本文將介紹:
- 如何實作tensorflow動態按需分配GPU
- 實作卷積神經網路實戰代碼
一、實作tensorflow動態按需分配GPU
關于tf動態分配記憶體可參考文章https://blog.csdn.net/TFATS/article/details/113978075
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
import tensorflow as tf
from tensorflow import keras
# 1,實作tensorflow動態按需分配GPU
from tensorflow.compat.v1 import ConfigProto
from tensorflow.compat.v1 import InteractiveSession
config = ConfigProto()
config.gpu_options.allow_growth = True
session = InteractiveSession(config=config)
# 列印使用的python庫的版本資訊
print(tf.__version__)
print(sys.version_info)
for module in mpl, np, pd, sklearn, tf, keras:
print(module.__name__, module.__version__)
二,實作卷積神經網路實戰代碼
1,從tf.keras.datasets中取資料
fashion_mnist = keras.datasets.fashion_mnist
(x_train_all, y_train_all), (x_test, y_test) = fashion_mnist.load_data()
x_valid, x_train = x_train_all[:5000], x_train_all[5000:]
y_valid, y_train = y_train_all[:5000], y_train_all[5000:]
print(x_valid.shape, y_valid.shape)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
2,將資料整合為標準化資料
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# 整合資料為1通道資料
x_train_scaled = scaler.fit_transform(
x_train.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1)
x_valid_scaled = scaler.transform(
x_valid.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1)
x_test_scaled = scaler.transform(
x_test.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1)
3,構建CNN模型
model = keras.models.Sequential()
model.add(keras.layers.Conv2D(filters=32, kernel_size=3,# 32個神經元;卷積核尺寸為3
padding='same', # padding填充像素至與原來相同
activation='selu', # 或者使用relu激活函式
input_shape=(28, 28, 1))) # 輸入層為1通道28*28的影像
model.add(keras.layers.Conv2D(filters=32, kernel_size=3,
padding='same',
activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
model.add(keras.layers.Conv2D(filters=64, kernel_size=3,
padding='same',
activation='selu'))
model.add(keras.layers.Conv2D(filters=64, kernel_size=3,
padding='same',
activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
model.add(keras.layers.Conv2D(filters=128, kernel_size=3,
padding='same',
activation='selu'))
model.add(keras.layers.Conv2D(filters=128, kernel_size=3,
padding='same',
activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(128, activation='selu'))
model.add(keras.layers.Dense(10, activation="softmax"))
model.compile(loss="sparse_categorical_crossentropy",# 損失函式
optimizer = "sgd", # 優化器
metrics = ["accuracy"]) # 其他衡量指標
4,查看模型層級和引數
model.summary()
5,定義callback 并 訓練模型
logdir = './cnn-relu-callbacks'
if not os.path.exists(logdir):
os.mkdir(logdir)
output_model_file = os.path.join(logdir,
"fashion_mnist_model.h5")
callbacks = [
keras.callbacks.TensorBoard(logdir),
keras.callbacks.ModelCheckpoint(output_model_file,
save_best_only = True),
keras.callbacks.EarlyStopping(patience=5, min_delta=1e-3),
]
history = model.fit(x_train_scaled, y_train,epochs=10,
validation_data=(x_valid_scaled, y_valid),
callbacks = callbacks)
6,列印訓練曲線
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid(True)
plt.gca().set_ylim(0, 1)
plt.show()
plot_learning_curves(history)
7,列印估計器結果
print(model.evaluate(x_test_scaled, y_test, verbose = 0))
三,總結代碼
1,總結代碼-未做過擬合處理
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
import tensorflow as tf
from tensorflow import keras
# 1,實作tensorflow動態按需分配GPU
from tensorflow.compat.v1 import ConfigProto
from tensorflow.compat.v1 import InteractiveSession
config = ConfigProto()
config.gpu_options.allow_growth = True
session = InteractiveSession(config=config)
# 列印使用的python庫的版本資訊
print(tf.__version__)
print(sys.version_info)
for module in mpl, np, pd, sklearn, tf, keras:
print(module.__name__, module.__version__)
# 2,從tf.keras.datasets中取資料
fashion_mnist = keras.datasets.fashion_mnist
(x_train_all, y_train_all), (x_test, y_test) = fashion_mnist.load_data()
x_valid, x_train = x_train_all[:5000], x_train_all[5000:]
y_valid, y_train = y_train_all[:5000], y_train_all[5000:]
print(x_valid.shape, y_valid.shape)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
# 3,將資料整合為標準化資料
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# 整合資料為1通道資料
x_train_scaled = scaler.fit_transform(
x_train.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1)
x_valid_scaled = scaler.transform(
x_valid.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1)
x_test_scaled = scaler.transform(
x_test.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1)
# 4,構建CNN模型
model = keras.models.Sequential()
model.add(keras.layers.Conv2D(filters=32, kernel_size=3,# 32個神經元;卷積核尺寸為3
padding='same', # padding填充像素至與原來相同
activation='selu', # 或者使用relu激活函式
input_shape=(28, 28, 1))) # 輸入層為1通道28*28的影像
model.add(keras.layers.Conv2D(filters=32, kernel_size=3,
padding='same',
activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
model.add(keras.layers.Conv2D(filters=64, kernel_size=3,
padding='same',
activation='selu'))
model.add(keras.layers.Conv2D(filters=64, kernel_size=3,
padding='same',
activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
model.add(keras.layers.Conv2D(filters=128, kernel_size=3,
padding='same',
activation='selu'))
model.add(keras.layers.Conv2D(filters=128, kernel_size=3,
padding='same',
activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(128, activation='selu'))
model.add(keras.layers.Dense(10, activation="softmax"))
model.compile(loss="sparse_categorical_crossentropy",# 損失函式
optimizer = "sgd", # 優化器
metrics = ["accuracy"]) # 其他衡量指標
# 5,查看模型層級和引數
model.summary()
# 6,定義callback 并 訓練模型
logdir = './cnn-relu-callbacks'
if not os.path.exists(logdir):
os.mkdir(logdir)
output_model_file = os.path.join(logdir,
"fashion_mnist_model.h5")
callbacks = [
keras.callbacks.TensorBoard(logdir),
keras.callbacks.ModelCheckpoint(output_model_file,
save_best_only = True),
keras.callbacks.EarlyStopping(patience=5, min_delta=1e-3),
]
history = model.fit(x_train_scaled, y_train,epochs=10,
validation_data=(x_valid_scaled, y_valid),
callbacks = callbacks)
# 7,列印訓練曲線
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid(True)
plt.gca().set_ylim(0, 1)
plt.show()
plot_learning_curves(history)
# 8,列印估計器結果
print(model.evaluate(x_test_scaled, y_test, verbose = 0))
# ---output------
[0.3523516479730606, 0.9085]
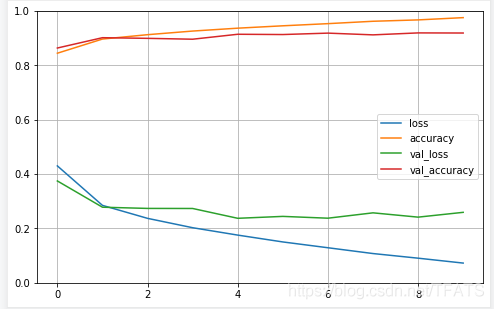
訓練曲線圖如下:
我們從圖中可以看到,訓練程序中已經出現了過擬合的現象,
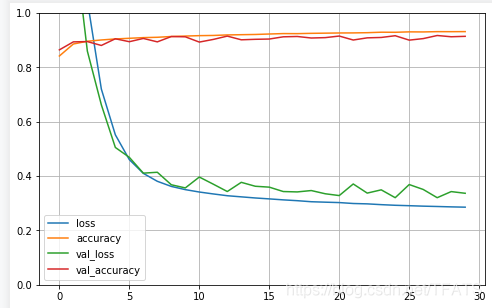
2,總結代碼-過擬合處理
添加了如下改動:
- set_seed - 使多次對比訓練中,隨機引數初始化為固定值,
- L2正則化 - 解決過擬合問題
- Dropout - 解決過擬合問題
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import sklearn
import pandas as pd
import os
import sys
import time
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import regularizers
my_seed = 666
np.random.seed(my_seed)
import random
random.seed(my_seed)
import tensorflow as tf
tf.random.set_seed(my_seed)
# 1,實作tensorflow動態按需分配GPU
from tensorflow.compat.v1 import ConfigProto
from tensorflow.compat.v1 import InteractiveSession
config = ConfigProto()
config.gpu_options.allow_growth = True
session = InteractiveSession(config=config)
# 列印使用的python庫的版本資訊
print(tf.__version__)
print(sys.version_info)
for module in mpl, np, pd, sklearn, tf, keras:
print(module.__name__, module.__version__)
# 2,從tf.keras.datasets中取資料
fashion_mnist = keras.datasets.fashion_mnist
(x_train_all, y_train_all), (x_test, y_test) = fashion_mnist.load_data()
x_valid, x_train = x_train_all[:5000], x_train_all[5000:]
y_valid, y_train = y_train_all[:5000], y_train_all[5000:]
print(x_valid.shape, y_valid.shape)
print(x_train.shape, y_train.shape)
print(x_test.shape, y_test.shape)
# 3,將資料整合為標準化資料
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
# 整合資料為1通道資料
x_train_scaled = scaler.fit_transform(
x_train.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1)
x_valid_scaled = scaler.transform(
x_valid.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1)
x_test_scaled = scaler.transform(
x_test.astype(np.float32).reshape(-1, 1)).reshape(-1, 28, 28, 1)
# 4,構建CNN模型
model = keras.models.Sequential()
model.add(keras.layers.Conv2D(filters=32, kernel_size=3,# 32個神經元;卷積核尺寸為3
padding='same', # padding填充像素至與原來相同
activation='selu', # 或者使用relu激活函式
kernel_regularizer=regularizers.l2(0.01),
input_shape=(28, 28, 1))) # 輸入層為1通道28*28的影像
model.add(keras.layers.Conv2D(filters=32, kernel_size=3,
padding='same',
kernel_regularizer=regularizers.l2(0.01),
activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
model.add(keras.layers.Conv2D(filters=64, kernel_size=3,
padding='same',
kernel_regularizer=regularizers.l2(0.01),
activation='selu'))
model.add(keras.layers.Conv2D(filters=64, kernel_size=3,
padding='same',
kernel_regularizer=regularizers.l2(0.01),
activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
model.add(keras.layers.Conv2D(filters=128, kernel_size=3,
padding='same',
kernel_regularizer=regularizers.l2(0.01),
activation='selu'))
model.add(keras.layers.Conv2D(filters=128, kernel_size=3,
padding='same',
kernel_regularizer=regularizers.l2(0.01),
activation='selu'))
model.add(keras.layers.MaxPool2D(pool_size=2))
model.add(keras.layers.Flatten())
model.add(keras.layers.Dense(128, activation='selu'))
# model.add(keras.layers.AlphaDropout(rate=0.5)) # 可以比對訓練結果決定是否需要加Dropout
model.add(keras.layers.Dense(10, activation="softmax"))
model.compile(loss="sparse_categorical_crossentropy",# 損失函式
optimizer = "sgd", # 優化器
metrics = ["accuracy"]) # 其他衡量指標s
# 5,查看模型層級和引數
model.summary()
# 6,定義callback 并 訓練模型
logdir = './cnn-relu-callbacks'
if not os.path.exists(logdir):
os.mkdir(logdir)
output_model_file = os.path.join(logdir,
"fashion_mnist_model.h5")
callbacks = [
keras.callbacks.TensorBoard(logdir),
keras.callbacks.ModelCheckpoint(output_model_file,
save_best_only = True),
keras.callbacks.EarlyStopping(patience=5, min_delta=1e-3),
]
history = model.fit(x_train_scaled, y_train,epochs=30,
validation_data=(x_valid_scaled, y_valid),
callbacks = callbacks)
# 7,列印訓練曲線
def plot_learning_curves(history):
pd.DataFrame(history.history).plot(figsize=(8, 5))
plt.grid(True)
plt.gca().set_ylim(0, 1)
plt.show()
plot_learning_curves(history)
# 8,列印估計器結果
print(model.evaluate(x_test_scaled, y_test, verbose = 0))
# ---output-------
[0.3523516479730606, 0.9085]
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/262925.html
標籤:python