?? 盡人事,聽天命,博主東南大學研究生在讀,熱愛健身和籃球,正在為兩年后的秋招準備中,樂于分享技術相關的所見所得,關注公眾號 @ 飛天小牛肉,第一時間獲取文章更新,成長的路上我們一起進步
?? 本文已收錄于 CS-Wiki(Gitee 官方推薦專案,現已 0.9k star),致力打造完善的后端知識體系,在技術的路上少走彎路,歡迎各位小伙伴前來交流學習
0. 前言
你知道當我們在網頁瀏覽器的地址欄中輸入 URL 時,Web 頁面是如何呈現的嗎?
Web 界面當然不會憑空出來,根據 Web 瀏覽器地址欄中指定的 URL,Web 使用一種名為 HTTP 的協議作為規范,完成從客戶端到服務端的一些流程,可以說,Web 是建立在 HTTP 協議上進行通信的,
1. HTTP 的誕生
其實,在 1983 年 3 月之前,互聯網還只屬于少數人,全世界的網民之間的資訊是無法共享的,在這一互聯網的黎明時期,HTTP 應運而生,
歐洲核子研究組織的 Tim Berners-Lee 博士提出了一種能夠讓遠隔兩地的網民共享知識的設想,最初的理念是:借助多檔案之間相互關聯的超文本(HyperTest),連成可相互參閱的 WWW(World Wide Web,萬維網),
現在已提出了 3 項 WWW 構建技術,分別是:
-
把 SGML(標準通用標記語言)作為頁面的文本標記語言 HTML
-
作為檔案傳遞協議的 HTTP
-
指定檔案所在地址的 URL
WWW 這一名稱,是 Web 瀏覽器當年用來瀏覽超文本的客戶端應用程式的名稱,現在用來表示這一系列的集合,也可簡稱為 Web,
2. 什么是 HTTP
說了這么多,大家只知道 HTTP 很牛逼,對 HTTP 是什么仍然沒有很直觀的概念,別急,在了解什么是 HTTP 之前,我們有必要知道超文本是什么,
HTTP 傳輸的內容就是超文本:
-
我們先來理解「文本」:在互聯網早期的時候只是簡單的字符文字,但隨著技術的發展,現在「文本」的涵義已經可以擴展為圖片、視頻、壓縮包等,在 HTTP 眼里這些都算做「文本」,
-
再來理解「超文本」:它就是超越了普通文本的文本,它是文字、圖片、視頻等的混合體,最關鍵有超鏈接,能從一個超文本跳轉到另外一個超文本,
HTML 就是最常見的超文本了,它本身只是純文字檔案,但內部用很多標簽定義了圖片、視頻等的鏈接,在經過瀏覽器的決議,呈現給我們的就是一個文字、有畫面的網頁了,
OK,下面我們正式介紹什么是 HTTP?
HTTP:超文本傳輸協議(HyperText Transfer Protocol)是當今互聯網上應用最為廣泛的一種網路協議,所有的 WWW(萬維網) 檔案都必須遵守這個標準,HTTP 和 TCP/IP 協議簇中的眾多協議一樣,用于客戶端和服務器端之間的通信,
3. 駐足不前的 HTTP
至今被世人廣泛使用的 HTTP 協議,仍然是 20 多年前的版本,也就是說,作為 Web 檔案傳輸協議的 HTTP,它的版本幾乎沒有更新,從另一方面來說,前人的智慧真的牛逼 ??
HTTP/0.9:HTTP 于 1990 年問世,功能簡陋,僅支持 GET 請求方式,并且僅能訪問 HTML 格式的資源,那時的 HTTP 并沒有作為正式的標準被建立,因此被被稱為 HTTP 0.9,
HTTP/1.0:1996 年 5 月 HTTP 正式作為標準被公布,版本號為 HTTP 1.0,在 0.9 版本上做了進步,增加了請求方式 POST 和 HEAD;不再局限于 0.9 版本的 HTML 格式,根據 Content-Type 可以支持多種資料格式...... 需要注意的是:1.0 版本的作業方式是短連接,雖說 HTTP/1.0 是初期標準,但該協議標準至今仍然在被廣泛使用,
HTTP/1.1:1997 年公布的 HTTP 1.1 是目前主流的 HTTP 協議版本,當年的 HTTP 協議的出現主要是為了解決文本傳輸的難題,現在的 HTTP 早已超出了 Web 這個框架的局限,被運用到了各種場景里,當然,1.1 版本的最大變化,就是引入了長連接以及流水線機制(管道機制),
這里面出現的各種專有名詞大家留個印象就行,下文會逐漸講解,
4. 區分 URL 和 URI
與 URI(統一資源識別符號) 相比,大家應該更熟悉 URL(Uniform Resource Location,統一資源定位符),URL 就是我們使用 Web 瀏覽器訪問 Web 頁面時需要輸入的網頁地址,比如 http://baidu.com,
URI 是 Uniform Resource Identifier 的縮寫,RFC 2386 分別對這三個單詞進行如下定義:
-
Uniform:統一規定的格式可方便處理多種不同型別的資源
-
Resource:資源的定義是可標識的任何東西,不僅可以是單一的,也可以是一個集合
-
Identifier:標識可標識的物件,也稱為識別符號
綜上,URI 就是由某個協議方法表示的資源的定位識別符號,比如說,采用 HTTP 協議時,協議方案就是 http,除此之外,還有 ftp、telnet 等,標準的 URI 協議方法有 30 種左右,
URI 有兩種格式,相對 URI 和絕對 URI,
-
相對 URI:指從瀏覽器中基本 URI 處指定的 URL,形如
/user/logo.png -
絕對 URI:使用涵蓋全部必要資訊
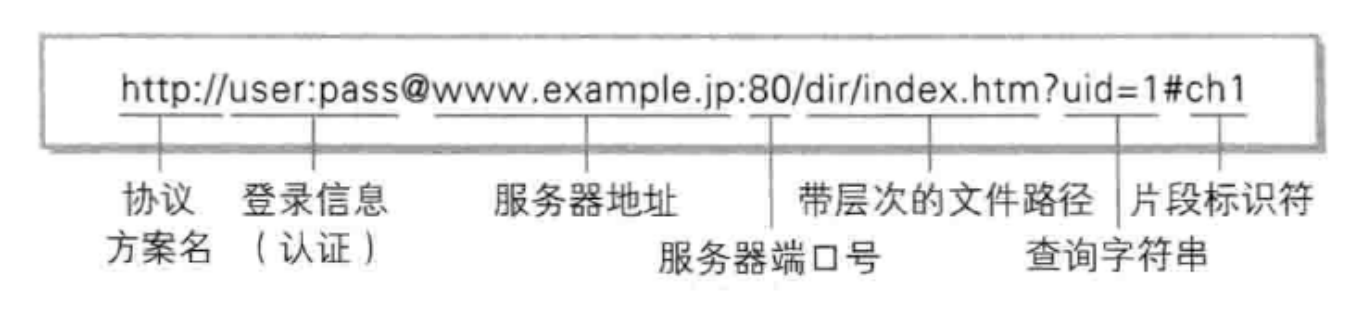
總結來說:URI 用字串標識某一處互聯網資源,而 URL 標識資源的地點(互聯網上所處的位置),可見 URL 是 URI 的子集,
5. HTTP 請求和回應
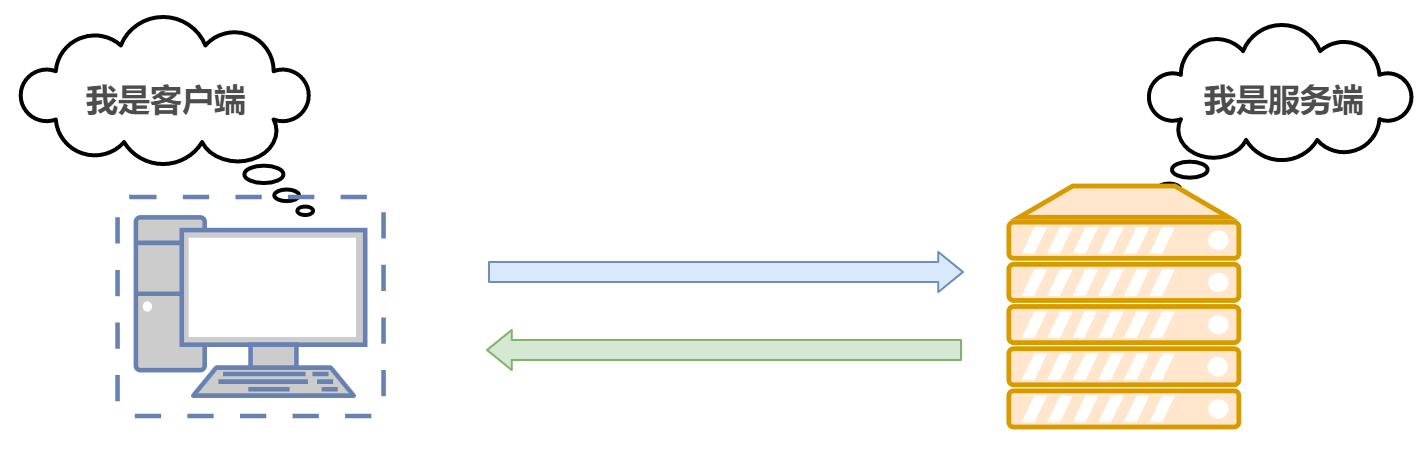
HTTP 協議規定,在兩臺計算機之間使用 HTTP 協議進行通信時,在一條通信線路上必定有一端是客戶端,另一端則是服務端,當在瀏覽器中輸入網址訪問某個網站時, 你的瀏覽器(客戶端)會將你的請求封裝成一個 HTTP 請求發送給服務器站點,服務器接收到請求后會組織回應資料封裝成一個 HTTP 回應回傳給瀏覽器,換句話說,肯定是先從客戶端開始建立通信的,服務器端在沒有接收到請求之前不會發送回應,
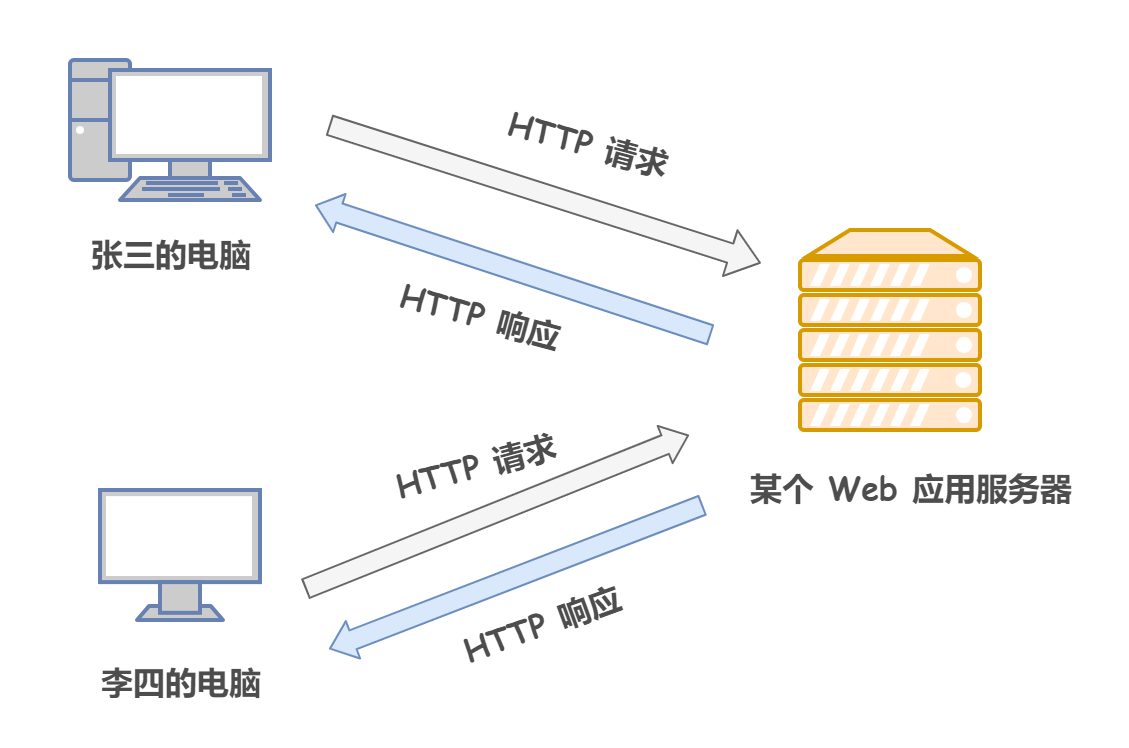
下面我們詳細分析一下 HTTP 的請求報文和回應報文
① HTTP 請求報文
HTTP 請求報文由 3 大部分組成:
1)請求行(必須在 HTTP 請求報文的第一行)
2)請求頭(從第二行開始,到第一個空行結束,請求頭和請求體之間存在一個空行)
3)請求體(通常以鍵值對 {key:value}方式傳遞資料)
舉個請求報文的例子:

請求行開頭的 POST 表示請求訪問服務器的型別,稱為方法(method),隨后的字串 /form/login 指明了請求訪問的資源物件,也叫做請求 URI(request-URI),最后的 HTTP/1.1 即 HTTP 的版本號,用來提示客戶端使用的 HTTP 協議功能,
綜上來看,這段請求的意思就是:請求訪問某臺 HTTP 服務器上的 /form/login 頁面資源,并附帶引數 name = veal、age = 37,
注意,無論是 HTTP 請求報文還是 HTTP 回應報文,請求頭/回應頭和請求體/回應體之間都會有一個空行,且請求體/回應體并不是必須的,
HTTP 請求方法
請求行中的方法的作用在于可以指定請求的資源按照期望產生某種行為,即使用方法給服務器下命令,
包括(HTTP 1.1):GET、POST、PUT、HEAD、DELETE、OPTIONS、CONNECT、TRACE,當然,我們在開發中最常見也最常使用的就只有前面三個,
1)GET 獲取資源
GET 方法用來請求訪問已被 URI 識別的資源,指定的資源經服務器端決議后回傳回應內容
使用 GET 方法請求-回應的例子:

2)POST 傳輸物體主體
POST 主要用來傳輸資料,而 GET 主要用來獲取資源,
使用 POST 方法請求-回應的例子:

3)PUT 傳輸檔案
PUT 方法用來傳輸檔案,由于自身不帶驗證機制,任何人都可以上傳檔案,因此存在安全性問題,一般不使用該方法,
使用 PUT 方法請求-回應的例子:

4)HEAD 獲取報文首部
和 GET 方法類似,但是不回傳報文物體主體部分,主要用于確認 URI 的有效性以及資源更新的日期時間等,
使用 HEAD 方法請求-回應的例子:

5)DELETE 洗掉檔案
與 PUT 功能相反,用來洗掉檔案,并且同樣不帶驗證機制,按照請求 URI 洗掉指定的資源,
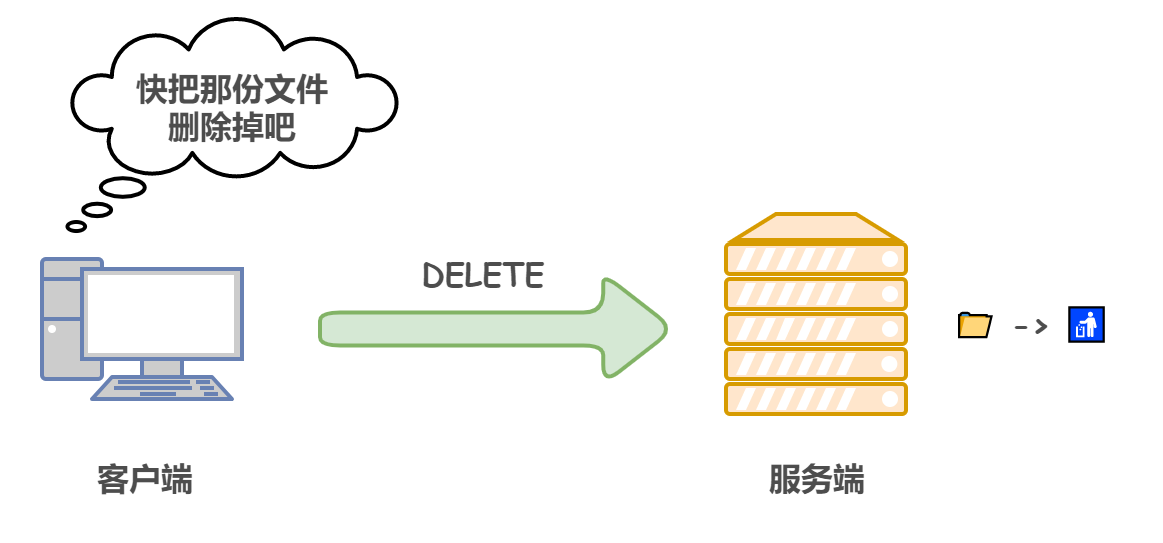
使用 DEELTE 方法請求-回應的例子:

6)OPTIONS 查詢支持的方法
用于獲取當前 URI 所支持的方法,若請求成功,會在 HTTP 回應頭中包含一個名為 “Allow” 的欄位,值是所支持的方法,如 “GET, POST”,
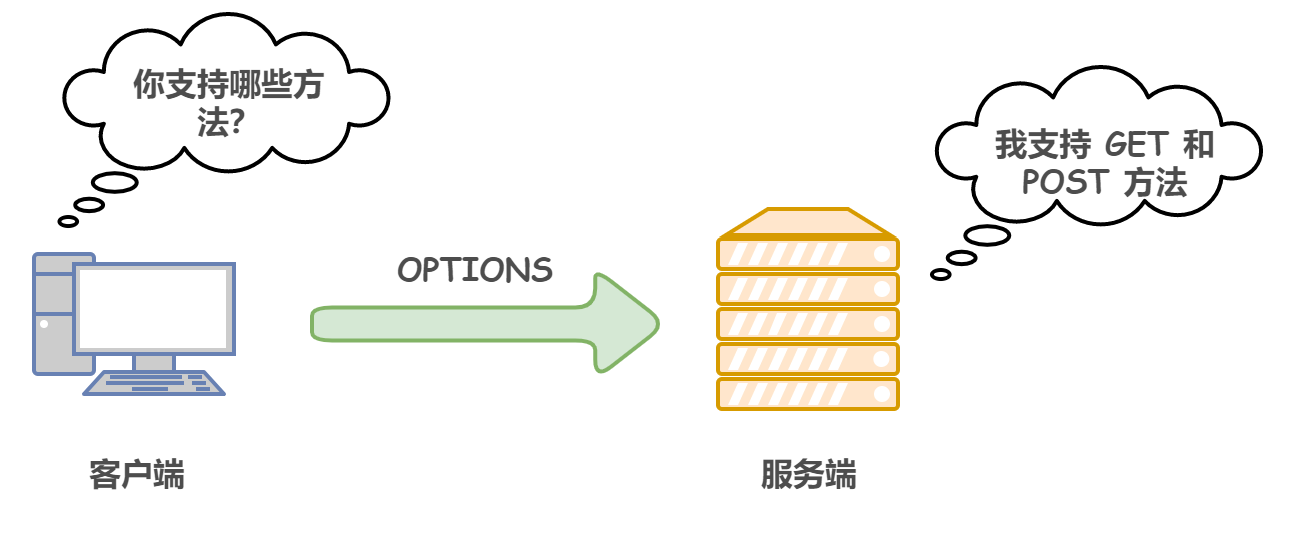
使用 OPTIONS 方法請求-回應的例子:

7)..........
HTTP 請求頭
請求頭用于補充請求的附加資訊、客戶端資訊、對回應內容相關的優先級等內容,以下列出常見請求頭:
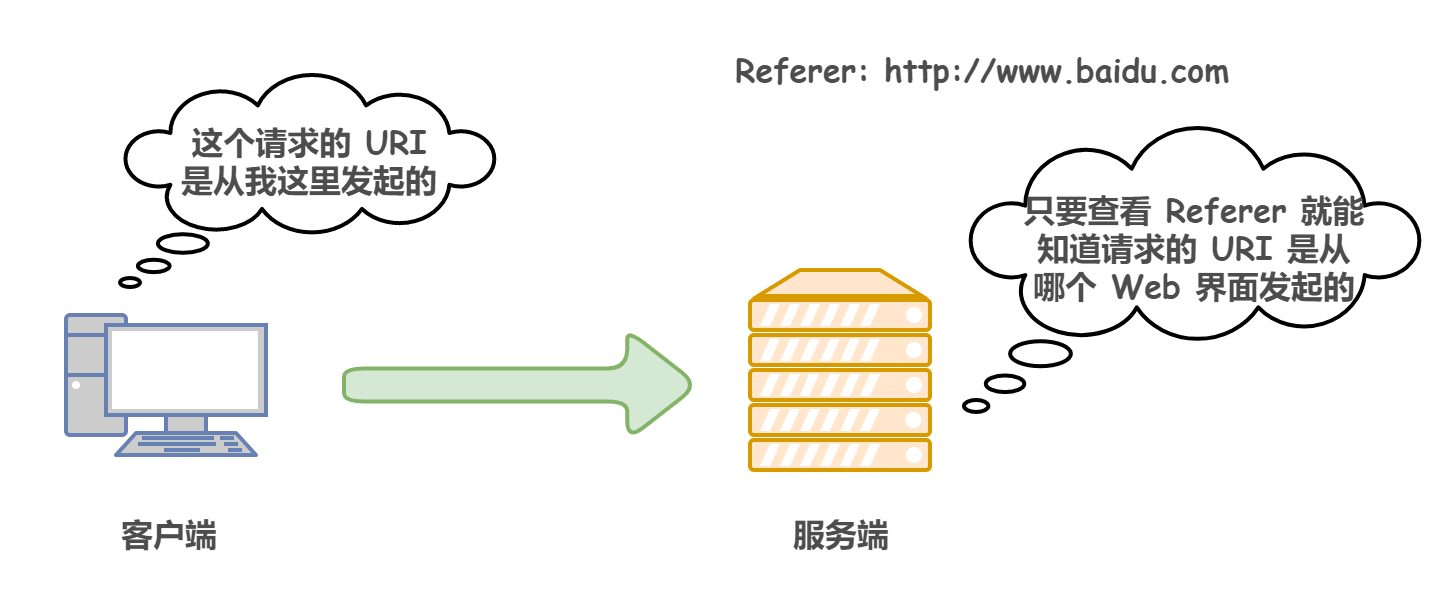
1)Referer:表示這個請求是從哪個 URI 跳過來的,比如說通過百度來搜索淘寶網,那么在進入淘寶網的請求報文中,Referer 的值就是:www.baidu.com,如果是直接訪問就不會有這個頭,這個欄位通常用于防盜鏈,
2)Accept:告訴服務端,該請求所能支持的回應資料型別,(對應的,HTTP 回應報文中也有這樣一個類似的欄位 Content-Type,用于表示服務端發送的資料型別,如果 Accept 指定的型別和服務端回傳的型別不一致,就會報錯)
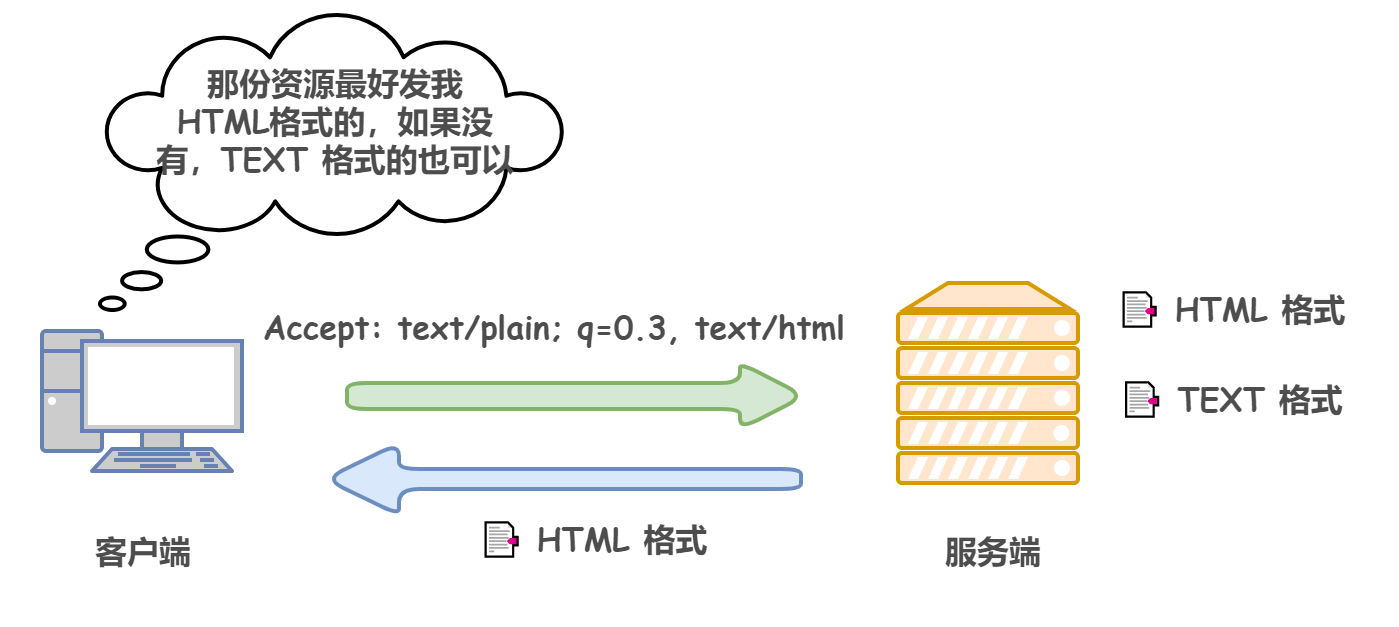
上圖中的 text/plain;q = 0.3 表示對于 text/plain 媒體型別的資料優先級/權重為 0.3(q 的范圍 0 ~ 1),不指定權重的,默認為 1.0,
資料格式型別如下圖:
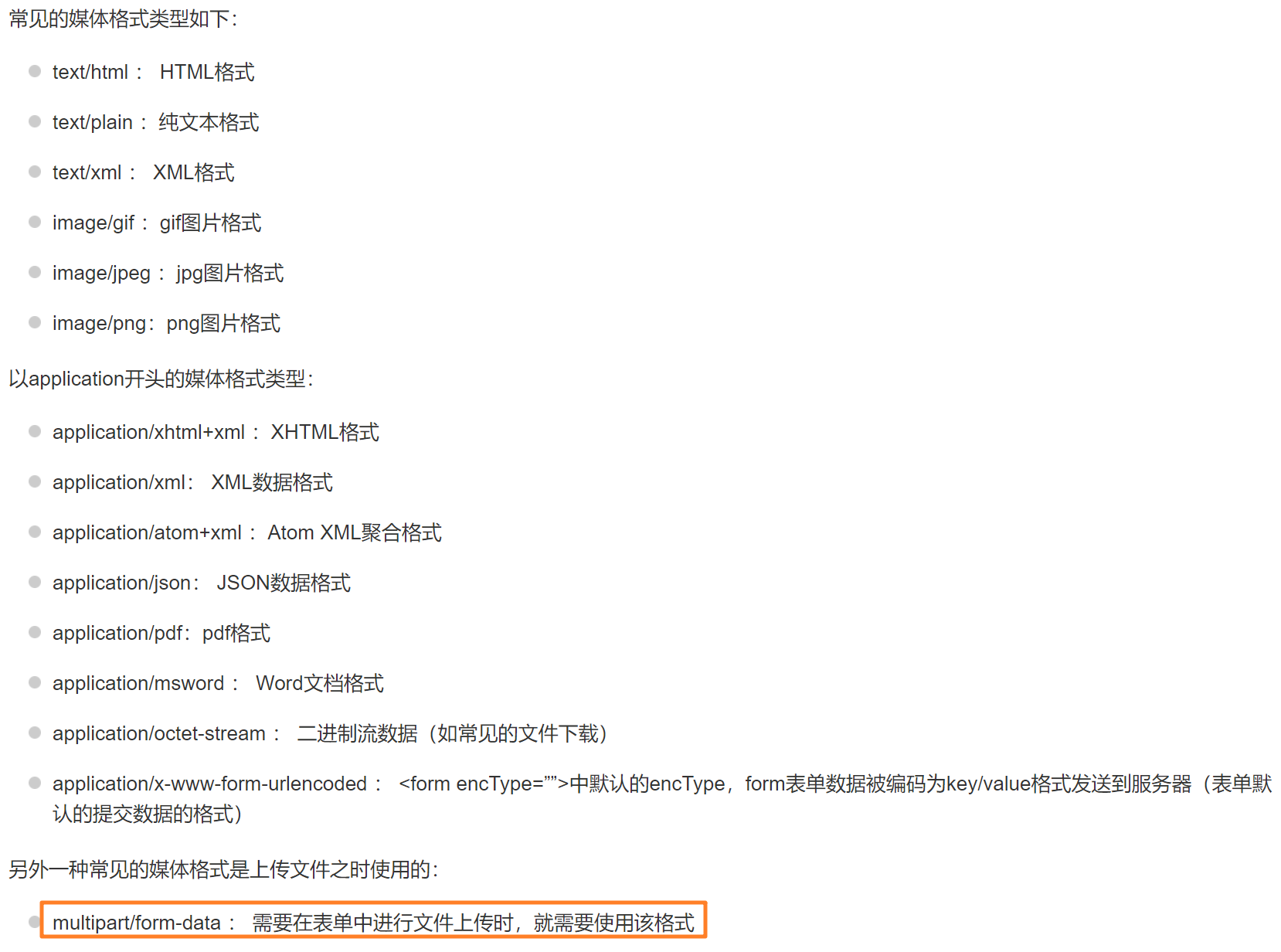
3)Host:告知服務器請求的資源所處的互聯網主機名和埠號,該欄位是 HTTP/1.1 規范中唯一一個必須被 包含在請求頭中的欄位,
4)Cookie:客戶端的 Cookie 就是通過這個報文頭屬性傳給服務端的!
Cookie: JSESSIONID=15982C27F7507C7FDAF0F97161F634B5
5)Connection:表示客戶端與服務連接型別;Keep-Alive 表示持久連接,close 已關閉
6)Content-Length:請求體的長度
7)Accept-Language:瀏覽器通知服務器,瀏覽器支持的語言
8)Range:對于只需獲取部分資源的范圍請求,包含首部欄位 Range 即可告知服務器資源的指定范圍
9)......
② HTTP回應報文
HTTP的回應報文也由三部分組成:
-
回應行(必須在 HTTP 回應報文的第一行)
-
回應頭(從第二行開始,到第一個空行結束,回應頭和回應體之間存在一個空行)
-
回應體
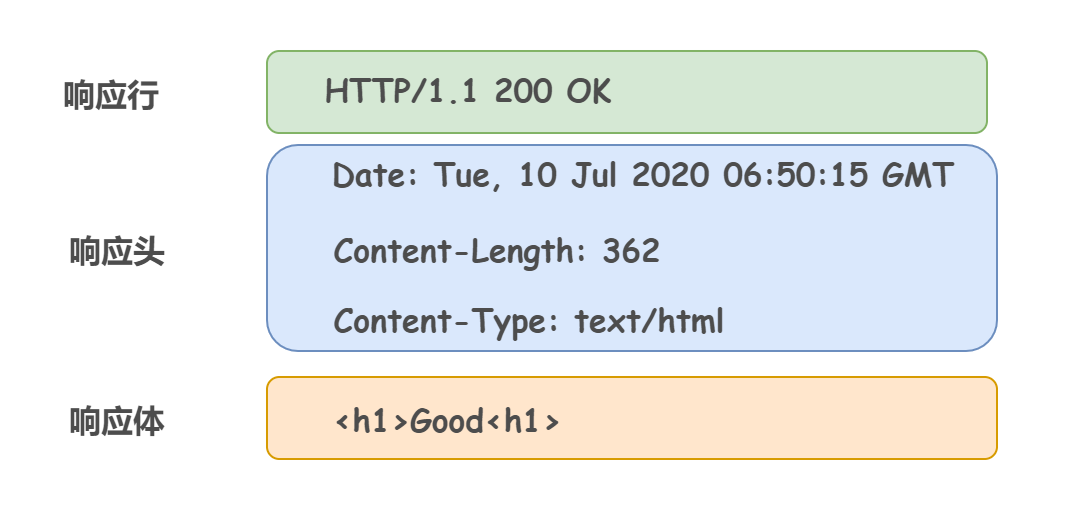
在回應行開頭的 HTTP 1.1 表示服務器對應的 HTTP 版本,緊隨的 200 OK 表示請求的處理結果的狀態碼和原因短語,
HTTP 狀態碼
HTTP 狀態碼負責表示客戶端 HTTP 請求的的回傳結果、標記服務器端處理是否正常、通知出現的錯誤等作業,(重中之重!!!,和我們日常開發息息相關)
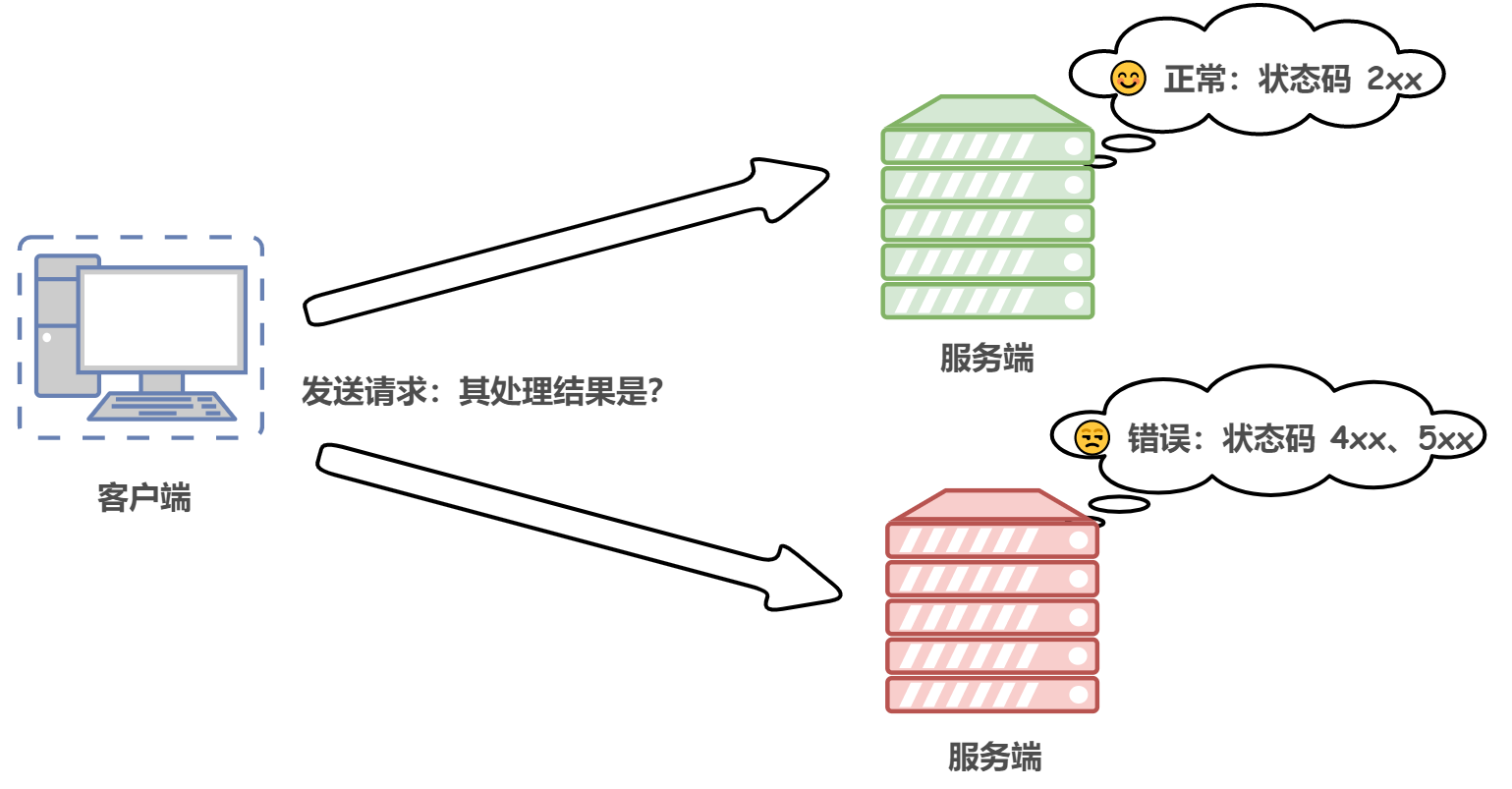
狀態碼由 3 位數字組成,第一個數字定義了回應的類別:
| 類別 | 原因短語 | |
|---|---|---|
| 1xx | Informational 資訊性狀態碼 | 接收的請求正在處理 |
| 2xx | Success 成功狀態碼 | 請求正常處理完畢 |
| 3xx | Redirection 重定向狀態碼 | 需要進行附加操作以完成請求 |
| 4xx | Client Error 客戶端錯誤狀態碼 | 服務器無法處理請求 |
| 5xx | Server Error 服務器錯誤狀態碼 | 服務器處理請求出錯 |
?? 2xx:請求正常處理完畢
-
200 OK:客戶端請求成功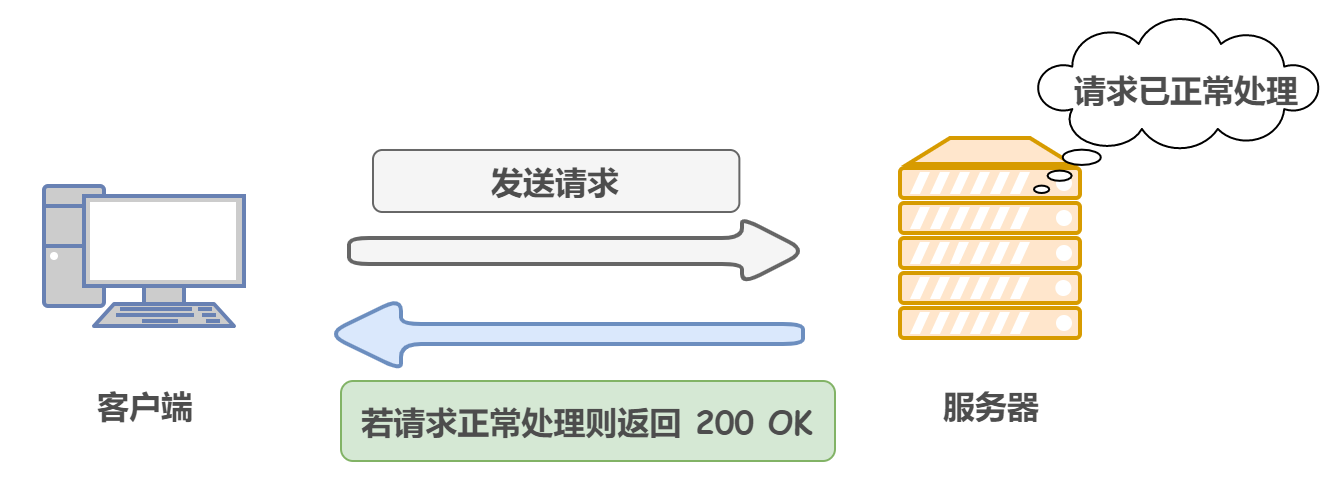
-
204 No Content:無內容,服務器成功處理,但未回傳內容,一般用在只是客戶端向服務器發送資訊,而服務器不用向客戶端回傳什么資訊的情況,不會重繪頁面,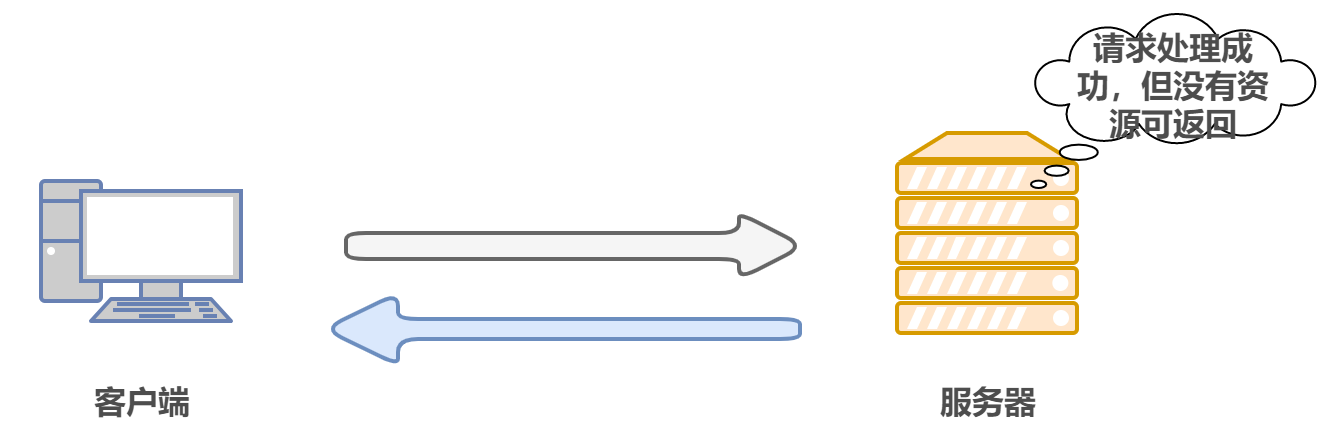
-
206 Partial Content:服務器已經完成了部分 GET 請求(客戶端進行了范圍請求),回應報文中包含 Content-Range 指定范圍的物體內容
?? 3xx:需要進行附加操作以完成請求(重定向)
-
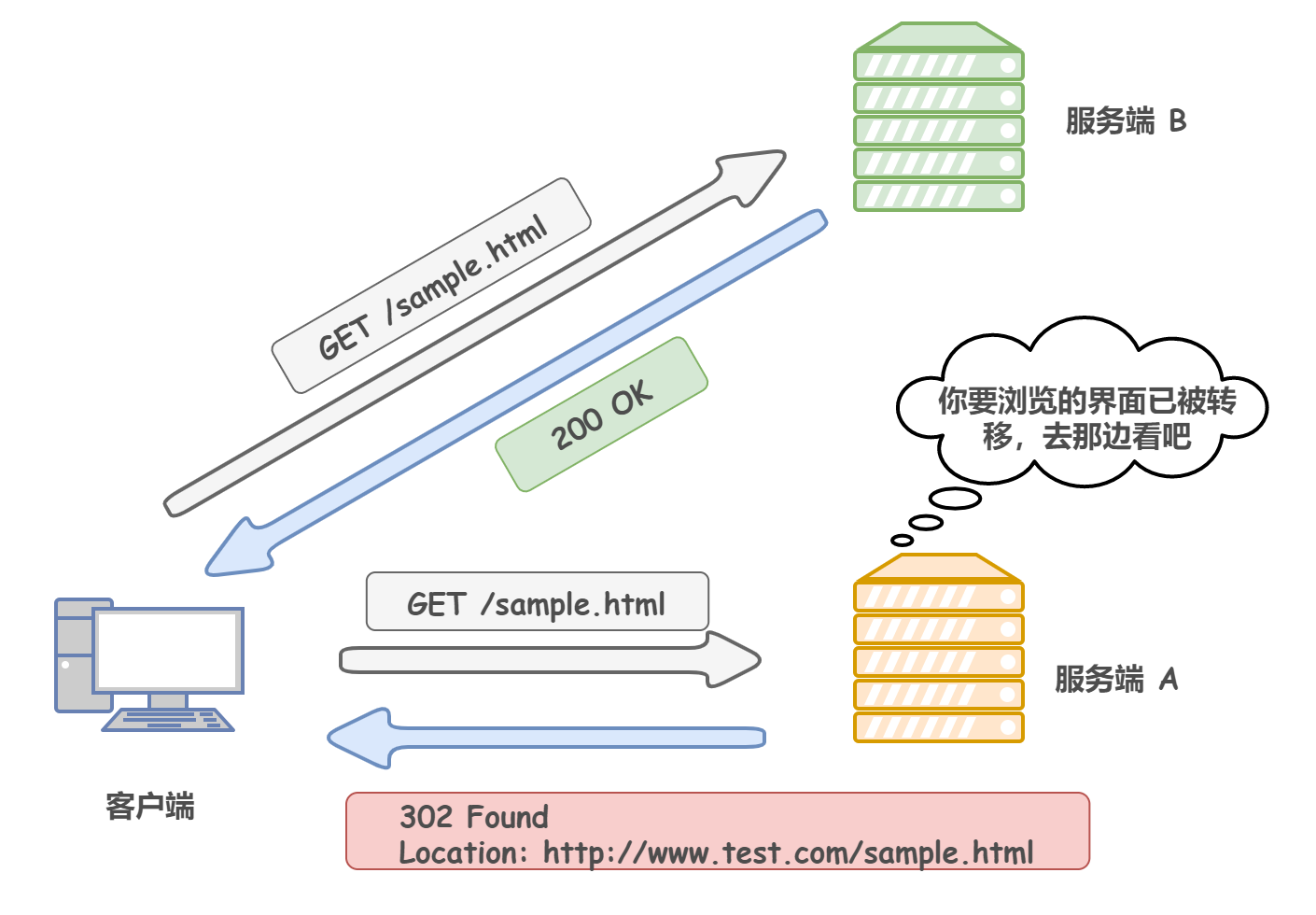
301 Moved Permanently:永久重定向,表示請求的資源已經永久的搬到了其他位置, -
302 Found:臨時重定向,表示請求的資源臨時搬到了其他位置 -
303 See Other:臨時重定向,應使用GET定向獲取請求資源,303功能與302一樣,區別只是303明確客戶端應該使用GET訪問 -
304 Not Modified:表示客戶端發送附帶條件的請求(GET方法請求報文中的IF…)時,條件不滿足,回傳304時,不包含任何回應主體,雖然304被劃分在3XX,但和重定向一毛錢關系都沒有 -
307 Temporary Redirect:臨時重定向,和302有著相同含義,POST不會變成GET
?? 4xx:客戶端錯誤
-
400 Bad Request:客戶端請求有語法錯誤,服務器無法理解, -
401 Unauthorized:請求未經授權,這個狀態代碼必須和 WWW-Authenticate 報頭域一起使用, -
403 Forbidden:服務器收到請求,但是拒絕提供服務 -
404 Not Found:請求資源不存在,比如,輸入了錯誤的 URL -
415 Unsupported media type:不支持的媒體型別
?? 5xx:服務器端錯誤,服務器未能實作合法的請求,
-
500 Internal Server Error:服務器發生不可預期的錯誤, -
503 Server Unavailable:服務器當前處于超負載或正在停機維護,暫時不能處理客戶端的請求,一段時間后可能恢復正常
HTTP 回應頭
回應頭也是用鍵值對 k:v,用于補充回應的附加資訊、服務器資訊,以及對客戶端的附加要求等,
這里著重說明一下 Location 這個欄位,可以將回應接收方引導至與某個 URI 位置不同的資源,通常來說,該欄位會配合 3xx:Redirection 的回應,提供重定向的 URI,
6. HTTP 連接管理
① 短連接(非持久連接)
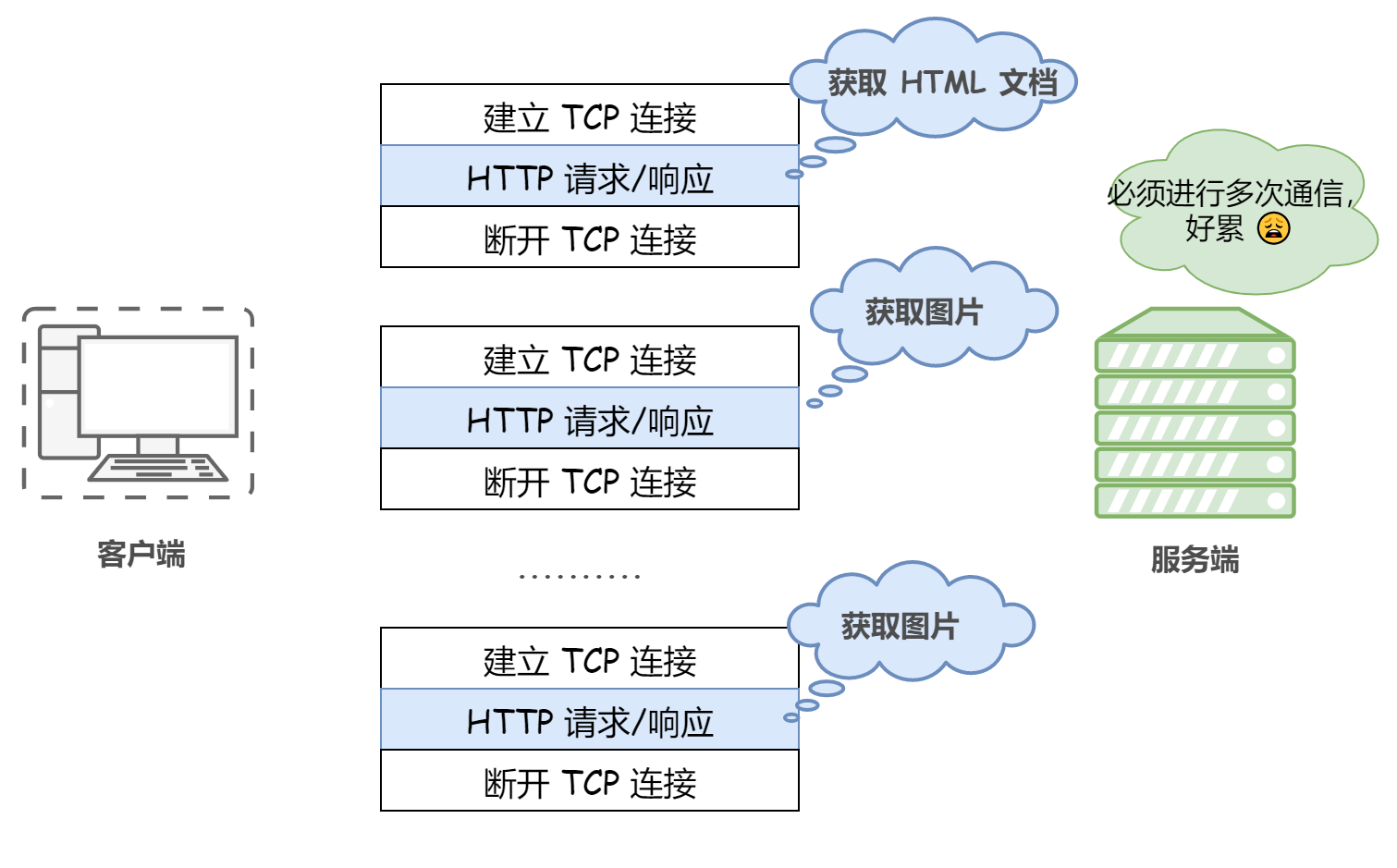
在 HTTP 協議的初始版本(HTTP/1.0)中,客戶端和服務器每進行一次 HTTP 會話,就建立一次連接,任務結束就中斷連接,當客戶端瀏覽器訪問的某個 HTML 或其他型別的 Web 頁中包含有其他的 Web 資源(如JavaScript 檔案、影像檔案、CSS檔案等),每遇到這樣一個 Web 資源,瀏覽器就會重新建立一個 HTTP 會話,這種方式稱為短連接(也稱非持久連接),
也就是說每次 HTTP 請求都要重新建立一次連接,由于 HTTP 是基于 TCP/IP 協議的,所以連接的每一次建立或者斷開都需要 TCP 三次握手或者 TCP 四次揮手的開銷,
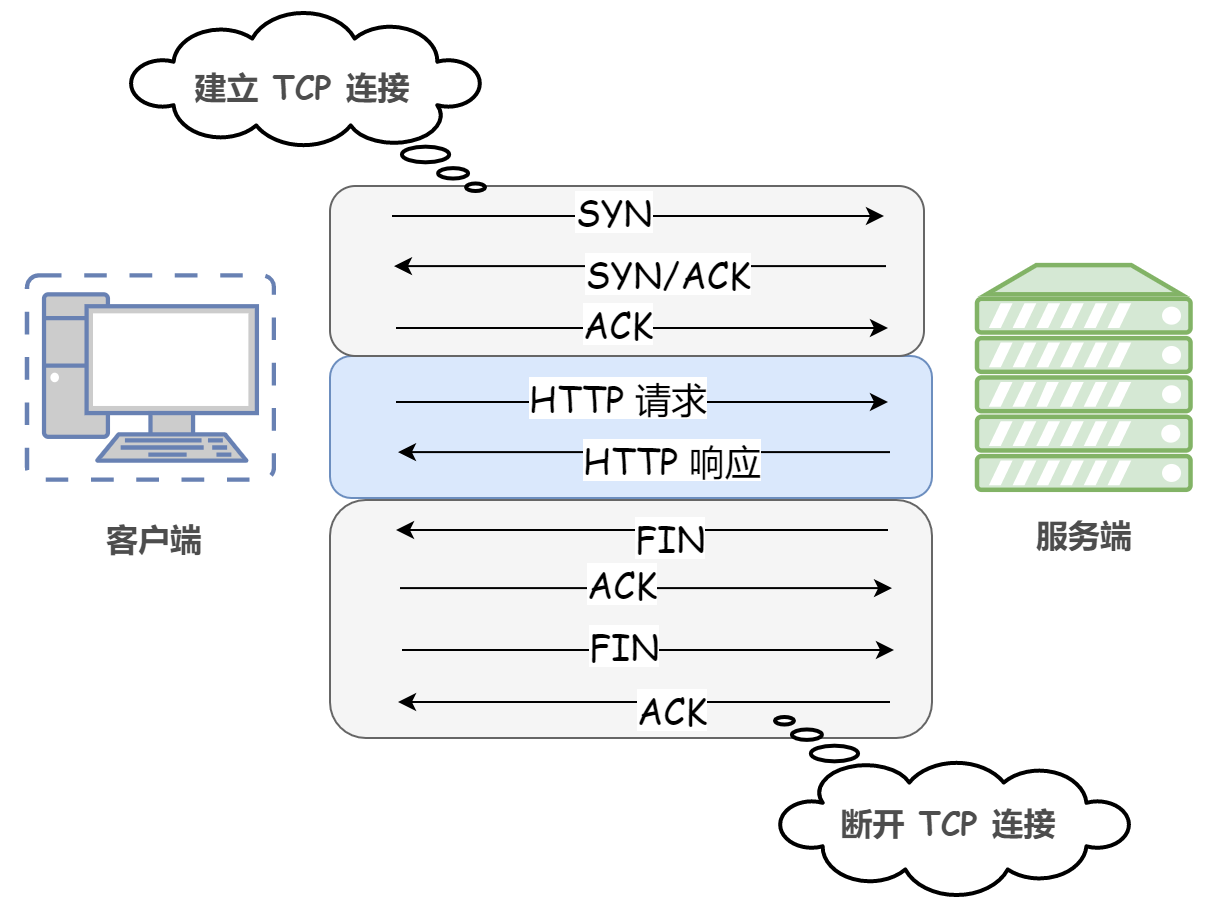
顯然,這種方式存在巨大的弊端,比如訪問一個包含多張圖片的 HTML 頁面,每請求一張圖片資源就會造成無謂的 TCP 連接的建立和斷開,大大增加了通信量的開銷
② 長連接(持久連接)
從 HTTP/1.1 起,默認使用長連接也稱持久連接 keep-alive,使用長連接的 HTTP 協議,會在回應頭加入這行代碼:Connection:keep-alive
在使用長連接的情況下,當一個網頁打開完成后,客戶端和服務器之間用于傳輸 HTTP 資料的 TCP 連接不會關閉,客戶端再次訪問這個服務器時,會繼續使用這一條已經建立的連接,Keep-Alive 不會永久保持連接,它有一個保持時間,可以在不同的服務器軟體(如 Apache)中設定這個時間,實作長連接需要客戶端和服務端都支持長連接,
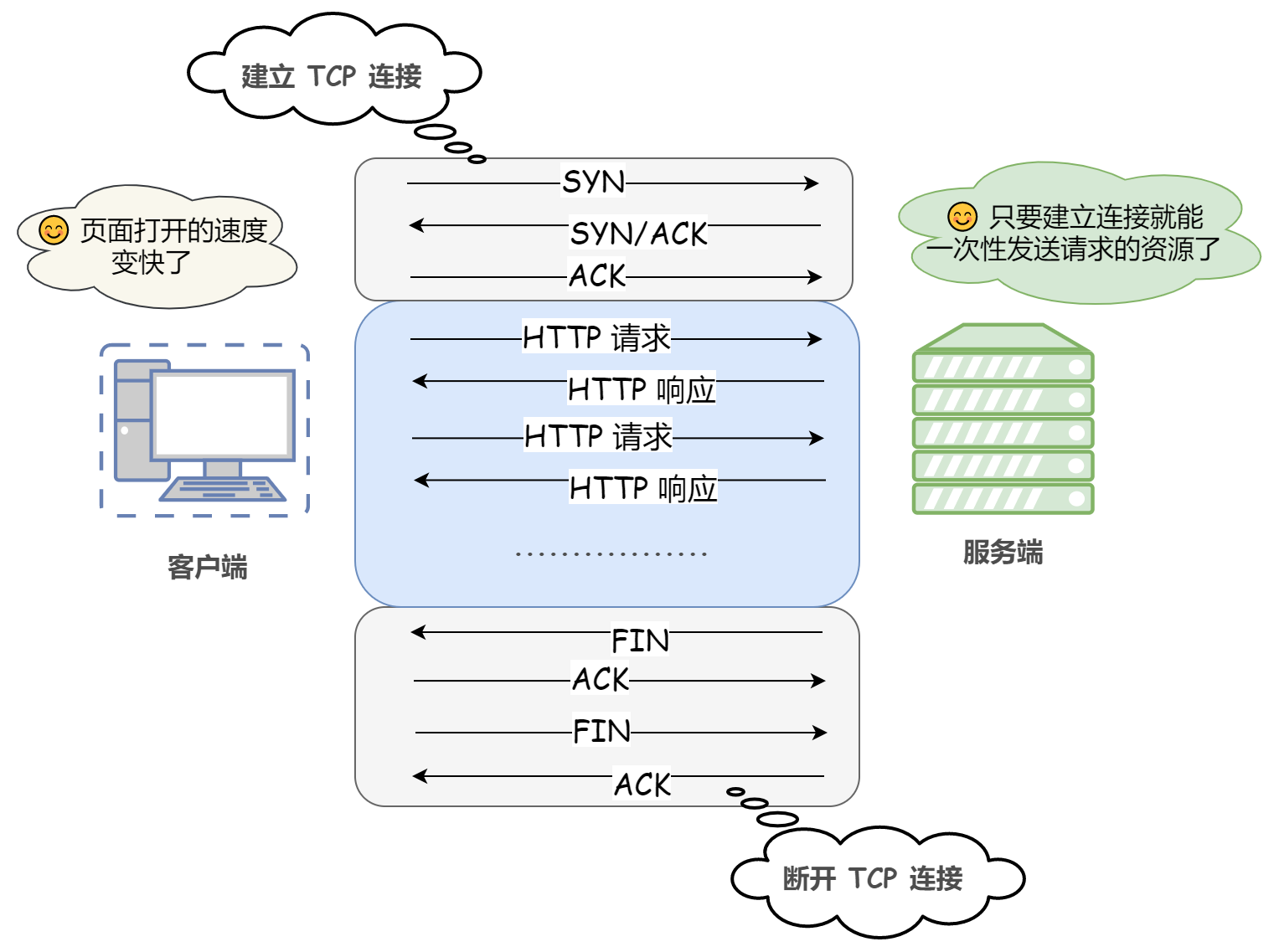
HTTP 協議的長連接和短連接,實質上是 TCP 協議的長連接和短連接,
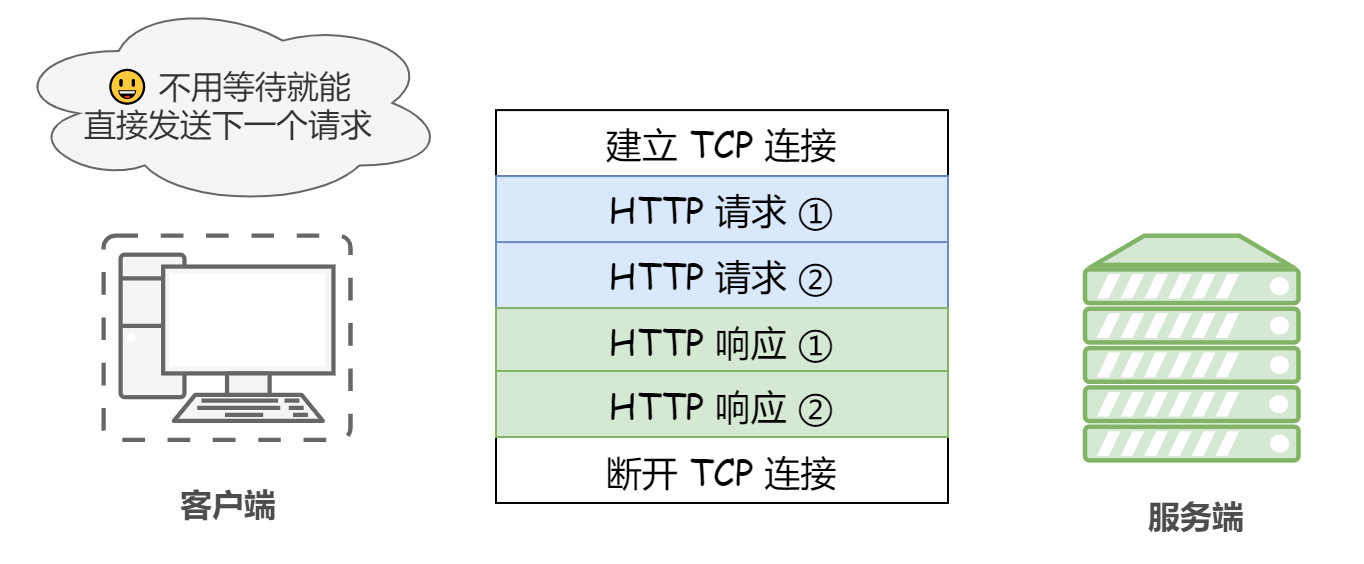
③ 流水線(管線化)
默認情況下,HTTP 請求是按順序發出的,下一個請求只有在當前請求收到回應之后才會被發出,由于受到網路延遲和帶寬的限制,在下一個請求被發送到服務器之前,可能需要等待很長時間,
持久連接使得多數請求以流水線(管線化 pipeline)方式發送成為可能,即在同一條持久連接上連續發出請求,而不用等待回應回傳后再發送,這樣就可以做到同時并行發送多個請求,而不需要一個接一個地等待回應了,
7. 無狀態的 HTTP
HTTP 協議是無狀態協議,也就是說他不對之前發生過的請求和回應的狀態進行管理,即無法根據之前的狀態進行本次的請求處理,
這樣就會帶來一個明顯的問題,如果 HTTP 無法記住用戶登錄的狀態,那豈不是每次頁面的跳轉都會導致用戶需要再次重新登錄?
當然,不可否認,無狀態的優點也很顯著,由于不必保存狀態,自然就減少了服務器的 CPU 及記憶體資源的消耗,另一方面,正式由于 HTTP 簡單,所以才會被如此廣泛應用,

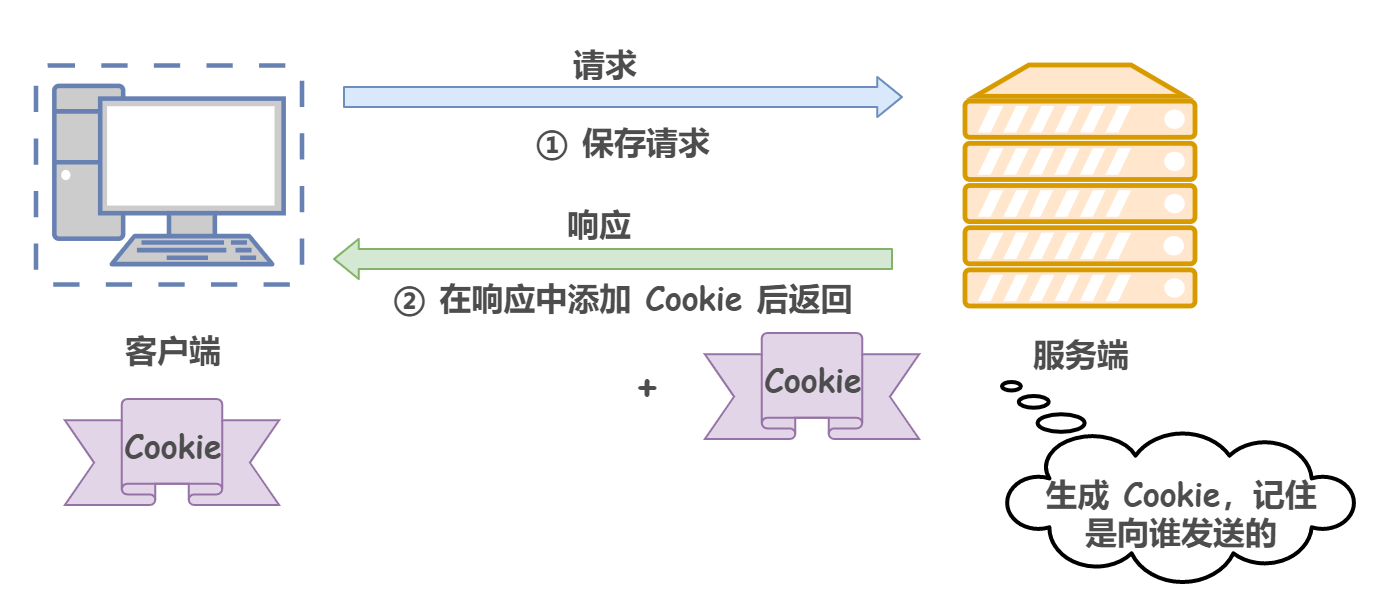
這樣,在保留無狀態協議這個特征的同時,又要解決無狀態導致的問題,方案有很多種,其中比較簡單的方式就是使用 Cookie 技術,
Cookie 通過在請求和回應報文中寫入 Cookie 資訊來控制客戶端的狀態,具體來說,Cookie 會根據從服務器端發送的回應報文中的一個叫作 Set-Cookie 的首部欄位資訊,通知客戶端保存 Cookie,當下次客戶端再往服務器發送請求時,客戶端會自動在請求報文中加入 Cookie 值發送出去,服務器端收到客戶端發來的 Cookie 后,會去檢查究竟是哪一個客戶端發來的連接請求,然后對比服務器上的記錄,最后得到之前的狀態資訊,
形象來說,在客戶端第一次請求后,服務器會下發一個裝有客戶資訊的身份證,后續客戶端請求服務器的時候,帶上身份證,服務器就能認得了,
下圖展示了發生 Cookie 互動的情景:
1)沒有 Cookie 資訊狀態下的請求:
對應的 HTTP 請求報文(沒有 Cookie 資訊的狀態)
GET /reader/ HTTP/1.1
Host: baidu.com
* 首部欄位沒有 Cookie 的相關資訊
對應的 HTTP 回應報文(服務端生成 Cookie 資訊)
HTTP/1.1 200 OK
Date: Thu, 12 Jul 2020 15:12:20 GMT
Server: Apache
<Set-Cookie: sid=1342077140226; path=/; expires=Wed, 10-Oct-12 15:12:20 GMT>
Content-Type: text/plain; charset=UTF-8
2)第 2 次以后的請求(存有 Cookie 資訊狀態)
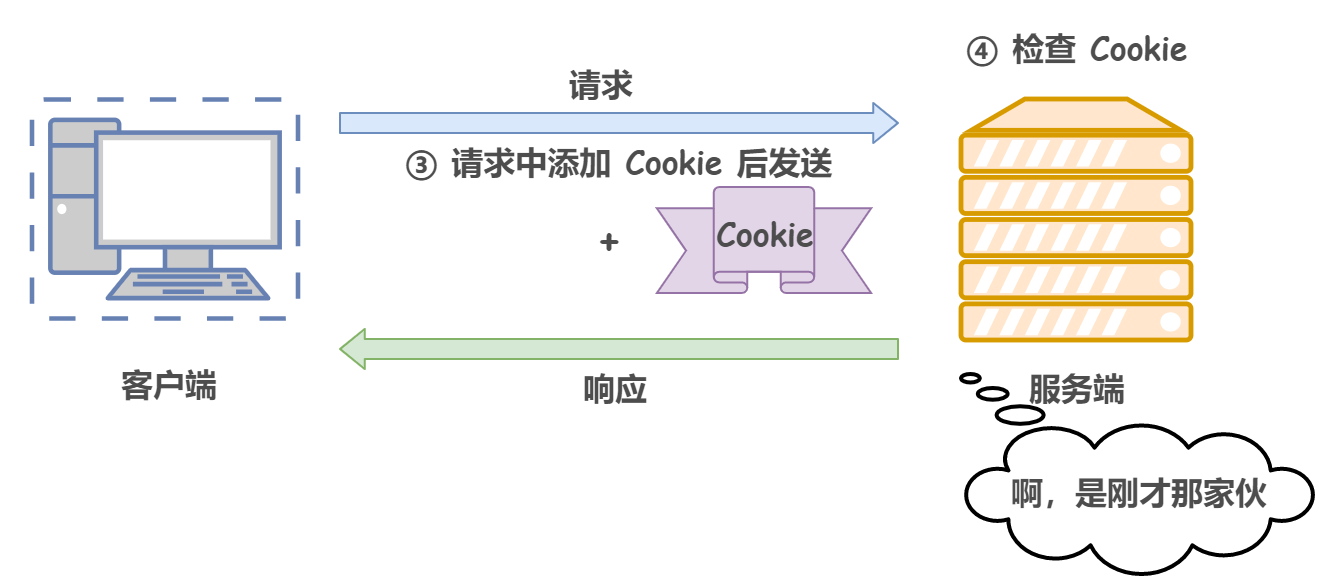
對應的 HTTP 請求報文(自動發送保存著的 Cookie 資訊)
GET /image/ HTTP/1.1
Host: baidu.com
Cookie: sid=1342077140226
8. HTTP 斷點續傳
所謂斷點續傳指的是下載傳輸檔案可以中斷,之后重新下載時可以接著中斷的地方開始下載,而不必從頭開始下載,斷點續傳需要客戶端和服務端都支持,
這是一個非常常見的功能,原理很簡單,其實就是 HTTP 請求頭中的欄位 Range 和回應頭中的欄位 Content-Range 的簡單使用,客戶端一塊一塊的請求資料,最后將下載回來的資料塊拼接成完整的資料,打個比方,瀏覽器請求服務器上的一個服務,所發出的請求如下:
假設服務器域名為 www.baidu.com,檔案名為 down.zip,
GET /down.zip HTTP/1.1
Accept: image/gif, image/x-xbitmap, image/jpeg, image/pjpeg, application/vnd.ms-
excel, application/msword, application/vnd.ms-powerpoint, */*
Accept-Language: zh-cn
Accept-Encoding: gzip, deflate
User-Agent: Mozilla/4.0 (compatible; MSIE 5.01; Windows NT 5.0)
Connection: Keep-Alive
服務器收到請求后,按要求尋找請求的檔案,提取檔案的資訊,然后回傳給瀏覽器,回傳資訊如下:
200
Content-Length=106786028
Accept-Ranges=bytes
Date=Mon, 30 Apr 2001 12:56:11 GMT
ETag=W/"02ca57e173c11:95b"
Content-Type=application/octet-stream
Server=Microsoft-IIS/5.0
Last-Modified=Mon, 30 Apr 2001 12:56:11 GMT
OK,那么既然要斷點續傳,客戶端瀏覽器請求服務器的時候要多加一條資訊 — 從哪里開始請求資料, 比如要求從 2000070 位元組開始:
GET /down.zip HTTP/1.0
User-Agent: NetFox
RANGE: bytes=2000070-
Accept: text/html, image/gif, image/jpeg, *; q=.2, */*; q=.2
仔細看一下就會發現多了一行 RANGE: bytes=2000070-,這一行的意思就是告訴服務器 down.zip 這個檔案從 2000070 位元組開始傳,前面的位元組不用傳了,
服務器收到這個請求以后,回傳的資訊如下:
206
Content-Length=106786028
Content-Range=bytes 2000070-106786027/106786028
Date=Mon, 30 Apr 2001 12:55:20 GMT
ETag=W/"02ca57e173c11:95b"
Content-Type=application/octet-stream
Server=Microsoft-IIS/5.0
Last-Modified=Mon, 30 Apr 2001 12:55:20 GMT
和前面服務器回傳的資訊比較一下,就會發現增加了一行: Content-Range=bytes 2000070-106786027/106786028,回傳的代碼也改為 206 了,而不再是 200 了,
9. HTTP 的缺點
到現在為止,我們已經了解到了 HTTP 具有相當優秀和方便的一面,然后,事務皆有兩面性,他也是有不足之處的:
-
通信使用明文(不加密),內容可能被竊聽
-
不驗證通信對方的身份,因此有可能遭遇偽裝
-
無法證明報文的完整性,所以有可能被篡改
這些問題不僅在 HTTP 上出現,其他未加密的協議中也存在類似問題,為了解決 HTTP 的痛點,HTTPS 應用而生,說白了 HTTP + 加密 + 認證 + 完整性保護就是 HTTPS 協議,關于 HTTPS 協議的內容也非常之多且重要,后續會單開一篇文章進行講解,
?? 關注公眾號 | 飛天小牛肉,即時獲取更新
-
博主東南大學研究生在讀,利用課余時間運營一個公眾號『 飛天小牛肉 』,2020/12/29 日開通,專注分享計算機基礎(資料結構 + 演算法 + 計算機網路 + 資料庫 + 作業系統 + Linux)、Java 基礎和面試指南的相關原創技術好文,本公眾號的目的就是讓大家可以快速掌握重點知識,有的放矢,希望大家多多支持哦,和小牛肉一起成長 ??
-
并推薦個人維護的開源教程類專案: CS-Wiki(Gitee 推薦專案,現已 0.9k star), 致力打造完善的后端知識體系,在技術的路上少走彎路,歡迎各位小伙伴前來交流學習 ~ ??
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/261239.html
標籤:Java
上一篇:程式員都遇到過哪些誤解?