Unet論文:http://www.arxiv.org/pdf/1505.04597.pdf
Unet源代碼:https://github.com/jakeret/tf_unet
發表于:2015年的MICCAI
一、基本介紹
1.1歷史背景
卷積神經網路(CNN)不僅對影像識別有所幫助,也對語意分割領域的發展起到巨大的促進作用, 2014 年,加州大學伯克利分校的 Long 等人提出全卷積網路(FCN),這使得卷積神經網路無需全連接層即可進行密集的像素預測,CNN 從而得到普及,使用這種方法可生成任意大小的影像分割圖,且該方法比影像塊分類法要快上許多,之后,語意分割領域幾乎所有先進方法都采用了該模型,
1.2 FCN(全卷積網路)
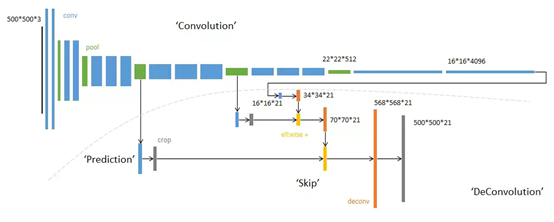
網路的整體結構分為:全卷積部分和反卷積部分,
全卷積部分:借用了一些經典的CNN網路并把最后的全連接層換成卷積,用于提取特征,形成熱點圖;
反卷積部分:將小尺寸的熱點圖上采樣得到原尺寸的語意分割影像,
總的來說:FCN對影像進行像素級的分類,從而解決了語意級別的影像分割問題,與經典的CNN在卷積層之后使用全連接層得到固定長度的特征向量進行分類(全聯接層+softmax輸出)不同,FCN可以接受任意尺寸的輸入影像,采用反卷積層對最后一個卷積層的feature map進行上采樣, 使它恢復到輸入影像相同的尺寸,從而可以對每個像素都產生了一個預測, 同時保留了原始輸入影像中的空間資訊, 最后在上采樣的特征圖上進行逐像素分類,
具體可參考:https://zhuanlan.zhihu.com/p/30195134
https://www.jianshu.com/p/14641b79a672
1.3提出的背景
雖然卷積網路已經存在很長時間了,但是由于可用訓練集的大小和網路結構的大小,它們的成功受到限制,在許多視覺任務中,特別是在生物醫學影像處理中,期望的輸出應包括位置,所以應該給每個像素都進行標注,然而在生物醫學任務中通常無法獲得數千個訓練影像,因此,提出了一種資料增強方法來有效利用標注資料,提出一種U型的網路結構可以同時獲取背景關系資訊和位置資訊
二、網路結構
2.1 網路組件
①U型結構
②編碼器-解碼器結構
編碼和解碼,早在2006年就發表在了Nature上,當時這個結構提出的主要作用并不是分割,而是壓縮影像和去噪聲,后來把這個思路被用在了影像分割的問題上,也就是現在我們看到的FCN或者U-Net結構,在它被提出的三年中,有很多很多的論文去講如何改進U-Net或者FCN,不過這個分割網路的本質的結構是沒有改動的, 即下采樣、上采樣和跳躍連接,
編碼器逐漸減少池化層的空間維度,解碼器逐步修復物體的細節和空間維度,編碼器和解碼器之間通常存在快捷連接,因此能幫助解碼器更好地修復目標的細節,U-Net 是這種方法中最常用的結構,
③skip-connection
2.2結構詳解
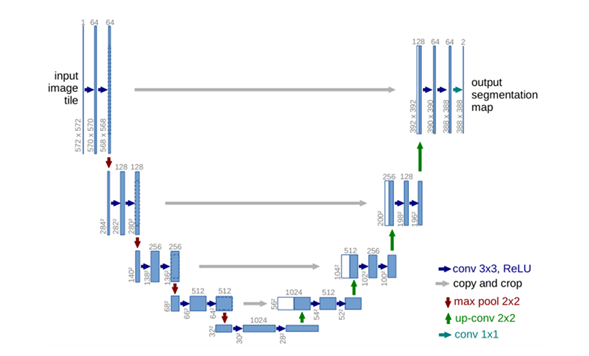
①U-net前半部分作用是特征提取,后半部分是上采樣,每一個藍色塊表示一個多通道特征圖,特征圖的通道數標記在頂部,X-Y尺寸設定在塊的左下邊緣,不同顏色的箭頭代表不同的操作,
②藍色箭頭代表3x3的卷積操作,channel的大小乘2,stride是1,padding為0,因此,每個該操作以后, feature map的大小會減2,輸入是572x572的,但是輸出變成了388x388,是因為灰色箭頭表示復制和剪切操作,在同一層左邊的最后一層要比右邊的第一層要大一些,這就導致了,想要利用淺層的feature,就要進行一些剪切,也導致了最終的輸出是輸入的中心某個區域,
③紅色箭頭代表2x2的max pooling操作,需要注意的是,如果pooling之前feature map的大小是奇數,那么就會損失一些資訊,
④綠色箭頭代表2x2的反卷積操作,操作會將feature map的大小乘2,channel的大小除以2,
⑤輸出的最后一層,使用了1x1的卷積層做了分類,把64個特征向量分成了2類(細胞類、背景類),
三、方法亮點
3.1同時具備捕捉背景關系資訊的收縮路徑和允許精確定位的對稱擴展路徑,并且與FCN相比,U-net的上采樣程序依然有大量的通道,這使得網路將背景關系資訊向更高層解析度傳播,
收縮路徑遵循卷積網路的典型架構,每一次下采樣后都把特征通道的數量加倍,擴展路徑中的每一步都首先使用反卷積,每次使用反卷積都將特征通道數量減半,特征圖大小加倍,反卷積過后,將反卷積的結果與收縮路徑中對應步驟的特征圖拼接起來,
3.2 Overlap-tile 策略,這種方法用于補全輸入影像的上下資訊,可以解決由于現存不足造成的影像輸入的問題,
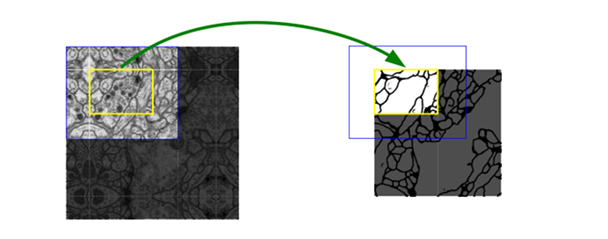
為了預測影像邊界區域中的像素,通過鏡像輸入影像來推斷缺失的背景關系, 這種平鋪策略對于將網路應用于大影像非常重要,因為解析度會受到GPU記憶體的限制,
該策略的思想是:對影像的某一塊像素點(黃框內部分)進行預測時,需要該影像塊周圍的像素點(藍色框內)提供背景關系資訊,以獲得更準確的預測,簡單地說,就是在預處理中,對輸入影像進行padding,通過padding擴大輸入影像的尺寸,使得最后輸出的結果正好是原始影像的尺寸, 同時, 輸入影像塊(黃框)的邊界也獲得了背景關系資訊從而提高預測的精度,
3.3使用隨機彈性變形進行資料增強,
作者采用了彈性變形的影像增廣,以此讓網路學習更穩定的影像特征,因為資料集是細胞組織的影像,細胞組織的邊界每時每刻都會發生不規則的畸變,所以這種彈性變形的增廣是非常有效的,

如果 σ值很大,則結果值很小,因為隨機值平均為0;如果σ很小,則歸一化后該欄位看起來像一個完全隨機的欄位,
對于中間σ值,位移場看起來像彈性變形,其中σ是彈性系數,然后將位移場乘以控制變形強度的比例因子 α, 將經過高斯卷積的位移場乘以控制變形強度的比例因子 α,得到一個彈性形變的位移場,最后將這個位移場作用在仿射變換之后的影像上,得到最終彈性形變增強的資料,作用的程序相當于在仿射影像上插值的程序,最后回傳插值之后的結果,
3.4使用加權損失,(分離同一類別的接觸物體)
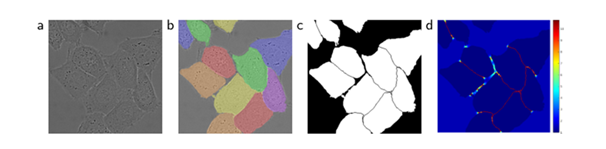
(a)原始影像
(b)標注影像實況分割 不同的顏色表示HeLa細胞的不同情況
(c)生成分割蒙版(白色:前景,黑色:背景)
(d)以像素為單位的權重映射,迫使網路學習邊界像素
方法:預先計算權重圖,一方面補償了訓練資料每類像素的不同頻率,另一方面是網路更注重學習相互接觸的細胞間邊緣,
因此,使用加權損失,其中接觸細胞之間的分離背景標簽在損失函式中獲得大的權重,預先計算每個真實分割的權重圖,以補償訓練資料集中某一類像素的不同頻率,并迫使網路學習,在觸摸細胞之間引入的小分離邊界(見圖c和d),
使用形態運算來計算分離邊界,權重圖計算如下:
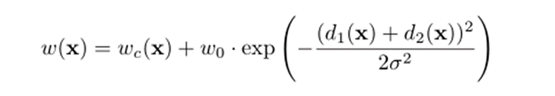
四、網路模型主要應用及結果
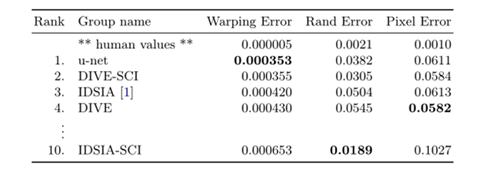
4.1在電子顯微鏡記錄中分割神經元結構,在下圖中演示了資料集中的一個例子和我們的分割結果,我們提供了全部結果作為補充材料,資料集是EM分割挑戰提供的,這個挑戰是從 ISBI 2012開始的,現在依舊開放,訓練資料是一組來自果蠅幼蟲腹側腹側神經索(VNC)的連續切片透射電鏡的30張影像(512x512像素),每個影像都帶有一個對應的標注分割圖,細胞(白色)和膜(黑色),測驗集是公開可用的,但對應的標注圖是保密的,可以通過將預測的膜概率圖發送給組織者來獲得評估,通過在10個不同級別對結果進行閾值化和計算“warping error”, “Rand error”還有“pixel error”(預測的label和實際的label),u-net(輸入資料的7個旋轉版本的平均值)無需進行任何進一步的預處理或后處理即可獲得0.0003529的warping error和0.0382的Rand error,
4.2 ISBI細胞追蹤挑戰的結果
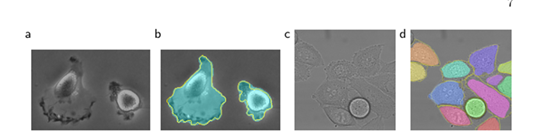
(a)" PHc-U373 "資料集輸入影像的一部分,(b)分割結果(青色mask)與人工真實(黃色邊框)(c)“DIC-HeLa”資料集的輸入影像,(d)分割結果(隨機彩色mask)與人工真實(黃色邊框),
4.3 ISBI細胞追蹤挑戰賽2015的分割結果(IOU)
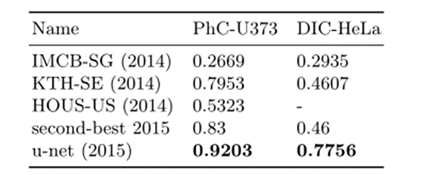
將u-net應用于光顯微影像中的細胞分割任務,這項分離任務是2014年和2015年ISBI細胞追蹤挑戰的一部分,第一個資料集“PHc-U373”包含Glioblastoma-astrocytoma(膠質母細胞瘤-星形細胞瘤)細胞在聚丙烯酰亞胺基底上,通過相差顯微鏡記錄,它包含35個部分注釋的訓練影像,實作了92%的平均IOU,這明顯優于83%的第二好演算法,第二個資料集“DIC-HeLa”是平板玻璃上的HeLa細胞,通過微分干涉對比顯微鏡記錄,它包含20個部分注釋的訓練影像,在這里,實作了77.5%的平均IOU,這明顯優于第二好的演算法46%,
五、網路缺陷和不足
5.1 不足之處
感興趣的目標尺寸非常小,對于尺寸極小的目標,U-Net分割性能可能會不好,分割效果也不好,
5.2研習Unet
①FCN與Unet的區別
U-Net和FCN非常的相似,U-Net比FCN稍晚提出來,但都發表在2015年,和FCN相比,U-Net的第一個特點是完全對稱,也就是左邊和右邊是很類似的,而FCN的decoder相對簡單,只用了一個deconvolution的操作,之后并沒有跟上卷積結構,第二個區別就是skip connection,FCN用的是加操作(summation),U-Net用的是疊操作(concatenation),這些都是細節,重點是它們的結構用了一個比較經典的思路,也就是編碼和解碼(encoder-decoder)結構,
②U型結構到底多深,是不是越深越好?
關于到底要多深這個問題,還有一個引申的問題就是,降采樣對于分割網路到底是不是必須的?問這個問題的原因就是,既然輸入和輸出都是相同大小的圖,為什么要折騰去降采樣一下再升采樣呢?
比較直接的回答當然是降采樣的理論意義,我簡單朗讀一下,它可以增加對輸入影像的一些小擾動的魯棒性,比如影像平移,旋轉等,減少過擬合的風險,降低運算量,和增加感受野的大小,升采樣的最大的作用其實就是把抽象的特征再還原解碼到原圖的尺寸,最終得到分割結果,
參考https://zhuanlan.zhihu.com/p/44958351
六、個人思考總結
從2015年這篇文章發表以來,Unet被參考數千次,成為大多做醫療影像語意分割任務的baseline,也啟發了大量研究者去思考U型語意分割網路,
新穎的特征融合,對影像特征多尺度識別,skip connection,到現在依舊值得我們學習借鑒,
附錄:
①Unet-family:https://github.com/ShawnBIT/UNet-family
②醫學影像特點:
(1)影像語意較為簡單、結構較為固定,做腦部影像的,就用腦CT和腦MRI,做胸片的只用胸片CT,做眼底的只用眼底OCT,都是一個固定的器官的成像,而不是全身的,由于器官本身結構固定和語意資訊沒有特別豐富,所以高級語意資訊和低級特征都顯得很重要,
(2)資料量少,醫學影像的資料獲取相對難一些,很多比賽只提供不到100例資料,所以我們設計的模型不宜多大,引數過多,很容易導致過擬合,(原始UNet的引數量在28M左右(上采樣帶轉置卷積的UNet引數量在31M左右),而如果把channel數成倍縮小,模型可以更小,縮小兩倍后,UNet引數量在7.75M,縮小四倍,可以把模型引數量縮小至2M以內)非常輕量,個人嘗試過使用Deeplab v3+和DRN等自然影像語意分割的SOTA網路在自己的專案上,發現效果和UNet差不多,但是引數量會大很多,
(3)多模態,相比自然影像,醫療影像是具有多種模態的,以ISLES腦梗競賽為例,其官方提供了CBF,MTT,CBV,TMAX,CTP等多種模態的資料,比如CBF是腦血流量,CBV用于檢測巨細胞病毒的,
(4)可解釋性重要,由于醫療影像最終是輔助醫生的臨床診斷,所以網路告訴醫生一個3D的CT有沒有病是遠遠不夠的,醫生還要進一步的想知道,病在哪一層,在哪一層的哪個位置,分割出來了嗎,能不能求體積,
參考文章:https://blog.csdn.net/haoji007/article/details/78442088?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-2&spm=1001.2101.3001.4242
https://blog.csdn.net/qian99/article/details/85084686
本文由博客群發一文多發等運營工具平臺 OpenWrite 發布
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/263663.html
標籤:Python
上一篇:Python常用的8個高級函式
下一篇:資料分析與產品:論一份報表的誕生