HashMap
關于hash表的基礎內容,請看文章
【資料結構-查找】3.散串列詳解
【Java自頂向下】HashMap面試題(2021最新版)
頂層應用
public class HashMapTest {
public static void main(String[] args) {
HashMap<String, String> stringStringHashMap = new HashMap<>();
// 1.put存盤鍵值對
stringStringHashMap.put("ffideal","宇定");
stringStringHashMap.put("床前明月光","疑是地上霜");
// 2.get利用key獲取value
String name = stringStringHashMap.get("ffideal");
System.out.println(name);
// 3.containsKey是否存在某個鍵值
if (stringStringHashMap.containsKey("ffideal")) {
System.out.println("ffideal存在");
} else {
System.out.println("ffideal不存在");
}
// 4.replace修改key-value
stringStringHashMap.replace("ffideal","宇定2");
String name3 = stringStringHashMap.get("ffideal");
System.out.println(name3);
// 5.遍歷HashMap中的鍵值對
Set<String> strings = stringStringHashMap.keySet();
for (String s: strings) {
System.out.println("遍歷資料:" + s);
}
// 6.clear清空HashMap中的元素
stringStringHashMap.clear();
Set<String> strings2 = stringStringHashMap.keySet();
for (String s: strings2) {
System.out.println("清空后的資料" + s);
}
}
}
底層原理
put => key => HashCode => 位置index
get => key => HashCode => 位置index
問:HashMap陣列大小初始值是多少?最大是多少?如果為給定初始值,初始大小是多少?
答:16( 2 4 2^4 24); 2 30 2^{30} 230;大于等于引數的最小2的冪次方
private static final int tableSizeFor(int c) {
// 傳入32或20
int n = c - 1;
// n=31或19
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
// 此時n=31或31,最后經過兩次判斷后回傳值為32
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}
問:HashMap 在 Java 7 與Java 8 中底層的不同?
答:Java 7 中的HashMap的底層是一個陣列+鏈表的設計,每個hash值的第一個值放在陣列里,之后經過hash運算得到相同的hash值鎖定陣列下標,陣列中的每一個元素都是一個單向鏈表(碰撞,串列),
- capacity:當前陣列容量,始終保持 2 n 2^n 2n,可以擴容,擴容后陣列大小為當前的 2 倍,
- loadFactor:負載因子,默認為 0.75,
- threshold:擴容的閾值,等于 capacity * loadFactor,
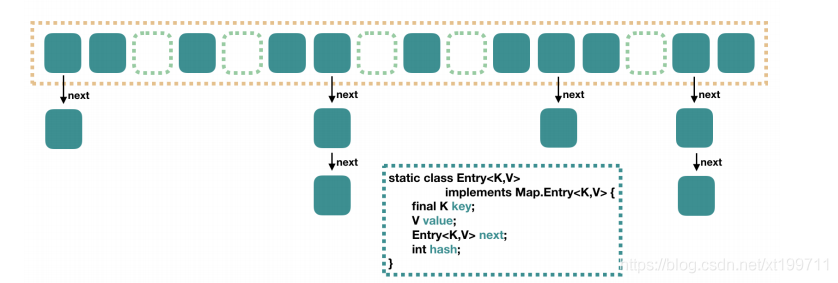
HashMap的資料插入原理
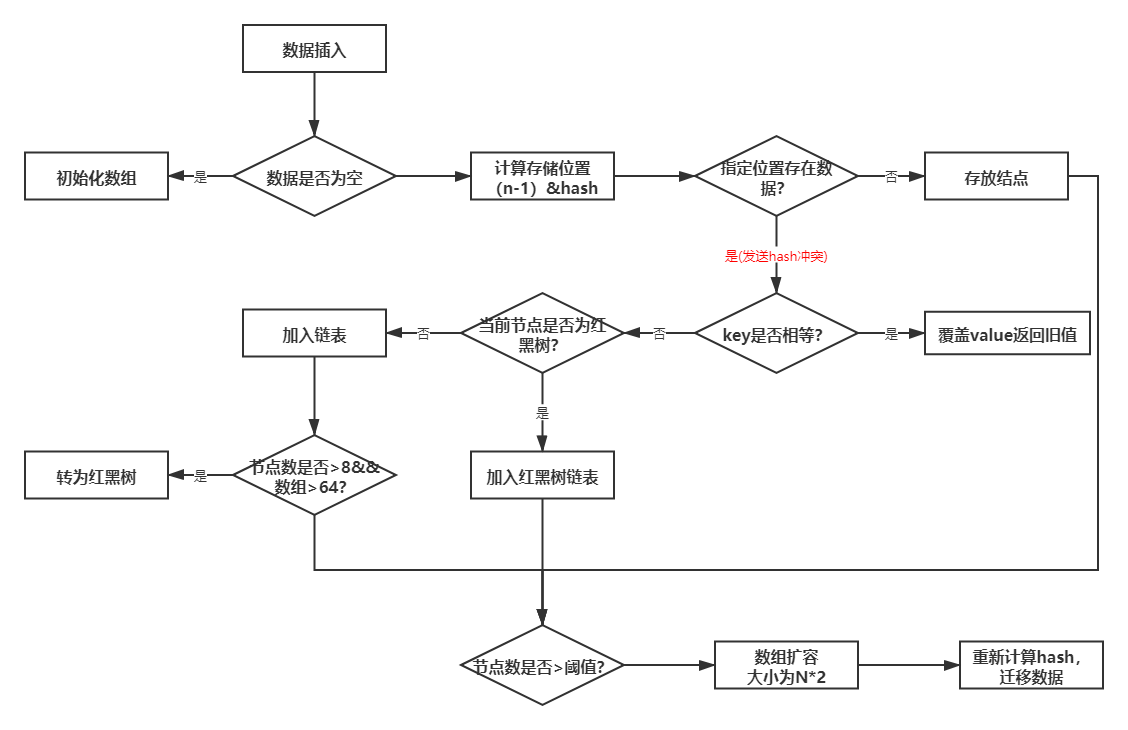
存盤結構的變化
Java 8 中的HashMap的底層是陣列+鏈表+紅黑樹的方式實作,
為什么要使用紅黑樹而不使用AVL樹
紅黑樹犧牲了一些查找性能 但其本身并不是完全平衡的二叉樹,因此插入洗掉操作效率略高于AVL樹
AVL樹用于自平衡的計算犧牲了插入洗掉性能,但是因為最多只有一層的高度差,查詢效率會高一些,
改進的是在資料量較大的情況下(Java8 中,當鏈表中的元素超過了 8 個以后,會將鏈表轉換為紅黑樹)單向鏈表的時間復雜是O(N),采用紅黑樹將時間復雜度降到O(logN),
static final int TREEIFY_THRESHOLD = 8;
那么, 如果我們在洗掉容器中的元素的時候,刪到多少才使得紅黑樹的存盤結構轉為鏈表呢?答案是6,
static final int UNTREEIFY_THRESHOLD = 6;
也就是說,在JDK8之后,創建HashMap物件=>添加陣列中同一個位置元素超過8個=>該位置鏈表轉為紅黑樹=>洗掉陣列中同一個位置元素少于6個=>該位置紅黑樹轉為串列,
最小樹形化的策略
最小樹形化容量閾值:即 當哈希表中的容量 > 該值時,才允許樹形化鏈表 (即 將鏈表 轉換成紅黑樹), 否則,若桶內元素太多時,則直接擴容,而不是樹形化,為了避免進行擴容、樹形化選擇的沖突,這個值不能小于 4 * TREEIFY_THRESHOLD,
也就是說,當陣列中某個桶中的元素大于8,陣列容量小于64時,使用容量進行兩倍擴容(其實就是用擴容代替鏈表轉紅黑樹操作),當陣列中某個桶中的元素大于8且陣列容量大于64時,鏈表轉紅黑樹操作,
hashMap并不是在鏈表元素個數大于8就一定會轉換為紅黑樹,而是先考慮擴容,擴容達到默認限制后才轉換
hashMap的紅黑樹不一定小于等于6的時候就會轉換為鏈表,而是只有在resize的時候才會根據 UNTREEIFY_THRESHOLD(6) 進行轉換
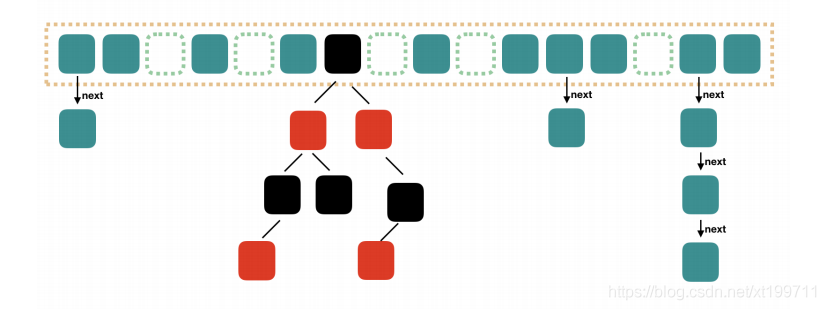
HashMap怎么解決碰撞問題的?
Java中HashMap是利用“拉鏈法”處理HashCode的碰撞問題,
在呼叫HashMap的put方法或get方法時,都會首先呼叫hashcode方法,去查找相關的key,當有沖突時,再呼叫equals方法,
hashMap基于hasing原理,我們通過put和get方法存取物件,當我們將鍵值對傳遞給put方法時,他呼叫鍵物件的hashCode()方法來計算hashCode,然后找到bucket(哈希桶)位置來存盤物件,
當獲取物件時,通過鍵物件的equals()方法找到正確的鍵值對,然后回傳值物件,
HashMap使用鏈表來解決碰撞問題,當碰撞發生了,物件將會存盤在鏈表的下一個節點中,hashMap在每個鏈表節點存盤鍵值對物件,當兩個不同的鍵卻有相同的hashCode時,他們會存盤在同一個bucket位置的鏈表中,
鍵物件的equals()來找到鍵值對,
HashMap的一些特點
| HashMap的5個特點 |
|---|
| HashMap鍵不可重復,值可重復 |
| 底層hash表 |
| 具有很快的訪問速度,遍歷順序不確定 |
| 執行緒不安全,若需要執行緒安全則需要使用Collections中的synchronizedMap方法來保障 |
| 允許key值為null,value值也為null |
一些誤區
問1:是否可以兩個key值為null?
答1:不可以,后者會把前者覆寫
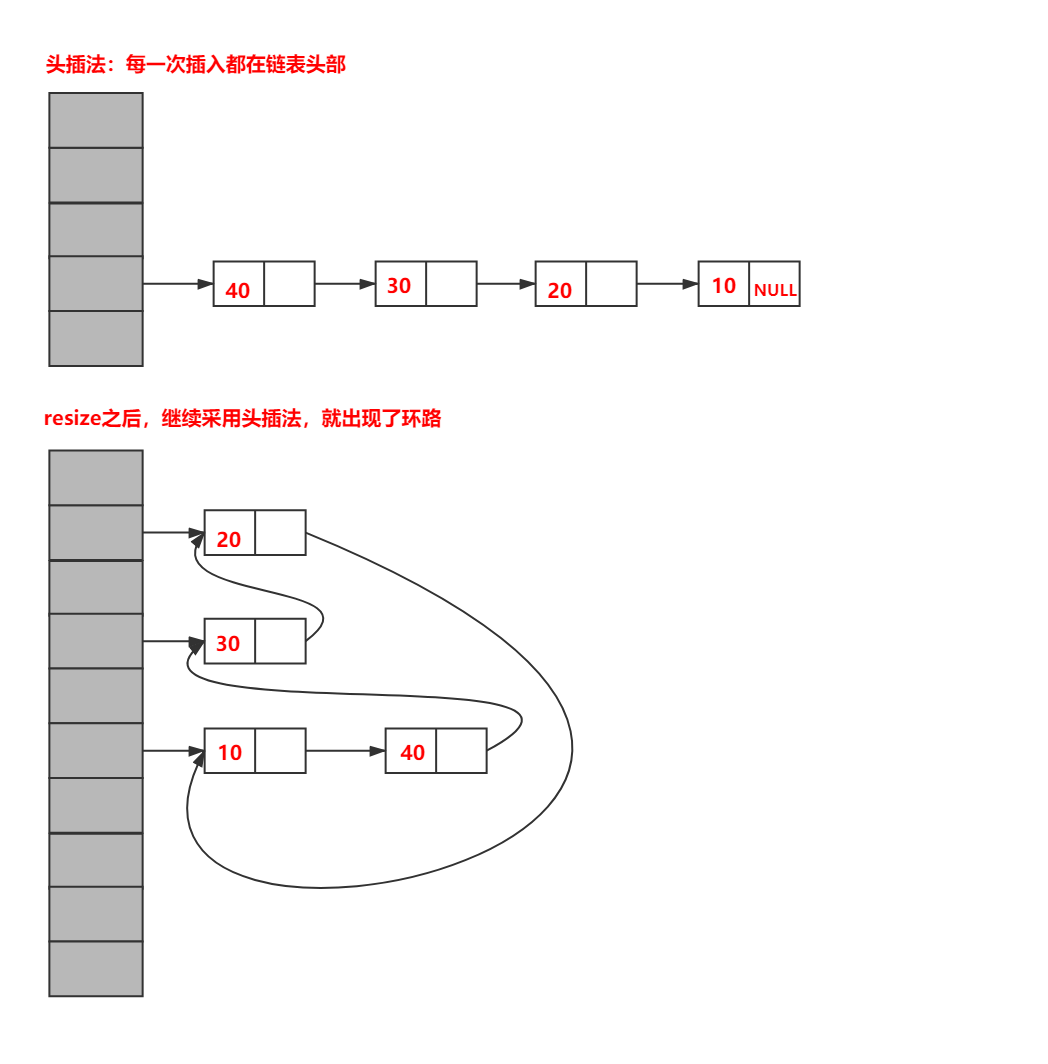
問2:HashMap插入時,使用頭插法還是尾插法?
答2:在插入時采用尾插法(1.7是頭插法),在并發場景下導致鏈表成環的問題,而在jdk1.8中采用尾插入法,在擴容時會保持鏈表元素原本的順序,就不會出現鏈表成環的問題了,
頭插法和尾插法
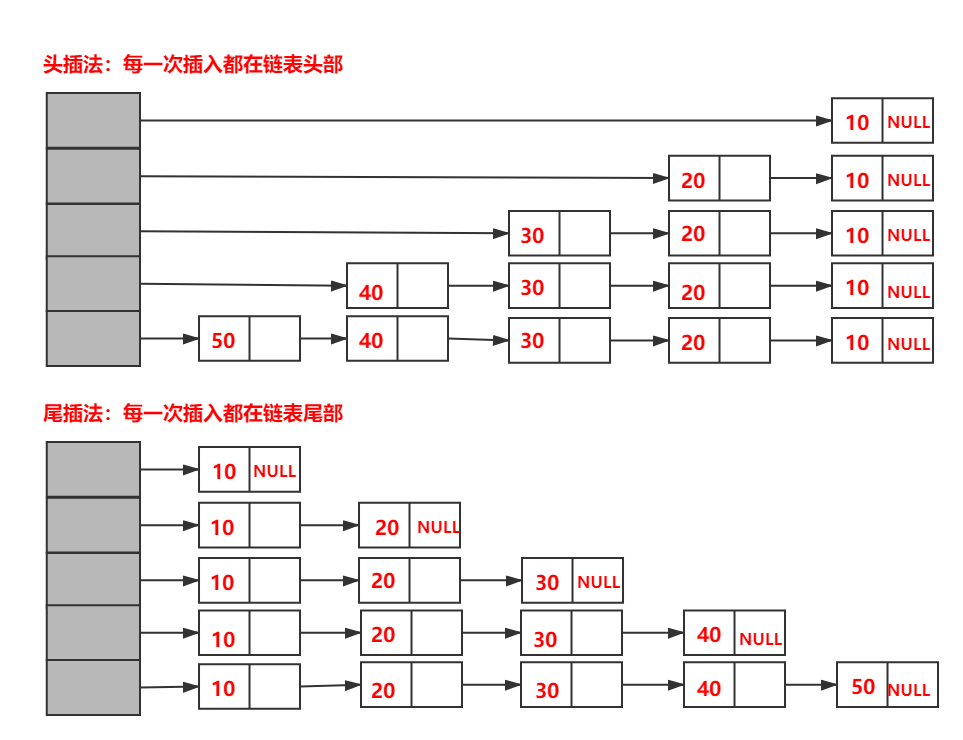
頭插法帶來的環狀
一些不足和解決方式
HashMap不是執行緒安全的.
Java中有HashTable、Collections.synchronizedMap、以及ConcurrentHashMap可以實作執行緒安全的Map,
HashTable是直接在操作方法上加synchronized關鍵字,鎖住整個陣列,粒度比較大,因為synchronized關鍵字每次執行都會呼叫作業系統的鎖來保證執行緒安全,也就是每次執行代碼塊,都要涉及 “用戶態” 到 “內核態” 的轉變,十分消耗資源,
Collections.synchronizedMap是使用 Collections集合工具的內部類,通過傳入Map封裝出一個SynchronizedMap物件,內部定義了一個物件鎖,方法內通過物件鎖實作,
ConcurrentHashMap使用分段鎖,降低了鎖粒度,讓并發度大大提高我們一般都會使用HashTable或者ConcurrentHashMap,但是因為前者的并發度的原因基本上沒啥使用場景了,所以存在執行緒不安全的場景我們都使用的是ConcurrentHashMap,
HashTable我看過他的原始碼,很簡單粗暴,直接在方法上鎖,并發度很低,最多同時允許一個執行緒訪問,ConcurrentHashMap就好很多了,1.7和1.8有較大的不同,不過并發度都比前者好太多了
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/264142.html
標籤:java