十大排序演算法復雜度及穩定性屬性表
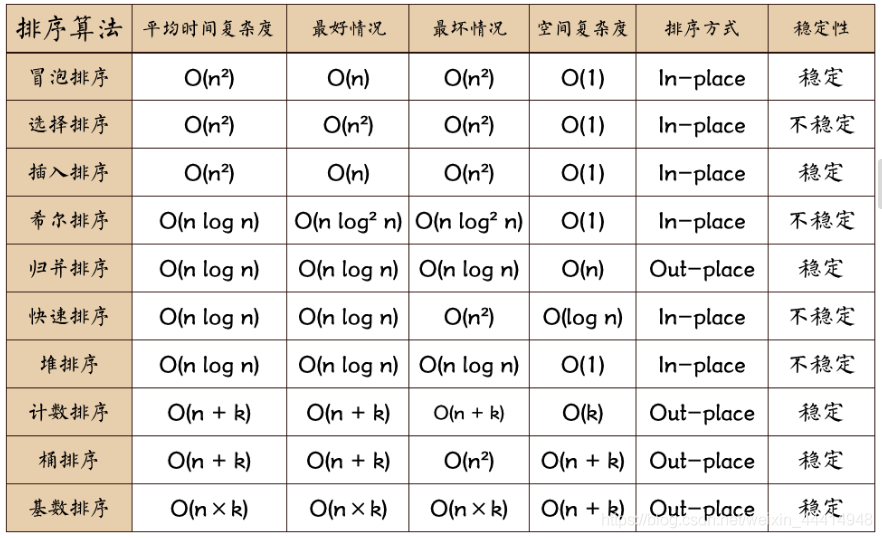
圖片名詞解釋:
n: 資料規模
k: “桶”的個數
In-place: 占用常數記憶體,不占用額外記憶體
Out-place: 占用額外記憶體
1、冒泡排序(Bubble Sort)
冒泡排序演算法的原理如下:
a. 比較相鄰的元素,如果第一個比第二個大,就交換他們兩個,
——
b. 對每一對相鄰元素做同樣的作業,從開始第一對到結尾的最后一對,在這一點,最后的元素應該會是最大的數,
——
c. 針對所有的元素重復以上的步驟,除了最后一個,
——
d. 持續每次對越來越少的元素重復上面的步驟,直到沒有任何一對數字需要比較
復雜度及穩定性:
時間復雜度:O(n^2)
空間復雜度:O(1)
穩定性:穩如老狗,內排序
python實作代碼:
def bubble_sort(nums):
n = len(nums)
# 進行多次回圈
for c in range(n):
for i in range(1, n - c):
if nums[i - 1] > nums[i]:
nums[i - 1], nums[i] = nums[i], nums[i - 1]
return nums
2、選擇排序(Select Sort)
每一趟從待排序的資料元素中選出最小(最大)的元素,順序放在待排序的數列最前,直到全部待排序的資料元素全部排完,
舉例:
[4, 2, 3] 找出最小的:2,與第一個元素交換
[2, 4, 3] 找出最小的:3,與第二個元素交換
[2, 3, 4]
復雜度及穩定性:
時間復雜度:O(n^2)
空間復雜度:O(1)
穩定性:鏈表穩定,陣列不穩定,內排序
python實作代碼:
def select_sort(nums):
n = len(nums)
for i in range(n):
for j in range(i, n):
if nums[i] > nums[j]:
nums[i], nums[j] = nums[j], nums[i]
return nums
3、插入排序(Insertion Sort)
核心思想:插入排序是前面已排序陣列找到插入的位置
復雜度及穩定性:
時間復雜度:O(n^2)
空間復雜度:O(1)
穩定性:穩如老狗,內排序
python實作代碼:
def insertion_sort(nums):
n = len(nums)
for i in range(1, n):
while i > 0 and nums[i - 1] > nums[i]:
nums[i - 1], nums[i] = nums[i], nums[i - 1]
i -= 1
return nums
4、希爾排序(Shell Sort)
插入排序的進階版,,,
演算法描述:
我們來看下希爾排序的基本步驟,在此我們選擇增量gap=length/2,縮小增量繼續以gap = gap/2的方式,這種增量選擇我們可以用一個序列來表示,{n/2,(n/2)/2…1},稱為增量序列,希爾排序的增量序列的選擇與證明是個數學難題,我們選擇的這個增量序列是比較常用的,也是希爾建議的增量,稱為希爾增量,但其實這個增量序列不是最優的,
先將整個待排序的記錄序列分割成為若干子序列分別進行直接插入排序,具體演算法描述:
步驟1:選擇一個增量序列 t1,t2,…,tk,其中 ti > tj,tk=1;
——
步驟2:按增量序列個數k,對序列進行k 趟排序;
——
步驟3:每趟排序,根據對應的增量ti,將待排序列分割成若干長度為m 的子序列,分別對各子表進行直接插入排序,僅增量因子為1 時,整個序列作為一個表來處理,表長度即為整個序列的長度,
復雜度及穩定性:
時間復雜度:O(nlogn)
空間復雜度:O(n)
穩定性:很穩定,外排序(需要額外空間)
python實作代碼:
def shell_sort(nums):
n = len(nums)
gap = n // 2
while gap:
for i in range(gap, n):
while i - gap >= 0 and nums[i - gap] > nums[i]:
nums[i - gap], nums[i] = nums[i], nums[i - gap]
i -= gap
gap //= 2
return nums
5、歸并排序(Merge Sort)
歸并排序,采用是分治法,先將陣列分成子序列,讓子序列有序,再將子序列間有序,合并成有序陣列,
演算法描述:
1、把長度為n的輸入序列分成長度 n/2的子序列;
2、對兩個子序列采用歸并排序;
3、合并所有子序列,
復雜度及穩定性:
時間復雜度:O(nlogn)
空間復雜度:O(1)
穩定性:不穩定,內排序
python實作代碼:
def merge_sort(nums):
if len(nums) <= 1:
return nums
mid = len(nums) // 2
# 分
left = merge_sort(nums[:mid])
right = merge_sort(nums[mid:])
# 合并
return merge(left, right)
def merge(left, right):
res = []
i = 0
j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
res.append(left[i])
i += 1
else:
res.append(right[j])
j += 1
res += left[i:]
res += right[j:]
return res
6、快速排序(Quick Sort)
快速排序是選取一個“哨兵”(pivot),將小于pivot放在左邊,把大于pivot放在右邊,分割成兩部分,并且可以固定pivot在陣列的位置,在對左右兩部分繼續進行排序,
快速排序使用分治法來把一個串(list)分為兩個子串(sub-lists),具體演算法描述如下:
步驟1:從數列中挑出一個元素,稱為 “基準”(pivot );
——
步驟2:重新排序數列,所有元素比基準值小的擺放在基準前面,所有元素比基準值大的擺在基準的后面(相同的數可以到任一邊),在這個磁區退出之后,該基準就處于數列的中間位置,這個稱為磁區(partition)操作;
——
步驟3:遞回地(recursive)把小于基準值元素的子數列和大于基準值元素的子數列排序,
復雜度及穩定性:
時間復雜度:O(nlogn)
空間復雜度:O(1)
穩定性:不穩定,內排序
python實作代碼:
def quick_sort(nums):
n = len(nums)
def quick(left, right):
if left >= right:
return nums
pivot = left
i = left
j = right
while i < j:
while i < j and nums[j] > nums[pivot]:
j -= 1
while i < j and nums[i] <= nums[pivot]:
i += 1
nums[i], nums[j] = nums[j], nums[i]
nums[pivot], nums[j] = nums[j], nums[pivot]
quick(left, j - 1)
quick(j + 1, right)
return nums
return quick(0, n - 1)
7、堆排序(Heap Sort)
堆排序是利用堆這個資料結構設計的排序演算法,
演算法描述:
1、建堆,從底向上調整堆,使得父親節點比孩子節點值大,構成大頂堆;
2、交換堆頂和最后一個元素,重新調整堆,
調整堆方法寫了遞回和迭代,都很好理解!
復雜度及穩定性:
時間復雜度:O(nlogn)
空間復雜度:O(1)
穩定性:不穩定,內排序
python實作代碼:
def heap_sort(nums):
# 調整堆
# 迭代寫法
def adjust_heap(nums, startpos, endpos):
newitem = nums[startpos]
pos = startpos
childpos = pos * 2 + 1
while childpos < endpos:
rightpos = childpos + 1
if rightpos < endpos and nums[rightpos] >= nums[childpos]:
childpos = rightpos
if newitem < nums[childpos]:
nums[pos] = nums[childpos]
pos = childpos
childpos = pos * 2 + 1
else:
break
nums[pos] = newitem
# 遞回寫法
def adjust_heap(nums, startpos, endpos):
pos = startpos
chilidpos = pos * 2 + 1
if chilidpos < endpos:
rightpos = chilidpos + 1
if rightpos < endpos and nums[rightpos] > nums[chilidpos]:
chilidpos = rightpos
if nums[chilidpos] > nums[pos]:
nums[pos], nums[chilidpos] = nums[chilidpos], nums[pos]
adjust_heap(nums, pos, endpos)
n = len(nums)
# 建堆
for i in reversed(range(n // 2)):
adjust_heap(nums, i, n)
# 調整堆
for i in range(n - 1, -1, -1):
nums[0], nums[i] = nums[i], nums[0]
adjust_heap(nums, 0, i)
return nums
8、計數排序(Counting Sort)
計數排序是典型的空間換時間演算法,開辟額外資料空間存盤用索引號記錄陣列的值和陣列值個數
演算法描述:
1、找出待排序的陣列的最大值和最小值;
2、統計陣列值的個數;
3、反向填充目標陣列,
復雜度及穩定性:
時間復雜度:O(n + k)
空間復雜度:O(k),對于資料范圍很大的陣列,需要大量時間和記憶體
穩定性:穩定,外排序
python實作代碼:
def counting_sort(nums):
if not nums: return []
n = len(nums)
_min = min(nums)
_max = max(nums)
tmp_arr = [0] * (_max - _min + 1)
for num in nums:
tmp_arr[num - _min] += 1
j = 0
for i in range(n):
while tmp_arr[j] == 0:
j += 1
nums[i] = j + _min
tmp_arr[j] -= 1
return nums
9、桶排序(Bucket Sort)
桶排序是計數排序的升級版,原理是:輸入資料服從均勻分布的,將資料分到有限數量的桶里,每個桶再分別排序(有可能再使用別的演算法或是以遞回方式繼續使用桶排序,此文編碼采用遞回方式)
演算法描述:
1、人為設定一個桶的BucketSize,作為每個桶放置多少個不同數值(意思就是BucketSize = 5,可以放5個不同數字比如[1, 2, 3,4,5]也可以放 100000個3,只是表示該桶能存幾個不同的數值);
——
2、遍歷待排序資料,并且把資料一個一個放到對應的桶里去;
——
3、對每個不是桶進行排序,可以使用其他排序方法,也遞回排序;
——
4、不是空的桶里資料拼接起來;
復雜度及穩定性:
時間復雜度:O(n ^ 2)
空間復雜度:O(n + k)
穩定性:穩定,外排序
python實作代碼:
def bucket_sort(nums, bucketSize):
if len(nums) < 2:
return nums
_min = min(nums)
_max = max(nums)
# 需要桶個數
bucketNum = (_max - _min) // bucketSize + 1
buckets = [[] for _ in range(bucketNum)]
for num in nums:
# 放入相應的桶中
buckets[(num - _min) // bucketSize].append(num)
res = []
for bucket in buckets:
if not bucket: continue
if bucketSize == 1:
res.extend(bucket)
else:
# 當都裝在一個桶里,說明桶容量大了
if bucketNum == 1:
bucketSize -= 1
res.extend(bucket_sort(bucket, bucketSize))
return res
10、基數排序(Radix Sort)
基數排序是對數字每一位進行排序,從最低位開始排序
演算法描述:
1、找到陣列最大值,得最大位數;
2、從最低位開始取每個位組成radix陣列;
3、對radix進行計數排序(計數排序適用于小范圍的特點),
復雜度及穩定性:
時間復雜度:O(n * k)
空間復雜度:O(n + k)
穩定性:穩定,外排序
python實作代碼:
def Radix_sort(nums):
if not nums: return []
_max = max(nums)
# 最大位數
maxDigit = len(str(_max))
bucketList = [[] for _ in range(10)]
# 從低位開始排序
div, mod = 1, 10
for i in range(maxDigit):
for num in nums:
bucketList[num % mod // div].append(num)
div *= 10
mod *= 10
idx = 0
for j in range(10):
for item in bucketList[j]:
nums[idx] = item
idx += 1
bucketList[j] = []
return nums
參考來源:https://leetcode-cn.com/problems/sort-an-array/solution/python-shi-xian-de-shi-da-jing-dian-pai-xu-suan-fa/
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/263826.html
標籤:python