目的
學習Java爬蟲技術,爬取網路平臺的影視地址,決議為我們自己需要的URL地址,
準備
爬取地址:https://v.qq.com/x/cover/mzc00200js3mdvw.html
環境準備:搭建WebMagic,不知道的可以直接下載代碼,很快入手,也可以參考我的另一篇博客 基于WebMagic爬取某豆瓣電影評論,
碼云地址:https://gitee.com/flashsword20/webmagic
頁面分析
1.獲取每集的視頻地址
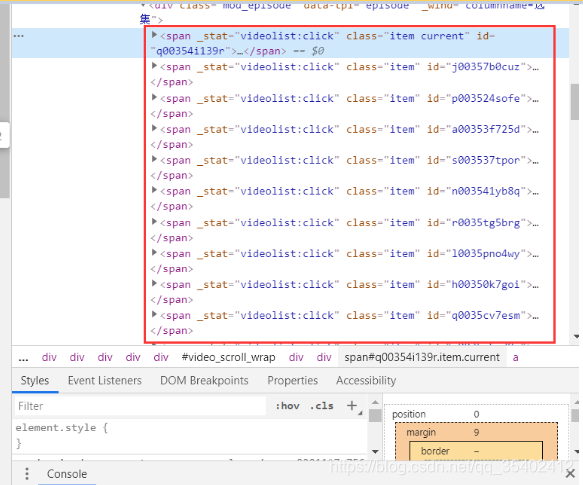
打開爬取網頁,按F12,找到每一集的url存放標簽,
查找發現視頻鏈接都放在類名為item的<span>里,
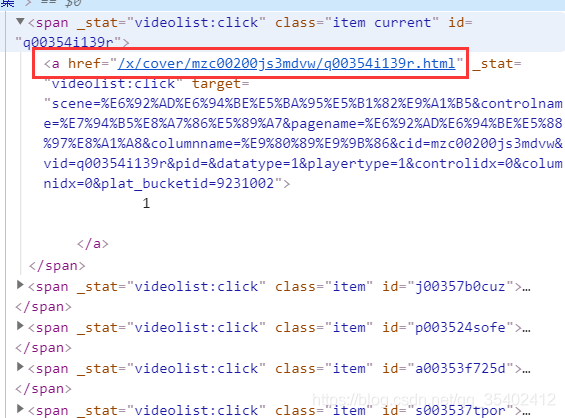
2.視頻決議
既然獲取到了每一集的視頻地址,結合我的另一篇博客 Vip影視的決議介面,既在視頻地址前加決議介面URL就可以決議視頻,
代碼
獲取到電視劇的所有視頻地址,代碼自然很簡單就出來了
import us.codecraft.webmagic.Page;
import us.codecraft.webmagic.ResultItems;
import us.codecraft.webmagic.Site;
import us.codecraft.webmagic.Spider;
import us.codecraft.webmagic.pipeline.FilePipeline;
import us.codecraft.webmagic.processor.PageProcessor;
import java.util.List;
import java.util.Map;
public class TengXunPageProcessor implements PageProcessor {
private Site site;
public TengXunPageProcessor() {
this.site = Site.me().setRetryTimes(3).setSleepTime(300); // 設定站點重試次數3 間隔300ms
}
@Override
public void process(Page page) {
page.putField("title", page.getHtml().xpath("//title/text()")); //爬取網頁標題
// page.putField("html", page.getHtml().toString()); //爬取整個頁面的html
page.putField("urlList", page.getHtml().css("span.item").links().all()); // 我們要爬取的核心資訊內容
page.putField("titleList", page.getHtml().css("span.item>a", "text").all());
}
@Override
public Site getSite() {
//settings
return site;
}
public static void main(String[] args) {
Spider spider = Spider.create(new TengXunPageProcessor()).addPipeline(new FilePipeline("E:\\pipeline", ".txt"));
ResultItems resultItems = spider.<ResultItems>get("https://v.qq.com/x/cover/mzc00200js3mdvw.html");// 爬取并獲得爬取結果
Map<String, Object> map = resultItems.getAll();
for (Map.Entry entry : map.entrySet()) {
System.out.println(entry.getKey() + " : " + entry.getValue()); //列印爬取的所有內容
}
List<String> urlList = (List<String>) map.get("urlList");
List<String> titleList = (List<String>) map.get("titleList");
System.out.println("=====================分隔線===================\n爬取結果如下:");
if (titleList.size() == urlList.size()) {
for (int i = 0; i < urlList.size(); i++) {
System.out.println(titleList.get(i) + ": https://vip.52jiexi.top/?url=" + urlList.get(i)); // 列印決議后的地址
}
}
spider.close();
}
}
運行
結果如下
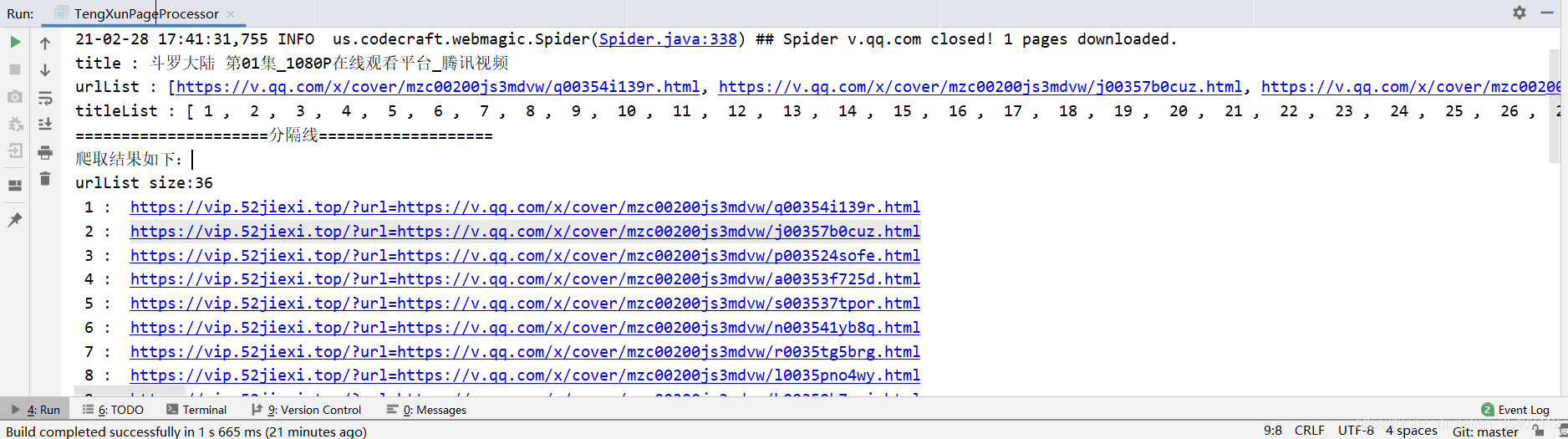
爬取成功,
拓展
其他視頻方式也一樣,如電影,動漫等,只需要替換爬取地址就行,
其他平臺爬取方式類似,
使用代理IP,避免反爬蟲或IP被封,給大家分享一個代理IP,需要的朋友可以去了解下,http://i0k.cn/5dAZa 👇

---------------------------------------------------------------------------------------------------------------------------------------------------
有興趣的朋友可以加Q群交流學習,群里有更多原始碼,學習資料,大神解答,
QQ群:741909960
點我進群
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/265660.html
標籤:java