K-means演算法
K-means是機器學習中很常用的聚類演算法, 關于K-means演算法的數學原理, 演算法, 偽代碼等已經有非常豐富的文獻資料, 這里就不介紹了. 直接看代碼.
- 呼叫以下庫
import numpy as np #用于抽樣和生成亂數
from sklearn.cluster import KMeans #sklearn自帶的Kmeans演算法, 用于嚴重本文演算法結果是否正確
import matplotlib.pyplot as plt #結果可視化
import sys #需要用到sys.exit()函式
如果你不需要驗證聚類結果可以不使用Sklearn庫
- 生成用于訓練的隨機資料
np.set_printoptions(suppress=True) #令numpy的結果不以科學計數法的方式輸出
Data = np.array([[1.0, 2.0], [1.5, 1.8], [3, 4], [6, 8], [8, 8], [1, 0.6],
[9, 11], [7, 10]]) #你也可以通過抽樣的方式來更快的獲得測驗資料
- 定義用于選擇隨機初始點和簇數(k)的函式
def K_means(data, k):
global Mean
mean = []
a = np.max(data[:, 0])
b = np.min(data[:, 0])
c = np.max(data[:, 1])
d = np.min(data[:, 1])
for i in range(k):
x = np.random.uniform(a, b, 1)
#此處回傳array
y = np.random.uniform(c, d, 1) #此處回傳array
mean.append([float(x), float(y)])
Mean = np.array(mean)
return Mean
上方代碼中為了限定初始點(x,y)的位置不過分遠離樣本點, 所以將均勻抽樣的上下限定為了訓練資料橫縱坐標的最大最小區間(a,b)和(c,d).
- 定義可視化函式, 繪制測驗資料散點圖
def vision(data, cell):
plt.figure(figsize=(12,6))
ax1 = plt.subplot(121)
ax1.scatter(Data[:, 0], Data[:, 1]) #原始資料散點圖
ax1.scatter(point[:, 0], point[:, 0]) #同時將隨機選取的初始點表示出來
plt.xlabel("x")
plt.ylabel("y")
plt.title("scatter of " + "rural" + " data")
ax2 = plt.subplot(122)
ax2.scatter(Data[:, 0], Data[:, 1]) #原始資料散點圖
ax2.scatter(data[:, 0], data[:, 1]) #經過迭代后最終確定的聚類點
plt.xlabel("x")
plt.ylabel("y")
plt.title("scatter of " + cell + " data")
plt.show()
將聚類結果可視化對判斷聚類結果是否準確非常重要.
- 定義迭代程序, 通過不斷計算各個樣本對聚類點的歐式聚類, 來不斷更新聚類點
def iteration(Data, point):
A = []
B = []
for i in range(len(Data)):
d1 = np.sqrt(sum(pow(Data[i] - point[0], 2)))
d2 = np.sqrt(sum(pow(Data[i] - point[1], 2)))
if d1 > d2:
A.append(list(Data[i]))
else:
B.append(list(Data[i]))
if len(A) == len(Data) or len(B) == len(Data):
print("初始化錯誤")
sys.exit(0)
new_x1 = np.mean(np.array(A)[:, 0])
new_y1 = np.mean(np.array(A)[:, 1])
new_x2 = np.mean(np.array(B)[:, 0])
new_y2 = np.mean(np.array(B)[:, 1])
new_point = np.array([[new_x1, new_y1], [new_x2, new_y2]])
return new_point
注意, 上段代碼中加入了一個if陳述句
if len(A) == len(Data) or len(B) == len(Data):
print("初始化錯誤")
sys.exit(0)
這個條件陳述句是非常必要的, 因為初始點是隨機生成的, 那么就有可能會出現所有樣本點都只靠近一個聚類中心而遠離另外一個聚類中心, 這樣就無法形成兩個簇, 程式會報錯, 所以我們需要剔除這種情況的發生. 一旦所有的樣本點只靠近一個聚類中心時令程式停止.
- 執行迭代
def fit(Data, object, n=20, max_iter=300, eps=1e-5,plot=None):
err = 0
for i in range(n):
res = iteration(Data, object)
print(res)
if plot == True:
vision(res,cell="object")
else:
pass
return res
如果不指定迭代次數那么將默認迭代20次, 但最大迭代次數不超過300次, plot=True時可視化聚類結果, 默認不進行可視化
- 完整代碼如下
import numpy as np
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
import sys
np.set_printoptions(suppress=True)
Data = np.array([[1.0, 2.0], [1.5, 1.8], [3, 4], [6, 8], [8, 8], [1, 0.6],
[9, 11], [7, 10]]) #實驗資料
def K_means(data, k):
global Mean
mean = []
a = np.max(data[:, 0])
b = np.min(data[:, 0])
c = np.max(data[:, 1])
d = np.min(data[:, 1])
for i in range(k):
x = np.random.uniform(a, b, 1)
#此處回傳array
y = np.random.uniform(c, d, 1) #此處回傳array
mean.append([float(x), float(y)])
Mean = np.array(mean)
return Mean
def vision(data, cell):
plt.figure(figsize=(12,6))
ax1 = plt.subplot(121)
ax1.scatter(Data[:, 0], Data[:, 1])
ax1.scatter(point[:, 0], point[:, 0])
plt.xlabel("x")
plt.ylabel("y")
plt.title("scatter of " + "rural" + " data")
ax2 = plt.subplot(122)
ax2.scatter(Data[:, 0], Data[:, 1])
ax2.scatter(data[:, 0], data[:, 1])
plt.xlabel("x")
plt.ylabel("y")
plt.title("scatter of " + cell + " data")
plt.show()
def iteration(Data, point):
A = []
B = []
for i in range(len(Data)):
d1 = np.sqrt(sum(pow(Data[i] - point[0], 2)))
d2 = np.sqrt(sum(pow(Data[i] - point[1], 2)))
if d1 > d2:
A.append(list(Data[i]))
else:
B.append(list(Data[i]))
if len(A) == len(Data) or len(B) == len(Data):
print("初始化錯誤")
sys.exit(0)
new_x1 = np.mean(np.array(A)[:, 0])
new_y1 = np.mean(np.array(A)[:, 1])
new_x2 = np.mean(np.array(B)[:, 0])
new_y2 = np.mean(np.array(B)[:, 1])
new_point = np.array([[new_x1, new_y1], [new_x2, new_y2]])
return new_point
def fit(Data, object, n=20, max_iter=300, eps=1e-5,plot=None):
err = 0
for i in range(n):
res = iteration(Data, object)
print(res)
if plot == True:
vision(res,cell="object")
else:
pass
return res
point = K_means(Data, 2)
fit(Data=Data, object=point,plot=True)
從上述代碼來看, 實際上Kmeans演算法只有兩個核心的程序: point = K_means(Data, 2) 生成初始點并給定簇數; 執行迭代fit(Data=Data, object=point,plot=True)
- 執行結果
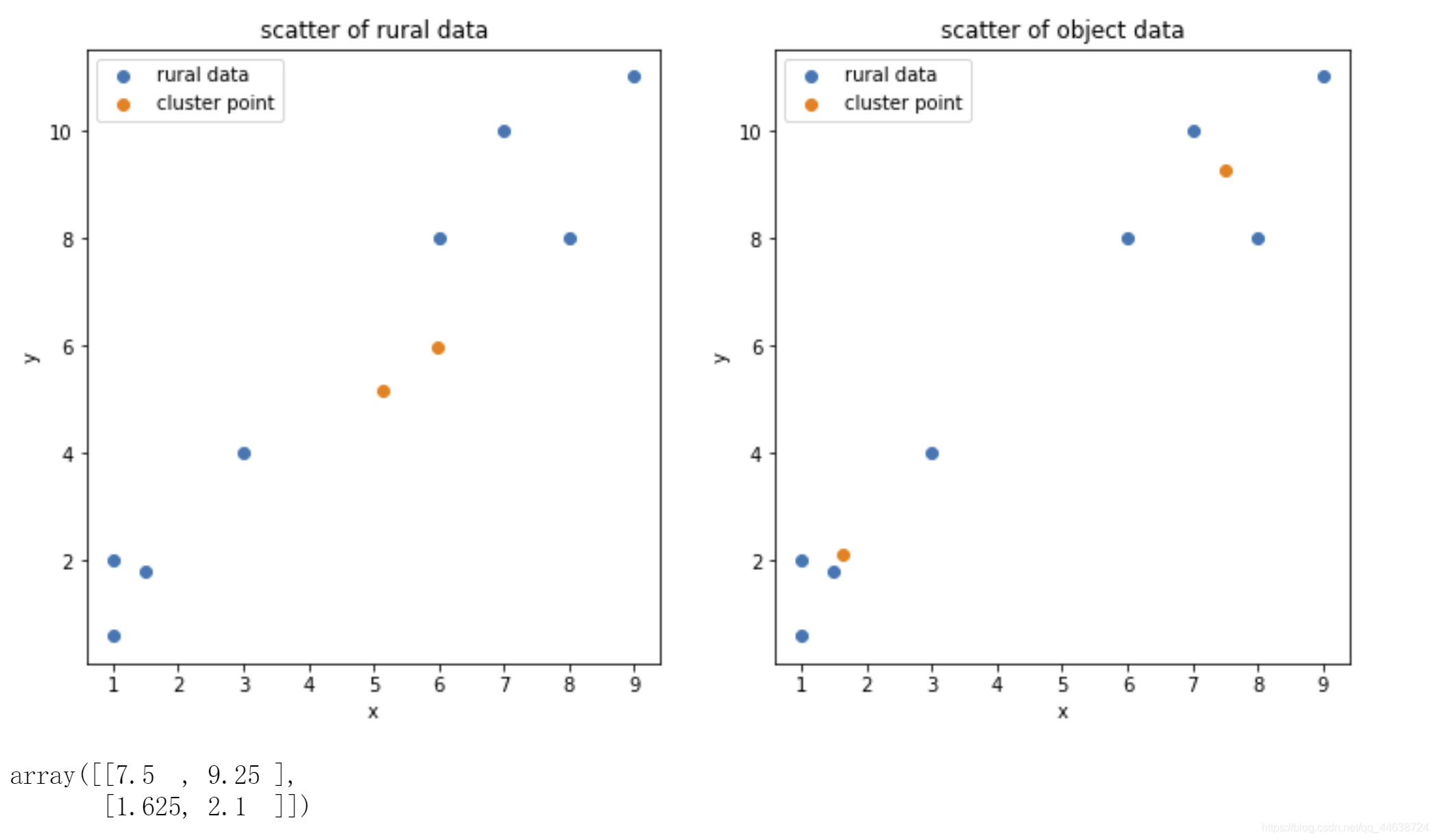
可以看到最終的聚類中心是(1.625, 2.1)和(7.5, 9.25), 那么這個結果是否正確呢?接下來將同樣的資料集放入Sklearn.KMeans中運行
clf = KMeans(n_clusters=2)
clf.fit(Data) # 分組
centers = clf.cluster_centers_ # 兩組資料點的中心點
labels = clf.labels_ # 每個資料點所屬分組
print(centers)
- Sklearn運行結果

可以看到結果與本文代碼保持一致. 但本文加入了聚類結果的可視化, 同時也能給出簇中包含了那些樣本, 因為在迭代函式iteration(Data, point)中將它們存入了A和B兩個串列中, 只需要return A, B就可以得到它們.
tips
K-means這種聚類演算法需要給定初始點, 而聚類結果又非常依賴初始點的位置, 這就導致了上述代碼多次運行時可能會得到不一樣的結果, 這與Sklearn.KMeans的情況相同, 所以這并不是程式出現了前后不一的錯誤, 而是演算法本身的局限性所導致的. 所以你應該多次運行聚類演算法才能得到穩定的聚類中心. 關于K-means演算法的詳細解釋可以參考Sklearn庫給出的KMeans手冊.
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/261876.html
標籤:python
下一篇:c語言陣列問題求教!!!