Python 以優雅的姿勢 操作檔案
文章目錄
- Python 以優雅的姿勢 操作檔案
- open() 方法🎏
- 檔案打開模式📌
- 使用 with 陳述句💡
- 創建檔案
- 讀取檔案
- 增加內容(末尾)
- 修改檔案內容(重點)🧬
- 洗掉檔案
- 洗掉檔案夾
- 擴展:利用 OS 模塊
- 擴展:檔案編碼知識
- 相關博客
open() 方法🎏
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
引數如下:
-
file:檔案路徑(絕對路徑或者相對路徑),如果直接寫檔案名的話那就是 相對路徑
-
mode:為字串引數,用于指定打開檔案的模式,默認值是 “r”,也就是讀取模式,其余模式參考下面內容
-
buffering:可選的整數引數,用于設定緩沖策略,若為 0 以切換緩沖關閉(僅允許在二進制模式下),1選擇行緩沖(僅在文本模式下),大于1的整數以指示固定大小的塊緩沖區的大小(單位:位元組),如果沒有給出引數,默認緩沖策略的作業方式如下:
- 二進制檔案以固定大小的塊進行緩沖;使用啟發式方法選擇緩沖區的大小,嘗試確定底層設備的“塊大小”或使用 io.DEFAULT_BUFFER_SIZE,在大多數系統上,緩沖區的長度通常為 4096 或 8192 位元組,
- “互動式”文本檔案( isatty() 回傳 True 的檔案)使用行緩沖,其他文本檔案使用上述策略用于二進制檔案,
-
encoding:指定用于解碼或編碼檔案時 所 編碼的名稱,只在文本模式下使用,默認值(默認編碼型別)是根據你的作業系統平臺決定的,Windows系統是默認國產的 GBK編碼,Liunx 、Macos 系統 為默認 UTF-8 編碼,這也是為什么在Windos平臺上打開utf-8編碼檔案時報錯的原因,這里建議 好習慣 encoding=”utf-8"
-
errors:可選字串引數,指定如何處理編碼和解碼錯誤,不能在二進制模式下使用
- strict :如果存在編碼錯誤,會引發 ValueError 報錯,默認值 None 具有相同的效果
- ignore :忽略錯誤,但忽略編碼錯誤可能會導致資料丟失,可能會在一些嵌入式環境中使用
- replace :會將替換標記(例如 ‘?’ )插入有錯誤資料的地方
-
newline:控制 universal newlines (通用換行符)模式如何生效(它僅適用于文本模式),如果 newline 為 None,則啟用通用換行模式,輸入中的行可以以 ‘\n’,’\r’ 或 ‘\r\n’ 結尾,這些行被Python翻譯成 ‘\n’ ,簡單來說,就是以什么為判斷內容下一行的依據,windos默認約定為 “\r\n” , Unix 為 “\n”,MacOS 為 “\r”
-
closefd:如果 closefd 是 False 并且給出了檔案描述符而不是檔案名,那么當檔案關閉時,底層檔案描述符將保持打開狀態;如果給出檔案名則 必須為 True(默認值,否則將引發錯誤
-
opener:設定自定義開啟器,通過使用引數( file,flags )呼叫 opener 獲得檔案物件的基礎檔案描述符,開啟器必須回傳一個打開的檔案描述符,
檔案打開模式📌
| 模式 | 描述 | 檔案已存在 | 檔案不存在 |
|---|---|---|---|
| r | 以 只讀 方式打開檔案(默認) | 正常讀取 | 報錯 FileNotFoundError |
| rb | 以 二進制格式 打開檔案 用于 讀取 | 正常讀取 | 報錯 FileNotFoundError |
| w | 以 只寫 方式打開檔案 | 清空原有內容從頭開始寫入 | 創建新檔案進行寫入 |
| wb | 以 二進制 方式打開檔案 用于 寫入 | 清空原有內容從頭開始寫入 | 創建新檔案進行寫入 |
| a | 以 追加 方式打開檔案 | 新的內容將會被寫入到已有內容末尾 | 創建新檔案進行寫入 |
| ab | 以 二進制 方式打開檔案 用于 追加 | 新的內容將會被寫入到已有內容末尾 | 創建新檔案進行寫入 |
| x | 排它性創建 寫模式 | 創建新檔案進行寫入 | 報錯 FileExistsError |
| b | 不單獨使用,二進制模式 | ~ | ~ |
| t | 不單獨使用,文本模式(默認) | ~ | ~ |
| U | 通用換行模式(Python3 已棄用) | ~ | ~ |
以 內容資料 型別為參考的話,Python 區分二進制 和 文本,那么又分為文本模式 和 二進制模式
文本模式
在不指定檔案模式時,默認模式為 “r”,打開用于讀取文本,與 “rt” 是一樣的,
文本模式下,檔案內容回傳為 字串,使用 “r”,“w” 等模式時,與 后面加 “t” 相同,“r” = “rt”
二進制模式
二進制模式下,回傳的內容為 bytes 物件,不進行任何解碼
在Python 中創建 圖片、視頻等檔案時,就需要用到 二進制模式 寫入資料內容,
使用 with 陳述句💡
在使用 open() 內置函式 操作檔案時,得記得在操作結束后加上一句 f.close()
每次操作完都得加上 f.close() ,顯得有些麻煩,且如果在操作完忘記加上這一句話,還會造成資源一直占用的問題
于是,這里 推薦使用 with 陳述句 來提升撰寫代碼的效率
普通寫法
f = open("中文.txt", "r", encoding="utf-8")
data = f.read()
print(data)
f.close()
使用 with 陳述句
with open("中文.txt", "r", encoding="utf-8") as f:
data = f.read()
print(data)
優點:
- 提升代碼閱讀性
- 減少代碼冗余,免去 f.close() 步驟,同時也防止忘記關閉檔案呼叫
接下來的代碼,我將統一使用 with 陳述句演示
創建檔案
創建檔案,常用的 檔案打開模式是 “w”,當然也可以使用 “x” 模式,前提是你所指定的目錄下沒有這個檔案
只是創建一個空白檔案的話 可以這么寫
with open("檔案.txt", "w", encoding="utf-8") as f_w:
pass
創建多個檔案 可以配合回圈
for i in range(1, 5):
with open(f"檔案_{i}.txt", "w", encoding="utf-8") as f_w:
pass
創建檔案 并且 寫入內容
with open(f"檔案.txt", "w", encoding="utf-8") as f_w:
f_w.write("hello word")
讀取檔案
讀取檔案,用到的 檔案打開模式是 “r”
-
.read(size = -1)*
讀取全部- size : 指定讀取的位元組數, 默認值-1表示讀取整個檔案
讀取全部內容with open(f"中文.txt", "r", encoding="utf-8") as f_w: data = f_w.read() # 讀取所有內容 print(data)利用 size 引數 在特點場合下有妙用
with open(f"中文.txt", "r", encoding="utf-8") as f_w: while True: data = f_w.read(10) # 每次只讀取10個位元組 if data: print(data) else: break -
.readline(size = -1)
讀取一行- size : 指定中讀取的位元組數, 默認值-1表示讀取一行內容, 用法與上面 .read() 相同
讀取一行with open(f"中文.txt", "r", encoding="utf-8") as f_w: data = f_w.readline() print(data)一行一行方式讀取 全部內容
with open(f"中文.txt", "r", encoding="utf-8") as f_w: while True: data = f_w.readline() if not data: break print(data) # 還可以直接回圈檔案物件實作 with open(f"中文.txt", "r", encoding="utf-8") as f_w: for line in f_w: print(line)
.readline(size = -1)
讀取所有行,并回傳串列,每一行為串列中的一個值
with open(f"中文.txt", "r", encoding="utf-8") as f_w:
data_list = f_w.readlines()
print(data_list)
增加內容(末尾)
對檔案內容進行追加,用到的 檔案打開模式是 “a”
追加的內容會寫在檔案末尾
with open("中文.txt", "w", encoding="utf-8") as f_w: # 創建初始檔案
f_w.write("我是第一行內容\n")
with open("中文.txt", "a", encoding="utf-8") as f_a: # 追加檔案內容
f_a.write("我是追加的內容")
這個模式用在寫簡單的 程式運行 日志 上
修改檔案內容(重點)🧬
需要使用到兩種 檔案打開模式 進行配合,先讀(“r”)后寫(“w”)
原理:
很簡單,就是先將 內容讀取 到記憶體,然后對讀取到的資料進行修改、增加、洗掉等操作,再重新寫入到新檔案中,再把舊檔案替換成新檔案,在編輯程序未結束的情況下 產生的新檔案可以理解為 臨時檔案,此時尚未與舊檔案替換
這種修改方式其實很常見,拿我們常用的 word 檔案來看
在平時編輯word檔案時,會發現在其相對路徑下會生成一個隱藏檔案,命名通常是以~$開頭,后面跟著檔案名
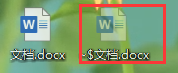

替換檔案
那么,在py中怎么替換檔案呢?
這就需要用到 os 標準庫模塊下的 os.replace()
os.replace("新檔案", "舊檔案")
根據以上原理,Py實作
temp_name = r"~$"
file_name = "中文.txt"
with open(f"{temp_name}{file_name}", "w", encoding="utf-8") as f_w:
with open(file_name, "r", encoding="utf-8") as f_r:
data = f_r.read()
data = data.replace("內容", "nei_rong") # 替換操作
data += "我是再加上的內容\n" # 增加內容
f_w.write(data)
os.replace(f"{temp_name}{file_name}", file_name) # 替換檔案
洗掉檔案
這里需要用到 os 標準庫模塊
file_path = ""
if os.path.isfile(file_path):
os.remove(file_path) # 只能洗掉檔案 非檔案夾
注意:只能洗掉檔案,非檔案夾,否則會出現 OSError 錯誤
洗掉檔案夾
需要注意的是,檔案夾分兩種,一種是空檔案夾,另外一種則是檔案夾中有內容的 非空檔案夾
- 空檔案夾:
利用 os 標準庫模塊
os.rmdir() 洗掉指定路徑的目錄,檔案夾必須為空dir_path = "" if not os.listdir(dir_path): os.rmdir(dir_path)
7 > 如果洗掉非空檔案夾,會出現 OSError 錯誤
-
非空檔案夾:
方法一:(推薦)
利用 shutil 標準庫模塊
shutil.rmtree() 洗掉一個完整的目錄樹path = "" if os.path.isdir(path): shutil.rmtree(path) # 洗掉非空檔案夾方法二:
還是使用回 os 標準庫模塊中的功能,但這個方法比較繁瑣for b, d, f in os.walk(path, topdown=False): # 一定要設定 topdown 引數為False,從里層開始 for file_n in f: os.remove(os.path.join(b, file_n)) for dir_p in d: dir_p = os.path.join(b, dir_p) if not os.listdir(dir_p): os.rmdir(dir_p) else: os.rmdir(path)
擴展:利用 OS 模塊
OS 模塊是個利器,操作檔案時 有 OS 可以做出更厲害的操作
匯入os模塊
import os
判斷檔案是否存在
os.path.isfile() # 判斷路徑是否為檔案
根據檔案是否存在決定寫入模式
file_path = "" # 檔案目錄
if os.path.isfile(file_path):
print("檔案存在")
with open(file_path, "a", encoding="urf-8") as f_a:
f_a.write("寫入內容") # 追加檔案中的內容
else:
print("檔案不存在")
with open(file_path, "w", encoding="utf-8") as f_w:
f_w.write("寫入內容")
拼接路徑
os.path.join() # 把目錄和檔案名合成一個路徑
path = os.path.join("路徑一", "路徑二")
獲取根路徑
適用于當前所運行的 py檔案
BASE_DIR = os.path.dirname(__file__) # 獲取當前Py 根目錄
判斷檔案夾是否存在
os.path.isdir() # 判斷路徑是否為目錄
如果檔案夾不存在,則創建檔案夾并在此檔案夾內創建檔案
BASE_DIR = os.path.dirname(__file__) # 獲取當前Py 根目錄
dir_path = [os.path.join(BASE_DIR, "我是檔案夾"), ] # 檔案夾路徑
file_path = os.path.join(dir_path[0], "我是檔案.txt") # 檔案目錄
def judg_isdir(funx):
"""
檔案夾初始化裝飾器
"""
def inner(*args, **kwargs):
for d in dir_path:
if not os.path.isdir(d): # 如果檔案夾不存在則創建
os.mkdir(d)
return funx(*args, **kwargs)
return inner
@judg_isdir
def mydir():
if os.path.isfile(file_path): # 如果檔案存在
print("檔案存在")
with open(file_path, "a", encoding="urf-8") as f_a:
f_a.write("寫入內容") # 追加檔案中的內容
else:
print("檔案不存在")
with open(file_path, "w", encoding="utf-8") as f_w:
f_w.write("寫入內容")
mydir()
擴展:檔案編碼知識
ASCII
ASCII (American Standard Code for Information Interchange,美國資訊交換標準代碼)是基于拉丁 字母 的一套編碼,主要用于顯示現代英語和其他西歐語言,是最通用的資訊交換標準,并等同于國際標準 ISO/IEC 646
ASCII 第一次以規范標準的型別發表是在1967年,最后一次更新則是在1986年,到目前為止共定義了128個字符
由于計算機是美國人發明的,因此最早只有 ASCII 被編碼到計算機里,大小寫英文字母、數字和一些符號
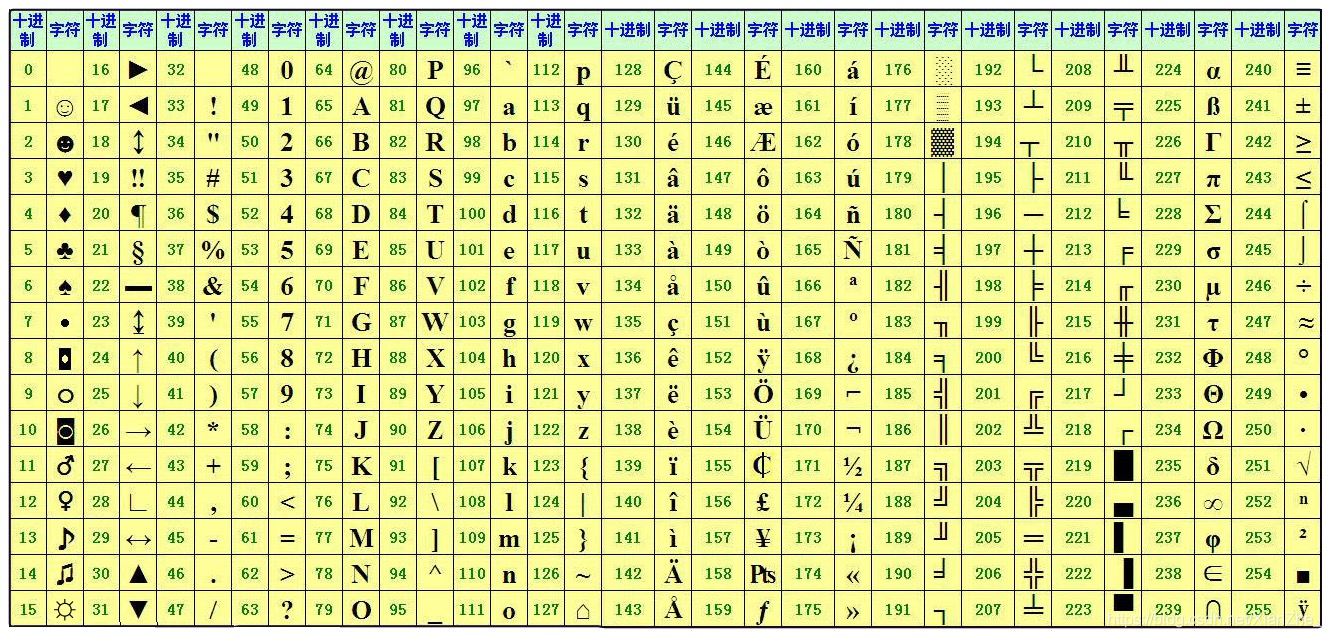
大寫字母 A 對應的編碼是65,小寫字母 a 對應編碼是97,數字 1 對應的編碼是 49
這些都可以通過 Python內置函式 ord() 進行查看
print(ord("A"))
print(ord("a"))
print(ord("1"))
GB2312 & GBK
GB2312 和 GBK 都為 國產編碼,GB2312 于1980年 最早發布
GBK 是 GB2312 的升級版,加入更多字符,向下與 GB 2312 編碼兼容國產編碼,一直用到現在,Windos中文平臺 默認編碼依舊是 GBK
可以在 命令提示符 中的屬性 看到Windos平臺 默認的編碼
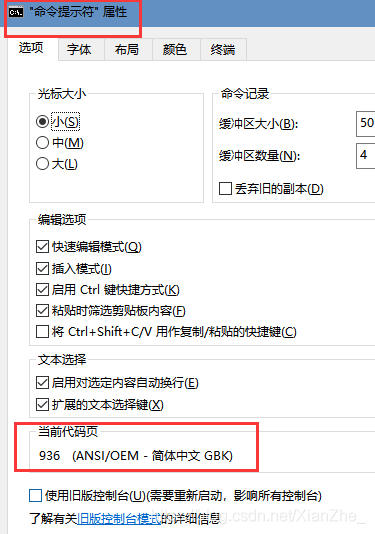
Unicode
Unicode 是 ISO(國際標誰化組織)制定的可以容納世界上所有文字和符號的字符編碼,所以又俗稱 萬國碼、統一碼,解決了 傳統的字符編碼方案的局限(簡單來說:每個國家都有自己一套的編碼標準,如果跨國辦公或者跨國產品,很容易出現各個國家編碼不相通,造成亂碼,在當時萬國碼沒出來之前,各國之間的編碼可謂是戰國時期,亂碼現象很常見)
特點:
-
Unicode 為每種語言中的每個字符設定了統一并且唯一的二進制編碼,以滿足跨語言、跨平臺進行文本轉換、處理、閱讀,極大改善了不同國家之間的資訊傳遞
-
可以跟各種語言的編碼自由轉換,兼容性很強,比如說用 gbk編碼 的文本 ,可以轉成Unicode
-
容納世界上所有文字和符號的字符編碼
UTF-8
Unicode 是 字符集,UTF-8 是 編碼規則
UTF-8 就是 Unicode 的實作方式,對unicode字符集進行編碼的一種編碼方式
在計算機記憶體中,使用Unicode編碼,當需要保存到硬碟或者需要傳輸的時候,就轉換為UTF-8編碼
具體流程:編輯文本時,從檔案讀取 UTF-8 字符轉換為 Unicode 字符到記憶體里,進行編輯操作,編輯完成后,再把記憶體中的 Unicode 字符 轉換為UTF-8 字符 存盤到檔案里
注意:utf-8 不能直接于 gbk 轉換,需要有 Unicode 作為中間人 過渡,這是為什么 在WIndows平臺上 打開utf-8文本檔案時容易出現亂碼的原因
此外 還有UTF-16,UTF-32
對比表
依據 出現時間 排序
| 編碼 | 出現時間 | 描述 | 所占大小 |
|---|---|---|---|
| ASCII | 1967年 | 最早誕生編碼,英語和西歐語言 | 一位元組 |
| GB2312 | 1980年 | 國產簡體中文編碼,兼容 ASCII 碼 | 兩位元組 |
| Unicode | 1991年 | 國際統一標準字符集,俗稱萬國碼 | 兩位元組 |
| GBK | 1995年 | GB2312升級版,支持繁體,加入更多字符 | 兩位元組 |
| UTF-8 | 1992年 | 不定長編碼 | 1 - 3 位元組 |
相關博客
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/264160.html
標籤:python
上一篇:JavaWeb之會話技術