python爬蟲入門(1)
初識爬蟲,了解簡單的概念后,先做一點小的專案,打幾行代碼,感受一下,才方便繼續學習,
在pycharm上運行需要的函式庫:
簡單地來說:
lxml–其中的HTML可決議網頁
pip(似乎需要最新版本)
requests–申請訪問
直接上代碼(每一個必要位置均有注釋):
(xpath最后會提到)
import requests
url = 'http://movie.douban.com/top250'
#偽裝身份--headers--dic
headers = {'user-agent':'mozilla/5.0'} #偽裝成瀏覽器
resp = requests.get(url,headers=headers)
a = resp.status_code
print(a)
#請求成功--a==200
html = resp.text #輸出更加美觀(盡管是看不懂)
#print(html)
#網頁內容決議
from lxml import etree
from parsel import selector #這個是另一個與xpath有類似功能的庫
parse_html = etree.HTML(html) #決議網頁 下面的text()務必寫成函式形式
one = parse_html.xpath('//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/span[1]/text()') #以文本格式輸出UTF-8,否則為element
print(one)
#在開發者模式下仔細觀察會發現:每個電影的代碼只有細微的差別
#//*[@id="content"]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/span[1]
#//*[@id="content"]/div/div[1]/ol/li[2]/div/div[2]/div[1]/a/span[1]
#去掉不一致的代碼([n])會打出所有的電影(該頁面的所有)
all = parse_html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()')
print(all)
#獲取評分
score = parse_html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/div/span[2]/text()')
print(score)
x = parse_html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/p[2]/span/text()')
print(x)
#小提示:如果使用pycharm,則注意選擇運行結果欄左邊的自動換行,更美觀,(滾輪難受得一批)
xpath的獲取:
在瀏覽器中找到開發者模式,如圖:
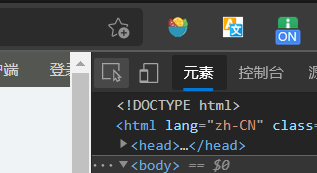
然后點擊上面欄的最左邊一個按鈕:
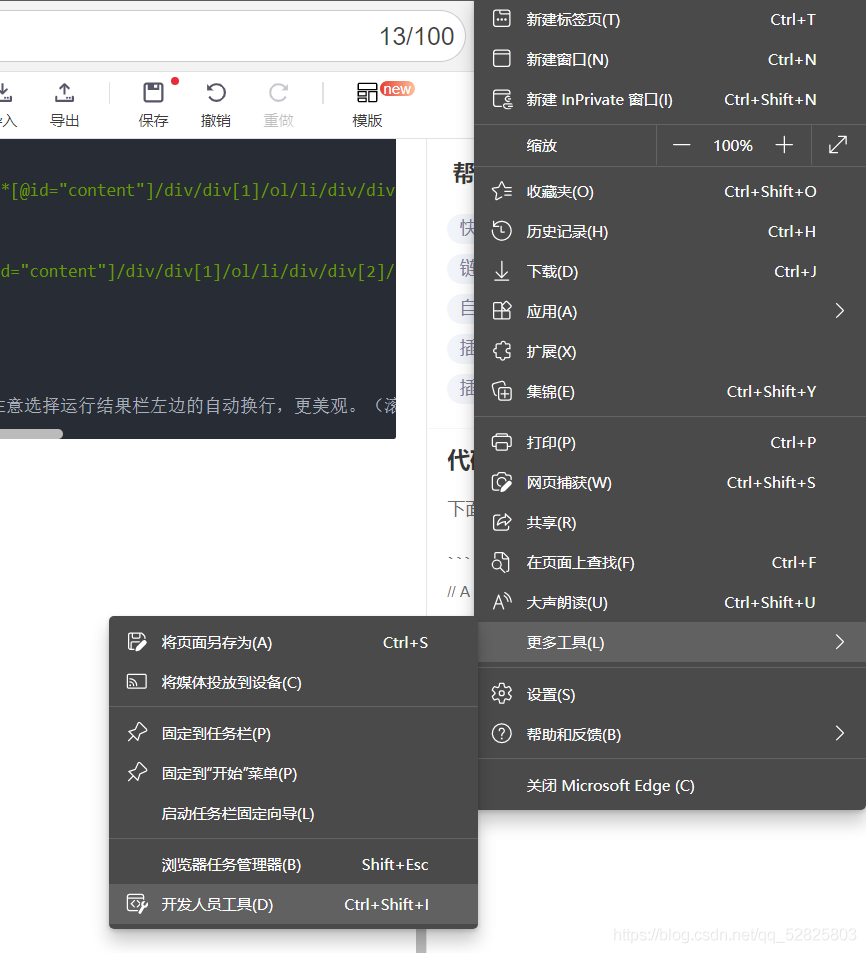
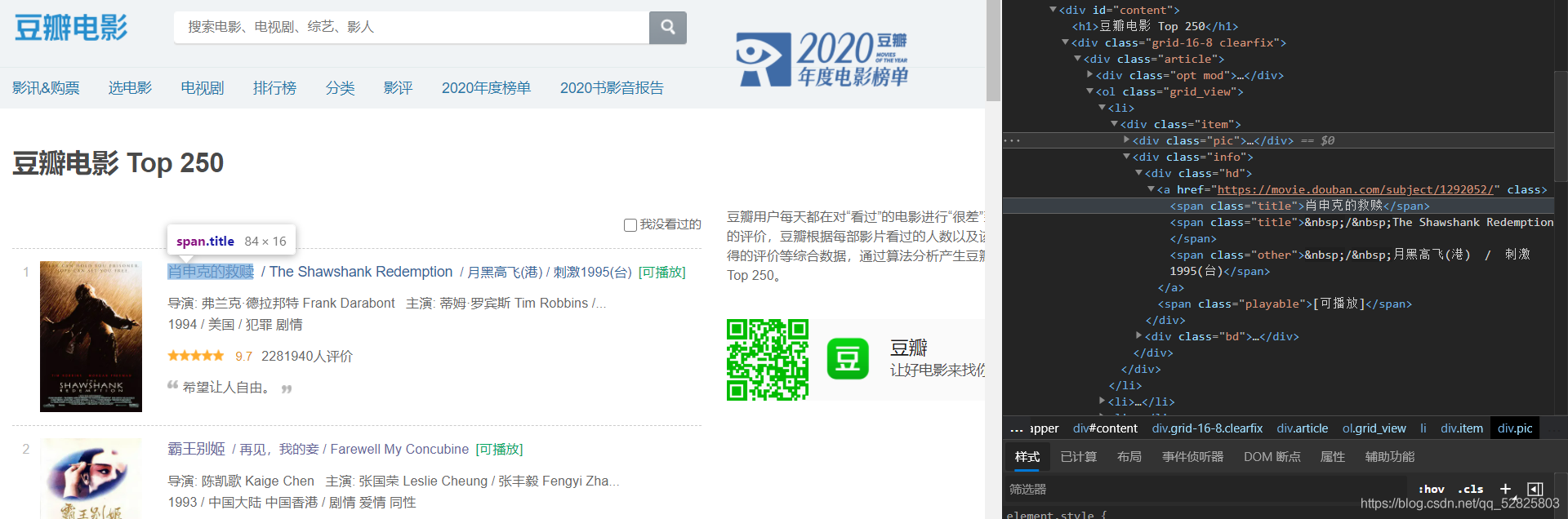
最后點擊你需要的內容,代碼會自動跟隨,復制/span的xpath即可:
打卡:day 1!!!
朋友們年后加油啊!!!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/261486.html
標籤:python