2021中科大軟體學院 絕對是最內卷的一年,400分以上據可靠統計已經有419人,好在中科大還有較高單科劃線的傳統,總分不但要過復試線,單科線也需要過線才能順利進入復試,除此之外中科大軟體學院一向重視數學和計算機專業考試,所以這就為部分總分處于尷尬370-390區間但數學和專業偏高的考生看到了生的希望,是的,博主我也是處于這尷尬的分數區間內,
那么與其焦慮的等待和被群里的各種搞心態,不如主動的去分析進復試的概率,好不太絕望或是有個心里準備,
下面開始進入正題****************************************************************************************************
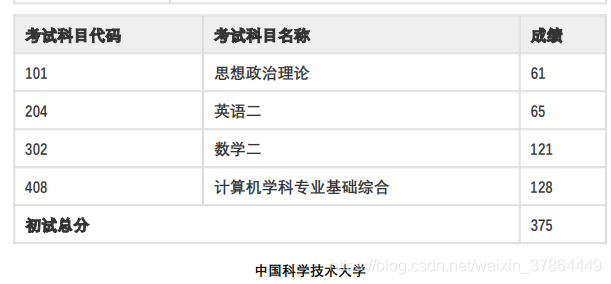
既然數學和專業單科最侄訓線未知,那么就有了可分析的物件,這時很容易想到應該對單科劃線的分數區間建立概率分布,
根據群里的訊息和其他知乎等非官方渠道,數學單科劃分極大可能出現在105--115磁區間,由于數學普遍都高分,難以很好卡人,但專業課不同,卡人還是有那么一點狠的,不妨假設專業分數劃線在105--120區間內,那么就可以開始對數學和專業分數劃線區間建立概率分布了:
(ps:這是我預估的劃線的概率分布,當然有我主觀因素,可能不是很準確,之所以數學107分開始概率變高,這來源于群里訊息)
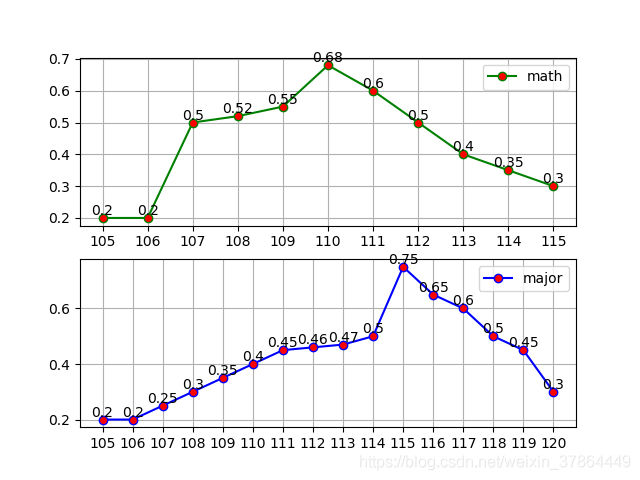
注:為方便定義分布,每個分數段對應的比例都是在0-1范圍取值(如專業課115分可以在0-1范圍內取比例值,這里取了0.75),之后再歸一化,使區間內比例和為1,即轉換為概率
有了概率分布后,接下來可以開始建模并計算出分數390--370區間內各分數段過復試線的概率了!建模思路并不復雜:
數學劃線區間是105--115分,共10個分數段,專業劃線區間是105--120分,共15個分數段,那么數學劃線和專業劃線的排列組合就有10*15=150種,對每一種組合(如數學劃線110,專業劃線115),我們只需要從1560名考生(今年考生人數)中去掉兩科中一科沒達到劃線成績的考生,然后從剩余考生中找到排名第600名的考生成績作為該組合的復試分數線(這里600名是因為有訊息說擴張,不妨假設復試名額為前600名),對所有組合都進行上述操作,我們就可以得到每一種組合的復試分數線了,
假設分數線劃到某組合的數學的概率為X,專業的概率為Y,那么每一種組合的概率P為:
P = X * Y
經過上面的處理后,就得到了每一種組合的復試分數線和劃線概率,
接下來就可以開始計算總分390--370區間內各分數段過復試線的概率了,假設待計算的總分為 S , S 過復試線的概率為PS,PS初始為0,將S與各組合復試線大小比較,如果S大于或等于該組合的復試線,就把該組合概率P加到PS中,即
PS += P (if S>=組合的復試線)
(注意上面概率統計是統計一般情況下的概率,即不針對某個人具體各科分數去統計進復試概率,也就是說總是認為存在某個總分S,當它大于或等于該組合的復試線時,其各科也不小于該組合的劃線,若要具體針對某個人各科分數計算過復試概率,那么計算概率的方法應改為當這個人總分大于或等于該組合的復試線且數學和專業單科不小于該組合劃線時才把該組合概率P加到PS中!)
完成這些操作后我們就得到該分數過復試線的一般概率了!下圖計算了分數360--390區間內各分數段過復試線的一般概率:
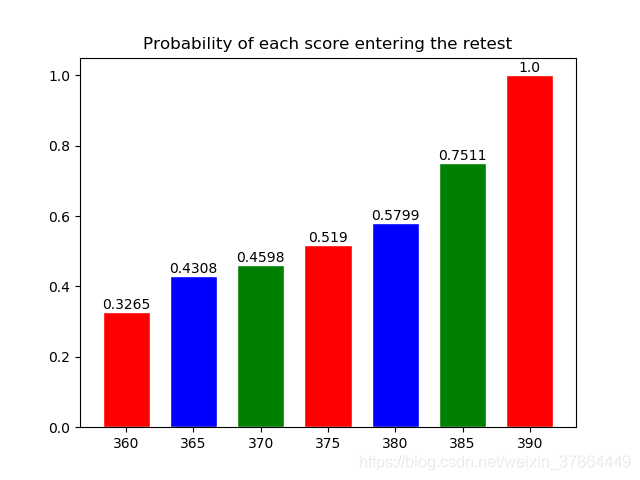
很好,對于375的我來說過線的一般概率是51.9%,額一半的概率,不說了我去燒香了~
點擊下載分數排名excel檔案
附代碼(python):
"""
licene:劉東無敵
2021/3/3
"""
import xlrd
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
xlsxPath='studentScore.xlsx'#全部考生成績統計excel表檔案路徑
mathFilterScoreRank=(105,115)#左閉右閉,數學劃線分數區間
mathFilterProportion=[0.2,0.2,0.50,0.52,0.55,0.68,0.6,0.5,0.4,0.35,0.3]#數學各分數段劃線概率(比例),每個元素取值范圍0-1
majorFilterScoreRank=(105,120)#左閉右閉,專業劃線分數區間
majorFilterProportion=[0.2,0.2,0.25,0.3,0.35,0.4,0.45,0.46,0.47,0.5,0.75,0.65,0.6,0.5,0.45,0.3]#專業各分數段劃線概率(比例),每個元素取值范圍0-1
totalEnrollment=600#計劃錄取人數
#輸出各分數進復試的概率
outPutScore=[390,385,380,375,370,365,360]
#將劃線比例轉換為概率
def changeProportionToProbability(listProportion):
sumProportion=sum(listProportion)
listProbability = [value/sumProportion for value in listProportion]
return listProbability
def read_excel(xlsxPath):
# 打開檔案
workBook = xlrd.open_workbook(xlsxPath)
#按索引號獲取sheet內容
sheet1_content1 = workBook.sheet_by_index(0)# sheet索引從0開始
content=[]
for rowIndex in range(sheet1_content1.nrows):
value=sheet1_content1.row_values(rowIndex)[2:4]#數學分數,專業分數
value.append(sheet1_content1.cell_value(rowIndex, 5))#append 總分數
content.append(value)
return content
def calScoreLineProbability(content,mathFilterProbability,majorFilterProbability):
minScores=[]
#僅保留過線的分數
for mathScore in range(mathFilterScoreRank[0],mathFilterScoreRank[1]+1):
for majorScore in range(majorFilterScoreRank[0],majorFilterScoreRank[1]+1):
# print(mathScore,majorScore)
filterTotalScore=[]#保留過線的人的總分
for rowValue in content:
if rowValue[0]>=mathScore and rowValue[1]>=majorScore:
filterTotalScore.append(rowValue[2])
if len(filterTotalScore)>=totalEnrollment:
minScores.append(filterTotalScore[totalEnrollment-1])
else:
minScores.append(filterTotalScore[-1])
outPutScoreProbability=[0 for _ in outPutScore]
#對outPutScore各個分數段計算入線概率
majorFilterLen = len(majorFilterProportion)
for outIndex,outScore in enumerate(outPutScore):
for minIndex,minScore in enumerate(minScores):
if outScore>=minScore:
outPutScoreProbability[outIndex]+=(mathFilterProbability[minIndex//majorFilterLen]*majorFilterProbability[minIndex%majorFilterLen])
return outPutScoreProbability
if __name__ == '__main__':
#將比例轉換為概率
mathFilterProbability = changeProportionToProbability(mathFilterProportion)
majorFilterProbability = changeProportionToProbability(majorFilterProportion)
#計算過線概率
content=read_excel(xlsxPath)
outPutScoreProbability=calScoreLineProbability(content,mathFilterProbability,majorFilterProbability)
print("Probability:", outPutScoreProbability)
outPutScoreProbability=[float('%.4f' % x) for x in outPutScoreProbability]#修改精度
#繪圖********************************************************************************************
#繪制概率分布圖
fig1 = plt.figure(2)
plt.subplot(211)
x=[str(mathScore) for mathScore in range(mathFilterScoreRank[0],mathFilterScoreRank[1]+1)]
#y=[float('%.3f' % p ) for p in mathFilterProbability]
y=mathFilterProportion
plt.plot(x,y,color='g',label="math", markerfacecolor='r', marker='o')
for a, b in zip(x, y):
plt.text(a, b, b, ha='center', va='bottom', fontsize=10)
plt.legend()
plt.grid() # 添加網格
# subplot(211)把繪圖區域等分為2行*1列共兩個區域,然后在區域1(上區域)中創建一個軸物件
plt.subplot(212) # 在區域2(下區域)創建一個軸物件
x=[str(majorScore) for majorScore in range(majorFilterScoreRank[0],majorFilterScoreRank[1]+1)]
#y = [float('%.3f' % p) for p in majorFilterProbability]
y=majorFilterProportion
plt.plot(x,y,color='b',label="major", markerfacecolor='r', marker='o')
for a, b in zip(x, y):
plt.text(a, b, b, ha='center', va='bottom', fontsize=10)
plt.legend()
plt.grid() # 添加網格
# 繪制各分數過復試線概率
fig2 = plt.figure(1)
# 添加資料標簽
def add_labels(rects):
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, height, height, ha='center', va='bottom')
# 柱形圖邊緣用白色填充,純粹為了美觀
rect.set_edgecolor('white')
rect=plt.bar(outPutScore, outPutScoreProbability,width=3.5,color='rgb')
add_labels(rect)
plt.gca().xaxis.set_major_locator(ticker.MultipleLocator(5))
plt.title(u'Probability of each score entering the retest')
plt.show()
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/266378.html
標籤:python
下一篇:Python對Excel進行處理