本文的文字及圖片來源于網路,僅供學習、交流使用,不具有任何商業用途,如有問題請及時聯系我們以作處理,
以下文章來源于Python爬蟲資料分析挖掘 ,作者李運辰
Python爬蟲、資料分析、網站開發等案例教程視頻免費在線觀看
https://space.bilibili.com/523606542

前言
今年給大家爬取『大年初一』上映的幾部熱門資料(評分、時長、型別)以及相關網友評論等資料
對評分、時長、型別進行圖表可視化
采用不同詞云圖案對七部電影『評論』詞云秀!!!!
資料獲取
1.評分資料
網頁分析
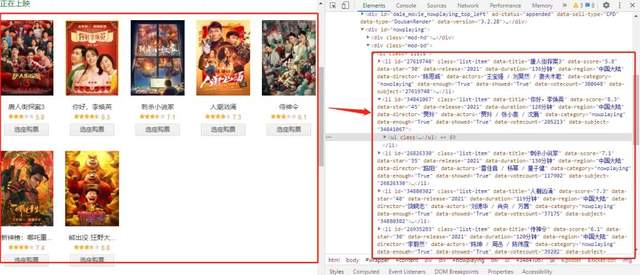
查看網頁源代碼,可以見到目標資料在標簽<ul >,通過xpath決議就可以獲取,下面直接上代碼!
編程實作
headers = { 'Host':'movie.douban.com', 'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36', 'cookie':'bid=uVCOdCZRTrM; douban-fav-remind=1; __utmz=30149280.1603808051.2.2.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=(not%20provided); __gads=ID=7ca757265e2366c5-22ded2176ac40059:T=1603808052:RT=1603808052:S=ALNI_MYZsGZJ8XXb1oU4zxzpMzGdK61LFA; dbcl2="165593539:LvLaPIrgug0"; push_doumail_num=0; push_noty_num=0; __utmv=30149280.16559; ll="118288"; __yadk_uid=DnUc7ftXIqYlQ8RY6pYmLuNPqYp5SFzc; _vwo_uuid_v2=D7ED984782737D7813CC0049180E68C43|1b36a9232bbbe34ac958167d5bdb9a27; ct=y; ck=ZbYm; __utmc=30149280; __utmc=223695111; __utma=30149280.1867171825.1603588354.1613363321.1613372112.11; __utmt=1; __utmb=30149280.2.10.1613372112; ap_v=0,6.0; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1613372123%2C%22https%3A%2F%2Fwww.douban.com%2Fmisc%2Fsorry%3Foriginal-url%3Dhttps%253A%252F%252Fmovie.douban.com%252Fsubject%252F34841067%252F%253Ffrom%253Dplaying_poster%22%5D; _pk_ses.100001.4cf6=*; __utma=223695111.788421403.1612839506.1613363340.1613372123.9; __utmb=223695111.0.10.1613372123; __utmz=223695111.1613372123.9.4.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/misc/sorry; _pk_id.100001.4cf6=e2e8bde436a03ad7.1612839506.9.1613372127.1613363387.', } url="https://movie.douban.com/cinema/nowplaying/zhanjiang/" r = requests.get(url,headers=headers) r.encoding = 'utf8' s = (r.content) selector = etree.HTML(s) li_list = selector.xpath('//*[@id="nowplaying"]/div[2]/ul/li') dict = {} for item in li_list: name = item.xpath('.//*[@]/a/@title')[0].replace(" ","").replace("\n","") rate = item.xpath('.//*[@]/text()')[0].replace(" ", "").replace("\n", "") dict[name] = float(rate) print("電影="+name) print("評分="+rate) print("-------")

電影名和評分資料已經爬取下來,并且降序排序,后面會進行可視化,
2.時長和電影型別
網頁分析
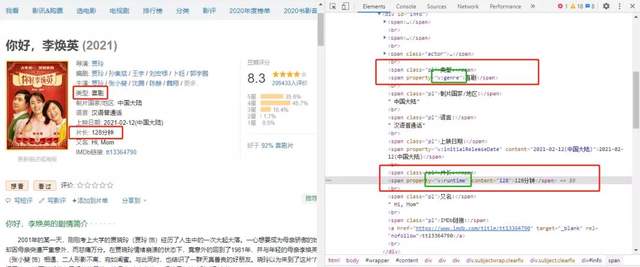
在頁面原始碼中,電影時長的網頁標簽是roperty="v:runtime",電影型別的網頁標簽對應是property="v:genre"
編程實作
###時長 def getmovietime(): url = "https://movie.douban.com/cinema/nowplaying/zhanjiang/" r = requests.get(url, headers=headers) r.encoding = 'utf8' s = (r.content) selector = etree.HTML(s) li_list = selector.xpath('//*[@id="nowplaying"]/div[2]/ul/li') for item in li_list: title = item.xpath('.//*[@]/a/@title')[0].replace(" ", "").replace("\n", "") href = item.xpath('.//*[@]/a/@href')[0].replace(" ", "").replace("\n", "") r = requests.get(href, headers=headers) r.encoding = 'utf8' s = (r.content) selector = etree.HTML(s) times = selector.xpath('//*[@property="v:runtime"]/text()') type = selector.xpath('//*[@property="v:genre"]/text()') print(title) print(times) print(type) print("-------")

3.評論資料
網頁分析
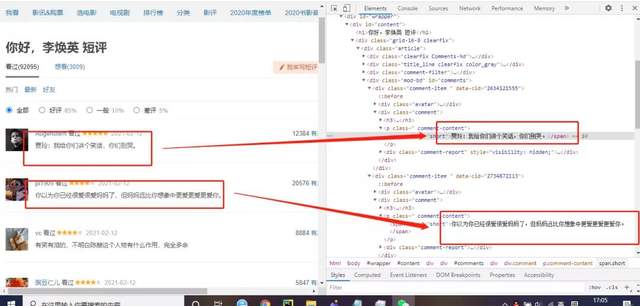
查看網頁代碼,評論資料的目標標簽是<div id="comments">
(不知道如何分析,可以看上一篇文章python爬取44130條用戶觀影資料,分析挖掘用戶與電影之間的隱藏資訊!,這篇文章也是分析豆瓣電影,里面有詳細介紹),
下面開始爬取這七部電影的評論資料!!!!
編程實作
###評論資料 def getmoviecomment(): url = "https://movie.douban.com/cinema/nowplaying/zhanjiang/" r = requests.get(url, headers=headers) r.encoding = 'utf8' s = (r.content) selector = etree.HTML(s) li_list = selector.xpath('//*[@id="nowplaying"]/div[2]/ul/li') for item in li_list: title = item.xpath('.//*[@]/a/@title')[0].replace(" ", "").replace("\n", "") href = item.xpath('.//*[@]/a/@href')[0].replace(" ", "").replace("\n", "").replace("/?from=playing_poster", "") print("電影=" + title) print("鏈接=" + href) ### with open(title+".txt","a+",encoding='utf-8') as f: for k in range(0,200,20): url = href+"/comments?start="+str(k)+"&limit=20&status=P&sort=new_score" r = requests.get(url, headers=headers) r.encoding = 'utf8' s = (r.content) selector = etree.HTML(s) li_list = selector.xpath('//*[@]') for items in li_list: text = items.xpath('.//*[@]/text()')[0] f.write(str(text)+"\n") print("-------") time.sleep(4)
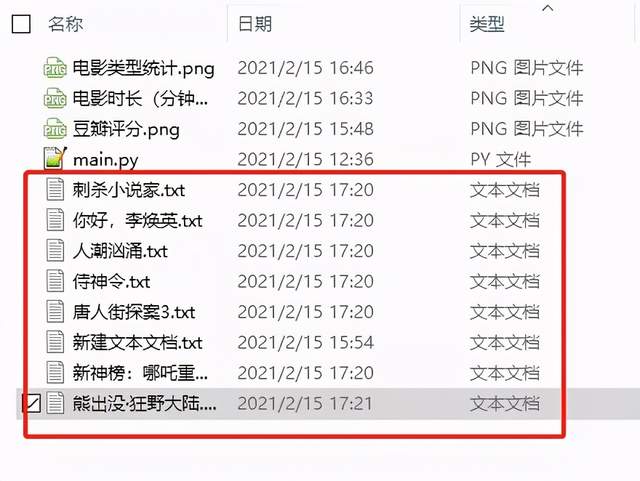
將這些評論資料分別保存到文本檔案中,后面將這些評論資料采用不同的圖形進行可視化展示!!!!
資料可視化
1.評分資料可視化
###畫圖 font_size = 10 # 字體大小 fig_size = (13, 10) # 圖表大小 data = ([datas]) # 更新字體大小 mpl.rcParams['font.size'] = font_size # 更新圖表大小 mpl.rcParams['figure.figsize'] = fig_size # 設定柱形圖寬度 bar_width = 0.35 index = np.arange(len(data[0])) # 繪制評分 rects1 = plt.bar(index, data[0], bar_width, color='#0072BC') # X軸標題 plt.xticks(index + bar_width, itemNames) # Y軸范圍 plt.ylim(ymax=10, ymin=0) # 圖表標題 plt.title(u'豆瓣評分') # 圖例顯示在圖表下方 plt.legend(loc='upper center', bbox_to_anchor=(0.5, -0.03), fancybox=True, ncol=5) # 添加資料標簽 def add_labels(rects): for rect in rects: height = rect.get_height() plt.text(rect.get_x() + rect.get_width() / 2, height, height, ha='center', va='bottom') # 柱形圖邊緣用白色填充,純粹為了美觀 rect.set_edgecolor('white') add_labels(rects1) # 圖表輸出到本地 plt.savefig('豆瓣評分.png')
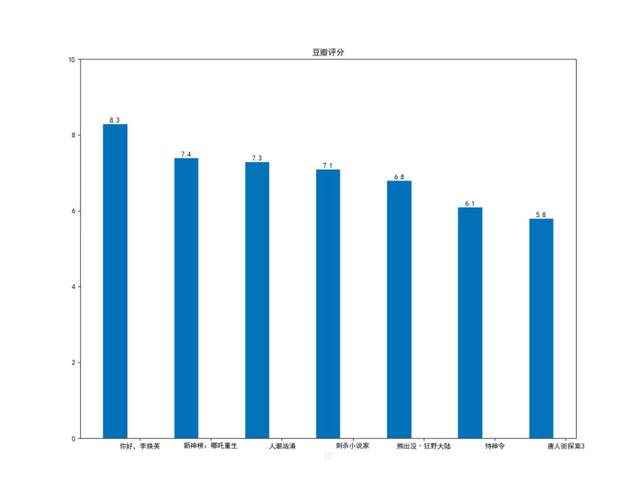
在熱映的這七部電影中,《你好,李煥英》評分最高(8.3),《唐人街探案3》最低(5.8),這有點出乎意料(唐人街探案3熱度遠比你好,李煥英熱度要高),
2.時長和型別可視化
時長資料可視化
#####時長可視化 itemNames.reverse() datas.reverse() # 繪圖, fig, ax = plt.subplots() b = ax.barh(range(len(itemNames)), datas, color='#6699CC') # 為橫向水平的柱圖右側添加資料標簽, for rect in b: w = rect.get_width() ax.text(w, rect.get_y() + rect.get_height() / 2, '%d' % int(w), ha='left', va='center') # 設定Y軸縱坐標上的刻度線標簽, ax.set_yticks(range(len(itemNames))) ax.set_yticklabels(itemNames) plt.title('電影時長(分鐘)', loc='center', fontsize='15', fontweight='bold', color='red') #plt.show() plt.savefig("電影時長(分鐘)")
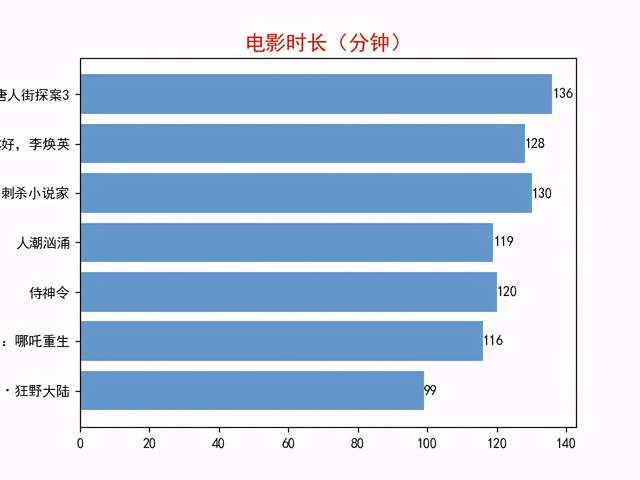
圖中的電影時長均在120分鐘左右
最長的電影《唐人街探案3》(136分鐘),時長最短的是《熊出沒·狂野大陸》(99分鐘)
電影型別資料可視化
#####2.型別可視化 ###從小到大排序 dict = sorted(dict.items(), key=lambda kv: (kv[1], kv[0])) print(dict) itemNames = [] datas = [] for i in range(len(dict) - 1, -1, -1): itemNames.append(dict[i][0]) datas.append(dict[i][1]) x = range(len(itemNames)) plt.plot(x, datas, marker='o', mec='r', mfc='w', label=u'電影型別') plt.legend() # 讓圖例生效 plt.xticks(x, itemNames, rotation=45) plt.margins(0) plt.subplots_adjust(bottom=0.15) plt.xlabel(u"型別") # X軸標簽 plt.ylabel("數量") # Y軸標簽 plt.title("電影型別統計") # 標題 plt.savefig("電影型別統計.png")
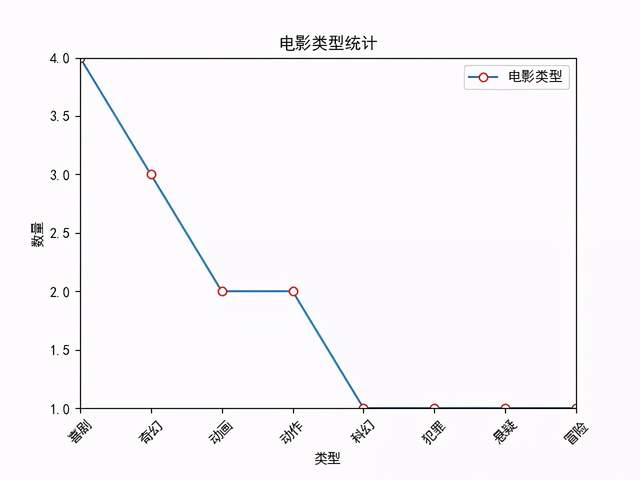
將這七部電影的型別進行統計(有的電影屬于多個型別,比如'動作', '奇幻', '冒險'),七部電影中其中有四部是屬于喜劇,科幻、犯罪、懸疑、冒險均屬于其中一部,
3.評論資料詞云可視化
使用七種不同的圖案進行詞云可視化,因此將繪圖的代碼封裝成函式!!!
####詞云代碼
def jieba_cloud(file_name, icon):
with open(file_name, 'r', encoding='utf8') as f:
text = f.read()
text = text.replace('\n',"").replace("\u3000","").replace(",","").replace(",","")
word_list = jieba.cut(text)
result = " ".join(word_list) # 分詞用 隔開
# 制作中文云詞
icon_name = ""
if icon == "1":
icon_name ='fas fa-envira'
elif icon == "2":
icon_name = 'fas fa-dragon'
elif icon == "3":
icon_name = 'fas fa-dog'
elif icon == "4":
icon_name = 'fas fa-cat'
elif icon == "5":
icon_name = 'fas fa-dove'
elif icon == "6":
icon_name = 'fab fa-qq'
elif icon == "7":
icon_name = 'fas fa-cannabis'
"""
# icon_name='',#國旗
# icon_name='fas fa-dragon',#翼龍
icon_name='fas fa-dog',#狗
# icon_name='fas fa-cat',#貓
# icon_name='fas fa-dove',#鴿子
# icon_name='fab fa-qq',#qq
"""
picp = file_name.split('.')[0] + '.png'
if icon_name is not None and len(icon_name) > 0:
gen_stylecloud(text=result, icon_name=icon_name, font_path='simsun.ttc', output_name=picp) # 必須加中文字體,否則格式錯誤
else:
gen_stylecloud(text=result, font_path='simsun.ttc', output_name=picp) # 必須加中文字體,否則格式錯誤
return picp
開始對這七部電影評論資料進行繪圖

###評論資料詞云
def commentanalysis():
lists = ['刺殺小說家','你好,李煥英','人潮洶涌','侍神令','唐人街探案3','新神榜:哪吒重生','熊出沒·狂野大陸']
for i in range(0,len(lists)):
title =lists[i]+".txt"
jieba_cloud(title , (i+1))廢話不多說了,下面開始『詞云秀』!!!!!!!
1.刺殺小說家

2.人潮洶涌

3.熊出沒·狂野大陸

4.新神榜:哪吒重生

5.唐人街探案3

6.你好,李煥英

7.侍神令

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/261620.html
標籤:Python