2.11 生成可控的隨機資料集合
1、首先我們需要了解一些術語
(1)分布或者概率分布:表示統計實驗的結果和發生概率之間的聯系,
(2)標準差:這個數值表示個體和群體之間的差異,如果差異很大,標準差會比較大;如果所有個體實驗在整組范圍內基本相同,標準差會比較小,
(3)方差:標準差的平方
(4)總體或者統計總體(Population or statisticalpopulation):所有潛在的可觀測案例的集合
(5)樣本:這是總體的子集
2、用Python的random模塊生成一個簡單的隨機樣本資料
import pylab
import random
SAMPLE_SIZE = 100
"""
種子隨機發生器
如果沒有提供引數
使用系統當前時間
"""
random.seed()
# 在此處存盤生成的隨機值
real_rand_vars = []
# 我們不需要迭代器值,我們把它叫做‘—’
for _ in range(SAMPLE_SIZE):
# 獲取下一個隨機值
new_value = random.random()
real_rand_vars.append(new_value)
# 從10個桶中的資料創建直方圖
pylab.hist(real_rand_vars, 10)
# 定義x和y標簽
pylab.xlabel("Number Range")
pylab.ylabel("Count")
pylab.show()
這是一個均勻分布的資料樣本,可以運行看到如下圖:
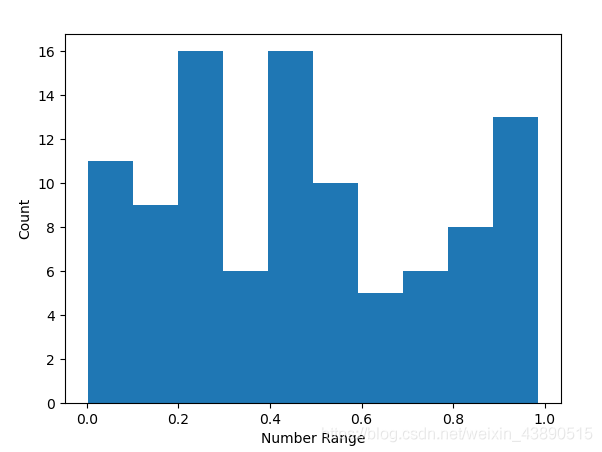
可以用random.randint(min, max),這里的 min 和 max 指相應的下限和上限,如果想生成浮點數而不是整數的樣本,可以用random.uniform(min, max)方法
3、生成虛擬價格增長資料的時序圖,并加上一些隨機噪聲
代碼實作如下:
"""
生成虛擬價格增長資料的時序圖,并加上一些隨機噪聲
"""
import pylab
import random
# 生成資料的天數
duration = 100
# 平均值
mean_inc = 0.2
# standard deviation(標準差)
std_dev_inc = 1.2
# time series(時間序列)
x=range(duration)
y=[]
price_today=0
for i in x:
next_delta=random.normalvariate(mean_inc,std_dev_inc)
price_today+=next_delta
y.append(price_today)
pylab.plot(x,y)
pylab.xlabel("Time")
pylab.ylabel("Value")
pylab.show()
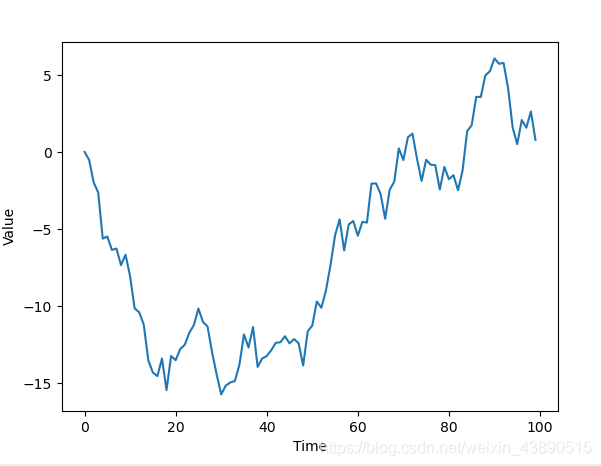
這段代碼定義了100個資料點(虛擬天數)的序列,
對于接下來的每一天,從中值為mean_inc,標準差為std_dev_inc的正態分布(random.normalvariate())中選取一個隨機值,然后加上前一天的價格(price_today)作為當天的價格,
4、如果想要更多的控制,可以使用不同的分布,下面的代碼說明并展示了不同的分布,
代碼實作如下:
import random
import matplotlib
import matplotlib.pyplot as plt
SAMPLE_SIZE = 1000
# 直方圖
buckets = 10
plt.figure()
# 我們需要為這個例子更新字體大小
matplotlib.rcParams.update({'font.size': 7})
plt.subplot(621)
plt.xlabel('random.random')
# 回傳[0.0,1.0]范圍內的下一個隨機浮點數,
res = []
for _ in range(1, SAMPLE_SIZE):
res.append(random.random())
plt.hist(res, buckets)
plt.subplot(622)
plt.xlabel('random.uniform')
# 回傳一個隨機浮點數N,使a<=N<=b表示a<=b,b<=N<=a表示b<a,
# 根據等式a+(b-a)*random()中的浮點舍入,端點值b可以包括在范圍內,也可以不包括在范圍內
a = 1
b = SAMPLE_SIZE
res = []
for _ in range(1, SAMPLE_SIZE):
res.append(random.uniform(a, b))
plt.hist(res, buckets)
plt.subplot(623)
plt.xlabel("random.triangular")
"""
回傳一個隨機浮點數N,使low<=N<=high,并且指定的模式位于這些界限之間,
下限和上限默認為0和1,mode引數默認為邊界之間的中點,提供對稱分布,
"""
low = 1
high = SAMPLE_SIZE
res = []
for _ in range(1, SAMPLE_SIZE):
res.append(random.triangular(low, high))
plt.hist(res, buckets)
plt.subplot(624)
plt.xlabel("random.betavariate")
# β分布,引數的條件是alpha>0和beta>0,回傳值的范圍介于0和1之間
alpha = 1
beta = 10
res = []
for _ in range(1,SAMPLE_SIZE):
res.append(random.betavariate(alpha,beta))
plt.hist(res,buckets)
plt.subplot(625)
plt.xlabel("random.expovariate")
"""
指數分布,lambd為1.0除以所需平均值,它應該是非零的,
(引數將被稱為“lambda”,但在Python中這是一個保留字,)
如果lambd為正,則回傳值的范圍是從0到正無窮大;
如果lambd為負,則回傳值的范圍是從負無窮大到0
"""
lambd=1.0/((SAMPLE_SIZE+1)/2.)
res=[]
for _ in range(1,SAMPLE_SIZE):
res.append(random.expovariate(lambd))
plt.hist(res,buckets)
plt.subplot(626)
plt.xlabel("random.gammavariate")
"""
伽馬分布,(不是gamma函式!)引數的條件是alpha>0和beta>0,
概率分布函式為:
x ** (alpha - 1) * math.exp(-x / beta)
pdf(x) = --------------------------------------
math.gamma(alpha) * beta ** alpha
"""
alpha = 1
beta = 10
res = []
for _ in range(1,SAMPLE_SIZE):
res.append(random.gammavariate(alpha,beta))
plt.hist(res,buckets)
plt.subplot(627)
plt.xlabel("random.lognormvariate")
"""
對數正態分布,如果你取這個分布的自然對數,你會得到一個正態分布,
平均μ和標準偏差σ,mu可以有任何值,sigma必須大于零,
"""
mu = 1
sigma = 0.5
res = []
for _ in range(1,SAMPLE_SIZE):
res.append(random.lognormvariate(mu,sigma))
plt.hist(res,buckets)
plt.subplot(628)
plt.xlabel("random.normalvariate")
"""
正態分布,mu是平均值,sigma是標準差,
"""
mu = 1
sigma = 0.5
res=[]
for _ in range(1,SAMPLE_SIZE):
res.append(random.normalvariate(mu,sigma))
plt.hist(res,buckets)
plt.subplot(629)
plt.xlabel("random.paretovariate")
"""
帕累托分布,alpha是形狀引數,
"""
alpha = 1
res = []
for _ in range(1,SAMPLE_SIZE):
res.append(random.paretovariate(alpha))
plt.hist(res,buckets)
plt.tight_layout()
plt.show()
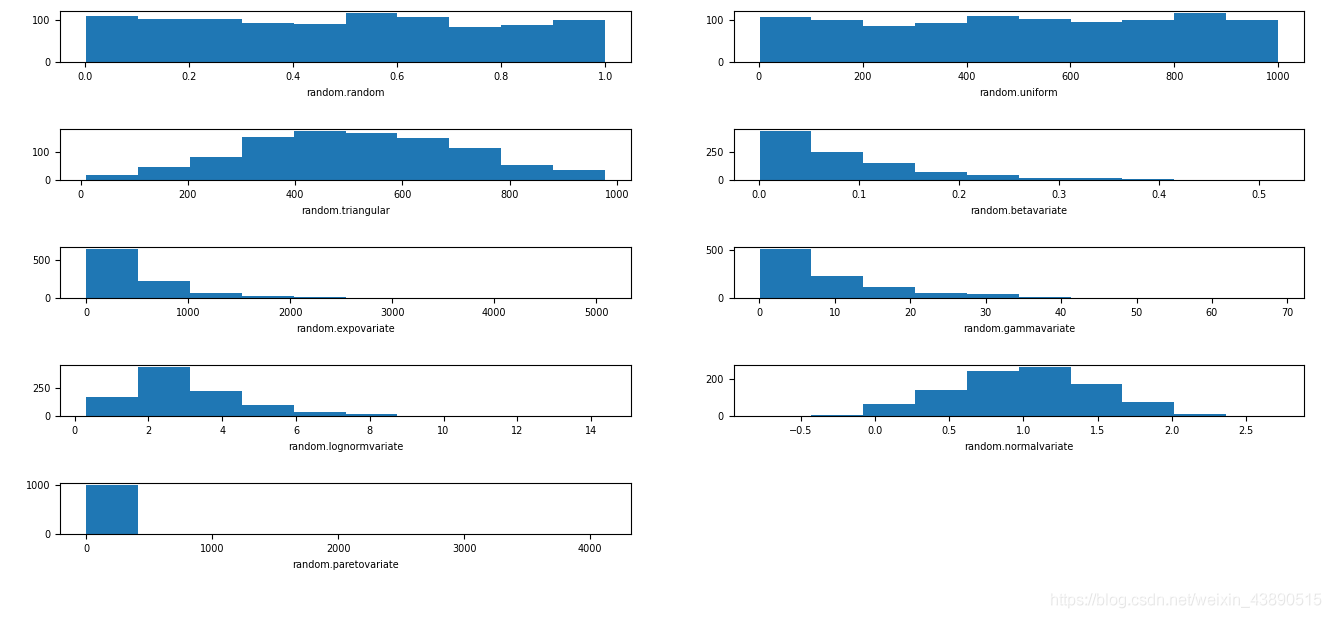
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/262041.html
標籤:python