五、Python資料挖掘(Pandas高級處理)
目錄:
- 五、Python資料挖掘(Pandas高級處理)
- 一、Nan 缺失值處理
- pd.isnull(DataFrame陣列) DataFrame陣列.isnull()
- pd.notnull(DataFrame陣列) DataFrame陣列.notnull()
- 1.處理方式——洗掉:
- DataFrame陣列.dropna(axis="rows", inplace=False)
- 2.處理方式——替換:
- DataFrame陣列.fillna(value, inplace)
- 二、其他型別缺失值處理
- DataFrame陣列.replace(to_replace=" ", value=np.nan)
- 三、資料離散化
- 1.資料類別處理
- 2.資料離散化
- 3.Panda 實作資料離散化
- (1)分組
- sr = pd.qcut(data, bins)
- sr = pd.cut(data, [ ])
- Series陣列.value_counts()
- (2)將分組結果轉換為 one-hot 編碼
- pd.get_dummies(sr, prefix=)
- 四、合并處理
- 1.按方向拼接
- pd.concat([ ], axis=0)
- 2.按索引拼接
- pd.merge(left, right, how="inner", on=[ ])
- 五、交叉表與透視表
- 1.交叉表
- pd.crosstab(value1, value2)
- 2.透視表
- DataFrame陣列.pivot_table([ ], index=[ ])
- 六、分組與聚合
- object_ = DataFrame.groupby(by=索引, as_index=False)
一、Nan 缺失值處理
回顧:在 Numpy庫 中介紹到,當讀取的資料檔案中包含 空格 或一些 字串 時就可能會出現缺失值 NaN
處理思路:
- 洗掉含有缺失值的樣本
- 替換/插補缺失值,如:平均值替換
具有一定的復雜程度,在 Pandas 中就較為容易
判斷是否為缺失值 NaN:
pd.isnull(DataFrame陣列)
DataFrame陣列.isnull()上述兩種呼叫方式都可以
判斷 DataFrame陣列 中是否為缺失值,是則對應位置為 True ,否則對應位置為 Falsepd.notnull(DataFrame陣列)
DataFrame陣列.notnull()上述兩種呼叫方式都可以
判斷 DataFrame陣列 中是否有值,是則對應位置為 True ,否則對應位置為 False
例:快速判斷一個 DataFrame陣列 中是否存在缺失值:
np.any() 配合 pd.isnull() 的方式,判斷是否存在缺失值:
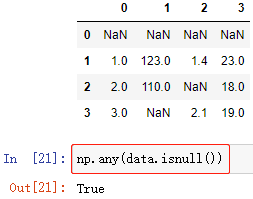
判斷列是否含有缺失值:
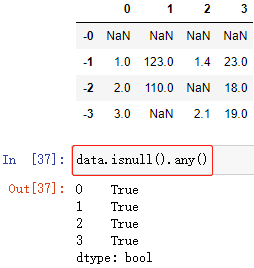
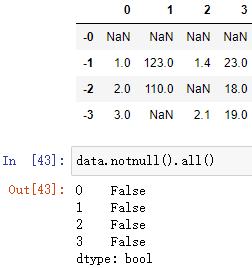
np.all() 配合 pd.notnull() 的方式,判斷是否都有值:

判斷列是否都有值:
1.處理方式——洗掉:
DataFrame陣列.dropna(axis=“rows”, inplace=False)
把含有缺失值 NaN 的行洗掉
當 axis=“rows” 時,會洗掉含缺失值 NaN 的行,axis 默認為 rows
當 axis=“columns” 時,會洗掉含缺失值 NaN 的列
當 inplace=True 時,會直接在原 DataFrame陣列 上進行修改
當 inplace=False 時,會回傳一個洗掉含 NaN 行的新陣列,不會修改 DataFrame陣列,inplace 默認為 False
例:

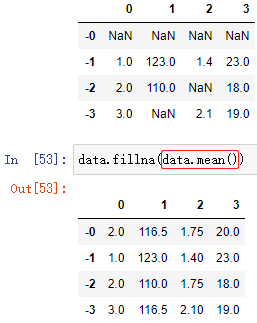
2.處理方式——替換:
DataFrame陣列.fillna(value, inplace)
將 DataFrame陣列 中的缺失值 NaN 統一修改為 value
value 統一修改后的值
當 inplace=True 時,會直接在原 DataFrame陣列 上進行修改
當 inplace=False 時,會回傳一個修改后的新陣列,不會修改 DataFrame陣列,inplace 默認為 False
例:分別替換為各列對應的平均值
二、其他型別缺失值處理
缺失值可能不是 NaN,可能是其他標記值,如:?
此時,我們需要把 ? 替換為 np.nan ——即 NaN 缺失值型別,再對 NaN 缺失值進行處理
DataFrame陣列.replace(to_replace=" ", value=np.nan)
把是 to_replace 的值全部替換為 value
to_replace=" " 是需要替換的值,如:to_replace="?"
value= 是替換成的值,如:value=np.nan,替換成 NaN 缺失值
三、資料離散化
1.資料類別處理
一般來說,事物的屬性可能并不完全能夠使用數字來表示,如:性別男或女,毛發的顏色等等......
以性別為例,如果以數字代表男女,如:1-男、2-女,但是計算機并不懂得這一數字的含義,以計算機的角度來看,計算機知道只知道這是兩個數字,并且它們具有大小排名,但是性別屬性是不應該具有大小排名之分的,這樣帶來的影響并不好,如何處理這些資料呢?
處理思路:額外增加其他屬性,符合時為1,不符合時為0即可

2.資料離散化
連續屬性的離散化就是將連續屬性的值域上,將值域劃分為若干個離散的區間,最后用不同的符號或整數值代表落在每個子區間中的屬性值
比如說:以身高為例
資料:
height = [165, 174, 160, 180, 159, 163, 192, 184]
離散化:

連續屬性離散化的目的是為了簡化資料結構,資料離散化技術可以用來減少給定連續屬性值的個數,離散化方法經常作為資料挖掘的工具
3.Panda 實作資料離散化
(1)分組
自動分組:
sr = pd.qcut(data, bins)
實作自動分組
data 需要分組的資料
bins 要分成的組數
回傳值 回傳一個 Series 陣列
sr = pd.cut(data, [ ])
data 需要分組的資料
[ ] 設定的分組區間,這里輸入是所有邊界
回傳值 回傳一個 Series 陣列
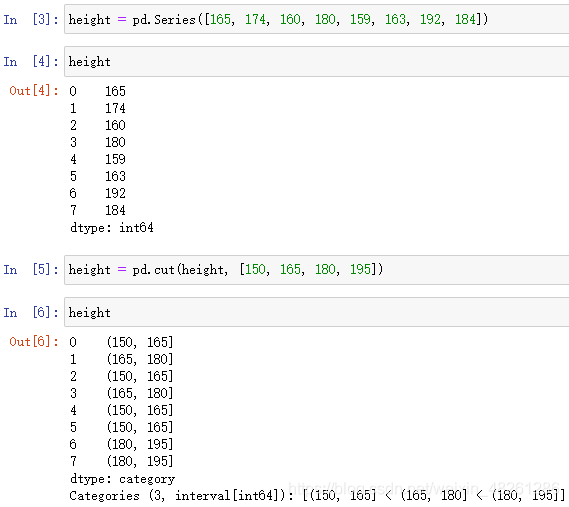
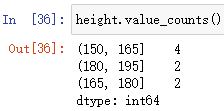
查看分組數量情況:
Series陣列.value_counts()
用于查看分組數量情況
例:
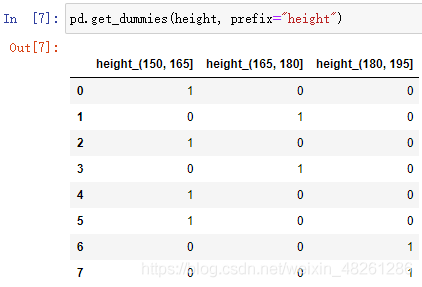
(2)將分組結果轉換為 one-hot 編碼
pd.get_dummies(sr, prefix=)
將分組結果轉換為 one-hot 編碼
sr 經過分組操作的 Series 陣列
prefix 指定前綴,一般取屬性名即可
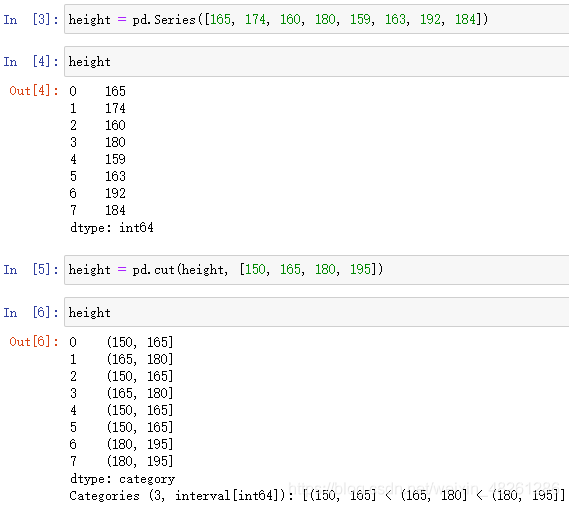
例:就以身高分組為例
資料:
height = [165, 174, 160, 180, 159, 163, 192, 184]
離散化結果:
分組:
將分組結果轉換為 one-hot 編碼:
四、合并處理
1.按方向拼接
pd.concat([ ], axis=0)
按照行或列進行拼接
[ ] 要進行拼接的陣列,串列形式
- axis 指定按行或按列進行拼接:
axis=0 表示進行豎直拼接
axis=1或-1 表示進行水平拼接
注:如果存在資料空缺的情況,空缺的位置用缺失值 NaN 填充
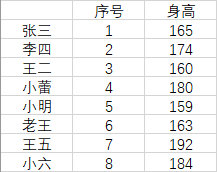
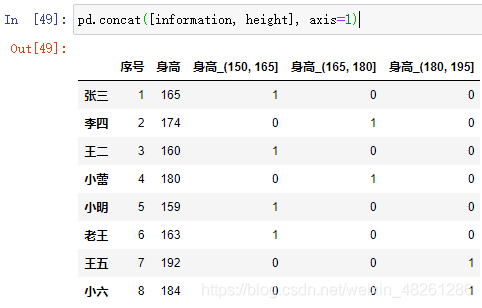
例:根據身高表,對身高進行資料離散化,再利用拼接將離散化后的資料拼接回原身高表中
資料:
 4
4
準備資料:
import numpy as np
import pandas as pd
index = ["張三", "李四", "王二", "小蕾", "小明", "老王", "王五", "小六"]
columns = ["序號", "身高"]
information = np.array([[1, 165], [2, 174], [3, 160], [4, 180], [5, 159], [6, 163], [7, 192], [8, 184]])
information = pd.DataFrame(information, index=index, columns=columns)
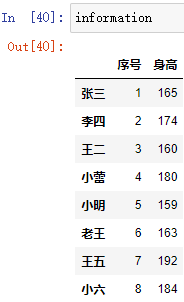
取出資料:
height = pd.Series(information["身高"])
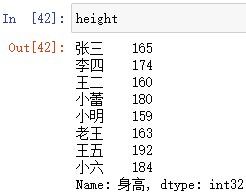
分組:
height = pd.cut(height, [150, 165, 180, 195])
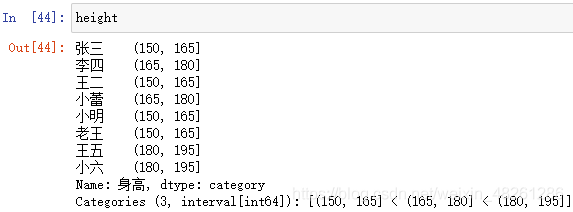
轉換為 one-hot 編碼:
height = pd.get_dummies(height, prefix="身高")
拼接到原資料表上:
information = pd.concat([information, height], axis=1)
2.按索引拼接
可以參考 SQL 中根據索引來進行連接的方式,一般可以根據主碼來進行連接
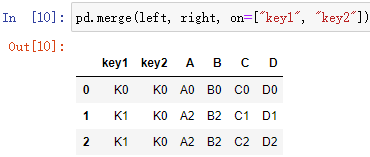
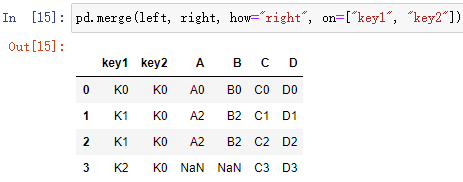
pd.merge(left, right, how=“inner”, on=[ ])
left 左表
right 右表
how=“inner” 連接方式,默認連接方式為內連接
on=[ ] 索引,即按什么索引進行連接,一般可以是主碼或主碼組
| how 引數 | 含義 |
|---|---|
| “left” | 左外連接 |
| “right” | 右外連接 |
| “outer” | 外連接 |
| “inner” | 內連接 |
在有意義的一張表中,索引就是這張表的屬性,而每一行就是一個個不同的事物
當兩張表進行連接時,會根據 on 所指定的索引中值相等的行 (因為 on 指定的索引/屬性中,值相等的行可以視為同一事物,這些行在左表中具有一些屬性;在右表中具有其他屬性,這些所有屬性組合起來,構成了新的表中的這些行的所有屬性) 構成新的表,而那些 on 所指定的索引在兩張表之間沒有相同值的行,在構成新的表時由于缺少了某一張表的屬性,而導致在構成新的表時缺少完整的屬性,而只能用 NaN 來表示
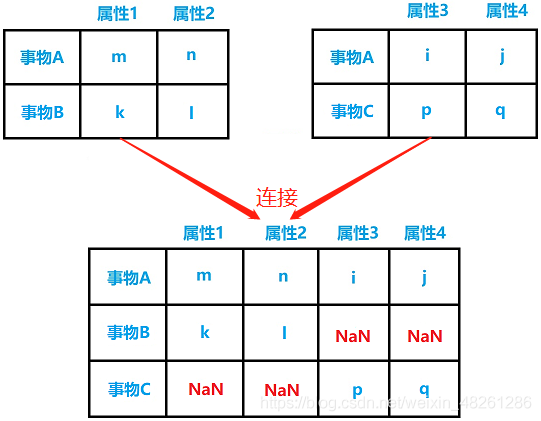
在新的表中,對這些含 NaN 的行的不同的保留情況,分為了四種不同的連接方式:
- 內連接:不保留那些 on 所指定的索引在兩張表之間沒有相同值的行,即不保留含 NaN 的行
- 外連接:保留那些 on 所指定的索引在兩張表之間沒有相同值的行,即保留含 NaN 的行
- 左外連接:保留出現在左表中那些 on 所指定的索引在兩張表之間沒有相同值的行,即保留左表那些含 NaN 的行
- 右外連接:保留出現在右表中那些 on 所指定的索引在兩張表之間沒有相同值的行,即保留右表那些含 NaN 的行
注:大多數情況下使用的是內連接
例:
資料:
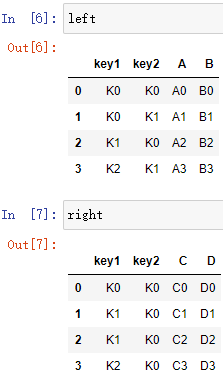
left = pd.DataFrame({"key1": ["K0", "K0", "K1", "K2"],
"key2": ["K0", "K1", "K0", "K1"],
"A": ["A0", "A1", "A2", "A3"],
"B": ["B0", "B1", "B2", "B3"]})
right = pd.DataFrame({"key1": ["K0", "K1", "K1", "K2"],
"key2": ["K0", "K0", "K0", "K0"],
"C": ["C0", "C1", "C2", "C3"],
"D": ["D0", "D1", "D2", "D3"]})
內連接:
外連接:
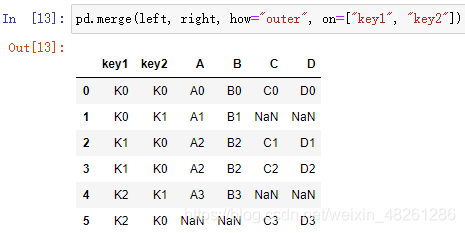
左外連接:
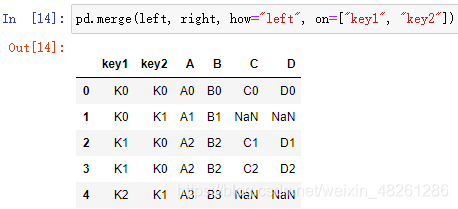
右外連接:
五、交叉表與透視表
交叉表和透視表可以理解成將兩個變數放在一起,探索兩個變數之間的關系
1.交叉表
pd.crosstab(value1, value2)
將 value1 和 value2 兩個資料串列比較
value1 資料串列1
value2 資料串列2
例:
準備資料:自 2020-01-01 開始,生成 600 天的股票漲跌資料
import numpy as np
import pandas as pd
stock_rate = np.random.normal(size=(600, 1))
date = pd.date_range(start = "2021-01-01", periods=600, freq="D")
stock_rate = pd.DataFrame(stock_rate, index=date, columns=["漲跌幅"])
要求:統計星期和漲跌幅之間的關系
根據要求,增加一列星期索引/屬性:
date = pd.to_datetime(stock_rate.index)
stock_rate["星期"] = date.weekday
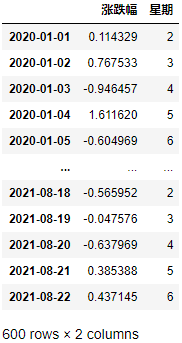
根據要求,增加一列漲跌情況屬性(1表示漲,0表示跌):
stock_rate["漲跌情況"] = np.where(stock_rate["漲跌幅"] > 0, 1, 0)
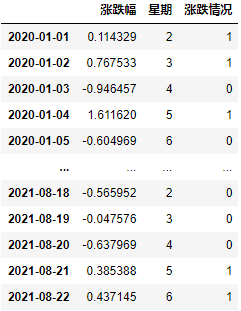
生成交叉表:
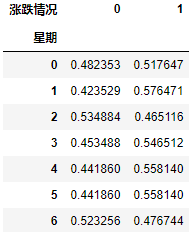
data = pd.crosstab(stock_rate["星期"], stock_rate["漲跌情況"])
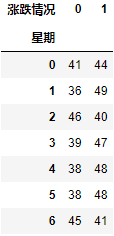
- 這里統計了所有股票中不同星期中的漲跌情況
將交叉表的數值顯示轉化為頻率顯示:
data.div(data.sum(axis=1), axis=0)
首先分別計算每個星期股票的總數:
data.sum(axis=1)
然后再讓每個星期中的漲跌數量情況除以總數,即可轉化為漲跌的頻率:
data.div(data.sum(axis=1), axis=0)
注意:由于 data.sum(axis=1) 是一維陣列,而 data 是二維陣列;我們需要 data 除以豎直的 data.sum(axis=1),因此我們在 div(other[, axis=1]) 中,需要把 other 行列轉置一下,即指定 axis=0 即可
一維陣列: 二維陣列:
二維陣列: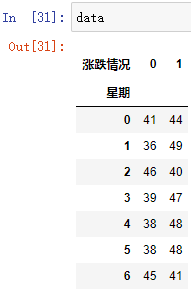
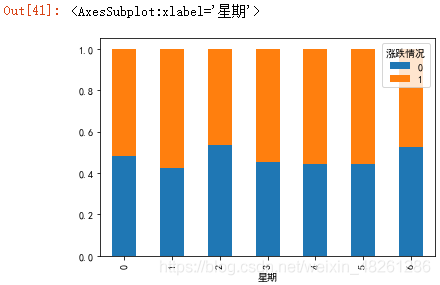
最后我們畫成柱狀圖的形式來進行表示:
data.div(data.sum(axis=1), axis=0).plot(kind="bar", stacked=True)
注:這里的 stacked=True 就是把柱狀圖設定為堆疊顯示
如果出現紅色報錯,可能存在中文顯示錯誤,加上以下代碼即可:
import matplotlib.pyplot as plt
# 指定默認字體
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['font.family']='sans-serif'
# 解決負號'-'顯示為方塊的問題
plt.rcParams['axes.unicode_minus'] = False
2.透視表
DataFrame陣列.pivot_table([ ], index=[ ])
使用透視表,實作剛才的程序更加簡單
DataFrame陣列 需要進行操作的總表
[ ] 需要進行分組的內容——因變數
index=[ ] 按照 index=[ ] 索引進行分組——自變數
例:
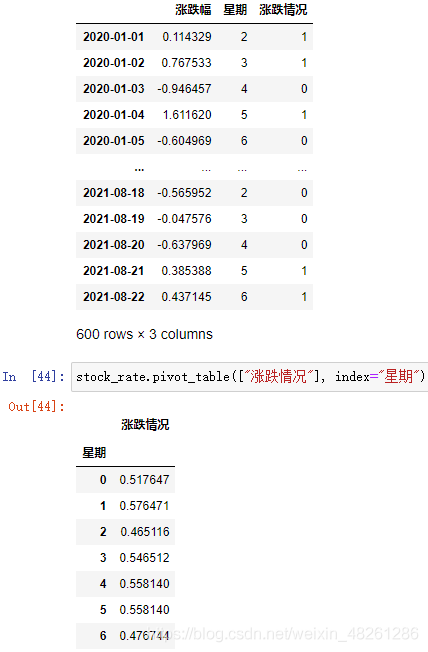
這里直接顯示的就是 1 的占比
六、分組與聚合
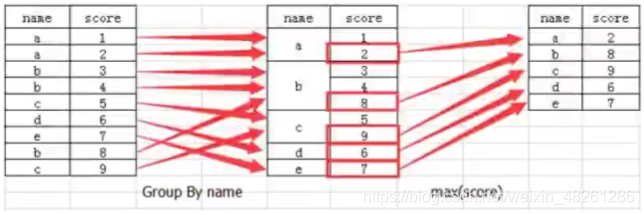
分組與聚合的含義,如圖:
如:表格中的 name 的分數 score 是累加的,且表格中的累加程序并不洗掉,而是保留在表格中,那么這種情況下,就需要對最終分數 score 進行篩選:
如圖,先根據主碼 name 進行分組,分組后取最大值后即為聚合
object_ = DataFrame.groupby(by=索引, as_index=False)
根據 by=索引 對陣列進行分組
by=索引 是分組的依據,會根據指定索引把值相同的行分為一組
例:
資料:
col = pd.DataFrame({"color": ["white", "red", "green", "red", "green"],
"object": ["pen", "pencil", "pencil", "ashtray", "pen"],
"price1": [5.56, 4.20, 1.30, 0.56, 2.75],
"price2": [4.75, 4.12, 1.60, 0.75, 3.15]})
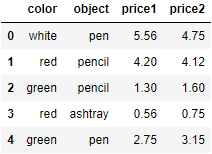
分組并聚合:
col.groupby(by="color")["price1"].max()

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/265925.html
標籤:python