用RNN寫詩
- 1. 背景
- 2. 資料描述
- 3. 資料使用
- 4. LSTM函式
- 5. Model
- 6. Train
- 7. Test
- 8. 全部代碼
- 小結
1. 背景
書上的內容可見此,一些關于此的博客1,2
實驗資料來自Github上中文愛好者收集的5萬多首唐詩,作者在此基礎上進行了一些資料處理,由于資料處理很耗時間,且不是pytorch學習的重點,這里省略,作者提供了一個numpy的壓縮包tang.npz,下載地址在此
2. 資料描述
import numpy as np
# 加載資料
datas = np.load('...your path/tang.npz', allow_pickle=True)
data = datas['data'] # numpy.ndarray
print(data)
print(np.shape(data))
[[8292 8292 8292 ... 846 7435 8290]
[8292 8292 8292 ... 7878 7435 8290]
[8292 8292 8292 ... 4426 7435 8290]
...
[8292 8292 8292 ... 7739 7435 8290]
[8292 8292 8292 ... 7290 7435 8290]
[8292 8292 8292 ... 1294 7435 8290]]
(57580, 125)
data是一個57580 * 125的numpy陣列,即總共有57580首詩歌,每首詩歌長度為125個字符(不足125補空格,超過125的丟棄)
ix2word = datas['ix2word']
print(ix2word)
{0: '憁', 1: '耀', 2: '枅', 3: '涉', 4: '談',...,, 8290: '<EOP>', 8291: '<START>', 8292: '</s>'}
ix2word = datas['ix2word']
ix2word2 = datas['ix2word'].item()
print(ix2word == ix2word2)
True
可以發現字典有沒有.item()都是一樣的,但是發現去掉回使用報錯IndexError: too many indices for array
ix2word = datas['ix2word']
print(type(ix2word))
ix2word2 = datas['ix2word'].item()
print(type(ix2word2))
<class 'numpy.ndarray'>
<class 'dict'>
這兩個實際上是不一樣的,更直觀的例子:
x = np.array({8290: '<EOP>', 8291: '<START>', 8292: '</s>'})
print(x)
print(x.item())
print(type(x))
print(type(x.item()))
print(x[0])
{8290: '<EOP>', 8291: '<START>', 8292: '</s>'}
{8290: '<EOP>', 8291: '<START>', 8292: '</s>'}
<class 'numpy.ndarray'>
<class 'dict'>
IndexError: too many indices for array
關于numpy中.item用法:
x = np.random.randint(9, size=(3, 3)) x array([[2, 2, 6], [1, 3, 6], [1, 0, 1]]) x.item(3) 1 x.item(7) 0 x.item((0, 1)) 2 x.item((2, 2)) 1
所以推測這里字典的儲存還是以numpy陣列格式儲存的,所以需要使用.item()把字典取出來
ix2word = datas['ix2word'].item()
# 查看第一首詩歌
poem = data[0]
print(poem)
print(len(poem))
# 詞序號轉成對應的漢字
poem_txt = [ix2word[i] for i in poem]
print(''.join(poem_txt))
[8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8292 8291 6731 4770 1787 8118 7577 7066 4817 648 7121 1542 6483 7435 7686 2889 1671 5862 1949 7066 2596 4785 3629 1379 2703 7435 6064 6041 4666 4038 4881 7066 4747 1534 70 3788 3823 7435 4907 5567 201 2834 1519 7066 782 782 2063 2031 846 7435 8290]
125
</s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s></s><START>度門能不訪,冒雪屢西東,已想人如玉,遙憐馬似驄,乍迷金谷路,稍變上陽宮,還比相思意,紛紛正滿空,<EOP>
可以發現’,‘對應著’7435’,’,‘對應著’7435’
同樣的,可以由詩歌轉化為數字:
word2ix = datas['word2ix'].item()
# 漢字轉成對應的詞序號
poem_txt = '度門能不訪,冒雪屢西東,'
poem = [word2ix[i] for i in poem_txt]
print(poem)
[6731, 4770, 1787, 8118, 7577, 7066, 4817, 648, 7121, 1542, 6483, 7435]
關于np.load()函式中的這個引數allow_pickle=True,功能是:布林值,允許使用Python pickles保存物件陣列,去掉的話會報錯:ValueError: Object arrays cannot be loaded when allow_pickle=False,所以就加上
3. 資料使用
import numpy as np # tang.npz的壓縮格式處理
import os # 打開檔案
import torch
def get_data():
if os.path.exists(data_path):
datas = np.load(data_path, allow_pickle=True) # 加載資料
data = datas['data'] # numpy.ndarray
word2ix = datas['word2ix'].item() # dic
ix2word = datas['ix2word'].item() # dic
return data, word2ix, ix2word
if __name__ == '__main__':
data_path = '...your path/tang.npz'
data, word2ix, ix2word = get_data()
data = torch.from_numpy(data)
dataloader = torch.utils.data.DataLoader(data, batch_size=128, shuffle=True, num_workers=1) # shuffle=True隨機打亂
這里沒有將data實作為一個DataSet物件,但是它還是可以利用DataLoader進行多執行緒加載,這是因為Data作為一個Tensor物件,已經實作了__getitm__和__len__方法,getitm[0]等價于data[0],len(data)回傳data.size(0),這種運行方式稱為鴨子型別(Duck Typing),是一種動態型別的風格
4. LSTM函式
再看一遍李宏毅老師2020機器學習關于RNN的課程,關于LSTM在pytorch中引數和用法可看此文章以及官方檔案
對輸入序列的每個元素,LSTM的每層都會執行以下計算: i t = s i g m o i d ( W i i x t + b i i + W h i h t ? 1 + b h i ) f t = s i g m o i d ( W i f x t + b i f + W h f h t ? 1 + b h f ) o t = s i g m o i d ( W i o x t + b i o + W h o h t ? 1 + b h o ) g t = t a n h ( W i g x t + b i g + W h g h t ? 1 + b h g ) c t = f t c t ? 1 + i t g t h t = o t ? t a n h ( c t ) \begin{aligned} i_t &= sigmoid(W_{ii}x_t+b_{ii}+W_{hi}h_{t-1}+b_{hi}) \ f_t &= sigmoid(W_{if}x_t+b_{if}+W_{hf}h_{t-1}+b_{hf}) \ o_t &= sigmoid(W_{io}x_t+b_{io}+W_{ho}h_{t-1}+b_{ho})\ g_t &= tanh(W_{ig}x_t+b_{ig}+W_{hg}h_{t-1}+b_{hg})\ c_t &= f_tc_{t-1}+i_tg_t\ h_t &= o_t*tanh(c_t) \end{aligned} it??=sigmoid(Wii?xt?+bii?+Whi?ht?1?+bhi?) ft??=sigmoid(Wif?xt?+bif?+Whf?ht?1?+bhf?) ot??=sigmoid(Wio?xt?+bio?+Who?ht?1?+bho?) gt??=tanh(Wig?xt?+big?+Whg?ht?1?+bhg?) ct??=ft?ct?1?+it?gt? ht??=ot??tanh(ct?)? h t h_t ht?是時刻 t t t的隱狀態, c t c_t ct?是時刻 t t t的細胞狀態, x t x_t xt?是上一層的在時刻 t t t的隱狀態或者是第一層在時刻 t t t的輸入, i t , f t , g t , o t i_t, f_t, g_t, o_t it?,ft?,gt?,ot? 分別代表 輸入門,遺忘門,細胞和輸出門
nn.LSTM引數:
- input_size :輸入的維度
- hidden_size:h的維度
- num_layers:堆疊LSTM的層數,默認值為1
- bias:偏置 ,默認值:True
- batch_first: 如果是True,則input為(batch, seq, input_size),默認值為:False(seq_len, batch, input_size)
- bidirectional :是否雙向傳播,默認值為False
輸出:
- output :(seq_len, batch, num_directions * hidden_size)受batch_first影響!
- h_n:(num_layers * num_directions, batch, hidden_size)
- c_n :(num_layers * num_directions, batch, hidden_size)
假如每個詞是100維的向量,每個句子含有24個單詞,一次訓練10個句子,那么batch_size=10,seq=24,input_size=100,(seq指的是句子的長度,input_size作為一個 x t x_{t} xt?的輸入)
model = nn.LSTM(100, 16, num_layers=2) # 詞向量為100維,隱層個數為16個,2層
x = torch.rand(10, 24, 100) # batch=10,seq_len=24,input_size=100
output, (h,c) = model(x)
print(output.size())
print(h.size())
print(c.size())
torch.Size([10, 24, 16])
torch.Size([2, 24, 16])
torch.Size([2, 24, 16])
加上batch_first=True:
model = nn.LSTM(100, 16, num_layers=2, batch_first=True)
x = torch.rand(10, 24, 100) # batch=10,seq_len=24,input_size=100
output, (h,c) = model(x)
print(output.size())
print(h.size())
print(c.size())
torch.Size([10, 24, 16])
torch.Size([2, 10, 16])
torch.Size([2, 10, 16])
model = nn.LSTM(100, 16, num_layers=3, batch_first=True, bidirectional=True)
x = torch.rand(10, 24, 100)
output, (h,c) = model(x)
print(output.size())
print(h.size())
print(c.size())
torch.Size([10, 24, 32])
torch.Size([6, 10, 16])
torch.Size([6, 10, 16])
關于nn.LSTM 輸出的h和c是什么見此文
5. Model
torch.nn.Embedding()將詞向量和詞對應起來,因為沒有指定訓練好的詞向量, 所以embedding會生成一個隨機的詞向量
.new()的作用,創建一個新的Tensor,該Tensor的type和device都和原有Tensor一致,其它可見此
例如:
x = torch.Tensor([1,2,3])
y = x.data[1]
z = x.data.new(2,2,2).fill_(0).float()
print(x)
print(y)
print(z)
結果
tensor([1., 2., 3.])
tensor(2.)
tensor([[[0., 0.],
[0., 0.]],
[[0., 0.],
[0., 0.]]])
模型構建代碼如下:
class Net(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(Net, self).__init__()
self.hidden_dim = hidden_dim
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, self.hidden_dim, num_layers=2, batch_first=True)
# lstm輸入為:batch, seq, input_size
# lstm輸出為:batch * seq * 256; (2 * batch * 256,...)
self.linear1 = nn.Linear(self.hidden_dim, vocab_size)
def forward(self, input, hidden=None):
seq_len, batch_size = input.size()
if hidden is None:
h_0 = input.data.new(2, batch_size, self.hidden_dim).fill_(0).float()
c_0 = input.data.new(2, batch_size, self.hidden_dim).fill_(0).float()
h_0, c_0 = Variable(h_0), Variable(c_0)
else:
h_0, c_0 = hidden
embeds = self.embeddings(input) # (seq_len, batch_size, embedding_dim), (1,1,128)
output, hidden = self.lstm(embeds, (h_0, c_0)) #(seq_len, batch_size, hidden_dim), (1,1,256)
output = self.linear1(output.view(seq_len*batch_size, -1)) # ((seq_len * batch_size),hidden_dim), (1,256) → (1,8293)
return output, hidden
6. Train
torchnet
使用PyTorchNet(torchnet 檔案)里的一個工具:meter,meter提供了一些輕量級的工具,用來幫助用戶快速統計訓練程序中的一些指標:
- AverageValueMeter,計算所有數的平均數和標準差,可以用來統計一個epoch中損失的平均值
- AUCMeter,測量二元分類問題的接收方操作特征(receiver-operating characteristic, ROC)曲線下的面積,曲線下面積(area under the curve, AUC)可以解釋為,給定一個隨機選擇的正例和一個隨機選擇的負例,正例被分類模型賦予比負例更高的分數的概率
- ConfusionMeter,為多類分類問題構建了一個混淆矩陣,是一個比準確率更詳細的統計指標
命令列輸入:
pip install torchnet
tqdm與enumerate()
enumerate()函式是python的內置函式,可以同時遍歷串列中的索引及其元素
from tqdm import tqdm
lt=['a','b','c']
for i,item in enumerate(lt):
print(i,item)
>>> # output
0 a
1 b
2 c
pytorch 中 tensor的資料型別見此
使用torch.transpose(Tensor,dim0,dim1)對pytorch中對tensor矩陣進行轉置,一次只能在兩個維度間進行轉置,之后使用.contiguous()回傳一個記憶體連續的有相同資料的 tensor,具體參考此
資料錯位
data = torch.Tensor([[1,2,3],
[4,5,6],
[7,8,9],
[10,11,12]])
print(data[:-1,:])
print(data[1:,:])
tensor([[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.]])
tensor([[ 4., 5., 6.],
[ 7., 8., 9.],
[10., 11., 12.]])
所以4行的資料實際上訓練了三次,輸入[1., 2., 3.]希望輸出[ 4., 5., 6.],輸入[4., 5., 6.]希望輸出[ 7., 8., 9.]……
訓練報錯:
RuntimeError: CUDA out of memory. Tried to allocate 504.00 MiB (GPU 0; 2.00 GiB total capacity; 713.18 MiB already allocated; 439.91 MiB free; 734.00 MiB reserved in total by PyTorch)
調小batch_size = 8
loss.data[0]報錯:
IndexError: invalid index of a 0-dim tensor. Use `tensor.item()` in Python or `tensor.item<T>()` in C++ to convert a 0-dim tensor to a number
pytorch版本不同,將loss.data[0] 改成loss.item()
訓練四個epoch:
7198it [03:40, 32.59it/s]
7198it [03:42, 32.35it/s]
7198it [03:42, 32.34it/s]
7198it [03:41, 32.51it/s]
訓練曲線如下:
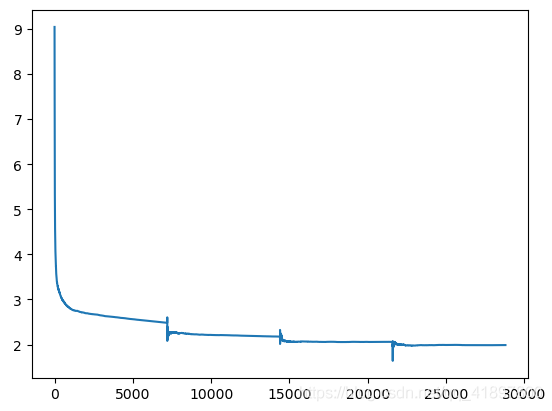
曲線有點不連續,應該是period.append(i + epoch * len(dataloader))有點問題,因為57580/8=71.975,本來就不是連續的
把epoch改為10還是有這個問題……
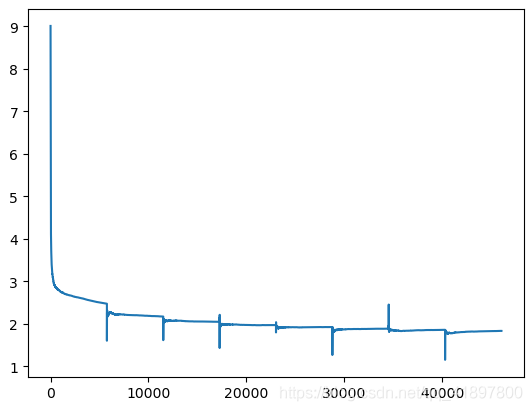
Cuda is available!
576it [00:21, 27.68it/s]574:床前明月光,不不不不人,<EOP>
1149it [00:41, 28.52it/s]1149:床前明月光,不人不不人,<EOP>
1725it [01:01, 26.94it/s]1724:床前明月光,不有不不人,不有不不見,不有不不人,<EOP>
2298it [01:21, 29.06it/s]2299:床前明月光,風風不可知,不知不可見,不見不知人,一人不可見,不知不可知,不知不可見,不見不知人,
2873it [01:41, 28.48it/s]2874:床前明月光,山水不可知,一日不可見,天門不可知,不知不可見,不見一中心,不見天山去,山山不可知,
3450it [02:01, 25.21it/s]3449:床前明月光,月色如不見,一日不可見,一人不可見,一來不可見,一日無所見,一來不可見,一日無所見,
4023it [02:21, 28.36it/s]4024:床前明月光,日日無人間,一日不可見,一日不可知,我人不可見,不得不可知,我有不可見,不知此人間,
4600it [02:41, 26.28it/s]4599:床前明月光,風雨無人語,一年不可見,一日不可見,一年不可知,一日不可見,一年不可知,一日不可見,
5174it [03:01, 28.77it/s]5174:床前明月光,日月無人間,山中有人間,不見青云間,不知此時去,不見青山中,何人不可見,不見東南山,
5750it [03:22, 25.30it/s]5749:床前明月光,一日不可見,一旦不可知,不知何所見,我有不可言,不知何所為,我來不可見,不得無人語,
5758it [03:22, 28.43it/s]
575it [00:21, 24.94it/s]574:床前明月光,一日一相逢,一夜一千里,一年一一年,一年一相見,一夜不可忘,一年不可見,一片不可忘,
1150it [00:41, 25.67it/s]1149:床前明月光,一夜一相逢,一夜一相見,一聲不可攀,一聲不可見,不得不可忘,我有一時人,不如君不知,
1725it [01:02, 25.14it/s]1724:床前明月光,一夜一相望,一聲不可見,一夜不可見,一聲不可見,一夜不可見,一聲不可見,一夜不可見,
2300it [01:22, 25.27it/s]2299:床前明月光,一日一百年,一朝一日日,不見青山人,一言不可見,一日不可尋,一言不可見,一日不可尋,
2873it [01:42, 28.53it/s]2874:床前明月光,日暮一相思,一夜不可見,一聲不可攀,君子不可見,此地不可忘,我有一時人,不知無所如,
3450it [02:02, 24.97it/s]3449:床前明月光,風雨如雨雪,一夜不可見,一夜不可見,一聲不可見,一夜不可見,一夜不可見,一聲不可惜,
4023it [02:22, 28.51it/s]4024:床前明月光,一夜一夜月,一聲一聲起,一夜一枝落,一聲一聲起,一夜一枝落,一聲一聲起,一夜一枝落,
4599it [02:42, 29.03it/s]4599:床前明月光,風吹一枝紅,一夜不可見,一聲不可攀,一聲不可見,一夜不可攀,一夜不可見,一聲不可攀,
5174it [03:02, 28.41it/s]5174:床前明月光,日月如水流,我來不可見,不知心不同,我來不可見,不覺心如何,我來不可見,不知心不窮,
5750it [03:22, 25.05it/s]5749:床前明月光,風吹一枝枝,一夜不可見,一聲不可攀,君不見青山,不見青山中,我有一片日,不見一片霜,
5758it [03:23, 28.32it/s]
575it [00:21, 25.36it/s]574:床前明月光,日月照清光,不知何所有,不覺心如何,不知何所有,不覺不可尋,我來不得意,不覺心如何,
1149it [00:41, 28.45it/s]1149:床前明月光,日落青山里,一朝一朝夕,萬里無所適,我有一朝人,不見天地間,我有一朝客,不見天地間,
1724it [01:01, 28.46it/s]1724:床前明月光,日日無人語,一言一百年,一日不可見,一言一百年,一日不可見,一言一百年,一日不可見,
2299it [01:21, 28.73it/s]2299:床前明月光,日日無人識,一身不可見,一身不可見,一身不可見,一身不可見,一身不可見,一身不可見,
2875it [01:41, 25.07it/s]2874:床前明月光,日月如水色,一夜一夜來,一夜一夜起,一夜一夜月,一一一一聲,一夜不可見,一夜不相思,
3449it [02:01, 28.59it/s]3449:床前明月光,日月如水色,一枝不可見,一夜不可見,君不見,不見人間,我有一時,不如不得,我有一人,
4023it [02:22, 28.47it/s]4024:床前明月光,日月如云起,一葉不可見,一聲不可見,君不見,不見人,不見人間不可知,君不見此時有余,
4600it [02:42, 25.19it/s]4599:床前明月光,日月照秋光,不知何處去,不覺春風來,君不見君子,不見君王孫,君不見君子,妾不見君王,
5173it [03:02, 28.50it/s]5174:床前明月光,風雨一聲清,一旦一杯酒,一杯一片云,一杯不可見,一日不相思,我有一杯酒,不如一榷訓,
5749it [03:22, 28.51it/s]5749:床前明月光,日月照清光,一朝一杯酒,一笑一時新,一朝不可見,一日無所求,我有一日心,不如此中情,
5758it [03:22, 28.38it/s]
573it [00:21, 28.74it/s]574:床前明月光,日日照中庭,一日不相見,一言不可尋,君子不可見,君子不可尋,我有一夫子,不知身不平,
1151it [00:41, 25.33it/s]1149:床前明月光,風吹清泠泠,一朝一朝夕,萬里無人情,一旦不可見,一言不可尋,我來不可見,不見不可攀,
1723it [01:01, 28.54it/s]1724:床前明月光,日月照清晨,一朝一朝夕,萬里無人心,一旦一何時,一身無所求,我來不可見,不見心中生,
2301it [01:21, 25.30it/s]2299:床前明月光,日月照前楹,一葉不可見,一聲無所思,一朝無一事,萬里無人心,一朝不可見,一旦無所思,
2873it [01:41, 28.93it/s]2874:床前明月光,日月照清光,一夜不相見,一聲不可尋,君子不可見,我心不可尋,我有一相見,心如萬里心,
3449it [02:02, 28.63it/s]3449:床前明月光,日月照清光,我有一人心,不見一片云,我有一人心,不如一一聲,我來不可見,何必有所思,
4024it [02:22, 28.75it/s]4024:床前明月光,日月照前楹,一夜不相見,一聲不可尋,我心不可見,此意何所為,我心不可見,此意何所為,
4598it [02:42, 28.60it/s]4599:床前明月光,日月照清光,一旦一杯酒,一杯一片云,一朝一杯酒,一旦一杯酒,一旦一杯酒,一杯不可見,
5174it [03:02, 28.38it/s]5174:床前明月光,日日明月明,一旦不可見,一旦不得真,一旦不得意,一言不可尋,一朝有所得,萬物皆自然,
5750it [03:22, 24.90it/s]5749:床前明月光,一日一日出,一朝一朝夕,一日一一日,一朝一朝夕,一日一一日,一朝一朝夕,一日一百里,
5758it [03:23, 28.35it/s]
573it [00:21, 28.84it/s]574:床前明月光,日月照清光,一朝一朝夕,一旦一日新,一朝一朝夕,一旦一日新,一朝一朝夕,一醉一相親,
1150it [00:41, 25.51it/s]1149:床前明月光,日月照清晨,一朝一朝暮,一旦一日行,一朝一朝去,一旦一日行,一旦不得意,一旦一相親,
1723it [01:01, 29.28it/s]1724:床前明月光,一旦一日暮,一朝一朝暮,一旦一相見,一旦東西來,一望一千里,江南一萬里,日暮東西北,
2298it [01:21, 28.75it/s]2299:床前明月光,日月照天地,一朝一朝暮,萬里無所適,一朝不可見,萬里無所適,一朝不可見,萬里無所適,
2874it [01:41, 28.97it/s]2874:床前明月光,一旦一日暮,一朝一朝暮,一日無一事,君子不可見,君子不可見,君子不可見,君子不可見,
3450it [02:02, 25.20it/s]3449:床前明月光,日日無所欲,我有一人書,不知何所似,我有一身心,不知身外事,我有一身心,不知身外事,
4023it [02:22, 28.76it/s]4024:床前明月光,日月照清晨,我來不可見,況乃無人知,我有一杯酒,我為一杯酒,我心不可忘,我心不可見,
4599it [02:42, 28.47it/s]4599:床前明月光,日月照清明,夜夜聞聲急,秋風入夜深,清風吹白日,白日照青天,遠近連天近,遙遙落照前,
5173it [03:02, 28.51it/s]5174:床前明月光,日月照清明,一夜不可見,一聲不可尋,一朝不可見,萬里無人心,一夜不可見,一聲不可聞,
5749it [03:22, 28.59it/s]5749:床前明月光,日月照清涼,清泠不可見,清凈不可尋,我有一寸心,不如一日心,我心不可忘,我心不可忘,
5758it [03:22, 28.38it/s]
575it [00:21, 26.28it/s]574:床前明月光,日日照前楹,不知何所有,不覺心相親,我來不得意,我亦無所聞,我來不得意,我亦無所聞,
1151it [00:41, 25.40it/s]1149:床前明月光,日月照清明,一旦一朝暮,一朝同此心,一朝無一事,萬里在江城,一旦東南望,千里萬里情,
1725it [01:01, 25.20it/s]1724:床前明月光,日月照清明,清風吹清風,清露灑清光,清晨動秋色,清景生秋光,清晨忽相見,清景自相尋,
2300it [01:21, 25.76it/s]2299:床前明月光,日月照天明,一朝不可見,萬里無窮年,一朝不可見,萬里無窮年,一朝不可見,萬里無窮年,
2873it [01:41, 28.84it/s]2874:床前明月光,日月照清晨,一聲一聲聲,萬里無人知,一旦不可見,萬里無人知,我來不可見,我有一生翁,
3449it [02:01, 28.83it/s]3449:床前明月光,天上一星星,天子一星星,天地一星星,天子不可見,天子不可當,一旦不可見,萬里無窮年,
4025it [02:22, 25.22it/s]4024:床前明月光,日月照秋色,一夜不可見,一聲不可見,我心不可窮,此夜不可見,我有一夜書,今來不可見,
4600it [02:42, 25.13it/s]4599:床前明月光,天籟清且清,清風吹玉琴,清夜清泠泠,清風忽相見,白日忽相尋,我來不得意,此物何所從,
5173it [03:02, 29.10it/s]5174:床前明月光,山下清風前,一朝一日月,一夜無一聲,一聲不可聽,一聲不可聽,一聲不可聽,一聲不可聽,
5748it [03:22, 28.85it/s]5749:床前明月光,日月照清明,一朝不可見,萬事皆可憐,一朝不可見,萬事皆可憐,一朝不可見,萬里無所營,
5758it [03:22, 28.39it/s]
574it [00:21, 28.46it/s]574:床前明月光,日月照清景,清晨日月明,清夜清風起,清風吹白云,颯颯灑幽草,清風忽相見,白日忽相見,
1151it [00:41, 24.91it/s]1149:床前明月光,日月照清明,一朝不可見,萬事皆相尋,一朝不可見,萬事皆相尋,一朝不可見,萬事皆相尋,
1723it [01:01, 28.64it/s]1724:床前明月光,日月照清明,一曲不可聽,一聲不可聽,我聞清涼夜,日暮清風前,我有一杯酒,不如一夜眠,
2300it [01:21, 25.46it/s]2299:床前明月光,日月照清明,一旦不可見,一生無所聞,一朝無一事,萬里無窮年,一旦東西來,一生不可尋,
2874it [01:41, 28.47it/s]2874:床前明月光,日月照清晨,清風吹玉珮,清露凝玉琴,清晨日月明,清夜清風前,一言不可遏,萬物不可尋,
3449it [02:01, 27.25it/s]3449:床前明月光,日月照清明,一聲清泠泠,一夜生秋琴,一聲清泠泠,萬籟生其根,一彈一杯酒,一曲無所聞,
4023it [02:22, 29.13it/s]4024:床前明月光,日月照清明,風吹風吹葉,風吹竹葉聲,山光照寒色,水汽入寒清,幽人惜幽賞,清夜坐清晨,
4598it [02:42, 28.48it/s]4599:床前明月光如玉,一點一聲三五月,一聲一聲聲不絕,一聲一曲聲聲絕,一聲一曲聲,一聲一聲鳴,一聲彈淚
5175it [03:02, 25.92it/s]5174:床前明月光如玉,月下高樓月明里,玉樓一曲聲不聞,玉筯雙雙淚如雨,君不見君王母,妾心不見妾,妾心不
5750it [03:22, 25.29it/s]5749:床前明月光如玉,玉堂金縷金瑯玕,玉壺金縷金縷縷,玉釵玉匣金麒麟,玉釵玉匣金麒麟,玉釵金縷金麒麟,
5758it [03:23, 28.34it/s]
574it [00:21, 29.19it/s]574:床前明月光如玉,月照青山天上天,玉樓月色照天色,金牓玲瓏照天碧,玉蟾蜍上金麒麟,玉蟾一日金麒麟,
1150it [00:41, 25.49it/s]1149:床前明月光如玉,一聲一聲無一聲,一聲一聲聲不盡,一聲一聲聲不鳴,夜深月明照明月,月明風急吹寒聲,
1724it [01:01, 28.51it/s]1724:床前明月光如玉,一聲一曲聲聲絕,一聲一聲聲不絕,一聲一曲聲聲絕,月明天上月明時,月照玉樓人不識,
2298it [01:21, 28.42it/s]2299:床前明月光如玉,玉堂金殿金麒麟,玉皇一曲皆相見,一旦如今不可見,君不見君王,不見君王說,不知何處
2873it [01:41, 28.60it/s]2874:床前明月光,日月明月明,清風吹玉琴,清夜清泠泠,一朝不可見,萬物皆自然,我來不可見,此道無所聞,
3450it [02:02, 25.42it/s]3449:床前明月光,日月照清明,人間有所遇,不覺心所宜,我有一尺書,不知身世間,我有一身心,不如身不閑,
4026it [02:22, 24.80it/s]4024:床前明月光如玉,月明照水光明滅,一聲一曲一聲聲,一曲琵琶一聲斷,一聲一曲聲聲聲,一聲一曲聲聲聲,
4598it [02:42, 28.48it/s]4599:床前明月光如玉,玉堂金鎖金盤盤,玉盤金縷珊瑚枝,玉盤金縷金瑯玕,玉顏一笑不可見,玉女不敢夸金雞,
5174it [03:02, 28.05it/s]5174:床前明月光如玉,夜夜清風吹玉堂,一聲一聲聲似夢,一聲吹笛聲聲,不知何處是君去,一夜風光無限情,君
5751it [03:23, 25.50it/s]5749:床前明月光如玉,夜夜相逢不相見,君不見君前見君意,今人不見君王侯,君不見君王不得意,今日相逢不相
5758it [03:23, 28.30it/s]
疑問,Cross Entropy Loss怎么計算的,有時間研究一下:
loss = criterion(output, target.view(-1)) # torch.Size([15872, 8293]), torch.Size([15872])
print(output)
print(output.size())
print(target.view(-1))
print(target.view(-1).size())
tensor([[ 0.0548, -0.0241, 0.0339, ..., 0.0208, 0.0340, 0.0335],
[ 0.0548, -0.0241, 0.0339, ..., 0.0208, 0.0340, 0.0335],
[ 0.0548, -0.0241, 0.0339, ..., 0.0208, 0.0340, 0.0335],
...,
[ 0.0807, -0.0297, 0.0327, ..., 0.0230, 0.0151, 0.0318],
[ 0.0465, -0.0348, 0.0352, ..., 0.0250, 0.0118, 0.0279],
[ 0.0407, -0.0019, 0.0164, ..., 0.0171, 0.0153, 0.0302]],
device='cuda:0', grad_fn=<AddmmBackward>)
torch.Size([1240, 8293])
tensor([8292, 8292, 8292, ..., 8290, 8290, 8290], device='cuda:0')
torch.Size([1240])
7. Test
看一下這個代碼:top_index = output.data[0].topk(1)[1][0]
print(output)
tensor([[-12.6328, -5.6997, -14.0606, ..., -16.1376, -18.8906, -14.4208]],
device='cuda:0', grad_fn=<AddmmBackward>)
print(output.data)
tensor([[-12.6328, -5.6997, -14.0606, ..., -16.1376, -18.8906, -14.4208]],
device='cuda:0')
print(output.data[0])
tensor([-12.6328, -5.6997, -14.0606, ..., -16.1376, -18.8906, -14.4208],
device='cuda:0')
print(output.data[0].topk(1))
torch.return_types.topk(
values=tensor([2.8427], device='cuda:0'),
indices=tensor([7066], device='cuda:0'))
print(output.data[0].topk(1)[1])
tensor([7066], device='cuda:0')
print(output.data[0].topk(1)[1][0])
tensor(7066, device='cuda:0')
所以topk()是求tensor中某個dim的前k大或者前k小的值以及對應的index,想知道每個樣本的最可能屬于的那個類別,其實可以用torch.max得到,如果要使用topk,則k應該設定為1
epoch = 8
機中有白玉,不得一一枝,器小不可得,不如不可欺,學之不可用,不為人世衰,習習不可見,我心不可求,
epoch = 4
機生不得意,不是不可求,器以不得意,不知何所求,學道不自得,不知無所求,習之不可見,不得無所求,
楊柳花,春色白,一枝一枝春色,思君不見,春色,春風吹落花,春風滿庭樹,春風滿庭樹,春風滿庭樹,一
楊柳花,春風吹,春風吹花,風吹花,思君不知春水綠,江南日暮江南北,程人不見,春風吹,江上月明天,
8. 全部代碼
import numpy as np # tang.npz的壓縮格式處理
import os # 打開檔案
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.nn.functional as F
import matplotlib.pyplot as plt
from torchnet import meter
import tqdm
def get_data():
if os.path.exists(data_path):
datas = np.load(data_path, allow_pickle=True) # 加載資料
data = datas['data'] # numpy.ndarray
word2ix = datas['word2ix'].item() # dic
ix2word = datas['ix2word'].item() # dic
return data, word2ix, ix2word
class Net(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(Net, self).__init__()
self.hidden_dim = hidden_dim
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(embedding_dim, self.hidden_dim, num_layers=2, batch_first=False)
# lstm輸入為:seq, batch, input_size
# lstm輸出為:seq * batch * 256; (2 * batch * 256,...)
self.linear1 = nn.Linear(self.hidden_dim, vocab_size)
def forward(self, input, hidden=None):
seq_len, batch_size = input.size()
if hidden is None:
h_0 = input.data.new(2, batch_size, self.hidden_dim).fill_(0).float()
c_0 = input.data.new(2, batch_size, self.hidden_dim).fill_(0).float()
h_0, c_0 = Variable(h_0), Variable(c_0)
else:
h_0, c_0 = hidden
embeds = self.embeddings(input) # (seq_len, batch_size, embedding_dim), (124,128,128)
output, hidden = self.lstm(embeds, (h_0, c_0)) #(seq_len, batch_size, hidden_dim), (124,128,256)
output = self.linear1(output.view(seq_len*batch_size, -1)) # ((seq_len * batch_size),hidden_dim), (15872,256) → (15872,8293)
return output, hidden
def train():
modle = Net(len(word2ix), 128, 256) # 模型定義:vocab_size, embedding_dim, hidden_dim —— 8293 * 128 * 256
criterion = nn.CrossEntropyLoss()
if torch.cuda.is_available() == True:
print('Cuda is available!')
modle = modle.cuda()
optimizer = torch.optim.Adam(modle.parameters(), lr=1e-3) # 學習率1e-3
criterion = criterion.cuda()
loss_meter = meter.AverageValueMeter()
period = []
loss2 = []
for epoch in range(8): # 最大迭代次數為8
loss_meter.reset()
for i, data in tqdm.tqdm(enumerate(dataloader)): # data: torch.Size([128, 125]), dtype=torch.int32
data = data.long().transpose(0,1).contiguous() # long為默認tensor型別,并轉置, [125, 128]
data = data.cuda()
optimizer.zero_grad()
input, target = Variable(data[:-1, :]), Variable(data[1:, :])
output, _ = modle(input)
loss = criterion(output, target.view(-1)) # torch.Size([15872, 8293]), torch.Size([15872])
loss.backward()
optimizer.step()
loss_meter.add(loss.item()) # loss:tensor(3.3510, device='cuda:0', grad_fn=<NllLossBackward>)loss.data:tensor(3.0183, device='cuda:0')
period.append(i + epoch * len(dataloader))
loss2.append(loss_meter.value()[0])
if (1 + i) % 575 == 0: # 每575個batch可視化一次
print(str(i) +':' + generate(modle,'床前明月光', ix2word, word2ix))
torch.save(modle.state_dict(), '...your path/model_poet_2.pth')
plt.plot(period, loss2)
plt.show()
def generate(model, start_words, ix2word, word2ix): # 給定幾個詞,根據這幾個詞生成一首完整的詩歌
txt = []
for word in start_words:
txt.append(word)
input = Variable(torch.Tensor([word2ix['<START>']]).view(1,1).long()) # tensor([8291.]) → tensor([[8291.]]) → tensor([[8291]])
input = input.cuda()
hidden = None
num = len(txt)
for i in range(48): # 最大生成長度
output, hidden = model(input, hidden)
if i < num:
w = txt[i]
input = Variable(input.data.new([word2ix[w]])).view(1, 1)
else:
top_index = output.data[0].topk(1)[1][0]
w = ix2word[top_index.item()]
txt.append(w)
input = Variable(input.data.new([top_index])).view(1, 1)
if w == '<EOP>':
break
return ''.join(txt)
def gen_acrostic(model, start_words, ix2word, word2ix):
result = []
txt = []
for word in start_words:
txt.append(word)
input = Variable(
torch.Tensor([word2ix['<START>']]).view(1, 1).long()) # tensor([8291.]) → tensor([[8291.]]) → tensor([[8291]])
input = input.cuda()
hidden = None
num = len(txt)
index = 0
pre_word = '<START>'
for i in range(48):
output, hidden = model(input, hidden)
top_index = output.data[0].topk(1)[1][0]
w = ix2word[top_index.item()]
if (pre_word in {',', '!', '<START>'}):
if index == num:
break
else:
w = txt[index]
index += 1
input = Variable(input.data.new([word2ix[w]])).view(1,1)
else:
input = Variable(input.data.new([word2ix[w]])).view(1,1)
result.append(w)
pre_word = w
return ''.join(result)
def test():
modle = Net(len(word2ix), 128, 256) # 模型定義:vocab_size, embedding_dim, hidden_dim —— 8293 * 128 * 256
if torch.cuda.is_available() == True:
modle.cuda()
modle.load_state_dict(torch.load('...your path/model_poet.pth'))
modle.eval()
# txt = generate(modle, '床前明月光', ix2word, word2ix)
# print(txt)
txt = gen_acrostic(modle, '機器學習', ix2word, word2ix)
print(txt)
if __name__ == '__main__':
data_path = '...your path/tang.npz'
data, word2ix, ix2word = get_data()
data = torch.from_numpy(data)
dataloader = torch.utils.data.DataLoader(data, batch_size=10, shuffle=True, num_workers=1) # shuffle=True隨機打亂
# train()
test()
小結
用PyTorch動手實作了LSTM的網路搭建,實作了基本的作詩功能,但是感覺效果一般,可能是訓練epoch少了,有時間看看和思考:
- Cross Entropy Loss具體怎么算出來的?
- 為什么影像有不連續處?
接下看一下GAN,Attention,BERT,Transform,可以實戰一下聊天機器人和英文文獻CNN文本分類的代碼復現
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/267174.html
標籤:python