首先以只讀方式打開單詞檔案,利用串列推導式創建兩個串列
串列sta記錄各單詞出現的次數,串列freq記錄各單詞出現的頻率
f = open('5500詞.txt','r',encoding='utf-8')
sta = [0 for i in range(26)]
freq = [0 for i in range(26)]
單詞格式如下所示:
a [ei] art.一(個);每一(個);(同類事物中)任一個
abandon [?’b?nd?n] vt.離棄,丟棄;遺棄,拋棄;放棄
abdomen [?b’d?umen] n.腹,下腹(胸部到腿部的部分)
abatement [?’beitm?nt] n.減(免)稅,打折扣,沖銷
abide [?’baid] vi.(abode,abided)(by)遵守;堅持;vt.忍受,容忍
每行一個單詞,所以我們選擇按行讀取檔案
for i in range(5500):
buf = f.readline()
然后依次統計每個字串中的字母個數,注意大寫字母也要統計(后面的字母省略)
for j in buf:
if j == 'a' or j == 'A':
sta[0] = sta[0] + 1
elif j == 'b' or j == 'B':
sta[1] = sta[1] + 1
注意到每個單詞后都有音標,所以遇到 中括號" [ "時停止計數
if j == '[':
break
然后每五個一行,依次輸出各個單詞出現的次數,將print函式中的end引數由默認換行改成幾個空格,使輸出更格式化,字母利用ASCII碼輸出
print('5498個詞匯中,各字母出現的次數分別為:\n')
asc = 97
for i in range(26):
if i < 25:
print("%c" % asc,':',sta[i],end=' ')
if (i + 1) % 5 == 0:
print('\n')
else:
print("%c" % asc,':',sta[i])
asc = asc + 1
利用一個for遍歷計算出所有字母數量的總和
sum = 0
for i in sta:
sum = sum + i
利用一個for遍歷計算出各字母出現的頻率,注意到Python中計算出的頻率會自動保留17位小數,為了方便查看,使用round()函式保留四位小數,值得注意的是,使用round()函式會自動去掉數字末尾的0
for i in range(26):
freq[i] = round(sta[i] / sum,4)
再以每五個一行,依次輸出各個單詞出現的頻率,將print函式中的end引數由默認換行改成幾個空格,使輸出更格式化,字母利用ASCII碼輸出,
print('各字母出現的頻率分別為:\n')
for i in range(26):
if i < 25:
print("%c" % asc,':',freq[i],end=' ')
if (i + 1) % 5 == 0:
print('\n')
else:
print("%c" % asc,':',freq[i])
asc = asc + 1
最后輸出的結果如下圖所示:
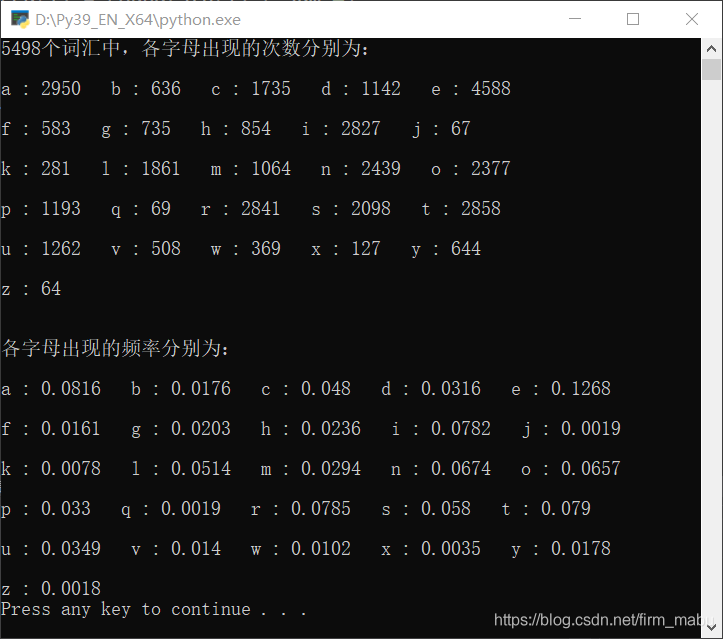
上概率論的課時,偶然看見居然有人拿著詞典去數字母的數量,就想能不能寫一個自動統計的程式,于是就隨便寫著玩,代碼功底很差,所以寫得很丑(居然有25個elif),所以看個樂呵就好了,
總的來說,我覺得有這些可以改進的地方:
①讀取單詞的方法可以改進,這種一行一行讀取的方式,對格式要求很高,很難找到
②用字典來存盤頻數和頻率是否會更好?后面輸出的時候可以避免使用ASCII碼,但是字典推導式我屬實記不清了
③判斷計數的這些if和elif能否抽象出一個方法?增加代碼復用
④round()函式會自動去掉小數后面的0,有沒有什么方法使0被保留下來?這樣輸出的格式會更好看
我的代碼的優點估計只有一點了:
①Python初學者就能看懂
如果你有什么改進的方法,請指出來,我將感激不盡;如果這篇文章能幫助到你,我更將不勝榮幸,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/267354.html
標籤:python
下一篇:20.旋轉字串