python selenium操作一個頁面的多個并列文章
- 實作目標
- 方法
- 重點
- 代碼:
- 最后
實作目標
? ?
對于一個網頁中有一連串的文章,想要獲取這一連串的文章,通過selenium自動化實作某些功能
方法
右擊網頁—>檢查—>找到下圖目標文章塊兒的部分
?
?
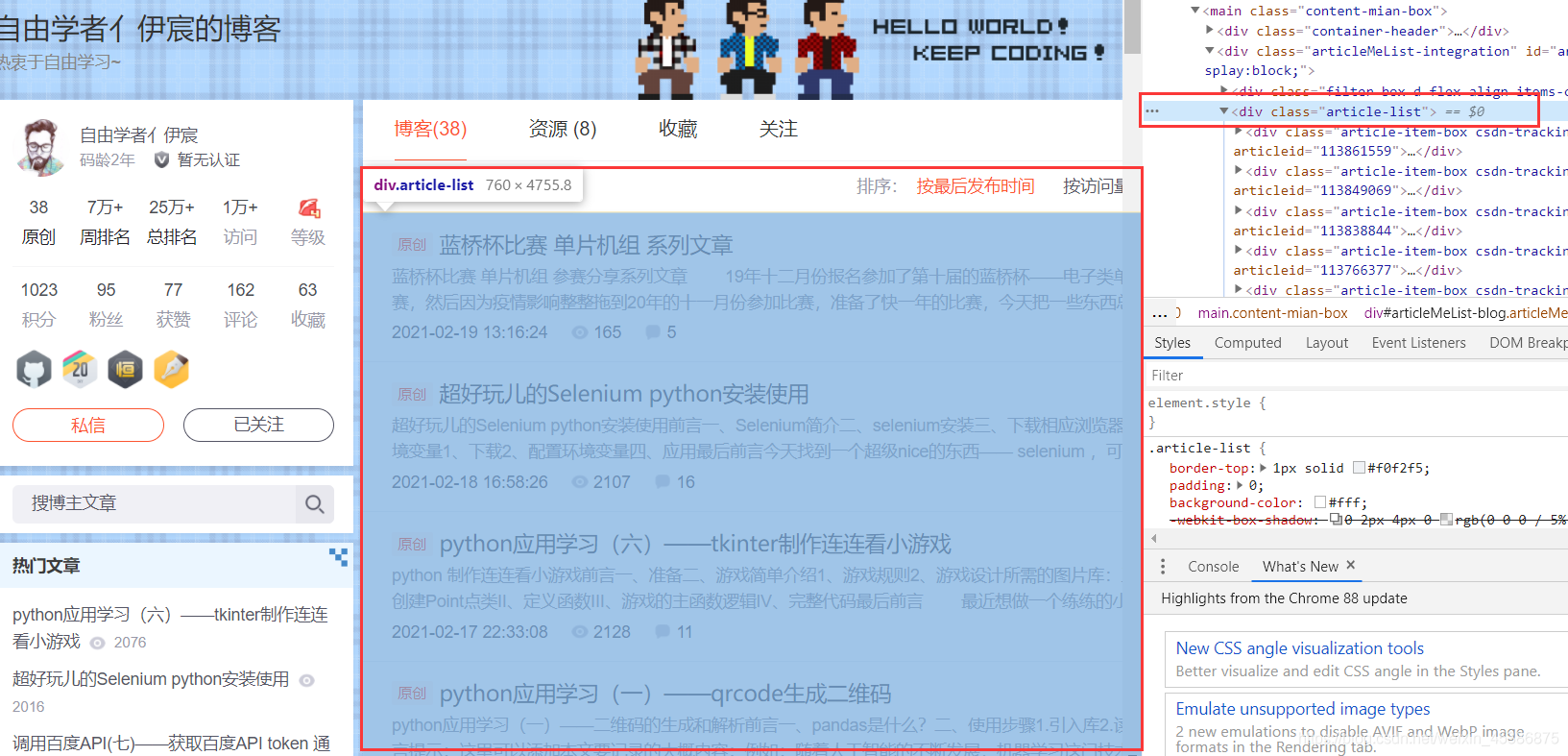
?
然后右擊該部分代碼,選擇Copy—>copy full xpath(得到/html/body/div[6]/main/div[2]/div[2])
?
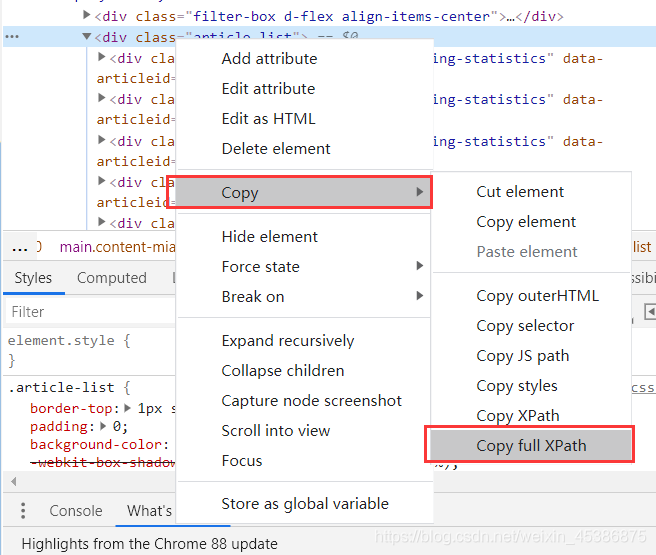
然后
driver.find_element_by_xpath(‘/html/body/div[6]/main/div[2]/div[2]’)
重點
注意:
這樣是不夠的,因為這里的得到的xpath只是所有文章的父節點(其通過len()發現其長度只是1,所以只能自動化訪問第一個頁面,后面的就自動化不了),想要訪問后面的文章還需在得到的xpath后面添加/div,即選取該父節點的所有div子節點(此時通過len()發現其長度就是總文章篇數了),即:/html/body/div[6]/main/div[2]/div[2]/div,然后就可以獲取剩余部分的全部article了,
?

代碼:
?
from selenium import webdriver
from time import sleep
i = 0
def get_all_article():
global i
all_articles = driver.find_elements_by_xpath('/html/body/div[6]/main/div[2]/div[2]/div')
for article in all_articles:
print('length of article:',len(all_articles))
i = i + 1
a = article.find_element_by_tag_name("a")
href = a.get_attribute('href')
js='window.open("'+href+'");'
driver.execute_script(js)
current_window = driver.current_window_handle
allHandles = driver.window_handles
for handle in allHandles:
if handle != driver.current_window_handle:
driver.switch_to.window(handle)
break
最后
非常開心又給大家完成了一次分享,剩下的就是…求贊啦!!!都看到這啦,創作不易,留下你們寶貴的贊吧~
?
?
其他selenium相關內容見:https://blog.csdn.net/weixin_45386875/article/details/113933541
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/262929.html
標籤:python