前言
本文的文字及圖片來源于網路,僅供學習、交流使用,不具有任何商業用途,如有問題請及時聯系我們以作處理,
Python爬蟲、資料分析、網站開發等案例教程視頻免費在線觀看
https://space.bilibili.com/523606542

前文內容
Python爬蟲新手入門教學(一):爬取豆瓣電影排行資訊
Python爬蟲新手入門教學(二):爬取小說
Python爬蟲新手入門教學(三):爬取鏈家二手房資料
Python爬蟲新手入門教學(四):爬取前程無憂招聘資訊
Python爬蟲新手入門教學(五):爬取B站視頻彈幕
Python爬蟲新手入門教學(六):制作詞云圖
Python爬蟲新手入門教學(七):爬取騰訊視頻彈幕
Python爬蟲新手入門教學(八):爬取論壇文章保存成PDF
Python爬蟲新手入門教學(九):多執行緒爬蟲案例講解
Python爬蟲新手入門教學(十):爬取彼岸4K超清壁紙
Python爬蟲新手入門教學(十一):最近王者榮耀皮膚爬取
Python爬蟲新手入門教學(十二):英雄聯盟最新皮膚爬取
Python爬蟲新手入門教學(十三):爬取高質量超清壁紙
Python爬蟲新手入門教程(十四):爬取有聲小說網站資料
Python爬蟲新手入門教學(十五):Python爬取某音樂網站的排行榜歌曲
Python爬蟲新手入門教學(十六):爬取網站音樂素材
Python爬蟲新手入門教學(十七):爬取yy全站小視頻
基本開發環境
- Python 3.6
- Pycharm
相關模塊的使用
import os import requests
安裝Python并添加到環境變數,pip安裝需要的相關模塊即可,
一、確定目標需求
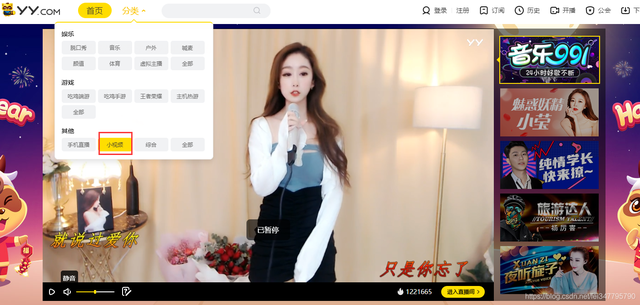
百度搜索YY,點擊分類選擇小視頻,里面的小姐姐自拍的短視頻就是我們所需要的資料了,
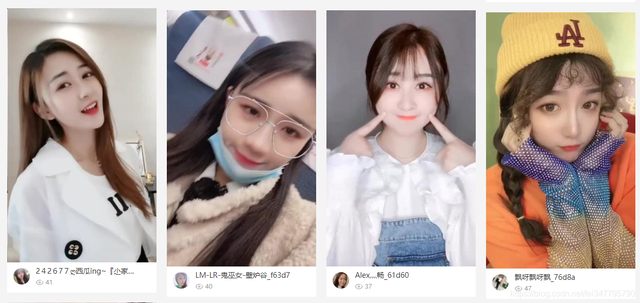
二、網頁資料分析
網站是下滑網頁之后加載資料,在上篇關于好看視頻的爬取文章中已經有說明,YY視頻也是換湯不換藥,
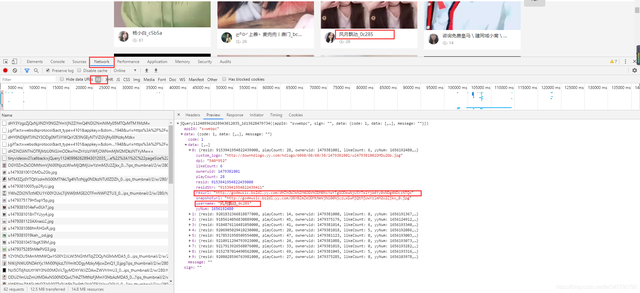
如圖所示,所框選的url地址,就是短視頻的播放地址了,
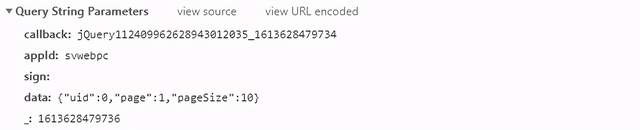
資料包介面地址:
https://api-tinyvideo-web.yy.com/home/tinyvideosv2?callback=jQuery112409962628943012035_1613628479734&appId=svwebpc&sign=&data=https://www.cnblogs.com/hhh188764/p/%7B%22uid%22%3A0%2C%22page%22%3A1%2C%22pageSize%22%3A10%7D&_=1613628479736
第二頁的資料請求引數:
第三頁的資料請求引數:
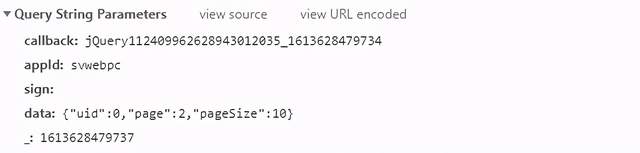
很明顯這是根據data引數中的page改變翻頁的,
構建翻頁回圈,獲取視頻url地址以及發布人的名字,保存到本地,
三、代碼實作
1、請求資料介面
import requests url = 'https://api-tinyvideo-web.yy.com/home/tinyvideosv2' params = { 'callback': 'jQuery112409962628943012035_1613628479734', 'appId': 'svwebpc', 'sign': '', 'data': '{"uid":0,"page":0,"pageSize":10}', '_': '1613628479737', } headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36' } response = requests.get(url=url, params=params, headers=headers)
問題來了,回傳的資料是json資料嘛?
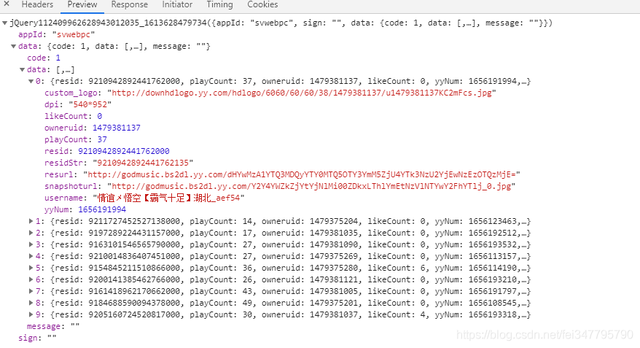
如上圖所示,很多人看到這樣的資料肯定就覺得這不就是一個json資料嘛?
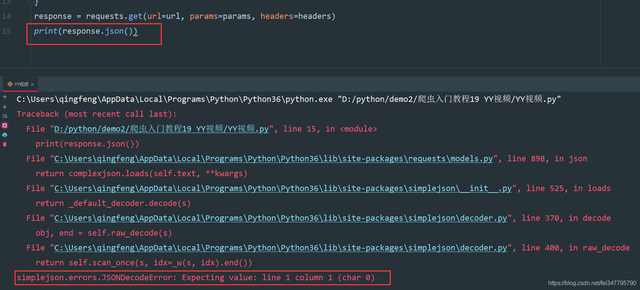
JSONDecodeError: json解碼錯誤,它并不是有一個json資料,而是字串,
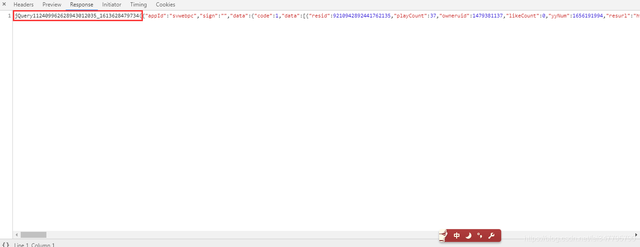
通過response查看就知道了,回傳給我們的資料是多了一段 jQuery112409962628943012035_1613628479734()
其中的json資料是包含在里面的,如果想要提取資料有三種方法,
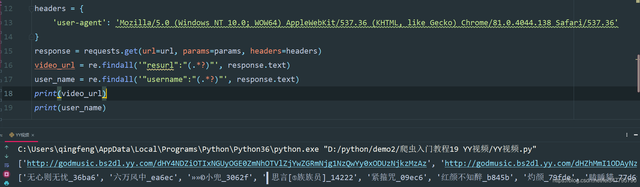
1、回傳response.text,使用正則運算式提取url地址以及發布人的名字
video_url = re.findall('"resurl":"(.*?)"', response.text) user_name = re.findall('"username":"(.*?)"', response.text)
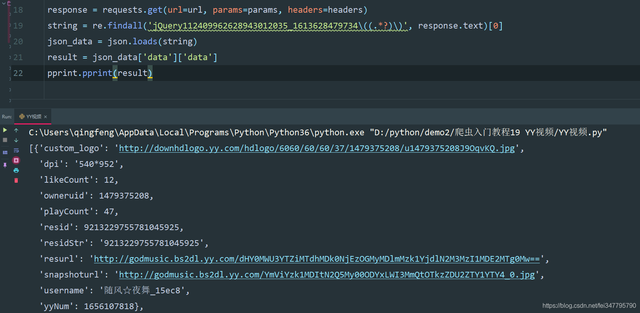
2、回傳response.text,使用正則運算式提取 jQuery112409962628943012035_1613628479734() 中的資料,然后通過json模塊把字串轉成json資料,然后遍歷提取資料,
string = re.findall('jQuery112409962628943012035_1613628479734\((.*?)\)', response.text)[0] json_data = json.loads(string) result = json_data['data']['data'] pprint.pprint(result)
3、把請求的url地址中的 callback 刪掉,可以直接獲取json資料
import pprint import requests url = 'https://api-tinyvideo-web.yy.com/home/tinyvideosv2' params = { 'appId': 'svwebpc', 'sign': '', 'data': '{"uid":0,"page":1,"pageSize":10}', '_': '1613628479737', } headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36' } response = requests.get(url=url, params=params, headers=headers) json_data = response.json() result = json_data['data']['data'] pprint.pprint(result)
2、保存資料
for index in result: video_url = index['resurl'] user_name = index['username'] video_content = requests.get(url=video_url, headers=headers).content with open('video\\' + user_name + '.mp4', mode='wb') as f: f.write(video_content) print(user_name)
注意點: 用戶名有特殊字符,保存的時候會報錯
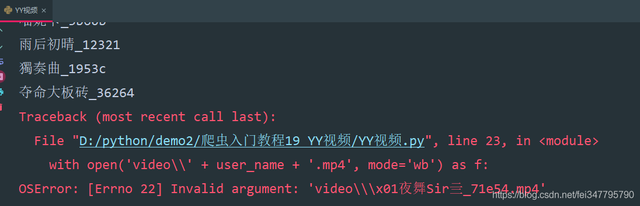

所以需要使用正則運算式替換掉特殊字符
def change_title(title): pattern = re.compile(r"[\/\\\:\*\?\"\<\>\|]") # '/ \ : * ? " < > |' new_title = re.sub(pattern, "_", title) # 替換為下劃線 return new_title
完整實作代碼
import re import requests import re def change_title(title): pattern = re.compile(r"[\/\\\:\*\?\"\<\>\|]") # '/ \ : * ? " < > |' new_title = re.sub(pattern, "_", title) # 替換為下劃線 return new_title page = 0 while True: page += 1 url = 'https://api-tinyvideo-web.yy.com/home/tinyvideosv2' params = { 'appId': 'svwebpc', 'sign': '', 'data': '{"uid":0,"page":%s,"pageSize":10}' % str(page), '_': '1613628479737', } headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36' } response = requests.get(url=url, params=params, headers=headers) json_data = response.json() result = json_data['data']['data'] for index in result: video_url = index['resurl'] user_name = index['username'] new_title = change_title(user_name) video_content = requests.get(url=video_url, headers=headers).content with open('video\\' + new_title + '.mp4', mode='wb') as f: f.write(video_content) print(user_name)

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/261256.html
標籤:Python