文章目錄
- 友情提示
- 原始碼以及注釋
- 效果
友情提示
1.爬取的網站為站長之家
2.爬取的時候可以適量少爬一點,夠用就行,小心律師函警告
3.代碼為博主原創,僅供學習參考,請勿用于商業用途!!!
4.網站在迭代,我寫下這篇博文的時候是適用的,其他時間段未必
5.附上原網站的說明

原始碼以及注釋
import requests # 發送請求
from lxml import etree # 資料決議
import time # 執行緒暫停,怕封ip
import os # 創建檔案夾
# 由于目標網站更新了反爬蟲機制,簡單的UA偽裝不能滿足我們的需求,所有對整個訊息頭進行了偽裝
headers = {
'Accept':
'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Encoding':
'gzip, deflate, br',
'Accept-Language':
'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Cache-Control':
'max-age=0',
'Connection':
'keep-alive',
'Cookie':
'__gads=undefined; Hm_lvt_aecc9715b0f5d5f7f34fba48a3c511d6=1614145919,1614755756; '
'UM_distinctid=177d2981b251cd-05097031e2a0a08-4c3f217f-144000-177d2981b2669b; '
'sctj_uid=ccf8a73d-036c-78e4-6b1d-6035e961b0d3; '
'CNZZDATA300636=cnzz_eid%3D1737029801-1614143206-%26ntime%3D1614759211; '
'Hm_lvt_398913ed58c9e7dfe9695953fb7b6799=1614145927,1614755489,1614755737; '
'__gads=ID=af6dc030f3c0029f-226abe1136c600e4:T=1614760491:RT=1614760491:S=ALNI_MZAA0rXz7uNmNn6qnuj5BPP7heStw; '
'ASP.NET_SessionId=3qd454mfnwsqufegavxl5lbm; Hm_lpvt_398913ed58c9e7dfe9695953fb7b6799=1614760490; '
'bbsmax_user=ce24ea68-9f80-42e3-8d4f-53b13b13c719; avatarId=a034b11b-abc9-4bfd-a8b2-bdf7fef644bc-; '
'Hm_lpvt_aecc9715b0f5d5f7f34fba48a3c511d6=1614756087',
'Host':
'sc.chinaz.com',
'If-None-Match':
'',
'Referer':
'https://sc.chinaz.com/jianli/free.html',
'Upgrade-Insecure-Requests':
'1',
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:86.0) Gecko/20100101 Firefox/86.0',
}
# 如果該檔案夾不存在,則創建檔案夾
if not os.path.exists('./moban'):
os.mkdir('./moban')
for i in range(1, 701): # 預計可爬700*20套簡歷模板
print("怕封ip,操作暫停中......") # 操作暫停提示語
time.sleep(15) # 每獲取一個串列頁暫停15s,一個串列頁有20分簡歷模板的鏈接
url = f'https://sc.chinaz.com/jianli/free_{str(i)}.html' # 設定相應的路由i
try: # 例外處理
response = requests.get(url=url, headers=headers)
except Exception as e:
print('連接失敗,選擇跳過!!!') # 連不上就不要連了,頭鐵容易出事
response.encoding = 'utf-8' # 中文編碼為utf-8
page = response.text # 獲取回應的文本資料
tree = etree.HTML(page) # 用etree進行資料決議
a_list = tree.xpath("//div[@class='box col3 ws_block']/a") # 用xpath提取目標內容形成20份一起的串列
for a in a_list:
resume_href = 'https:' + a.xpath('./@href')[0] # 根據爬取的鏈接設定新的網頁
resume_name = a.xpath('./img/@alt')[0] # 爬取名字,并對串列進行切片取第一個
try: # 例外處理
resume_response = requests.get(url=resume_href, headers=headers) # 進入簡歷模板詳情頁面
except Exception as e:
print('連接失敗,選擇跳過!!!') # 連不上就不要連了,頭鐵容易出事
resume_response.encoding = 'utf-8' # 中文編碼為utf-8
resume_page = resume_response.text # 獲取回應的文本資料
resume_tree = etree.HTML(resume_page) # 用etree進行資料決議
resume_link = resume_tree.xpath('//ul[@class="clearfix"]/li/a/@href')[0] # 用xpath提取目標內容的下載鏈接
try: # 例外處理
download = requests.get(url=resume_link, headers=headers).content # 獲取二進制資料
except Exception as e:
print('連接失敗,選擇跳過!!!') # 進入簡歷模板詳情頁面
download_path = './moban/' + resume_name + '.rar' # 設定保存路徑以及檔案名稱
with open(download_path, 'wb') as fp: # 設定檔案制作,以二進制形式
fp.write(download) # 保存檔案
print(resume_name, '下載成功!!!') # 下載成功提示語
print("怕封ip,操作暫停中......") # 操作暫停提示語
time.sleep(5) # 每下載一份模板暫停5s
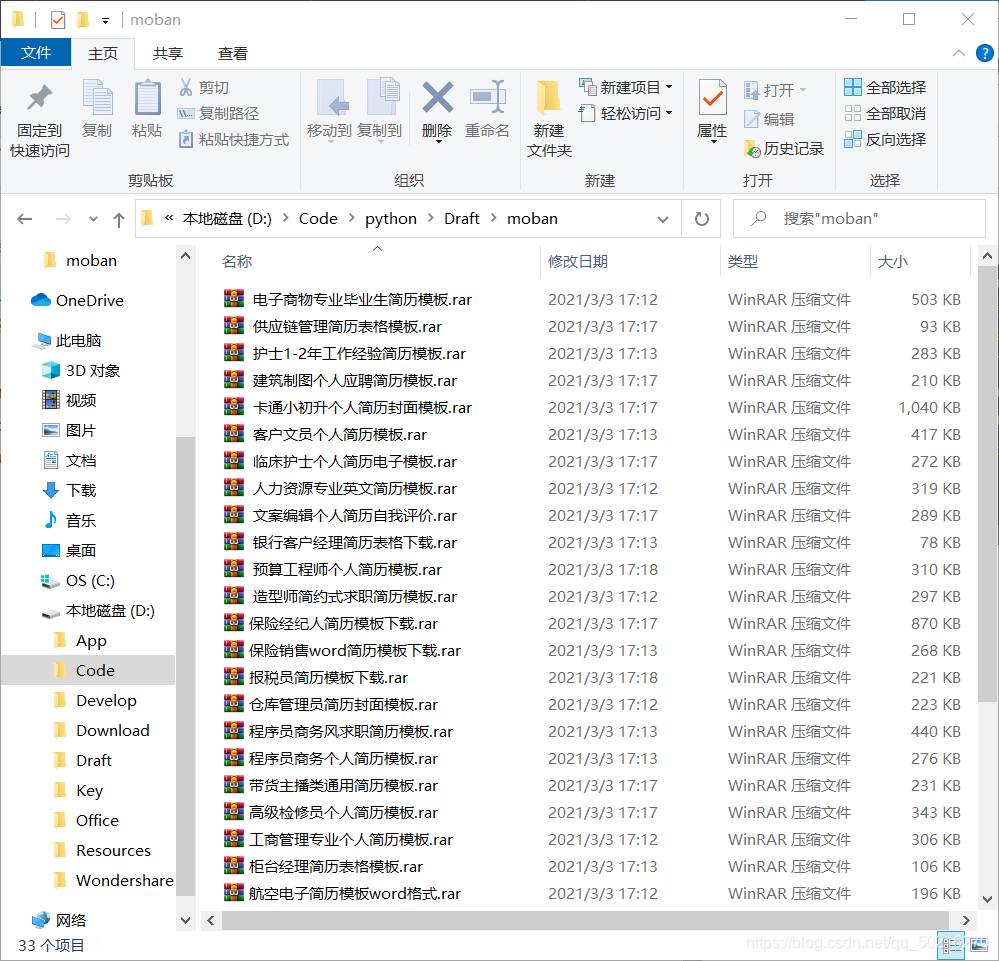
效果
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/265930.html
標籤:python