爬取某小說網站
from bs4 import BeautifulSoup
import urllib.request
from fake_useragent import UserAgent
# 爬取資料
def getdata(url):
headers = {
"User-Agent":UserAgent().random
}
res = urllib.request.Request(url,headers=headers)
response = urllib.request.urlopen(res)
strre = str(response.read().decode('gbk'))
num1 = strre.find('<',0,100)
num2 = strre.find('>',0,100)
name = strre[num1+1:num2]
data = [strre,name]
return data
# 保存資料
def savedata(strre,name):
f = open('D:/小說/試試'+'/'+name+".txt",'wb')
f.write(strre.encode())
f.close()
print("爬取成功")
if __name__ == '__main__':
url = "http://dl.wenku8.com/txtgbk/2/2500.txt"
data = getdata(url)
savedata(data[0],data[1])
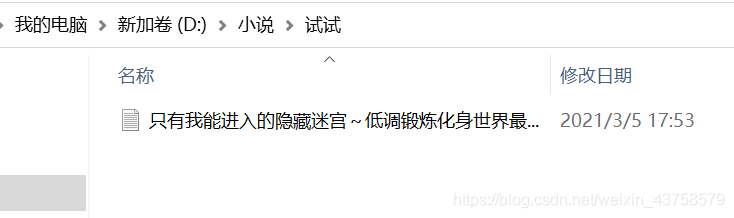
如圖
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/267124.html
標籤:python