL序號按25增加
url = 'https://movie.douban.com/top250?start=' + str(num) + '&filter='
crawl(url)
i = i + 1
注意:當i初始值為0,num值為0,獲取第1頁資訊;當i增加為1,num值為25,獲取第2頁資訊;當i增加為9,num值為225,獲取第10頁的資訊,
講到這里,爬取豆瓣網電影資訊的DOM樹結構分析、網頁鏈接跳轉已經分析完成,下一小節是講解完整的代碼,
二.爬取豆瓣電影資訊
完整代碼為test02.py檔案,如下所示,
test02.py
# -*- coding: utf-8 -*-
# By:Eastmount CSDN
import urllib.request
import re
from bs4 import BeautifulSoup
import codecs
#-------------------------------------爬蟲函式-------------------------------------
def crawl(url, headers):
page = urllib.request.Request(url, headers=headers)
page = urllib.request.urlopen(page)
contents = page.read()
soup = BeautifulSoup(contents, "html.parser")
infofile.write("")
print('爬取豆瓣電影250: \n')
for tag in soup.find_all(attrs={"class":"item"}):
#爬取序號
num = tag.find('em').get_text()
print(num)
infofile.write(num + "\r\n")
#電影名稱
name = tag.find_all(attrs={"class":"title"})
zwname = name[0].get_text()
print('[中文名稱]', zwname)
infofile.write("[中文名稱]" + zwname + "\r\n")
#網頁鏈接
url_movie = tag.find(attrs={"class":"hd"}).a
urls = url_movie.attrs['href']
print('[網頁鏈接]', urls)
infofile.write("[網頁鏈接]" + urls + "\r\n")
#爬取評分和評論數
info = tag.find(attrs={"class":"star"}).get_text()
info = info.replace('\n',' ')
info = info.lstrip()
print('[評分評論]', info)
#獲取評語
info = tag.find(attrs={"class":"inq"})
if(info): #避免沒有影評呼叫get_text()報錯
content = info.get_text()
print('[影評]', content)
infofile.write(u"[影評]" + content + "\r\n")
print('')
#-------------------------------------主函式-------------------------------------
if __name__ == '__main__':
#存盤檔案
infofile = codecs.open("Result_Douban.txt", 'a', 'utf-8')
#訊息頭
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
#翻頁
i = 0
while i<10:
print('頁碼', (i+1))
num = i*25 #每次顯示25部 URL序號按25增加
url = 'https://movie.douban.com/top250?start=' + str(num) + '&filter='
crawl(url, headers)
infofile.write("\r\n\r\n")
i = i + 1
infofile.close()
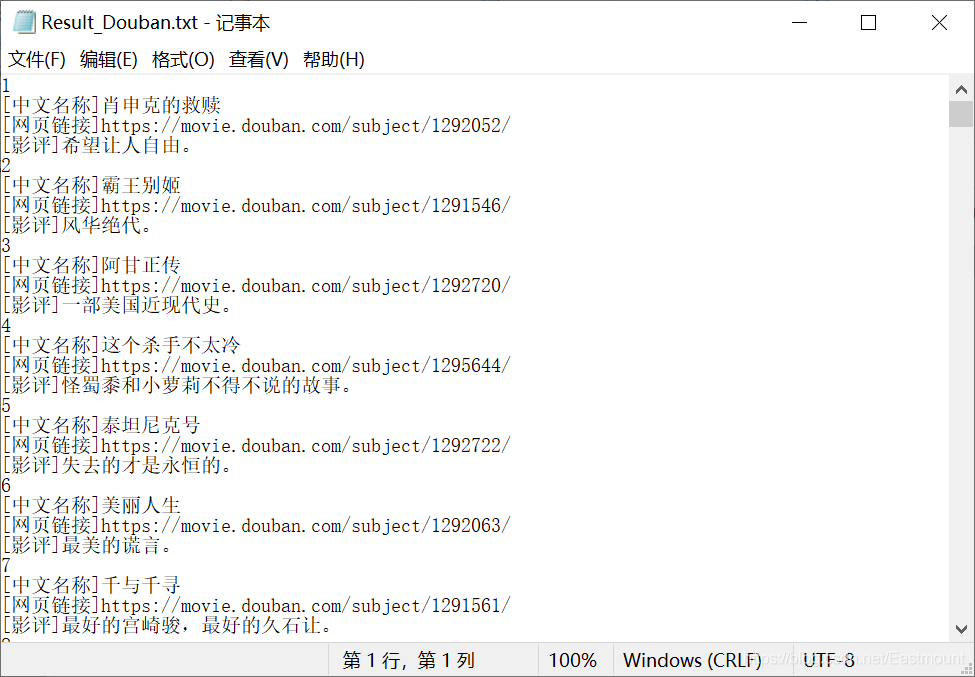
運行結果如圖7所示,爬取了電影名稱、網頁連接、評分評論數和影評等資訊,

并且將爬取的250部電影資訊存盤到“Result_Douban.txt”檔案中,如下圖所示,
在代碼中,主函式定義回圈依次獲取不同頁碼的URL,然后呼叫crawl(url)函式對每頁的電影資訊進行定向爬取,在crawl(url)函式中,通過urlopen()函式訪問豆瓣電影網址,然后呼叫BeautifulSoup函式進行HTML分析,前面第一部分講解了每部電影都位于< li >< div class=“item” >…< /div >< /li >節點下,故采用如下for回圈依次定位到每部電影,然后再進行定向爬取,
for tag in soup.find_all(attrs={"class":"item"}):
#分別爬取每部電影具體的資訊
具體方法如下,
(1) 獲取序號
序號對應的HTML原始碼如圖8所示,需要定位到< em class >1< /em >節點,通過find(‘em’)函式獲取具體的內容,

對應的代碼如下:
num = tag.find('em').get_text()
print(num)
(2) 獲取電影名稱
電影名稱對應的HTML原始碼如圖9所示,包括class='title’對應中文名稱和英文名稱,class='other’對應電影其他名稱,
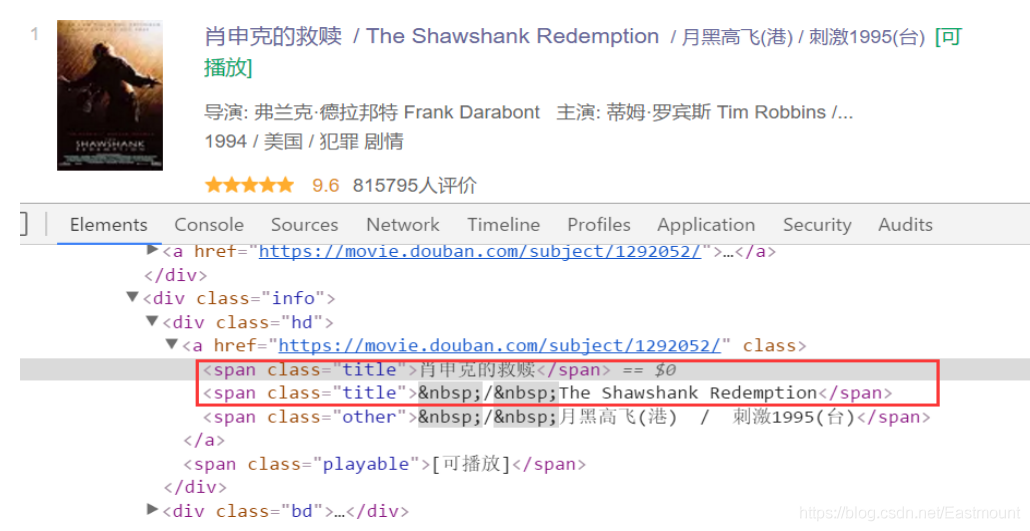
對應的代碼如下,因為HTML中包含兩個title,即< span class=‘title’ >< /span >,所以使用下面的函式獲取兩個標題:
- tag.find_all(attrs={“class”:“title”})
但這里我們僅需要中文標題,則直接通過變數name[0]獲取其第一個值,即為中文名稱,再呼叫get_text()函式獲取其內容,
name = tag.find_all(attrs={"class":"title"})
zwname = name[0].get_text()
print('[中文名稱]', zwname)
infofile.write("[中文名稱]" + zwname + "\r\n")
同時,上述代碼呼叫codecs庫進行了檔案處理,其中檔案操作的核心代碼如下,打開檔案三個引數分別是:檔案名、讀寫方式、編碼方式,此處檔案名為“Result_Douban.txt”,采用檔案寫方式(a),編碼方式是utf-8,
infofile = codecs.open("Result_Douban.txt", 'a', 'utf-8') #打開檔案
infofile.write(num+" "+name+"\r\n") #寫檔案
infofile.close() #關閉檔案
3.獲取電影鏈接
電影鏈接對應的HTML原始碼如上圖9所示,定位到< div class=‘hd’ >節點下的< a >< /a >節點,然后獲取屬性位href的值,即:attrs[‘href’],
url_movie = tag.find(attrs={"class":"hd"}).a
urls = url_movie.attrs['href']
print('[網頁鏈接]', urls)
獲取評分和內容的方法一樣,呼叫函式即可獲取:
- find(attrs={“class”:“star”}).get_text()
但是存在一個問題,它輸出的結果將評分數和評價數放在了一起,如“9.4 783221人評價”,而通常在做分析的時候,我們是將評分數存在一個變數中,評價數存在另一變數中,
這就需要進行簡單的文本處理,這里推薦大家使用前面講述過的正則運算式來處理,將此段代碼修改如下,呼叫re.compile(r’\d+.?\d*’)獲取字串中的數字,第一個數字為電影的分數,第二個數字為評論數,
#爬取評分和評論數
info = tag.find(attrs={"class":"star"}).get_text()
info = info.replace('\n',' ')
info = info.lstrip()
print(info)
mode = re.compile(r'\d+\.?\d*') #正則運算式獲取數字
print(mode.findall(info))
i = 0
for n in mode.findall(info):
if i==0:
print('[分數]', n)
infofile.write("[分數]" + n + "\r\n")
elif i==1:
print('[評論]', n)
infofile.write(u"[評論]" + n + "\r\n")
i = i + 1
獲取的結果前后對比如圖10所示,

這樣,整個豆瓣250部電影資訊就爬取成功了,接下來,我們再繼續深入,去到具體的每個網頁中,爬取詳細資訊及更多的評論,同時,作者更推崇的是本文講解的分析方法,只有知道了具體的方法才能解決具體的問題,
三.鏈接跳轉分析及詳情頁面爬取
在第二部分我們詳細分析了如何爬取豆瓣前250部電影資訊,同時爬取了每部電影對應詳細頁面的超鏈接,本小節主要結合每部電影的超鏈接url網站,定位到具體的電影頁面,進行深一步的詳情頁面爬取,這里作者還是采用電影《肖申克的救贖》舉例,前面爬取了該電影的超鏈接地址為:
- https://movie.douban.com/subject/1292052/
該網頁打開如圖11所示,

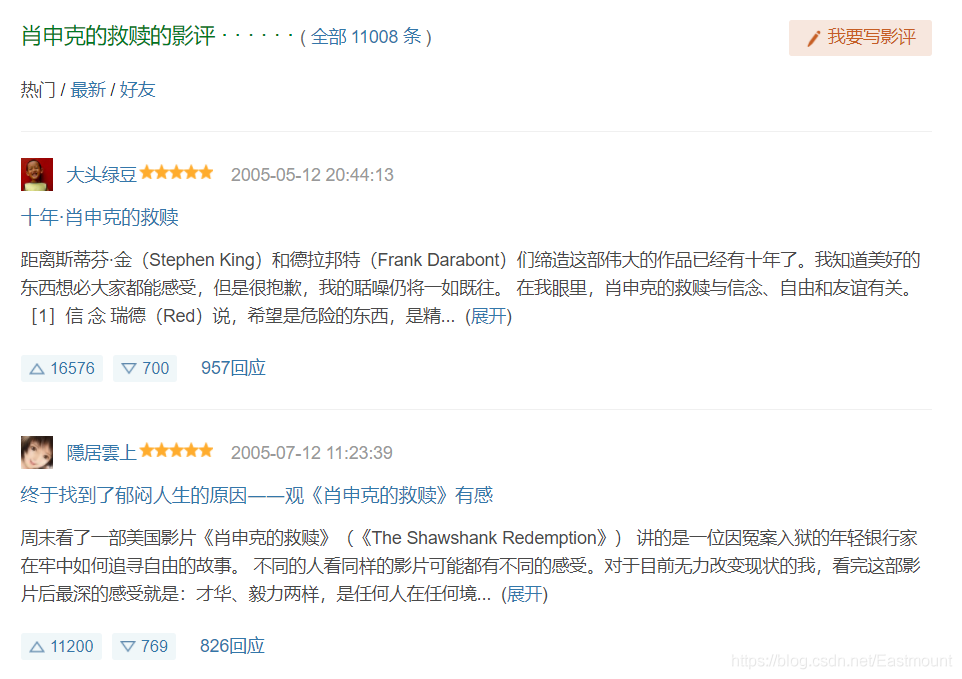
作者主要分析如何爬取該部電影的導演資訊、電影簡介資訊以及熱門影評資訊,其中影評資訊如圖12所示,
1.爬取詳情頁面基本資訊
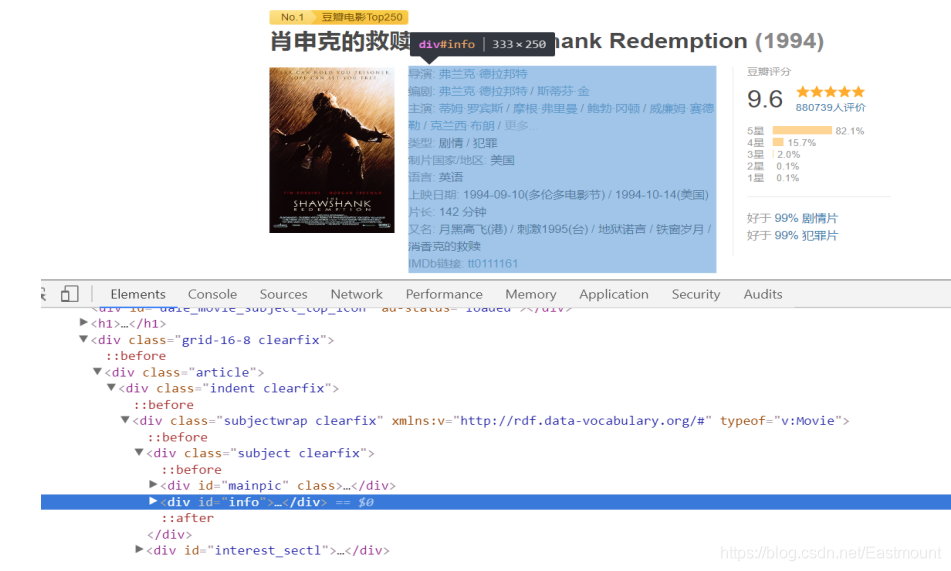
下面對詳情頁面進行DOM樹節點分析,其基本資訊位于< div class=‘article’ >…< /div >標簽下,核心內容位于該節點下的子節點中,即< div id=‘info’ >…< /div >,使用如下代碼獲取內容:
info = soup.find(attrs={"id":"info"})
print(info.get_text())
2.爬取詳情頁面電影簡介
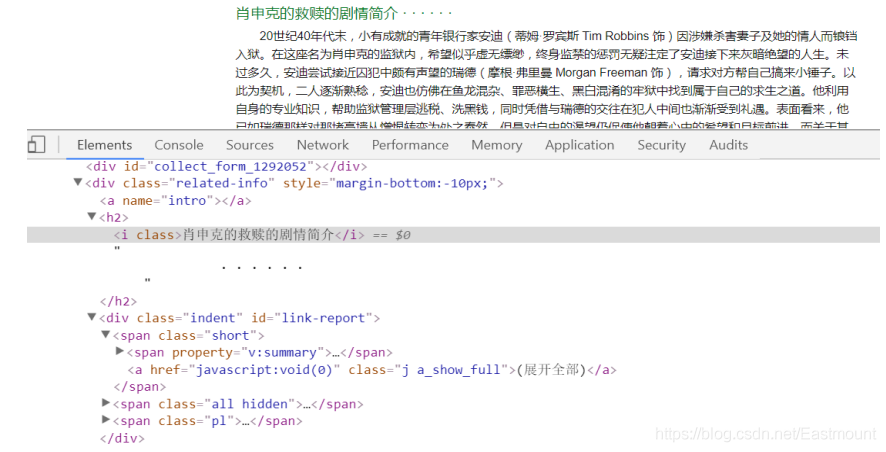
同樣,通過瀏覽器審查元素,可以得到如圖14所示的電影簡介HTML原始碼,其電影簡介位于< div class=‘related-info’ >…< /div >節點下,它包括簡短版(short)的簡介和隱藏的詳細版簡介(all_hidden),這里作者通過下列函式獲取,代碼replace(’\n’,’’).replace(’ ‘,’’)用于過濾所爬取HTML中多余的空格和換行符號,
other = soup.find(attrs={"class":"related-info"}).get_text()
print other.replace('\n','').replace(' ','') #過濾空格和換行
3.爬取詳情頁面電影熱門評論資訊
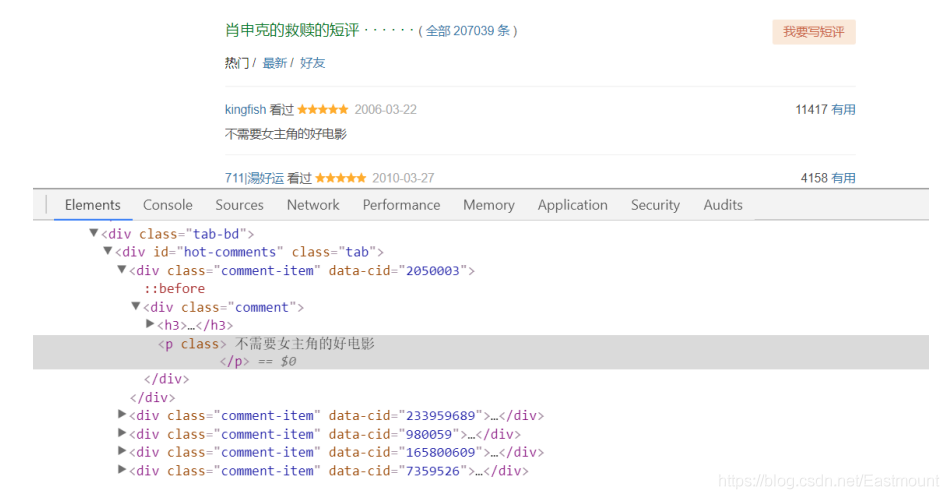
熱門評論資訊位于< div id=‘hot-comments’ >…< /div >節點下,然后獲取節點下的多個class屬性為“comment-item”的div布局,如下圖所示,在使用find()或find_all()函式進行爬取時,需要注意標簽屬性是class還是id,或是其它,必須與之對應一致,才能正確爬取,
#評論
print('\n評論資訊:')
for tag in soup.find_all(attrs={"id":"hot-comments"}):
for comment in tag.find_all(attrs={"class":"comment-item"}):
com = comment.find("p").get_text() #爬取段落p
print com.replace('\n','').replace(' ','')
完整代碼如下:
test03.py
# -*- coding: utf-8 -*-
# By:Eastmount CSDN
import urllib.request
import re
from bs4 import BeautifulSoup
import codecs
#-----------------------------------爬取詳細資訊-------------------------------------
def getInfo(url, headers):
page = urllib.request.Request(url, headers=headers)
page = urllib.request.urlopen(page)
content = page.read()
soup = BeautifulSoup(content, "html.parser")
#電影簡介
print('電影簡介:')
info = soup.find(attrs={"id":"info"})
print(info.get_text())
other = soup.find(attrs={"class":"related-info"}).get_text()
print(other.replace('\n','').replace(' ',''))
#評論
print('\n評論資訊:')
for tag in soup.find_all(attrs={"id":"hot-comments"}):
for comment in tag.find_all(attrs={"class":"comment-item"}):
com = comment.find("p").get_text()
print(com.replace('\n','').replace(' ',''))
print("\n\n\n----------------------------------------------------------------")
#-------------------------------------爬蟲函式-------------------------------------
def crawl(url, headers):
page = urllib.request.Request(url, headers=headers)
page = urllib.request.urlopen(page)
contents = page.read()
soup = BeautifulSoup(contents, "html.parser")
for tag in soup.find_all(attrs={"class":"item"}):
#爬取序號
num = tag.find('em').get_text()
print(num)
#電影名稱
name = tag.find_all(attrs={"class":"title"})
zwname = name[0].get_text()
print('[中文名稱]', zwname)
#網頁鏈接
url_movie = tag.find(attrs={"class":"hd"}).a
urls = url_movie.attrs['href']
print('[網頁鏈接]', urls)
#爬取評分和評論數
info = tag.find(attrs={"class":"star"}).get_text()
info = info.replace('\n',' ')
info = info.lstrip()
#正則運算式獲取數字
mode = re.compile(r'\d+\.?\d*')
i = 0
for n in mode.findall(info):
if i==0:
print('[電影分數]', n)
elif i==1:
print('[電影評論]', n)
i = i + 1
#獲取評語
getInfo(urls, headers)
#-------------------------------------主函式-------------------------------------
if __name__ == '__main__':
#訊息頭
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) \
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
#翻頁
i = 0
while i<10:
print('頁碼', (i+1))
num = i*25 #每次顯示25部 URL序號按25增加
url = 'https://movie.douban.com/top250?start=' + str(num) + '&filter='
crawl(url, headers)
i = i + 1
其中爬取的《龍貓》電影資訊輸出如圖16所示,

講到這里,使用BeautifulSoup技術分析爬取豆瓣電影前250部電影資訊的實體已經講解完畢,但在實際爬取程序中可能由于某些頁面不存在會導致爬蟲停止,這時需要使用例外陳述句“try-except-finally”進行處理,
同時,爬取程序中需要結合自己所需資料進行定位節點,存盤至本地檔案中,也需要結合字串處理過濾一些多余的空格或換行,
四.總結
在學習網路爬蟲之前,讀者首先要掌握分析網頁節點、審查元素定位標簽,甚至是翻頁跳轉、URL分析等知識,然后才是通過Python、Java或C#實作爬蟲的代碼,本文作者結合自己多年的網路爬蟲開發經驗,深入講解了BeautifulSoup技術網頁分析并爬取了豆瓣電影資訊,讀者可以借用本章的分析方法,結合BeautifulSoup庫爬取所需的網頁資訊,并學會分析網頁跳轉,盡可能爬取完整的資料集,
同時,本章所爬取的內容是存盤至TXT檔案中的,讀者也可以嘗試著存盤至Excel、CSV、Json檔案中,甚至存盤至資料庫,這將為您后面的資料分析提供強大的資料支撐,資料處理起來更為方便,那么,Python究竟怎么將所爬取的文本存盤至資料庫呢?后續作者將帶給您答案,
該系列所有代碼下載地址:
- https://github.com/eastmountyxz/Python-zero2one
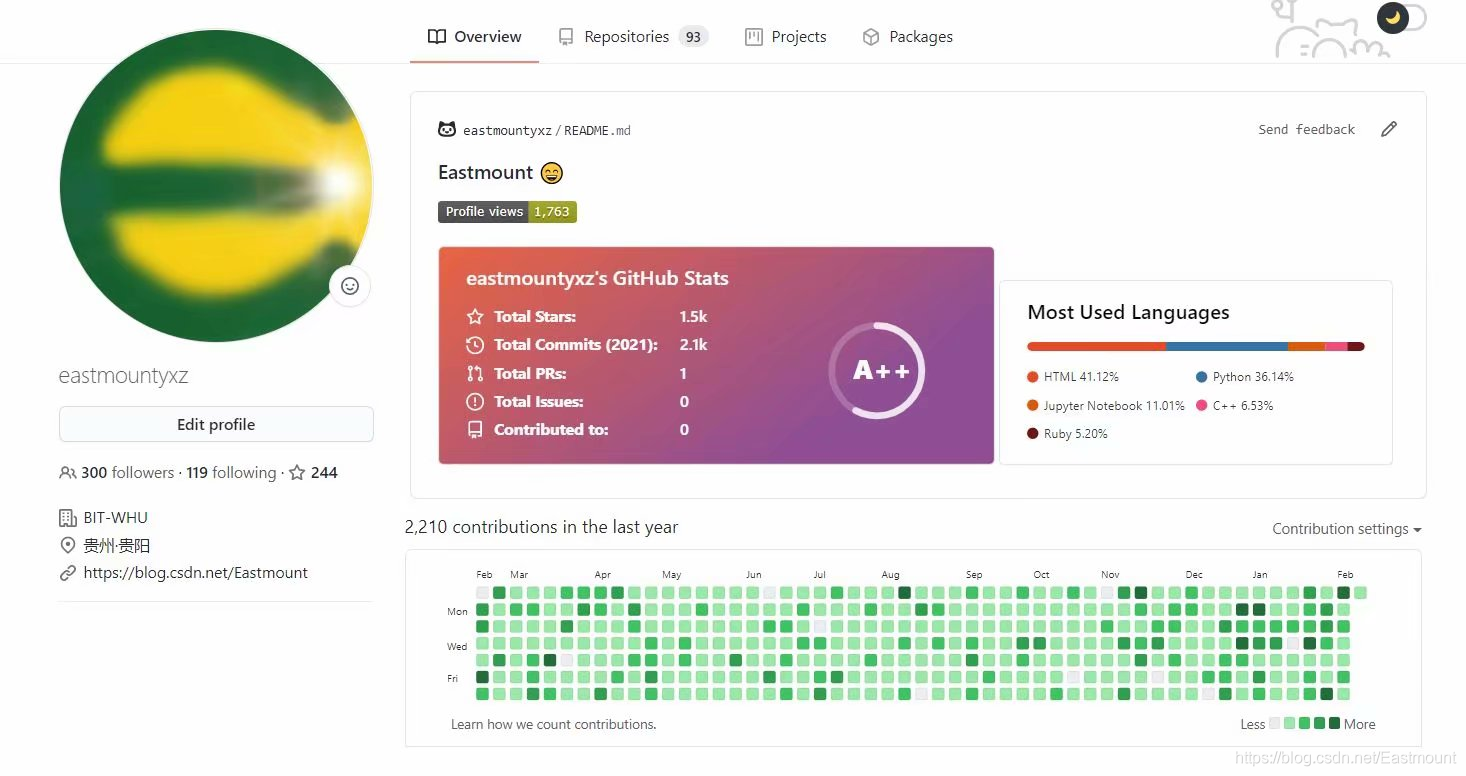
2020年在github的綠瓷磚終于貼完了第一年提交2100余次,獲得1500多+stars,開源93個倉庫,300個粉絲,挺開心的,希望自己能堅持在github打卡五年,督促自己不斷前行,簡單總結下,最滿意的資源是YQ爆發時,去年2月分享的輿情分析和情感分析,用這系列有溫度的代碼為武漢加油;最高贊的是Python影像識別系列,也獲得了第一位來自國外開發者的貢獻補充;最花時間的是Wannacry逆向系列,花了我兩月逆向分析,幾乎成為了全網最詳細的該蠕蟲分析;還有AI系列、知識圖譜實戰、CVE復現、APT報告等等,當然也存在很多不足之處,希望來年分享更高質量的資源,也希望能將安全和AI頂會論文系列總結進來,真誠的希望它們能幫助到大家,感恩有你,一起加油~
最后,真誠地感謝您關注“娜璋之家”公眾號,感謝CSDN這么多年的陪伴,會一直堅持分享,希望我的文章能陪伴你成長,也希望在技術路上不斷前行,文章如果對你有幫助、有感悟,就是對我最好的回報,且看且珍惜!2020年8月18日建立的公眾號,再次感謝您的關注,也請幫忙宣傳下“娜璋之家”,哈哈~初來乍到,還請多多指教,

(By:娜璋之家 Eastmount 2021-02-17 夜于貴陽 https://blog.csdn.net/Eastmount )
參考文獻如下:
- 作者書籍《Python網路資料爬取及分析從入門到精通》
- 作者博客:https://blog.csdn.net/Eastmount
- 北京豆網科技有限公司——豆瓣
- [python爬蟲] BeautifulSoup和Selenium對比爬取豆瓣Top250電影資訊 - Eastmount
- Crummy.com網站. BeautifulSoup 4.2.0檔案
- [python知識] 爬蟲知識之BeautifulSoup庫安裝及簡單介紹 - Eastmount
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/260594.html
標籤:python
上一篇:爬蟲實戰:爬取相親網站,看看當下年輕小姐姐的擇偶觀。
下一篇:day16 階段總結